







文章目录
记录一下在CentOS7上搭建Hadoop环境的过程
我们先要有以下软件安装包:

- centos7镜像(这里是为了用模拟器安装,有云服务器同学可以用云服务器)
- hadoop安装包
- jdk8 Linux版本安装包
- finalshell:用来连接Linux并上传数据
1.虚拟机安装Centos7环境(有环境的同学跳到后面)
我使用的是VMware Workstation 16 Pro,这个的安装教程很多,大家可以自行搜索安装。
官网:https://www.vmware.com/cn/products/workstation-pro.html
导入镜像后需要先开放网络, 首先在命令行里登录,账号是root,再敲入命令nmtui设置网络
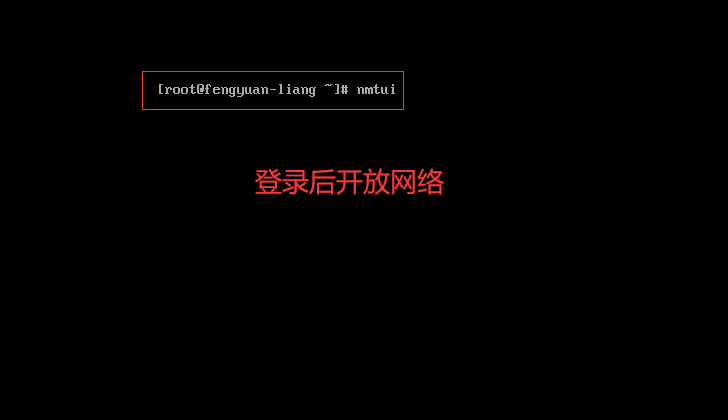
再在这个界面设置开放网络
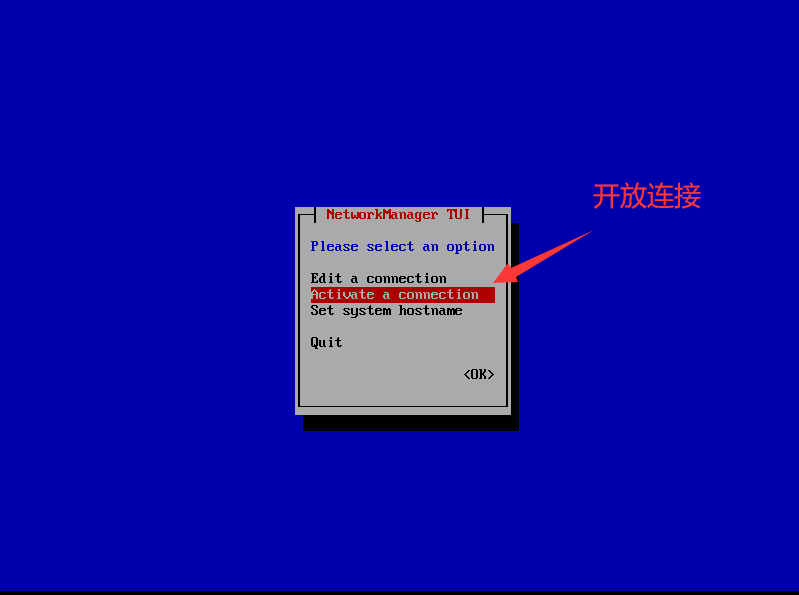
选择第二个
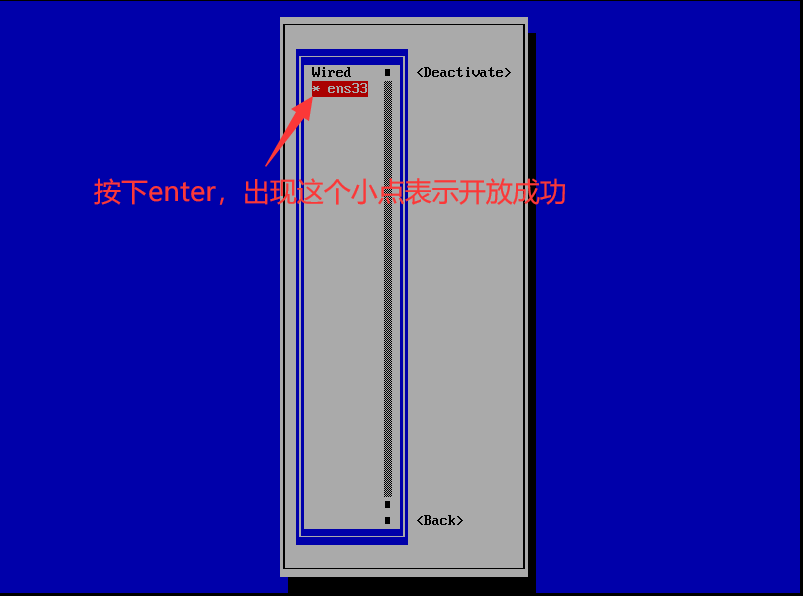
返回

