







我们在学习Spring的时候会去加载Spring上下文环境,一般常用的加载方式有这三种:
ClassPathXmlApplicationContext:它可以加载类路径下的配置文件,要求配置文件必须在类路径下。
FileSystemXmlApplicationContext:它可以加载磁盘任意路径下的配置文件(必须有访问权限)。
AnnotationConfigApplicationContext:它是用于读取注解创建容器的。
我们现在用的比较多的是依靠注解形式的开发,在Spring中我们通常像下面这样拿到Spring容器的上下文:
先写一个配置类(这里自定义了过滤规则,被@Server标记的类不会被加载到容器里):
@Component
@ComponentScan(basePackages = "text.pros",
useDefaultFilters = false,
includeFilters = {@ComponentScan.Filter(type = FilterType.ANNOTATION,value = Component.class)},
excludeFilters = {@ComponentScan.Filter(type = FilterType.ANNOTATION,value = Server.class)}
)
public class AppConfig {
}
解析配置类:
@Test
public void test01(){
//加载上下文环境
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
String[] beanDefinitionNames = context.getBeanDefinitionNames();//拿到容器中所有bean的名字
Arrays.asList(beanDefinitionNames).forEach(System.out::println);//输出bean的名字
}
然后它就会去扫描@ComponentScan里面标记的包及其子包,并将其加载到上下文中
接下来我们就可以看看这个神奇的
AnnotationConfigApplicationContext是怎么加载Spring上下文环境了
点进去看,我们可以看到:
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this();//初试化AnnotatedBeanDefinitionReader和ClassPathBeanDefinitionScanner
register(componentClasses);
}
public AnnotationConfigApplicationContext(String... basePackages) {
this();//实现自定义或者默认的过滤器规则,即扫描那些包,默认扫描被@Component标记的包
scan(basePackages);//扫描包 将bean包装成beanDefinition对象,再注册到容器中
refresh();
}
接下来我们分别看这三行代码中Spring是怎么实现过滤包、扫描注册bean、这三个功能的
1. 实现自定义或者默认的包扫描规则
从上面的代码中我们可以知道AnnotationConfigApplicationContext加载上下文的方式可以有两种:可以传入一个反射字节码、也可以传入一个包名。其实我们猜也可以猜到,传入字节码也只不过是拿到@ComponentScan(basePackages = "text.pros")里面的包路径名称,所以我们可以先看下面的方法,先探索一下加载上下文的过程中
this()调用的是其无参构造函数
public AnnotationConfigApplicationContext() {
StartupStep createAnnotatedBeanDefReader = this.getApplicationStartup().start("spring.context.annotated-bean-reader.create");
//用来解析带注解的Bean
this.reader = new AnnotatedBeanDefinitionReader(this);
createAnnotatedBeanDefReader.end();
//类路径扫描器,扫描指定类路径中注解Bean定义的扫描器
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
扫描包及其子包的奥秘就这这行代码里面:
this.scanner = new ClassPathBeanDefinitionScanner(this);
加载了一个扫描器,并将当前类放入,我们继续点进去,可以看到
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry) {
this(registry, true);
}
但是我们传进来的不是一个AnnotationConfigApplicationContext吗?为什么参数列表里面变成了BeanDefinitionRegistry
因为他们之间是有继承关系的:
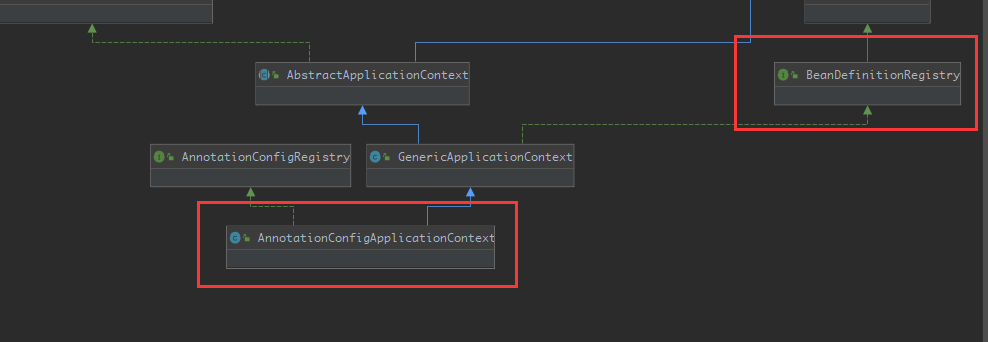
点到this里面,第一个参数就是我们加载上下文的ApplicationContext,第二个参数表示使用默认的构造器,第三个参数表示要从传入的类中拿到系统的环境变量和jdk的环境变量,就是我们System.getProperties()能够拿到的东西
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters) {
this(registry, useDefaultFilters, getOrCreateEnvironment(registry));
}
我们继续点进去
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment) {
this(registry, useDefaultFilters, environment,
(registry instanceof ResourceLoader ? (ResourceLoader) registry : null));
}
可以看到参数再不断变多,继续点进去看,接下来就是核心了
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;//为容器设计加载Bean定义的注册器
if (useDefaultFilters) {
//初始化spring扫描默认过滤规则,对应@ComponentScan注解,如果没有自定义规则,就初始化默认过滤规则
registerDefaultFilters();
}
//设置环境
setEnvironment(environment);
//为容器设置资源加载器
setResourceLoader(resourceLoader);
}
如果没有自定义过滤器,就会使用默认过滤器registerDefaultFilters(),可以看一下这个默认过滤器
protected void registerDefaultFilters() {
//默认情况下,只要是@Component相关注解都要扫描,添加此规则
//@Service和@Controller都是Component,因为这些注解都添加了@Component注解
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
//获取当前的类加载器 JVM双亲委派模型,通过此加载了当前类的类加载器,app类加载器
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
//向要包含的过滤规则添加JavaEE6的@ManagedBean注解
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("jakarta.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'jakarta.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Jakarta EE) not available - simply skip.
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("jakarta.inject.Named", cl)), false));
logger.trace("JSR-330 'jakarta.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
在这一行代码中
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
includeFilters是一个被final修饰的List集合,final修饰可以保证线程安全,可以看到此过滤器的规则是默认情况下只要Component标记的类都会被加到容器中,除此之外,还默认加载@ManagedBean和@Named注解标记的类
到此我们可以看到Spring是如何设置默认的过滤器规则的,接下来我们看刚开始入口函数中的第二个方法scan(basePackages),看下Spring是怎么扫描注册bean的
