







AlexNet 是 2012年ILSVRC 比赛冠军,远超第二名的CNN,比LeNet更深,用多层小卷积叠加来替换单个的大卷积,结构如下图所示。

结构
预处理
-
原始图片: 256 ∗ 256 ∗ 3 256*256*3 256∗256∗3
-
图像处理:
- 1.随机的剪切,将 256 ∗ 256 256*256 256∗256 的图片剪切成为 224 ∗ 224 224*224 224∗224 的图片
- 2.对 224 ∗ 224 224*224 224∗224 的图像做了一些旋转和位置变换
- 3.对 224 ∗ 224 224*224 224∗224 的图像做了一个图像大小的扩大,变成 227 ∗ 227 227*227 227∗227 的图片
-
备注:实际输入AlexNet网络的图片是一个 227 ∗ 227 ∗ 3 227*227*3 227∗227∗3 的图片信息
-
激励函数:论文中是:sigmoid,但是实际比赛的时候,使用的是ReLU
-
总参数量:60956032
L0:输入层
- input: 227 ∗ 227 ∗ 3 227*227*3 227∗227∗3
- output: 227 ∗ 227 ∗ 3 227*227*3 227∗227∗3
L1 卷积+激励
- input: 227 ∗ 227 ∗ 3 227*227*3 227∗227∗3
- filter: 3 ∗ 11 ∗ 11 3*11*11 3∗11∗11
- stripe: 4 4 4
- padding: 0 0 0
- filter size/depth: 48 ∗ 2 48*2 48∗2
- output: 55 ∗ 55 ∗ 48 ∗ 2 55*55*48*2 55∗55∗48∗2
- 神经元数目: 55 ∗ 55 ∗ 48 ∗ 2 55*55*48*2 55∗55∗48∗2
- 参数个数: ( 3 ∗ 11 ∗ 11 + 1 ) ∗ 48 ∗ 2 = 34944 (3*11*11+1)*48*2=34944 (3∗11∗11+1)∗48∗2=34944
- 连接方式:
- 使用双GPU来进行卷积操作,这个卷积操作和普通卷积一样
- 两个GPU并行的进行卷积操作,每个GPU只负责其中48个卷积核的计算
- 效果:可以并行的计算模型,模型执行效率可以得到提升,并且将GPU之间的通信放到网络结构偏后的位置,可以降低信号传输的损耗"
L2 最大池化
- input: 55 ∗ 55 ∗ 48 ∗ 2 55*55*48*2 55∗55∗48∗2
- filter: 3 ∗ 3 3*3 3∗3
- stripe: 2 2 2
- padding: 0 0 0
- output: 27 ∗ 27 ∗ 48 ∗ 2 27*27*48*2 27∗27∗48∗2
- 参数个数: 0 0 0
L3 卷积+激励
- input: 27 ∗ 27 ∗ 48 ∗ 2 27*27*48*2 27∗27∗48∗2
- filter: 5 ∗ 5 ∗ 48 5*5*48 5∗5∗48
- stripe: 1 1 1
- padding: 2 2 2 上下左右各加2个像素
- filter size/depth: 128 ∗ 2 128*2 128∗2
- output: 27 ∗ 27 ∗ 128 ∗ 2 27*27*128*2 27∗27∗128∗2
- 神经元数目: 27 ∗ 27 ∗ 128 ∗ 2 27*27*128*2 27∗27∗128∗2
- 参数个数: ( 5 ∗ 5 ∗ 48 + 1 ) ∗ 128 ∗ 2 = 307456 (5*5*48+1)*128*2=307456 (5∗5∗48+1)∗128∗2=307456
- 连接方式:各个GPU中对应各自的48个feature map进行卷积过程,和普通卷积一样
L4 最大池化
- input: 27 ∗ 27 ∗ 128 ∗ 2 27*27*128*2 27∗27∗128∗2
- filter: 3 ∗ 3 3*3 3∗3
- stripe: 2 2 2
- padding: 0 0 0
- output: 13 ∗ 13 ∗ 128 ∗ 2 13*13*128*2 13∗13∗128∗2
- 参数个数: 0 0 0
L5 卷积+激励
- input: 13 ∗ 13 ∗ 128 ∗ 2 13*13*128*2 13∗13∗128∗2
- filter: 3 ∗ 3 ∗ 256 3*3*256 3∗3∗256
- stripe: 1 1 1
- padding: 2 2 2
- filter size/depth: 192 ∗ 2 192*2 192∗2
- output: 13 ∗ 13 ∗ 192 ∗ 2 13*13*192*2 13∗13∗192∗2
- 神经元数目: 13 ∗ 13 ∗ 192 ∗ 2 13*13*192*2 13∗13∗192∗2
