










端到端Exactly Once的含义就是:Source的每条数据会被处理有且仅有一次,并且输出到Sink中的结果不重不丢。
Flink和Spark structure streaming能否做到端到端的exactly once?是可以的。由于原理类似,接下来拿spark举例分析一下。
kafka有关详细内容请看:
KIP-98 - Exactly Once Delivery and Transactional Messaging - Apache Kafka - Apache Software Foundation
一、前提
首先要明确几个概念:消息传输保障、幂等、事务、source、sink
1. 消息传输保障
一般情况消息中间件的消息传输保障有3个层级,分别是 at most once,at least once,exactly once。
对于kafka而言,如果生产者发送消息时,broker成功接收,由于kafka的高可靠性,消息就不会丢失。如果消息在发送途中遇到网络波动造成通信中断,那么生产者就不能判断消息是否已经提交,于是生产者可以通过retry来确保消息写入成功,这就有可能导致消息重复写入broker。所以在生产端kafka只能做到 at least once。
对于消费端,则完全取决于offset。如果在commit之前消费者拉取了某个offset后,突然挂掉,那么服务启动后会重新拉取该offset,此时也就对应了 at least once。那如果先发生commit,在逻辑处理时服务挂掉,启动后该消息就丢失了,此时便是 at most once。
那在kafka 0.11.0版本之后引入了幂等和事务的机制,以此来实现 exactly once。
2. 幂等
幂等,官方翻译,对接口的多次调用所产生的结果和调用一次的结果是一致的
如何开启幂等,properties.put("enable.idempotence", true),至于其他相关参数的配置,查看上面网址。
那什么时候用幂等呢?上面提到生产者因为网络故障对消息进行retry时,如果开启了幂等,那么就会保证消息无论发送多少次都会只有一条写入broker。同样内容的消息发送多次和一条消息重试多次,本质上是不一样的,不要弄混,前者每一条对broker来讲都是新的message,broker才不管内容是否相同。
为了实现幂等,kafka增加了producer id(PID)和序列号(epoch)两个概念。新的生产者初始化时会对应新的PID,同时epoch是从0递增,生产者每发送一条都会将<PID, partition>对应的epoch值加1。broker只有遇到了递增的消息才会将其写入,以此来实现幂等。但是如果同一条消息因某种原因retry时跨了分区,那幂等就无法发挥作用了,那就只能依靠事务了。
3. 事务
幂等做不到的是,事务可以保证对多个分区写入操作的原子性。kafka中的事务可以使应用程序将consume、produce和commit当做原子操作来处理,即使生产或消费跨多个分区。
为了实现事务,需要客户端提供唯一的 transactionlId,这个 transactionlId通过参数配置,例如:properties.put("transactionl.id", "xxxx")。同时开启事务的同时也要开启幂等,否则会抛出异常。
transactionlId是和PID 一 一对应的,前者由用户自行设置,后者则是由broker生成。另外,当客户端重启后,由于transactionlId保持不变,在获取PID的同时也会获取一个单调递增的epoch值,目的是避免同时存在两个相同的生成者。所以对于生产者,哪怕重启,也能保证幂等以及跨生产者会话的事务恢复。