退出
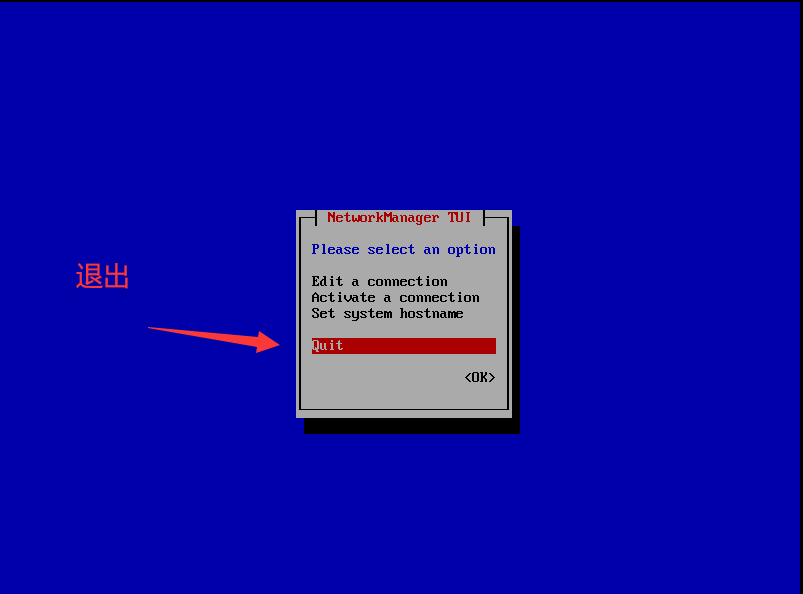
在root模式下敲入命令行
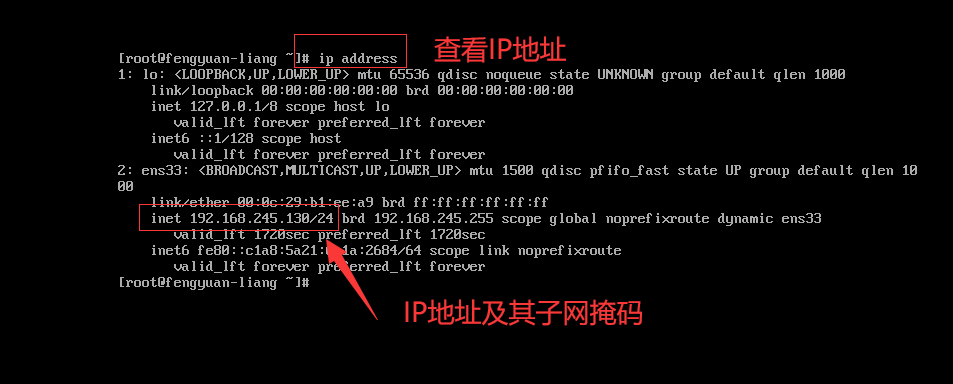
ip address查看开放的IP地址
用shell连接(这里选择finalshell,因为上传文件非常方便!!!)

