






上一篇:https://blog.csdn.net/fengxianaa/article/details/124409120
当主从集群下Master当宕机,Redis 的哨兵机制(Sentinel)会从Slave节点中选举一个新的Master
主要功能如下
(1)集群监控,负责监控redis master和slave是否正常工作
(2)故障转移,如果master node挂掉了,自动故障转移,从Slave节点中选举一个新的Master
(3)消息通知,如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
如果故障转移发生了,通知client客户端新的master地址

1. 集群监控
哨兵是基于心跳机制监控集群状态,每秒向集群中的实例发送ping命令
-
- 如果某个哨兵节点发现某实例没在规定时间(is-master-down-after-milliseconds)响应,则该实例主观宕机(sdown)
- 如果指定数量(quorum)的哨兵都认为这个实例宕机,则该实例客观宕机(odown),quorum最好超过一半数量

上图中,一同有3个哨兵,其中2个都认为master宕机了,且quorum=2,那么这个master就是客观宕机,需要进行故障转移
2. 故障转移
一旦认为Master客观宕机,哨兵会在slave中选出一个最为新的Master,选举算法
- 判断跟Master断开连接的时长,超过了down-after-milliseconds的10倍,排除这个slave
- 判断salve的优先级,slave priority越低,优先级就越高
- 如果slave priority相同,那么看replication offset,offset越大,优先级就越高
- 如果上面两个条件都相同,那么选择一个run id比较小的
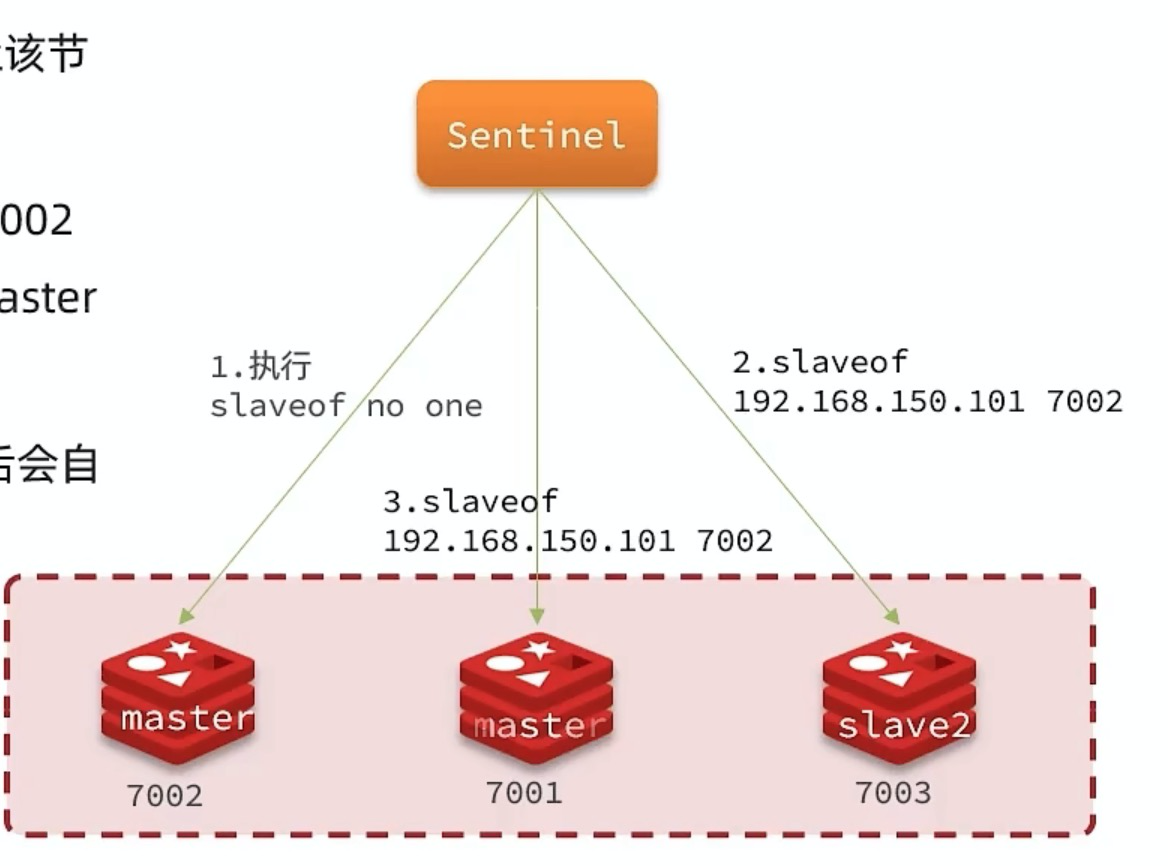
一旦确定Master节点后,会选择一个哨兵节点,进行故障转移
- 给备选的slave发送slave no none 命令,让该节点成为Master
- 给其他slave节点发送 slaveof <master IP> <master port> 命令,让这些slave成为新Master的从节点
- 给故障的节点标记为slave,当节点恢复后,会自动成为从节点
3. 搭建哨兵集群
1. 配置
在 /root/soft/redis 目录下创建 3 个 文件夹