4. source/sink
- source:streaming data 的产生端(比如 kafka、MySQL 等)
- sink:streaming data 的的输出端(比如 kafka、HDFS 等)
end-to-end 指的是,如果 source 选用类似 Kafka, HDFS 等,sink 选用类似 Kafka, HDFS, MySQL 等,那么 Structured Streaming 将自动保证在 sink 里的计算结果是 exactly-once 的,不需要使用者做额外的操心。
二、Structured Data
使用 Dataset/DataFrame 的形式来表达 structured data,具有广泛的适用性:
- Java 类 class Person { String name; int age; double height} 的多个对象可以方便地转化为 Dataset/DataFrame
- 多条 json 对象比如 {name: "Alice", age: 20, height: 1.68} 可以方便地转化为 Dataset/DataFrame
- 或者 MySQL 表、行式存储文件、列式存储文件等等都可以方便地转化为 Dataset/DataFrame
在Spark 2.0中,使用 Dataset/Dataframe 的行列数据表格扩展表达 streaming data —— 所以就出现了 structured streaming。与静态的 structured data 不同,动态的 streaming data 的数据表格是一直无限增长的(行数是可以不断增加),因为 streaming data 在源源不断地产生。
三、Structured Streaming
- structured streaming 同 spark streaming一样,也是先纯定义、再触发执行的模式,即前面代码是纯定义 Dataset/DataFrame 的transform算子,直到最后才真正 start 一个新线程,去触发执行之前定义好的算子。
- 在新的执行线程里需要持续地去拉取新数据,进而持续地查询最新计算结果直至写出。
- 在整个structured streaming中无法执行action算子,比如count,只能输出到某一处。
四、StreamExecution(持续查询的运转引擎)
StreamExecution 也就是整个Spark Structured Streaming 的驱动引擎。
Spark Structured Streaming 实现内部状态Exactly Once的语义基本原理是:隔一段时间做一个Checkpoint,持久化记录当前上游Source处理到哪里了(如Kafka offset),以及当时本地状态的值,如果过了一会进程挂了,就把这个持久化保存的Checkpoint读出来,加载当时的状态,并从当时的位置重新开始处理,这样每条消息一定只会影响自身状态一次。但这种方式是没办法保证输出到下游Sink的数据不重复的。要想下游输出的消息不重,就需要下游Sink支持事务消息,把两次checkpoint之间输出的消息当做一个事务提交(对应一个batch),如果新的checkpoint成功,则Commit,否则Abort。
1. StreamExecution 的初始状态
StreamExection 包含的重要成员变量:
- source: streaming data的产生端
- logicalPlan: DataFrame/Dataset 的一系列变换(即计算逻辑)
- sink: streaming data的输出端
- currentBatchId: 当前执行的 batch id
- batchCommitLog: 已经成功处理过的batch有哪些
- offsetLog, availableOffsets, committedOffsets: 当前执行需要处理的 source data 的 meta 信息
- state:窗口中的聚合状态
- offsetSeqMetadata: 当前执行的 watermark 信息
大部分上面变量都可以在checkpoint的目录中找到,如图(其中state目录只有使用了window才会生成):

如果细分一下,有人总结的特别好,比如这个图:

2. StreamExecution 的持续查询
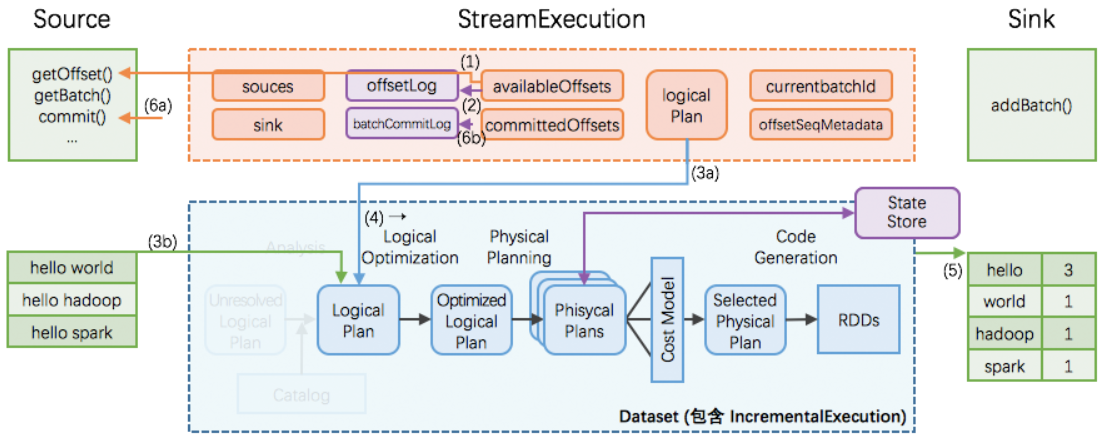
一次执行的过程如上图;有6个关键步骤:
1. StreamExecution 通过 Source.getOffset() 获取最新的 offsets;
2. StreamExecution 将 offsets 等写入到 offsetLog里(对应checkpoint中的offsets目录);
- 这里的 offsetLog 是一个持久化的 WAL (Write-Ahead-Log),是将来可用作故障恢复用
3. StreamExecution 构造本次执行的 LogicalPlan
- a. 将预先定义好的逻辑(即 StreamExecution 里的 logicalPlan 成员变量)制作一个副本出来
- b. 给定刚刚取到的offsets,通过 Source.getBatch(offsets) 获取本次执行新收到的数据,并用Dataset/DataFrame 表示,最后替换到 a 中的副本里
- c. 经过a、b两步,构造完成的 LogicalPlan 就是针对本执行新收到的数据的 Dataset/DataFrame 变换(即整个处理逻辑)了
4. 触发对本次执行的 LogicalPlan 的优化,得到 IncrementalExecution
- 逻辑计划的优化:通过 Catalyst 优化器完成
- 物理计划的生成与选择:结果是可以直接用于执行的 RDD DAG
- 逻辑计划、优化的逻辑计划、物理计划、及最后结果 RDD DAG,合并起来就是 IncrementalExecution
5. 将表示计算结果的 Dataset/DataFrame (包含 IncrementalExecution) 交给 Sink,即调用 Sink.add(ds/df)
6. 计算完成后 commit
- 通过 Source.commit() 告知 Source 数据已经完整处理结束;Source 可按需完成数据的 gc
- 将本次执行的批次 id 写入到 batchCommitLog 里
开启了事务,将相当于上述几个操作变成一个原子操作。
3. StreamExecution 的持续查询(增量)
structured streaming 在编程模型上暴露给用户的是,每次持续查询看做面对全量数据(而不仅仅是本次执行收到的数据),所以每次执行的结果是针对全量数据进行计算的结果。
但是在实际执行过程中,全量数据会越攒越多,那么每次对全量数据进行计算的代价和消耗会越来越大。
Structured Streaming 的做法是:
