







 本文详细介绍了注意力机制的概念及其在自然语言处理中的应用。首先解释了注意力机制如何通过计算注意力分布和加权平均解决信息过载问题。然后介绍了注意力机制在RNN、完全基于注意力的seq2seq模型、Self-attention及Transformer中的具体应用。
本文详细介绍了注意力机制的概念及其在自然语言处理中的应用。首先解释了注意力机制如何通过计算注意力分布和加权平均解决信息过载问题。然后介绍了注意力机制在RNN、完全基于注意力的seq2seq模型、Self-attention及Transformer中的具体应用。
一、先说attention是什么。
attention也就是注意力机制,抽象来说是一种资源分配的方案,解决信息超载问题
注意力机制的计算可以分两步:
1、在所有输入信息上计算注意力分布
2、根据注意力分布来计算输入信息的加权平均
现在常用的是用键值对(key-value)来表示输入信息。抽象计算公式如下:
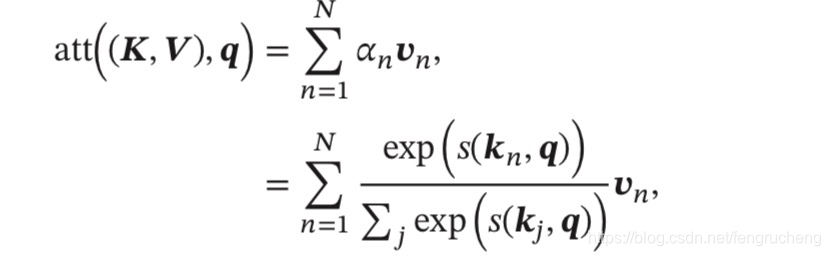
注意力分布𝛼𝑛 表示了在查询 𝒒 时,第n个输入向量受关注的程度