- 参数个数: ( 3 ∗ 3 ∗ 256 + 1 ) ∗ 192 ∗ 2 = 885120 (3*3*256+1)*192*2=885120 (3∗3∗256+1)∗192∗2=885120
- 连接方式:将两个GPU中的256个feature map一起做卷积过程
L6 卷积+激励
- input: 13 ∗ 13 ∗ 192 ∗ 2 13*13*192*2 13∗13∗192∗2
- filter: 3 ∗ 3 ∗ 192 3*3*192 3∗3∗192
- stripe: 1 1 1
- padding: 2 2 2
- filter size/depth: 192 ∗ 2 192*2 192∗2
- output: 13 ∗ 13 ∗ 192 ∗ 2 13*13*192*2 13∗13∗192∗2
- 神经元数目: 13 ∗ 13 ∗ 192 ∗ 2 13*13*192*2 13∗13∗192∗2
- 参数个数: ( 3 ∗ 3 ∗ 192 + 1 ) ∗ 192 ∗ 2 = 663936 (3*3*192+1)*192*2=663936 (3∗3∗192+1)∗192∗2=663936
- 连接方式:各个GPU中对应各自的48个feature map进行卷积过程,和普通卷积一样
L7 卷积+激励
- input: 13 ∗ 13 ∗ 192 ∗ 2 13*13*192*2 13∗13∗192∗2
- filter: 3 ∗ 3 ∗ 192 3*3*192 3∗3∗192
- stripe: 1 1 1
- padding: 2 2 2
- filter size/depth: 128 ∗ 2 128*2 128∗2
- output: 13 ∗ 13 ∗ 128 ∗ 2 13*13*128*2 13∗13∗128∗2
- 神经元数目: 13 ∗ 13 ∗ 128 ∗ 2 13*13*128*2 13∗13∗128∗2
- 参数个数: ( 3 ∗ 3 ∗ 192 + 1 ) ∗ 128 ∗ 2 = 442624 (3*3*192+1)*128*2=442624 (3∗3∗192+1)∗128∗2=442624
- 连接方式:各个GPU中对应各自的48个feature map进行卷积过程,和普通卷积一样
L8 最大池化
- input: 13 ∗ 13 ∗ 128 ∗ 2 13*13*128*2 13∗13∗128∗2
- filter: 3 ∗ 3 3*3 3∗3
- stripe: 2 2 2
- padding: 0 0 0
- output: 6 ∗ 6 ∗ 128 ∗ 2 6*6*128*2 6∗6∗128∗2
- 参数个数: 0 0 0
L9 全连接+激励
- input: 9216 9216 9216
- output: 2048 ∗ 2 2048*2 2048∗2
- 参数个数: 9216 ∗ 2048 ∗ 2 = 37748736 9216*2048*2=37748736 9216∗2048∗2=37748736
L10 全连接+激励
- input: 4096 4096 4096
- output: 2048 ∗ 2 2048*2 2048∗2
- 参数个数: 4096 ∗ 4096 = 16777216 4096*4096=16777216 4096∗4096=16777216
L11 全连接+激励
- input: 4096 4096 4096
- output: 1000 1000 1000
- 参数个数: 4096 ∗ 1000 = 4096000 4096*1000=4096000 4096∗1000=4096000
AlexNet结构优化
非线性激活函数:ReLU
使用Max Pooling,并且提出池化核和步长,使池化核之间存在重叠,提升了特征的丰富性。
防止过拟合的方法:Dropout,Data augmentation(数据增强)
大数据训练:百万级ImageNet图像数据
GPU实现:在每个GPU中放置一半核(或神经元),还有一个额外的技巧:GPU间的通讯只在某些层进行。
LRN归一化:对局部神经元的活动创建了竞争机制,使得其中响应比较大的值变得相对更大,并抑制其它反馈较小的神经元,增强了模型的泛化能力。本质上,LRN是仿造生物学上活跃的神经元对于相邻神经元的抑制现象(侧抑制)

在AlexNet引入了一种特殊的网络层次,即:Local Response Normalization(LRN, 局部响应归一化),主要是对ReLU激活函数的输出进行局部归一化操作,公式如下:
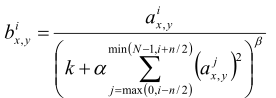
其中a表示第i个卷积核在(x,y)坐标位置经过激活函数的输出值,这个式子的含义就是输出一个值和它前后的n个值做标准化。k、n、α、β是超参数,在AlexNet网络中分别为:2、5、10^-4、0.75,N为卷积核总数。















 5356
5356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









