






关于SRv6基本原理的相关内容,可参考博客SRv6(BE)-原理介绍+报文解析+配置示例。
关于SRv6 TE原理的相关内容,可参考博客SRv6 TE Policy场景-原理浅谈及配置示例。
LFA FRR相关资料可参考:
- 关于LFA FRR基本原理的相关内容,可参考2008年发布RFC5286-Basic Specification for IP Fast Reroute: Loop-Free Alternates。
- 关于LFA FRR应用的相关内容,可参考2012年发布RFC6571-Loop-Free Alternate (LFA) Applicability in Service Provider (SP) Networks。
- 关于RLFA FRR基本原理的相关内容,可参考2015年发布RFC7490-Remote Loop-Free Alternate (LFA) Fast Reroute (FRR)。
- 关于TI-LFA FRR基本原理的相关内容,可参考Internet-Draft-Topology Independent Fast Reroute using Segment Routing。
- 关于增强型TI-LFA基本原理的相关内容,可参考Internet-Draft-Enhanced Topology Independent Loop-free Alternate Fast Re-route。
Flex-Algo相关资料可参考:
- 关于Flex-Algo基本原理的相关内容1,可参考Internet-Draft-Flexible Algorithms: Bandwidth, Delay, Metrics and Constraints。
- 关于Flex-Algo基本原理的相关内容2,可参考2023年发布的RFC9350-IGP Flexible Algorithm。
G-SRv6相关资料可参考:
- 关于G-SRv6基本原理的相关内容,可参考Internet-Draft-Generalized SRv6 Network Programming for SRv6 Compression。(目前该草案已被废弃。)
- 关于SRv6 SL压缩原理的相关内容,可参考Internet-Draft-Compressed SRv6 Segment List Encoding。(目前该草案于2023-10-23年更新G-SRv6为REPLACE-C-SID Flavor。)
网络切片相关资料可参考:
- 关于Network Slices基本框架的相关内容,可参考2024年发布的RFC9543-A Framework for Network Slices in Networks Built from IETF Technologies。(该文档先前的草案又名为Draft-ietf-teas-ietf-network-slices、Draft-ietf-teas-ietf-network-slice-framework、Draft-ietf-teas-ietf-network-slice-definition、draft-nsdt-teas-ietf-network-slice-definition、Draft-nsdt-teas-ns-framework和Draft-nsdt-teas-transport-slice-definition等。)
- 关于BGP下发SRv6 Policy属性的相关内容,可参考Internet-Draft-Advertising Segment Routing Policies in BGP。
- 关于BGP SRv6 Policy属性中的网络切片,可参考Internet-Draft-BGP SR Policy Extensions for Network Resource Partition。
- 关于数据面携带Slice ID的HBH方案,可参考Internet-Draft-Carrying Network Resource (NR) related Information in IPv6 Extension Header。
- 关于数据面携带Slice ID的源地址方案,可参考Internet-Draft-Encoding Network Slice Identification for SRv6。
- 关于网络切片方案的其他实现方式,可参考Internet-Draft-Stateless and Scalable Network Slice Identification for SRv6。