而关于注意力分布的计算,需要先计算打分,相应的打分函数有:

当前最常用的是缩放点积模型
二、attention的应用
1. Rnn+attention:
试图解决seq2seq中长序列遗忘的问题;
结合方式是在decoder时,以decoder的隐状态向量为q,encoder的隐状态向量为k和v, 计算注意力权重后加权平均,得到encoder隐状态的综合表示c。
所以,加入attention能使decoder有所侧重的使用隐状态。
s0是encoder的最终状态,通过𝛼i=align(h𝑖, 𝑠0) 得到h𝑖与s0之间的相关性, c0=𝛼1h1+𝛼2h2+ …+𝛼𝑚h𝑚.
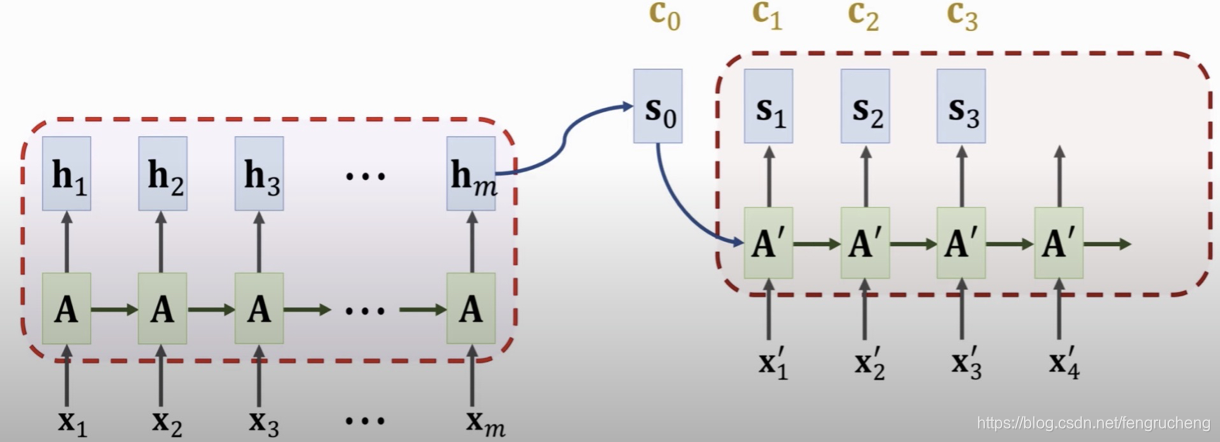
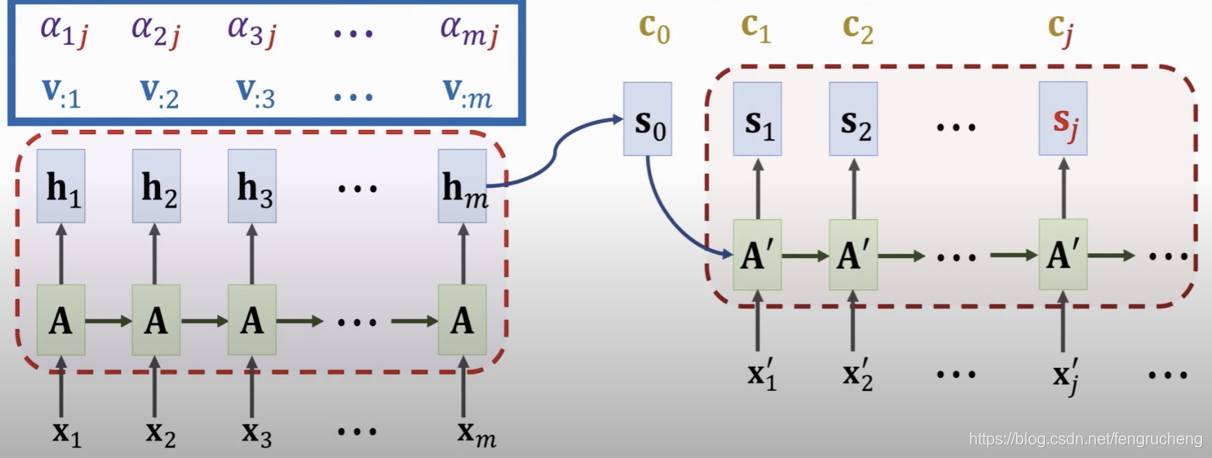
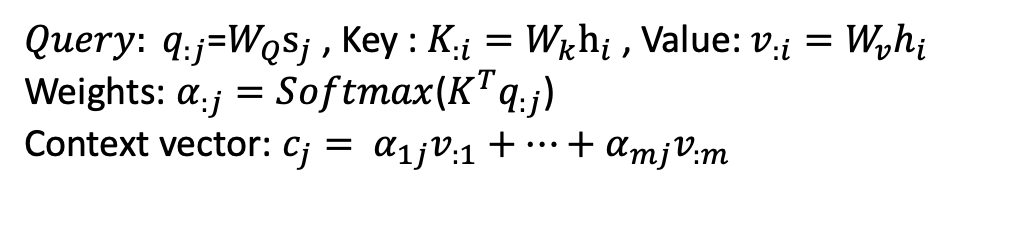

可以看到,和传统RNN比,在decoder的每一步,输入增加了个c0,即所有encoder隐状态的加权汇总。
2. 完全基于attention的seq2seq