在 s1 中 创建 sentinel.conf 文件,并添加下面内容
# 哨兵 监听端口
port 27001
# 哨兵之间通信使用的ip地址
sentinel announce-ip 192.168.56.103
# 监控集群,格式:sentinel monitor <master name(可自定义)> <master ip> <master port> <quorum>
sentinel monitor mymaster 192.168.56.103 7001 2
# 主观判断指定时间内,节点是否宕机,单位:毫秒
sentinel down-after-milliseconds mymaster 5000
# 故障转移的超时时间,单位:毫秒,如果超时,再选一个slave进行切换
sentinel failover-timeout mymaster 60000
# 工作目录
dir "/root/soft/redis/s1"
# 密码配置,我没有设置密码
#sentinel auth-pass mymaster <password>
# 新的master别切换之后,同时有多少个slave被切换到去连接新master,重新做同步
# sentinel parallel-syncs mymaster 1
# 假设1个master,4个slave,然后master宕机了,4个slave中有1个切换成了master,剩下3个slave就要挂到新的master上面去
# 这个时候,如果parallel-syncs是1,那么3个slave,一个一个,排序挂接到新的master上面去
# 如果parallel-syncs是3,那么一次性就会把所有slave挂接到新的master上去s2、s3类似
启动哨兵: redis-sentinel s1/sentinel.conf,启动前要保证redis实例已经启动