- 关于IP/MPLS网络中切片的实现方式,可参考Internet-Draft-Realizing Network Slices in IP/MPLS Networks。
…
SRv6存在大量相关RFC及其他文档,感兴趣者可查阅相关资料。
本文的主要目的在于记录和学习SRv6的基本内容,详细内容可查阅相关资料。并且鉴于个人能力限制和SRv6技术仍在持续发展的因素,因此难免有纰漏之处。敬请各位专家不吝指导。
参考资料存在实时更新,引用不当烦请理解。
第2和第3章节具体描述了SRv6的相关内容,有基础者可直接对相关内容进行指教。
目录
SRv6扩展阅读:故障保护LFA+G-SRv6+Flex-Algo+网络切片
1.故障保护Fast ReRoute
1.1.背景介绍
传统IGP协议通过各自产生和泛洪相应的链路状态,(在一定范围内)维护相同的LSDB。一旦网络中链路状态发生改变,节点将重新通告链路状态。IGP域将重新进行一次网络拓扑的收敛。
然而IGP的收敛往往取决于设备硬件的相应处理速度,更不用提IGP协议对相应链路状态处理上的限制。比如,OSPFv2的默认Hello时间为10s,也即一旦节点宕机网络最晚可感知10s,更不用说RFC2328中还为OSPFv2的LSA的重传定义了定时器。并且控制面收敛完成下发转发面也需要一定时间。一旦IGP网络因链路等问题而未收敛完成,此时不可避免的就是产生流量中断。这对流量损失非常敏感的业务是不可接收的。
基于以上考虑,提出了Fast ReRoute(FRR,快速重路由)机制主要用于解决由于链路故障导致收敛期间发生的故障丢包。
FRR的基本思想在于,在正常路由转发的基础上,计算额外的备份保护路径放入转发面。一旦感知链路问题,可不经控制面收敛完成,优先走转发面的FRR备份路径转发。待控制面重新收敛完成后,依照控制面下发给转发面的路径进行转发。最大程度上减少流量丢失。
相似的,STP/RSTP/MSTP生成树协议在收到TC报文时会将接口MAC/ARP表项进行清除。这种机制也是为了防止在生成树未收敛完成时导致的拓扑环路。
FRR通常可分为IP FRR、LDP FRR、TE FRR、VPN FRR和PE FRR等。
这里着重介绍IP FRR的三种技术:
LFA:Loop-Free Alternates,无环备份。
RLFA:Remote Loop-Free Alternate,远程无环备份。
TI-LFA:Topology-Independent Loop-free Alternate,拓扑独立无环备份。
1.2.三种IP FRR
在介绍 IP FRR 之前,应当说明的是全网网络是一个稳定状态,并且节点之间已经形成了 LSDB 的同步。否则形成的 IP FRR 是没有意义的。
这里要求形成 LSDB 的同步,是因为计算节点应当能依据同步的 LSDB 计算出邻居节点的 SPF 路径。因为邻居节点/备份路径的下一跳在故障发生的瞬时状态是无法感知的,需要邻居同步相应的状态信息才可感知到。
计算节点需要保证将流量导向邻居节点/备份路径时,邻居节点/备份路径不会将相应的流量在重新发给计算节点。这就需要计算节点能够根据 LSDB 以不同节点(包括邻居节点/备份路径等)作为根节点计算SPF,从而保证路径无环。
换句话说,需要计算节点不仅需要知道自己本身流程的转发路径,还需要知道流量转发到邻居节点/备份节点后的路径。从而确保流量不会发回自身。
理解这一点非常重要。
1.2.1.LFA
LFA 也即 Loop-Free Alternates 具有两种保护场景:链路保护和节点保护。
链路保护:
要求存在计算节点(以 S/PLR 标识:源节点或者 Point of Local Repair 本地修复节点)的邻居节点/备份下一跳(以 N 标识)到目的节点(以 D 标识)的 SPF 最短路径不经过被保护链路。
其数学表达为:公式1
D i s t a n c e _ o p t ( N , D ) < D i s t a n c e _ o p t ( N , S ) + D i s t a n c e _ o p t ( S , D ) Distance\_opt(N, D) < Distance\_opt(N, S) + Distance\_opt(S, D) Distance_opt(N,D)<Distance_opt(N,S)+Distance_opt(S,D)
也即邻居到流量目的地址的开销,小于邻居计算的将流量绕回至计算节点S之后走向目的地址的开销。
自动换行
或者可表示为:
Distance_opt(N, D) < Distance_opt(N, PLR) + Distance_opt(PLR, D)
 考虑上图场景,则为:
考虑上图场景,则为:
