







一、什么是数据预处理
数据预处理是指在机器学习、数据分析和数据挖掘等领域中,对原始数据进行一系列的处理和转换,以便为后续的分析和建模做好准备。数据预处理是数据科学项目中的重要步骤,因为原始数据往往存在各种质量问题,如缺失值、异常值、重复数据、不一致的格式等,这些问题会直接影响模型的性能和最终结果的准确性。因此在数据分析中,对数据做数据预处理是必不可少的一个环节。
二、数据预处理的步骤
1、数据清洗:
-
处理缺失值:通过删除、填充或插值等方法处理数据中的缺失值。
import pandas as pd
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [None, 2, 3, 4],
'C': [1, 2, 3, None]
})
df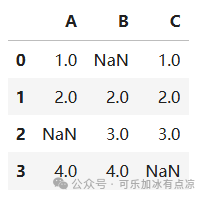
-
删除含有缺失值的行
# 删除含有缺失值的行
no_null_data = df.dropna()
no_null_data
-
填充缺失值
# 填充缺失值
fillna_data_mean=df.fillna(value=df.mean()) # 使用每一列的平均值填充
fillna_data_mean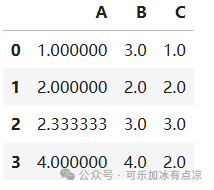
filled_data_before=df.fillna(method='ffill') # 使用前一个值填充
filled_data_before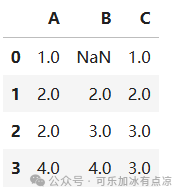
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2186
2186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