哨兵启动后,会互相通信
7001 日志

7002 日志

7003 日志

2. 测试
关闭 7001 主节点,从 3 个哨兵日志中,找到如下日志,我的是在s2中找到的

解释:
客观认为 7001 宕机
24701:X 18 Apr 2022 22:48:18.502 # +sdown master mymaster 192.168.56.103 7001
主观认为 7001 宕机, 因为 quorum 2/2
24701:X 18 Apr 2022 22:48:18.603 # +odown master mymaster 192.168.56.103 7001 #quorum 2/2
开始投票选出一个哨兵做故障转移,最终结果投票给 f5296605b9c786e377e4afb2fb93ded6094415e5
24701:X 18 Apr 2022 22:48:18.603 # +new-epoch 1
24701:X 18 Apr 2022 22:48:18.603 # +try-failover master mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:18.608 # +vote-for-leader f5296605b9c786e377e4afb2fb93ded6094415e5 1
24701:X 18 Apr 2022 22:48:18.617 # bf82c362a5d426a822d34327d5d1641683d683bc voted for f5296605b9c786e377e4afb2fb93ded6094415e5 1
24701:X 18 Apr 2022 22:48:18.618 # ed6cbda34457bf8d1f6e910e03362c6062a35061 voted for f5296605b9c786e377e4afb2fb93ded6094415e5 1
24701:X 18 Apr 2022 22:48:18.666 # +elected-leader master mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:18.666 # +failover-state-select-slave master mymaster 192.168.56.103 7001
从集群中选择一个作为新的master,最终选择了 7002
24701:X 18 Apr 2022 22:48:18.721 # +selected-slave slave 192.168.56.103:7002 192.168.56.103 7002 @ mymaster 192.168.56.103 7001
给 7002 发送了noone命令,让它成为主节点,查看下方图1
24701:X 18 Apr 2022 22:48:18.721 * +failover-state-send-slaveof-noone slave 192.168.56.103:7002 192.168.56.103 7002 @ mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:18.798 * +failover-state-wait-promotion slave 192.168.56.103:7002 192.168.56.103 7002 @ mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:19.719 # +promoted-slave slave 192.168.56.103:7002 192.168.56.103 7002 @ mymaster 192.168.56.103 7001
重新配置7001,让其成为slave
24701:X 18 Apr 2022 22:48:19.719 # +failover-state-reconf-slaves master mymaster 192.168.56.103 7001
通知7003 ,新的master是7002,查看下方图2
24701:X 18 Apr 2022 22:48:19.777 * +slave-reconf-sent slave 192.168.56.103:7003 192.168.56.103 7003 @ mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:20.724 * +slave-reconf-inprog slave 192.168.56.103:7003 192.168.56.103 7003 @ mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:20.724 * +slave-reconf-done slave 192.168.56.103:7003 192.168.56.103 7003 @ mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:20.796 # -odown master mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:20.796 # +failover-end master mymaster 192.168.56.103 7001
24701:X 18 Apr 2022 22:48:20.796 # +switch-master mymaster 192.168.56.103 7001 192.168.56.103 7002
24701:X 18 Apr 2022 22:48:20.796 * +slave slave 192.168.56.103:7003 192.168.56.103 7003 @ mymaster 192.168.56.103 7002
24701:X 18 Apr 2022 22:48:20.796 * +slave slave 192.168.56.103:7001 192.168.56.103 7001 @ mymaster 192.168.56.103 7002
24701:X 18 Apr 2022 22:48:25.853 # +sdown slave 192.168.56.103:7001 192.168.56.103 7001 @ mymaster 192.168.56.103 7002图1:

图2:

这时候再次重启 7001 ,然后查看7002日志,发现7001请求同步数据

查看7001日志,作为一个slave,连接7002

4. redisTemplate
redisTemplate感知redis故障转移
修改之前 properties 文件
# master 名称
spring.redis.sentinel.master=mymaster
# 哨兵地址
spring.redis.sentinel.nodes[0]=192.168.56.103:27001
spring.redis.sentinel.nodes[1]=192.168.56.103:27002
spring.redis.sentinel.nodes[2]=192.168.56.103:27003增加一个bean配置
/**
* 配置读写分离
* @return
*/
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}代码中的 ReadFrom.REPLICA_PREFERRED 是redis的读取策略,有下面几种
- MASTER 从master读取
- MASTER_PREFERRED 优先 master 读取,master不可用,读 slave
- REPLICA 从 slave 读取
- REPLICA_PREFERRED 优先从 slave 读取,slave不可用,读master
Controller
@Autowired
private StringRedisTemplate stringRedisTemplate;
@GetMapping("/set")
public String set(@RequestParam String key , @RequestParam String value){
stringRedisTemplate.opsForValue().set(key, value);
return "success";
}
@GetMapping("/get")
public String get(@RequestParam String key){
return stringRedisTemplate.opsForValue().get(key);
}正常访问,没问题,如果停掉7002 ,再次访问,也是正常的
5. 两种数据丢失
- 异步复制导致的数据丢失
- 因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了
- 脑裂导致的数据丢失
- 脑裂,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着
- 此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master
- 这个时候,集群里就会有两个master,也就是所谓的脑裂
- 虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了
解决:
- min-replicas-to-write 1
- 写数据时,如果跟 master 正常同步的 slave 数量小于1,则 master 拒绝写入
- 配置0,则关闭此功能
- min-slaves-max-lag 10
- 主从库间进行数据复制时,从库给主库发送 ACK 消息的最大延迟,单位:秒
- 如果大于10秒,则 master 拒绝写入
这两个配置可以有效避免数据的丢失














 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