N_1 可以作为 S/PLR 节点的邻居节点/备份下一跳,用于 S—>E 链路保护。
这里需要注意的是:
- 保护链路的方向性。因为链路的开销计算是具有方向性的。链路来回的开销有可能不一致,虽然往往一致。
- S节点不一定指的是源节点,而是指的是计算节点。通常需要LFA的都是链路上的中间节点。
- 在某些场景下有更严格的约束:Distance_opt(N, D) < Distance_opt(S, D)。
自动换行
节点保护:
要求存在计算节点(以 S/PLR 标识:源节点或者 Point of Local Repair 本地修复节点)的邻居节点/备份下一跳(以 N 标识)到目的节点(以 D 标识)的 SPF 最短路径不经过被不经过故障节点(以E标识)。
其数学表达为:公式2
D i s t a n c e _ o p t ( N , D ) < D i s t a n c e _ o p t ( N , E ) + D i s t a n c e _ o p t ( E , D ) Distance\_opt(N, D) < Distance\_opt(N, E) + Distance\_opt(E, D) Distance_opt(N,D)<Distance_opt(N,E)+Distance_opt(E,D)
也即邻居节点/备份下一跳到目的地址的开销,小于邻居计算的将流量绕回至计算节点之后走向目的地址的开销。
 考虑上图场景,则为:
考虑上图场景,则为:
N_1 可以作为 S/PLR 节点的邻居节点/备份下一跳,用于 E节点 的节点保护。
但就给出的场景和拓扑来看,链路保护和节点保护非常相似。
Q:那么两者的区别在哪里,公式定义上差别的作用是?
A:链路保护允许邻居计算的下一跳经过故障节点(故障节点的链路发生故障,而节点本身可能未发生故障)。而节点保护不允许经过故障节点。
//如上图所示,S/PLR—>E故障链路时,邻居节点允许其经过E节点。但是E节点本身如果故障,上述场景将无法执行S/PLR对E的节点保护。
自动换行
广播型链路上的LFA:
如果主下一跳使用广播链路,则备用链路应相对于该链路的伪节点(PN)无环路,以提供链路保护。
其数学表达为:公式3
D i s t a n c e _ o p t ( N , D ) < D i s t a n c e _ o p t ( N , P N ) + D i s t a n c e _ o p t ( P N , D ) Distance\_opt(N, D) < Distance\_opt(N, PN) + Distance\_opt(PN, D) Distance_opt(N,D)<Distance_opt(N,PN)+Distance_opt(PN,D)
这一要求的目的在于:
- 要获得链路保护,来自所选备用下一跃点的路径必须不遍历感兴趣的链路,并且从 S 用于到达该备用下一跃点的链路必须不是感兴趣的链路。
- 要使 N 提供链路保护,首先必须确保 N 到 D 的最短路径不遍历伪节点 PN。 其次,S 选择的备用下一跃点必须不遍历 PN。
 考虑上图场景,则为:
考虑上图场景,则为:
N_1 可以作为 PN 广播网的邻居节点/备份下一跳,用于 PN广播网 的广播保护。
此外RFC5286在OSPF网络中应用时给出了如下提醒*:
@:不建议在配置了虚链路的情况下对骨干区域配置LFA。而对非骨干区域无此限制。
@:对具有多个备份ABR的域间路由不应当使用LFA。
@:不建议对特定非骨干域的Type-4 ASBR路由和Type-5 AS-External路由使用LFA。该特定非骨干域存在两个以上的ABR,其中一个兼具ASBR角色,另一个ABR也作为其他非骨干域的ABR存在。
@:不建议对不同非骨干域通告相同external metric的ASBR的特定网络配置LFA。该特定网络的不同ASBR具有相同的ABR。
自动换行
相应的在ISIS网络中应用时给出了如下提醒:
@:不应当选择具有过载标识的IS作为可用的邻居节点/备选路径。
@:对于携带Link-Attributes Sub-TLV等特定TLV时,路由器不应由于具有 LFA 而指定“本地保护可用”标志。
@:邻居节点/备份下一跳链路已通告为“从本地保护路径中排除的链路”或属性“需要本地维护”,不应使用其作为备份下一跳。
对于ECMP场景和SRLG等其他详细内容,可查阅相关资料。并且注意以上公式是不允许等式存在的,以防止可能的环路。
1.2.2.RLFA及PQ空间
在上一个章节,我们介绍了 LFA 的使用原理及其场景,并且可以发现 LFA 的使用是受到网络结构的限制的。并且链路上的开销也会影响 LFA 的使用。