即不再使用rnn产生隐状态,q是decoder的输入(上一个翻译的词),k和v是所有的encoder的输入。
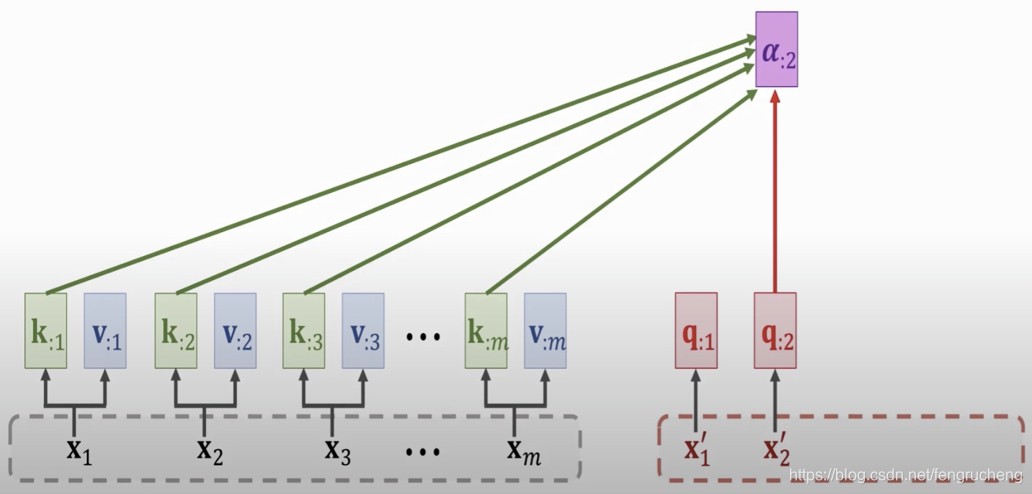
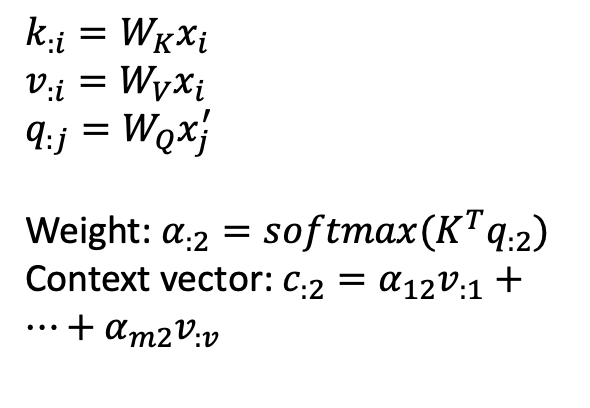
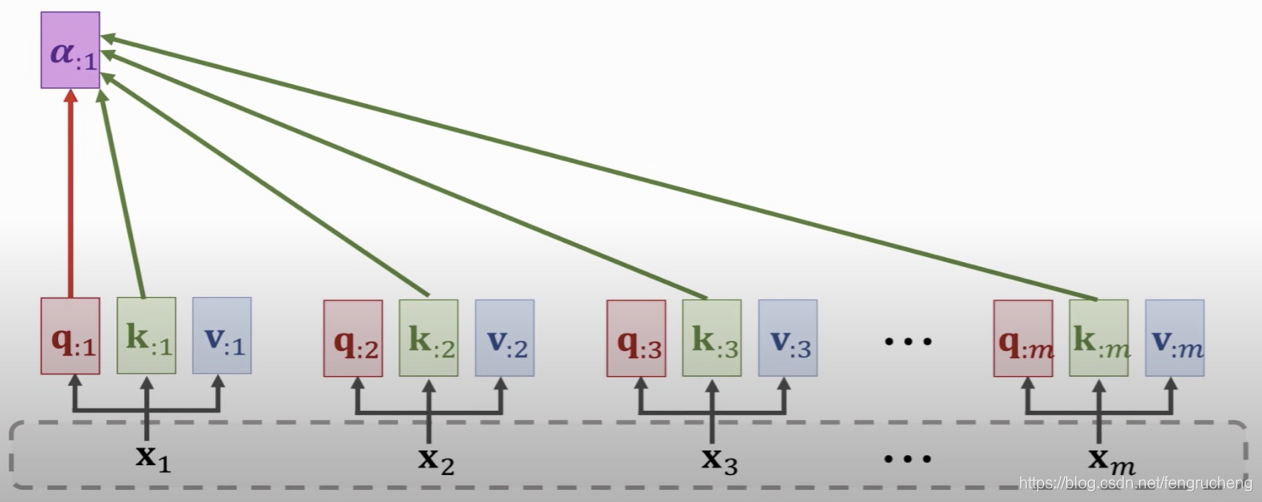
3. Self attention
q、k、v都是由相同的输入产生,充分挖掘数据内容上下文之间的关联性
4. Transformer
它是一个seq2seq的模型
它也可以看成是由encoder和decoder组成,但它不是RNN
它完全基于attention机制和全连接层等
在大型数据集上,相比RNN有更高的准确率
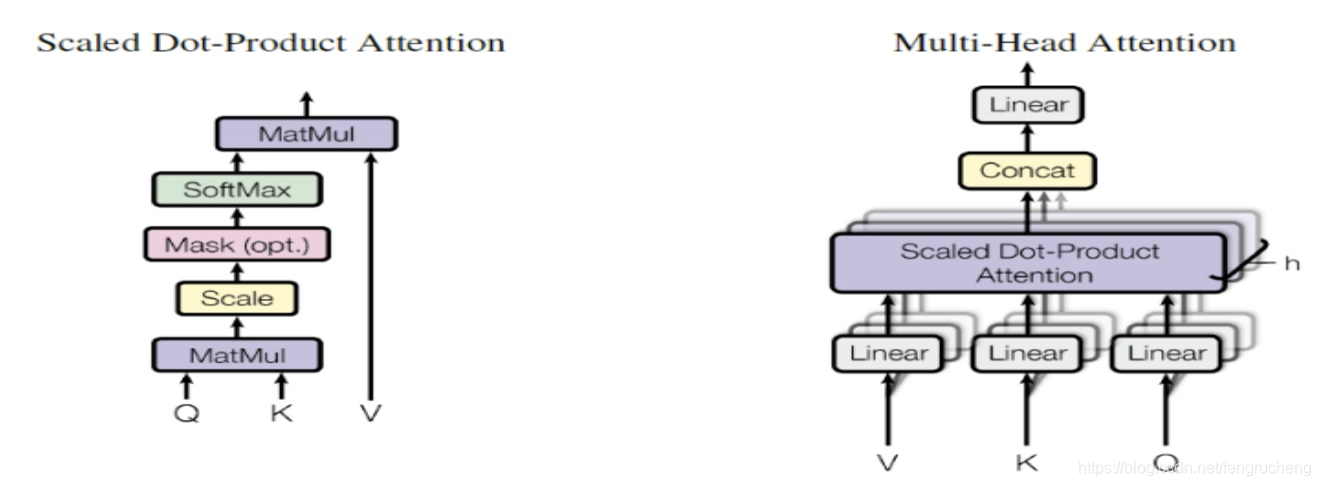
主要的特点:
- Self-attention:充分挖掘序列信息
- 归一化点积:抵消特征向量维度的影响,维度过高导致softmax的梯度很小,除了一个dk可以增加梯度
