







前段时间老师布置了一个使用
java代码打印hadoop中DataNode里数据的作业,起初不太熟悉在Linux里Java导包的步骤,来来回回花了很多时间去试错,最后终于弄好了,写篇博客记录一下
我的目标是使用idea远程打印和在Linux中本地打印DataNode里面的数据:

首先我们要知道的是Hadoop其实提供了很多端口供我们访问,我们可以通过特定的端口管理Hadoop中的很多组件,例如NameNode、DataNode、NodeManager等等,具体要看你的配置文件,主要是这两个配置文件

其中就定义了一些默认的管理端口
管理界面:http://localhost:8088
NameNode界面:http://localhost:50070
HDFS NameNode界面:http://localhost:8042
我们也可以访问这些界面对我们的hadoop集群进行管理,我这里访问的是NameNode的管理界面

如果我们想要访问到DataNode里面的数据的话,我们可以访问
9000端口,这个配置在core-site.xml中可以找到
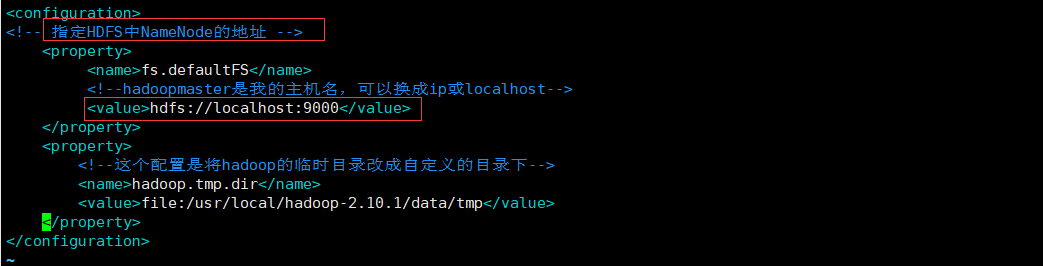
这里我们有两种方式来访问我们的结点数据,远程访问和本地访问
1. 使用idea远程访问
我们先创建一个Maven工程,导入以下依赖(注意要和自己的hadoop版本对应,我的是2版本):
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-it</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
接着编写代码:
package com.fx.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Arrays;
/**
* @author: eureka
* @date: 2022/4/27 12:06
* @Description: idea连接hadoop demo
*/
public class demo {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","root");//指定访问的用户
FileSystem fs = FileSystem.get(new URI("hdfs://你的公网ip:端口号"), new Configuration(),"root");
Path homeDirectory = fs.getHomeDirectory(); //获得hadoop的home目录
System.out.println(homeDirectory); //打印home目录
FileStatus[] fileStatuses = fs.listStatus(new Path("/root/data/input")); //拿到指定目录下的所有文件
System.out.println(Arrays.toString(fileStatuses)); //打印所有文件
Path path = new Path("/root/data/input/log.txt");
FSDataInputStream fsDataInputStream = fs.open(path);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
System.out.println("读取文件:"+path);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
bufferedReader.close();
fsDataInputStream.close();
}
}
这样执行通常会报一个错:
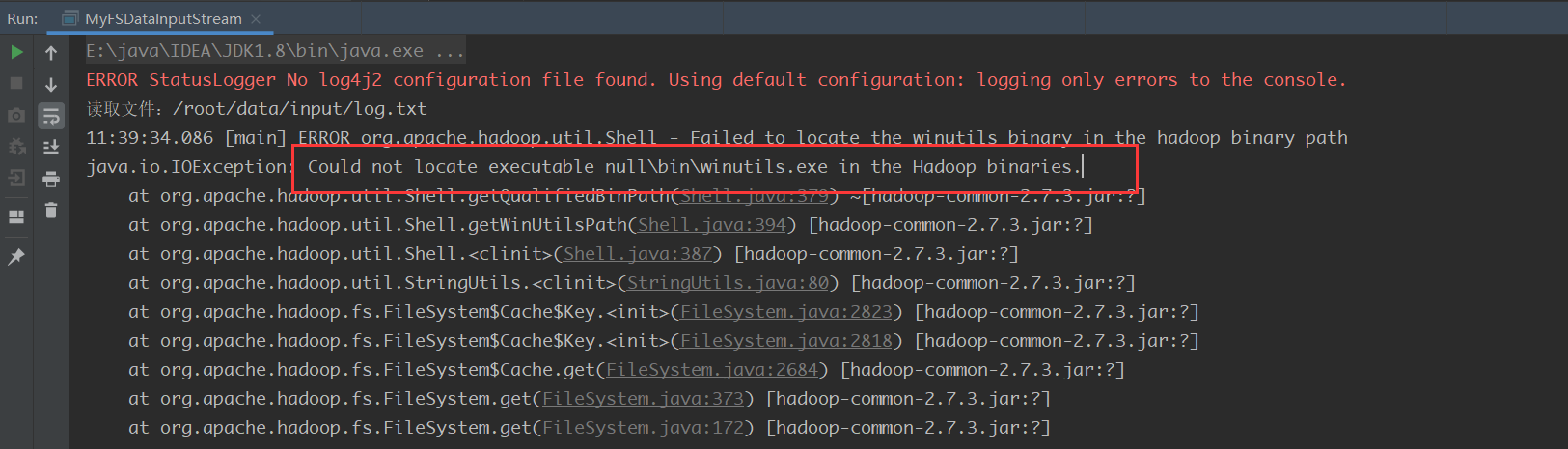
原因是缺少winutils.exe程序,我们需要在自己的电脑上安装一下这个插件
注意:winutils.exe的版本号一定要和使用的hadoop版本号保持一致!!!
现在我们来安装一下(两种方式)
- 未配置环境变量–>配置环境变量HADOOP_HOME,然后重启电脑。
- 或者代码中设置System.setProperty(“hadoop.home.dir”, “hadoop安装路径”)。
我这里采用方式二
System.setProperty("hadoop.home.dir","D:\\Environment\\Hadoop\\hadoop-common-2.2.0-bin-master\\bin");
所以需要在代码中添加这一行,完整代码为:
package com.fx.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Arrays;
/**
* @author: eureka
* @date: 2022/4/27 12:06
* @Description: TODO
*/
public class demo {
public static void main(String[] args) throws Exception {
System.setProperty("hadoop.home.dir","D:\\Environment\\Hadoop\\hadoop-common-2.2.0-bin-master");
System.setProperty("HADOOP_USER_NAME","root");
FileSystem fs = FileSystem.get(new URI("hdfs://你的ip:你的端口号"), new Configuration(),"root");
Path homeDirectory = fs.getHomeDirectory();
System.out.println(homeDirectory);
FileStatus[] fileStatuses = fs.listStatus(new Path("/root/data/input"));
System.out.println(Arrays .toString(fileStatuses));
Path path = new Path("/root/data/input/log.txt");
FSDataInputStream fsDataInputStream = fs.open(path);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
System.out.println("读取文件:"+path);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
bufferedReader.close();
fsDataInputStream.close();
}
}
运行结果:

2. 在Linux本地上执行Java脚本
在Linux执行Java程序要麻烦一些,因为没有IDE为我们自动导包,我们需要手动进行导包
在linux环境下使用命令行执行java程序时,如果要使用到大量外部的jar包或class文件,一般我们有两种方式进行导包:
-classpath,命令格式:# java -classpath ,使用";"分隔
-cp ,这个命令一看就是-classpath的缩写,当然用途是一样的。
-Djava.ext.dirs,命令格式:# java -Djava.ext.dirs= //多个路径用可以使用冒号分隔(windows下使用分号)分割
详细区别请看:https://blog.csdn.net/weixin_34441120/article/details/114517185
我们需要先在自己的本机上找到执行Java脚本所需的jar包
hadoop-2.10.1/share/hadoop/common
hadoop-2.10.1/share/hadoop/common/bin
hadoop-2.10.1/share/hadoop/hdfs
hadoop-2.10.1/share/hadoop/hdfs/bin
先建立demo.java文件
vim demo.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.Arrays;
/**
* @author: 梁峰源
* @date: 2022/4/27 12:06
* @Description: TODO
*/
public class demo {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","root");
FileSystem fs = FileSystem.get(new URI("hdfs://127.0.0.1:9000"), new Configuration(),"root");
Path homeDirectory = fs.getHomeDirectory(); //获得根文件夹
System.out.println(homeDirectory); //打印根文件夹
FileStatus[] fileStatuses = fs.listStatus(new Path("/root/data/input"));
System.out.println(Arrays.toString(fileStatuses)); //打印根文件夹下面的东西
Path path = new Path("/root/data/input/log.txt");
FSDataInputStream fsDataInputStream = fs.open(path);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
System.out.println("读取文件:"+path);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
bufferedReader.close();
fsDataInputStream.close();
}
}
保存退出
这里需要加载四个路径下的jar,用extCLassLoader加载器进行加载
/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common
/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/hdfs
/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common/lib
/usr/lib/jvm/jre-1.8.0-openjdk/lib //自己jdk的lib路径
你要找到自己的jar路径然后像我下面一下拼接起来
使用编译命令
javac -Djava.ext.dirs=/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common:/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/hdfs:/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common/lib:/usr/lib/jvm/jre-1.8.0-openjdk/lib demo.java

运行
java -Djava.ext.dirs=/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common:/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/hdfs:/root/fengyuan-liang/hadoop-2.10.1/share/hadoop/common/lib:/usr/lib/jvm/jre-1.8.0-openjdk/lib demo

大功告成!















 1158
1158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