例如在下图场景,LFA 无法提供相应的保护。
场景1@无法提供 S—>P4 链路保护:自动换行
场景2@无法提供 E 节点保护。:
故障无法收敛。
因此提出了 RLFA(Remote Loop-Free Alternate,远端无环备份)的概念。在 RLFA 中提出 P 空间和 Q 空间的概念,将 LFA 节点的计算范围扩大到了远端节点而不仅限于邻居节点,从而提高了 LFA 计算的成功概率。
RFC7490定义的RLFA中引入如下概念:
P-Space:计算节点(以 S/PLR 标识:源节点或者 Point of Local Repair 本地修复节点)使用预收敛最短路径从该特定路由器访问的路由器集。该预收敛最短路径(包括等价路径拆分)不应当通过该受保护链路或受保护节点。
P空间的数学表达为:公式4
D i s t a n c e _ o p t ( S , P ) < D i s t a n c e _ o p t ( S , E ) + D i s t a n c e _ o p t ( E , P ) Distance\_opt(S, P) < Distance\_opt(S, E) + Distance\_opt(E, P) Distance_opt(S,P)<Distance_opt(S,E)+Distance_opt(E,P)
该公式的含义为自己到 P 节点的 SPF 路径不经过受保护链路或受保护节点。
Extended P-space:计算节点(以 S/PLR 标识:源节点或者 Point of Local Repair 本地修复节点)的直连下一跳节点使用预收敛最短路径从该特定路由器访问的路由器集。该预收敛最短路径(包括等价路径拆分)不应当通过该受保护链路或受保护节点。
Pe空间的数学表达为:公式5
D i s t a n c e _ o p t ( N , P ) < D i s t a n c e _ o p t ( N , E ) + D i s t a n c e _ o p t ( E , P ) Distance\_opt(N, P) < Distance\_opt(N, E) + Distance\_opt(E, P) Distance_opt(N,P)<Distance_opt(N,E)+Distance_opt(E,P)
该公式的含义为自己的直连下一跳到 P 节点的 SPF 路径不经过受保护链路或受保护节点。
Q-space:对于被保护链路的 Q 空间是任何使用预收敛最短路径不通过该受保护链路的路由器集。
Q空间的数学表达为:公式6
D i s t a n c e _ o p t ( Q , D ) < D i s t a n c e _ o p t ( Q , E ) + D i s t a n c e _ o p t ( E , D ) Distance\_opt(Q, D) < Distance\_opt(Q, E) + Distance\_opt(E, D) Distance_opt(Q,D)<Distance_opt(Q,E)+Distance_opt(E,D)
该公式的含义为 Q 节点到目标节点的SPF路径不经过受保护链路或受保护节点。
PQ node:节点 S 对保护链路 S-E 的 PQ 节点是 S 的 P 空间(或扩展 P 空间)相对于该受保护链路 S-E 和 E 的 Q 空间(相对于该受保护链路 S-E)的成员交集。
简而言之 RLFA 的相关概念可以总结如下:
P空间:以计算节点(以 S/PLR 标识:源节点或者 Point of Local Repair 本地修复节点)为根,计算不经过被保护链路 S—>E 或被保护节点 E 到达其他节点的最短路径路由器集。如果这个定义中的其他节点取为目的节点,并且存在这样的 P 节点,那么此时形成的就是上一章节提到的 LFA 保护。
扩展P空间:以计算节点(以 S/PLR 标识:源节点或者 Point of Local Repair 本地修复节点)的直连下一跳为根,计算不经过被保护链路 S—>E 或被保护节点 E 到达其他节点的最短路径路由器集。扩展 P 空间用于防止不存在 PQ 节点的情况。
Q空间:应当以其他节点 为根,计算不经过被保护链路 S—>E 或被保护节点 E 到达到目的节点 D 的最短路径路由器集。
PQ node:P/Pe 空间和 Q 空间的交集。
需要说明的是上述情况的计算仍然都是由 S/PLR 节点计算而来。以便 S/PLR 节点将报文转发至 PQ 节点时不会造成环路。这也是要求 LSDB 已全局同步的原因。
自动换行
Q:为什么扩展空间要求的是 S/PLR 节点的直连下一跳?