2. 配置java环境
在Linux中安装jdk有两种方式:
- 第一种属于傻瓜式安装,一键安装即可(yum安装);
- 第二种手动安装,需要自己去Oracle官网下载需要的jdk版本,然后解压并配置环境,整个过程其实很简单
2.1 yum安装
第一种,这种办法简单粗暴,就像盖伦丢技能一样。废话不多说,直接开始操作
首先执行以下命令查看可安装的jdk版本:
yum -y list java*

选一个进行安装,一般选择1.8的版本,我这里选择java-1.8.0-openjdk-devel.x86_64的版本
yum install -y java-1.8.0-openjdk-devel.x86_64
然后就安装完了😁,是不是很简单
查看一下:
java -version

jdk会默认安装在/usr/lib/jvm目录下:

这种方式的优点就是异常简单,缺点就是我们不知道我们的jdk安装在哪里去了,很多Linux的细节我们无从得知,所以我们一般学习阶段建议尝试用第二种方式安装,其实也很简单滴!
但是这样安装没有配置JAVA_HOME,我们需要进一步配置,不然后面安装hadoop会报错
接下来就该配置环境变量了,输入以下指令进行配置:
vim /etc/profile
没有装vim的同学可以用vi /etc/profile,只是一个文本编辑器而已
打开后shift + G进入末尾,按i进入插入模式,在文件尾部添加如下信息:
JAVA_HOME的位置你要看自己的电脑情况,不要自己copy!
#set java environment
JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME CLASSPATH PATH
编辑完之后,保存并退出,然后输入以下指令,刷新环境配置使其生效:
source /etc/profile
2.2 上传安装包手动安装
手动安装的好处就是可以安装到想要安装的目录下,更能加深自己的体会和对Linux文件结构的理解
首先先上传我们下载好的安装包,用finalShell很方便,直接拖到对应目录里就好:

然后解压到我们想要放的文件夹,jdk目录需要自己手动创建,也可以叫java,名字自己随意取(见名知意),然后解压该压缩包,输入如下指令:
tar zxvf jdk-8u321-linux-x64.tar.gz
解压好后就能看到了:

接下来就该配置环境变量了,输入以下指令进行配置:
vim /etc/profile
没有装vim的同学可以用vi /etc/profile,只是一个文本编辑器而已
输入完毕并回车,在文件尾部添加如下信息:
export JAVA_HOME=你的安装包的位置,例如我的是:/root/fengyuan-liang/jdk1.8.0_321
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
编辑完之后,然后老规矩,按一下esc,输入:wq退出vi且保存,然后输入以下指令,刷新环境配置使其生效:
source /etc/profile
同样验证一下:
3. 安装单机版Hadoop
有了安装java的经验,那我们安装hadoop就可以很顺畅了
首先解压压缩包:
tar zxvf hadoop-2.10.1.tar.gz

然后需要检查一下hadoop看能不能用,我们先进入hadoop的目录:
cd hadoop-2.10.1
./bin/hadoop version

配置环境变量
vim /etc/profile,按i进入插入模式,在最后加上:
#HADOOP_HOME,我的是/root/fengyuan-liang/hadoop-2.10.1
export HADOOP_HOME=你的目录/hadoop-2.10.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
:wq保存并退出
刷新配置
source /etc/profile
查看一下
hadoop version

到此单机版hadoop安装完毕!
更换hadoop配置文件中JavaHome
配置成功了,但是有一点需要注意,在hadoop环境配置文件中需要将JAVA_HOME由原来${JAVA_HOME}换成具体路径,这样在集群环境中才不会出现问题
进入hadoop配置文件:
vim /你的目录/hadoop-2.10.1/etc/hadoop/hadoop-env.sh
shift + g到文件最后面,增加JAVA_HOME
export JAVA_HOME=/你的目录/jdk1.8.0_171

Hadoop目录结构
bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
4. 伪分布式安装
4.1 修改配置文件
前面安装教程和单机模式一模一样,但是需要修改一些配置文件
所有修改的文件都在:/你的目录/hadoop-2.10.1/etc/hadoop/ 下面,先进入目录!