- 多头机制:从不同的表示子空间,做注意力加权表示,减小方差。多头attention的dk/dv分别减小为单头attention的1/h倍,所以多头attention的计算量其实与单头attention一样
- 这样的网络结构可以并行训练,并且特征提取能力比rnn/lstm/cnn等都要强,
整体架构:
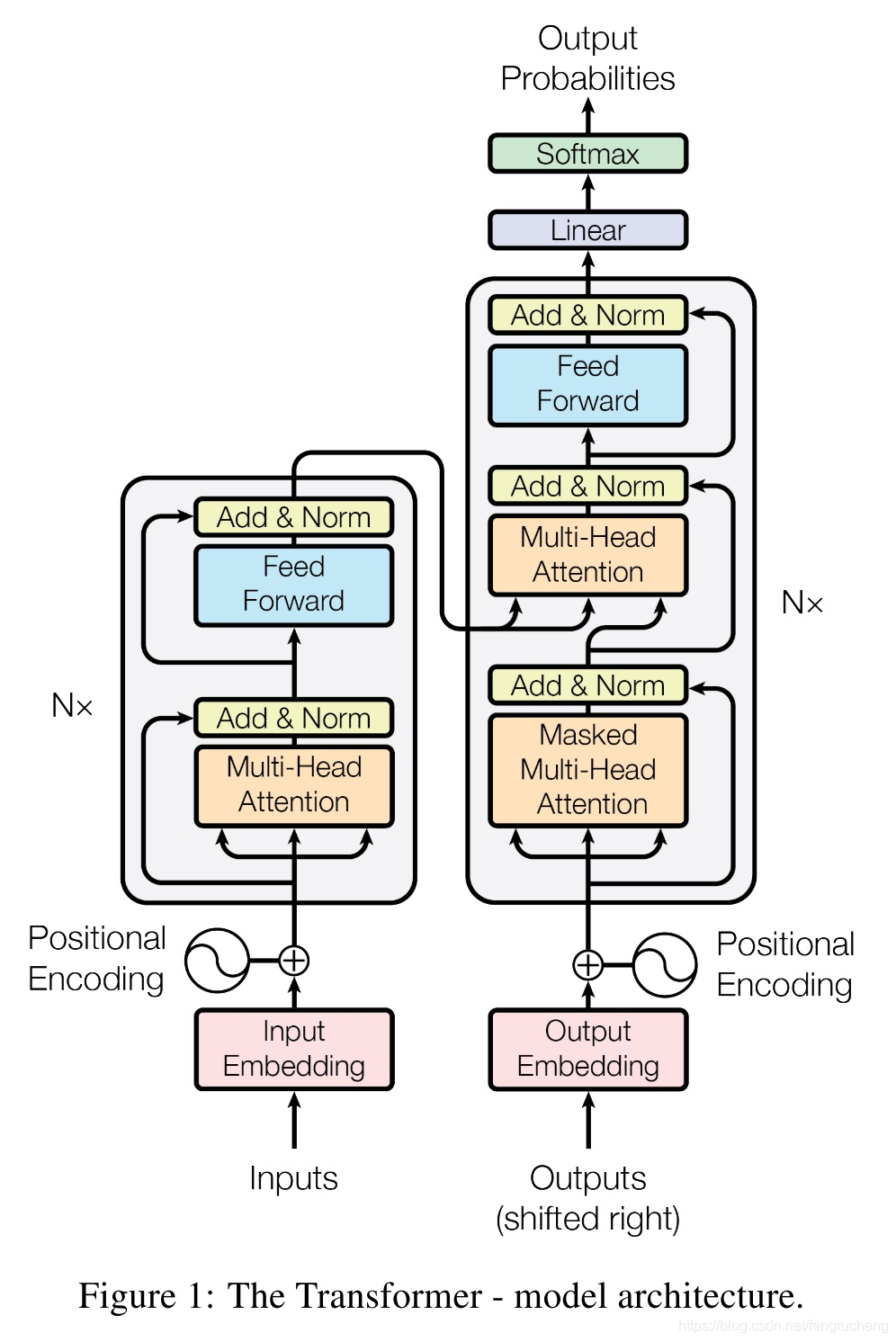
一些细节:
- 短连接:让信息无损的传递,减小训练的难度,能够叠加多层
- 位置编码:attention本身无法表示位置,只能通过编码(加法)
- 归一化:layernorm(不同特征维度之间),训练更快、更稳定
- 前向网络:信息融合
- decoder中的attention:不是self-attention,q是所有的输出历史加权向量。
- 每一层都要把encoder的输出作为输入
- 线性转化的目的主要是为了使得输出的维度与Scaled Dot-Product Attention保持一致


















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