A:在详细解释这一点之前,需要明确。
对于 LFA: 其工作原理在于 S/PLR 将流量不经修改的向自己计算得到的以 S/PLR 为根计算的下一跳转发。下一跳收到后可直接依照目的地址进行转发,后续转发的最短路径树必然不途径故障链路。
对于普通的 RLFA: 其工作原理在于 S/PLR 将流量添加隧道信息后向自己计算以 S/PLR 为根计算到达 PQ 节点的下一跳转发。流量经隧道到达 PQ 节点。PQ 节点收到后剥离隧道信息可直接依照流量原始目的地址进行转发,后续转发的最短路径树必然不途径故障链路。
对需扩展的 RLFA:在普通的 RLFA下没有 PQ 节点,其实意味着不存在这样一个中间节点同时满足
- S/PLR 到中间节点的最短路径树不途径故障链路/故障节点。
- 从中间节点到目标节点的最短路径树不途径故障链路/故障节点。
自动换行
扩展 P 空间/扩展的 RLFA 的解决办法是由自己的直连下一跳来承担这一功能找寻 PQ 节点。随后自己的直连下一跳按普通的 RLFA 执行。而自己到直连下一跳必然是路径无环的。相比于选择其他非直连下一跳,这样操作较为简单功能程序处理可以不用考虑其他复杂情况。
1@LFA 无法链路保护,RLFA 可以保护 P1—>P4 链路的场景:S/PLR 节点计算得到:
P空间/扩展P空间:[PE1,P1 ,P2,P3];
Q空间:[PE2,P4,P3];
PQ节点:[P3]。
因此在链路故障时,S/PLR 节点将流量导向 P3 节点。待 IGP 收敛完成后重新导向收敛完成的下一跳节点。
2@LFA无法节点保护,RLFA可以保护 E 节点的场景:
S/PLR 节点计算得到:
P空间/扩展P空间:[PE2,P4,P3];
Q空间:[P3];
PQ节点:[P3]。
因此在 E 节点故障时,S/PLR节点将流量导向 P3 节点。待 IGP 收敛完成后重新导向相应节点。
3@无 P 空间但有扩展 P 空间的场景:
该场景下 P2 可作为 P 节点,P3 可作为 Q 节点。则无 PQ 节点。
需要扩展 P 空间,则有 P3 节点作为 P 节点最终 P3作为 PQ 节点。
计算出 PQ 节点后,RLFA 的转发:
本质是在计算节点 S/PLR 和 PQ 节点之间建立隧道。
由于计算节点 S/PLR 和 PQ 节点之间往往是非直连下一跳,如果计算节点 S/PLR 单纯将流量导向去往 PQ 节点的下一跳时必定发生流量丢弃。
此时计算节点 S/PLR 和 PQ 节点建立 Target LDP 或者 Remote LDP 邻居关系,报文中嵌套相应的隧道协议。
如果源节点至目标节点之间本身位于 IP/MPLS LDP 隧道中,计算节点 S/PLR 和 PQ 节点的TLDP或RLDP还需要传递相应 PQ 节点发向目标节点的Label。否则由于PQ节点收到相应流量后,无法识别相应的标签造成流量丢弃。
这是由于传统的LDP分配的标签通常仅具有本地意义或者一跳之内的可识别性。如果可以全局获取相应的Label,计算节点 S/PLR 则可以之间建立相应的流量转发指导。
这也是RLFA的缺陷所在,扩展性差(LDP需要保证Label的连续性)并且引入了额外的保护隧道状态。
1.2.3.TI-LFA及中间节点保护
传统的 LFA/RLFA 都是基于 IGP 开销进行选择。相比于 LFA,RLFA 将选择的备份下一跳从邻居节点扩展到了远端节点。即使功能已经非常强大,但是在某些场景下无法计算 PQ 节点也就无法进行备份路径选择。