修改core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<!--hadoopmaster是我的主机名,可以换成ip或localhost-->
<value>hdfs://localhost:9000</value>
</property>
<property>
<!--这个配置是将hadoop的临时目录改成自定义的目录下-->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.10.1/data/tmp</value>
</property>
</configuration>
修改hdfs-site.xml
对hdfs-site.xml进行同样的替换操作,属性的含义分别为复制的块的数量、DFS管理节点的本地存储路径、DFS数据节点的本地存储路径:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
格式化namenode
hdfs namenode -format

4.2 启动
切换到hadoop根目录下的sbin目录中
启动namenode
./hadoop-daemon.sh start namenode

查看namenode是否启动
查看namenode是否启动成功,需要使用jps查看进程:
有些Openjdk没有带上jps命令,可yum添加依赖:
先查看jdk版本:
rpm -qa|grep openjdk

如果是1.8直接盖伦放大招:
yum install -y java-1.8.0-openjdk-devel
安装好就查看一下:

启动datanode
./hadoop-daemon.sh start datanode

jps查看是否已经启动:

4.3 操作集群
在文件系统中建立一个创建用户目录input文件夹
我这里图方便直接用root用户登录了,如果你也是root用户就把user改为root或者你自己定义的其他用户
hadoop fs -mkdir -p /root/data/input
查看本地目录
hadoop fs -ls -R /

上传log.txt
将单机模式中的log.txt上传至Hadoop文件系统中input目录:
如果没有找到合适文件也可以创建一个文件 echo My Name is fengyuan-liang >/input/log.txt
这里的目录可以随意创建,没有必要在根目录下创建一个input目录,在哪里创建都可以,只要有这个文件就好了
这行命令也很简单 echo打印,>重定向,也就是把那句话打印到哪里去,/input/log.txt表示根目录下的input下的log.txt文件
我这里还是在根目录下创建了这个文件
先到根目录下:cd /
创建input目录:mkdir input
将这段文字输出到指定文件中,只要文件夹存在,文件会自动生成
echo My Name is fengyuan-liang >/input/log.txt

接下来就是把这个文件上传到我们的hadoop中了(含有hadoop的命令都要在hadoop根目录下的sbin目录中进行)
hadoop fs -put /input/log.txt /root/data/input/
查看一下
hadoop fs -ls -R /

测试
测试请切换到
hadoop-2.10.1的安装目录下进行,我的是:/root/fengyuan-liang/hadoop-2.10.1
使用和单机模式一样的测试
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount /root/data/input/ /root/data/output
输出一大段文字就表示成功了
查看结果:
hadoop fs -ls -R /

进入sbin目录并输出我们hadoop的输出
hadoop fs -cat /root/data/output/part-r-00000

至此伪分布模式搭建成功!
5 后记
熟悉Linux的同学应该知道在Linux中变量一般放在三个位置,在这三个位置里的所有变量在任何地方都可以访问到
/bin
/sbin
/usr/bin or sbin

其实都一样,我们发现我们现在每次操纵集群的时候都需要进入hadoop根目录下的sbin中,其实原因是我们只有在sbin目录下执行hadoop才能调用hadoop给我们提供的sh命令,如果我们想在其他地方调用,我们可以把添加一个环境变量,让我们可以在任意地方调用hadoop的命令
我们也可以通过type命令查看命令所在位置,例如我们常用的sh命令:

可以看到sh脚本都是放到usr/bin之下
那我们的hadoop的变量呢?

现在我们将其添加到环境变量中,ln -s 表示创建软连接,跟windows上面快捷方式一样
ln -s /root/fengyuan-liang/hadoop-2.10.1/bin/hadoop /usr/local/bin/

现在你就可以在任意文件夹下调用我们的hadoop的命令了
下一篇文章我们将探究如何用三台或者更多台Linux主机搭建真正意义上的分布式集群















 6265
6265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