- 引入全局范围、高可用的 StateStore(对应checkpoint目录中的state目录)
- 转全量为增量,即在每次执行时:
- 先从 StateStore 里 restore 出上次执行后的状态
- 然后加入本执行的新数据,再进行计算
- 如果有状态改变,将把改变的状态重新 save 到 StateStore 里
- 为了在 Dataset/DataFrame 框架里完成对 StateStore 的 restore 和 save 操作,引入两个新的物理计划节点 —— StateStoreRestoreExec 和 StateStoreSaveExec (对应着对store目录操作的逻辑)
所以 Structured Streaming 在编程模型上暴露给用户的是,每次持续查询看做面对全量数据,但在具体实现上转换为增量的持续查询。
4. 故障恢复
存储 source offsets 的 offsetLog,和存储计算状态的 StateStore都是至关重要的,必须是全局高可用的。实际开发中,一般存储到HDFS、Redis、HBase(本质还是HDFS)。如图紫色部分:
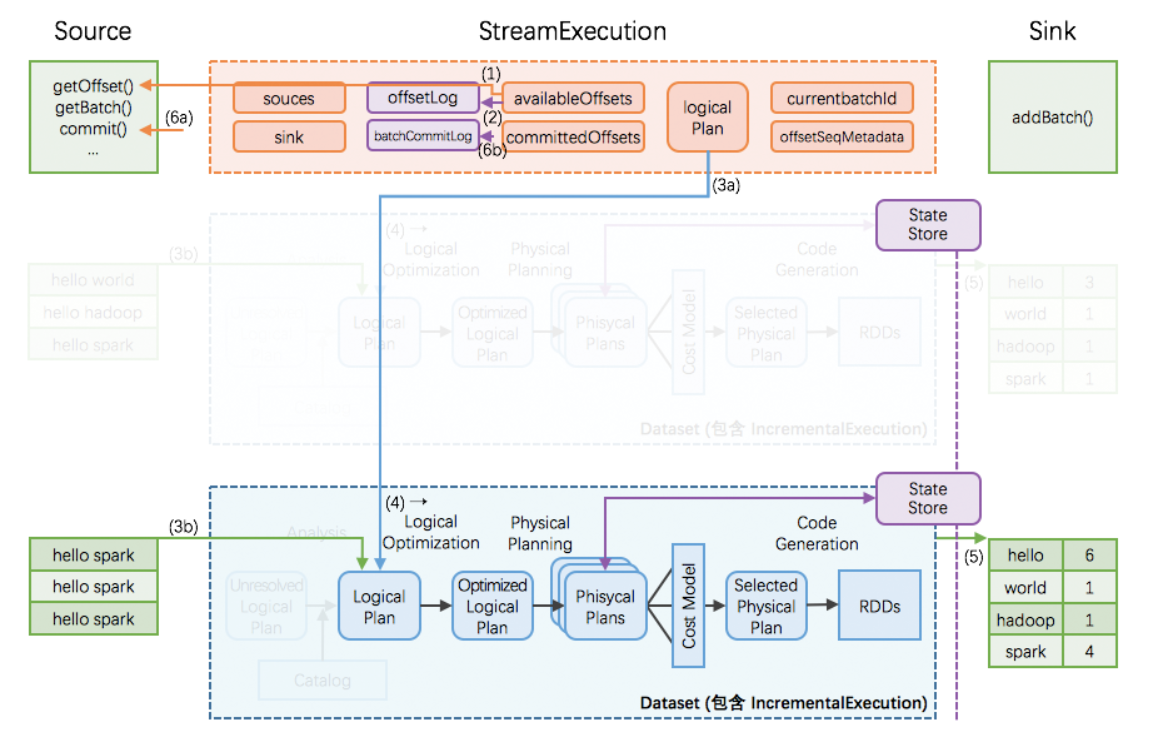
exectutor 节点的故障可由Spark框架本身提供高可用做保障,所以下面只讨论 driver 故障恢复。
如果在某个执行过程中发生 driver 故障,那么重新起来的 StreamExecution:
- 读取 WAL offsetlog 恢复出最新的 offsets 等;相当于取代正常流程里的 (1)(2) 步
- 读取 batchCommitLog 决定是否需要重做最近一个批次,也就是判断是否存在offsts已经记录但是没有commit的情况
- 如果需要,那么重做 (3a), (3b), (4), (5), (6a), (6b) 步
- 这里第 (5) 步需要分两种情况讨论
- a. 如果故障发生在 (5) 结束前,那么本次执行里 sink 应该完整写出计算结果
- b. 如果故障发生在 (5) 结束后,那么本次执行里 sink 可以重新写出计算结果(覆盖上次结果),也可以跳过写出计算结果(因为上次执行已经完整写出过计算结果了)
这样可保证每次执行的计算结果,在 sink 这个层面,是 不重不丢 的 —— 即使中间发生过N多次的故障恢复。
五. 小结
在 Structured Streaming 里,总结一下:
offsets in WAL + state management + fault-tolerant sources and sinks = end to end exactly once
参考资料
- Structured Streaming Programming Guide
- Github: org/apache/spark/sql/execution/streaming/Source.scala
- Github: org/apache/spark/sql/execution/streaming/Sink.scala
- KIP-98 - Exactly Once Delivery and Transactional Messaging - Apache Kafka - Apache Software Foundation
- Kafka核心设计与原理(朱忠华)















 2956
2956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