扩展 P 空间后仍无 PQ 节点可进行链路保护:
自动换行
无 PQ 节点可进行节点保护:基于 IGP 开销的 LFA 无法选择备份下一跳。
因此基于 SR 思想提出了 Topology-Independent Loop-free Alternate 拓扑独立的无环备份。TI-LFA 继承了 RLFA 的相关概念,但 TI-LFA 可以具有 100% 的网络保护,并且可以避免次优路径。TI-LFA基本原理为计算节点(以 S/PLR 标识:源节点或者 Point of Local Repair 本地修复节点)封装额外的 SID 信息强制将其向备份下一跳进行转发。
LFA/RLFA的次优路径问题:
LFA/RLFA 计算得到备份邻居下一跳节点和远端 PQ 下一跳节点往往都是计算节点 S/PLR 根据 LSDB 以非下一跳为根计算得到的。而故障收敛后的流量下一跳是以自己为根计算得到的。因此备份下一跳节点和故障后收敛到的下一跳节点很有可能非同一个节点。
在这种情况下,往往意味着计算的备份节点是次优路径。
1@对于 LFA 场景使用 TI-LFA:
此时备份节点必定是邻居下一跳,并且该备份下一跳可直接转发流量。此时计算节点 S/PLR 可直接将流量转发给邻居下一跳,邻居节点可依照自身 IGP 得到的转发面将流量导向正确的目标节点。
2@无需扩展 P 空间的 RLFA 场景使用 TI-LFA:
由于备份下一跳为PQ节点且不是直连下一跳,无法直接导通流量。此时需计算节点 S/PLR 将流量导向 PQ 节点。
基于SRv6网络平面的计算节点 S/PLR 可进行如下操作:
1@在IPv6 的 SRH 中插入指向 PQ 空间的 SID。
这里的SID可选择PQ空间的End SID,或者可以选择路径上到直连PQ空间的End.X SID。两者的区别在SID的处理方式不同。此外还可结合相应的Flavor行为进行相应处理。
2@将原有数据流作为 Payload,重新封装一层 IPv6头 部。目的IPv6选择相应的 PQ 空间 SID。
此外也可以选择插入SRH进行相应操作。
3@所需扩展 P 空间保护 A—>D 链路的 RLFA 场景使用 TI-LFA:
 经计算只有 C 节点可作为扩展 P 空间后的 PQ 节点。此时 A 节点不能直接将流量导向 C 节点,需要在 A 节点上封装由 TI-LFA 计算指向 C 节点的额外隧道进行流量转发指导。
经计算只有 C 节点可作为扩展 P 空间后的 PQ 节点。此时 A 节点不能直接将流量导向 C 节点,需要在 A 节点上封装由 TI-LFA 计算指向 C 节点的额外隧道进行流量转发指导。
display isis srv6 ti-lfa-node 可查看针对目的节点形成的 P 节点、Q 节点以及从 P 节点到 Q 节点的 SID 标签栈。
4@RLFA 不满足,但可使用 TI-LFA 进行保护的场景:
 如上图所示,TI-LFA 应当指导流量先后导向 P 空间节点和 Q 空间节点。也即在 P1 节点上首先沿邻接 SID 到达 P2 节点(或者经 P2 节点的节点 SID 到达 P2 节点),随后沿 P 空间节点和 Q 空间节点之间的邻接 SID 到达 P3 节点。