2. 扫描包 将bean包装成beanDefinition对象,再注册到容器中
把上面的代码贴下来:
public AnnotationConfigApplicationContext(String... basePackages) {
this();//实现自定义或者默认的过滤器规则,即扫描那些包,默认扫描被@Component标记的包
scan(basePackages);//扫描包并注册bean
refresh();
}
现在我们来研究这个方法scan(basePackages),看是Spring是如何扫描包并注册bean的
public int scan(String... basePackages) {
//获取容器中已经注册的Bean个数,因为配置文件以及包路径有多个,所以可能会有已经注册好的bean
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
//启动扫描器并扫描指定包
doScan(basePackages);
// Register annotation config processors, if necessary.
//注册注解配置(Annotation config)处理器
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
//返回新注册的Bean的个数
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
进doScan方法,看是如何具体扫描的
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
/*
* 创建一个集合,存放扫描到Bean定义的封装类
* set无序不可重复,BeanDefinitionHolder包装一个BeanDefinition
* BeanDefinition是bean的定义类,里面存放一个关于Bean的所有信息,例如有scope、lazy、initMethod、destroyMethod
* **/
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
//遍历扫描所有给定的包
for (String basePackage : basePackages) {
//调用父类ClassPathScanningCandidateComponentProvider的方法
//扫描给定类路径,获取符合条件的Bean定义,并存入集合BeanDefinitions中
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
//遍历扫描所有扫描到的Bean
for (BeanDefinition candidate : candidates) {
//获取@Scope注解的值,即获取Bean的作用域,SCOPE_SINGLETON单例,立马创建,SCOPE_PROTOTYPE非单例,getBean的时候才创建
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
//为Bean设置作用域
candidate.setScope(scopeMetadata.getScopeName());
//为bean生成名字,首字母小写还是类的全路径名称
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
/*
* AbstractBeanDefinition 抽象Bean 没有属性
* AnnotatedBeanDefinition 定义一些具体的Bean的定义属性 scope、lazy、proxy等等
* **/
if (candidate instanceof AbstractBeanDefinition) {
//后置处理bean定义,也就是给bean默认值,例如一个bean什么都不写也会默认lazy加载
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//根据bean的名称检查指定bean是否需要在容器中注册,或者在容器中冲突
if (checkCandidate(beanName, candidate)) {
//创建bean
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
//根据注解中配置的作用域,为Bean应用相应的代理模式
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
//将生成的definitionHolder保存到集合中
beanDefinitions.add(definitionHolder);
//向容器注册扫描到的Bean
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
其中这一行是在处理当前bean是否有代理时
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
我们点进去可以看到:
static BeanDefinitionHolder applyScopedProxyMode(
ScopeMetadata metadata, BeanDefinitionHolder definition, BeanDefinitionRegistry registry) {
//获取注解Bean定义类中@Scope注解的proxyMode属性值
ScopedProxyMode scopedProxyMode = metadata.getScopedProxyMode();
//如果不代理,则直接返回
if (scopedProxyMode.equals(ScopedProxyMode.NO)) {
return definition;
}
//获取配置的@Scope注解的proxyMode属性值,如果为TARGET_CLASS,则返回true,如果为INTERFACES,则返回false
/*
* 代理有两种,基于继承TARGET_CLASS 和 基于接口INTERFACES
* 默认是基于继承结构的代理ScopedProxyMode.TARGET_CLASS
* **/
boolean proxyTargetClass = scopedProxyMode.equals(ScopedProxyMode.TARGET_CLASS);
//为注册的Bean创建相应模式的代理对象
return ScopedProxyCreator.createScopedProxy(definition, registry, proxyTargetClass);
}
最后就是扫描注册bean了
registerBeanDefinition(definitionHolder, this.registry);
一直往下点:
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
//获取解析的BeanDefinition的名称
String beanName = definitionHolder.getBeanName();
//注册bean并将其交给Spring容器
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
//如果解析的BeanDefinition有别名,向容器为其注册别名
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
//不管一个Bean有多少个别名,只注册一次
registry.registerAlias(beanName, alias);
}
}
}
可以看到我们注册bean的方法
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
继续点进去可以看到,后面就是beanFactory来具体实例化一个bean了

我们继续回到doscan方法,探究下Spring是如何扫描当前包及其子包的
具体追踪路径为:
AnnotationConfigApplicationContext
-> AnnotationConfigApplicationContext(String... basePackages)里面的scan(basePackages)
-> this.scanner.scan(basePackages)
-> doScan(basePackages)
-> Set<BeanDefinition> candidates = findCandidateComponents(basePackage)
-> return scanCandidateComponents(basePackage)
-> Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath)
-> 实现类PathMatchingResourcePatternResolver
-> public Resource[] getResources(String locationPattern) throws IOException
到这里我们就可以看到Spring扫描包及其子包的全过程了😀















 1188
1188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