如上图所示,TI-LFA 应当指导流量先后导向 P 空间节点和 Q 空间节点。也即在 P1 节点上首先沿邻接 SID 到达 P2 节点(或者经 P2 节点的节点 SID 到达 P2 节点),随后沿 P 空间节点和 Q 空间节点之间的邻接 SID 到达 P3 节点。
上述图示展示了新增一个 SRH 插入了 2 个 SID 的转发实例。该 SRH 包含的 SID 也可称为 Repair List。
还可采用双SRH的方式进行相应转发。在到达相应节点后,进行第一层SRH的剥离。
自动换行
TI-LFA 的相应原则:
@:SRLG(Share Risk Link Group)链路 > 节点保护 > 链路保护。
SRLG类似于Uplink/monitor-link,在进行相应计算时对同一个链路组内的链路具有相同的判断原则。详细内容可查阅相关资料。
@:对于有约束路径的场景的情况,TI-LFA 可能存在失效情况。此时需要进行 Midpoint 中间节点保护。
Midpoint中间节点保护:
在 SRv6 Policy 场景指定严格节点束路径转发时,如果严格节点故障则会 TI-LFA FRR 保护失效问题。TI-LFA 根据报文目的地址计算出的备份下一跳可能仍然经过故障节点。此时需要由中间严格节点(Midpoint)的上游节点代替它完成这个转发处理,这个上游节点称之为代理转发(Proxy Forwarding)节点。
其触发事件为:代理转发节点感知到报文的下一跳接口故障,并且下一跳是报文目的地址,SL > 0。
处理动作为:代理转发节点代替中间节点执行 End 行为。将 SL - 1,并将下层要处理的 SID 更新到外层 IPv6 报文头,然后按照下层 SID 的指令进行转发。从而绕过故障节点,实现 SRv6 中间节点故障的保护。
例如在上图中有 A 节点发向 F 节点的严格路径[e,f]。
- 当 E 节点故障后,代理转发节点 B 感知到故障触发 Midpoint 中间节点保护,并将下一个 SID 填充到 DIP 中进行转发。
- 此时 B 节点发现 SL = 0,可以去掉 SRH 扩展报文头进行 Native IPv6 转发。
- 针对下一个 SID = f 或者说针对 DIPv6,触发 TI-LFA 保护进行备份下一跳计算。新增1个 SRH 扩展报文头,经过备份路径转发到 F 节点。
其原理与MPLS TE FRR通过Bypass LSP绕过故障点比较类似,所以有时也被称为SRv6 TE FRR。自动换行
自动换行
发生Mindpoint的场景:
- FIB查询没有命中,触发FIB-MISS。
- 报文IPv6目的地址为本地接口的地址且出端口Down, TI-LFA FRR也不是Node保护时。
- 本地SID表命中为End.X SID且出端口Down时。
- 从路由表中查到的路由为NULL0路由时。
自动换行
需要注意的是进行Midpoint保护功能的节点应当是Segment List中的上游设备。
1.2.4.防微环
前文我们介绍了 IP FRR 主要用于解决全网设备 IGP 收敛时间的差异导致网络中发生短时流量中断的场景。但是仍然很有可能 S/PLR(Ponit of Local Repair)节点已经完成 IGP 的收敛,而其他节点还未完成收敛。此时就会发生相应的环路问题。
基于以上场景,TI-LFA 另有防微环方案:正切防微环和回切防微环。
正切防微环:
本端正切防微环:PE1—>PE2
 如上图所示,在P1—P3链路故障时,计算节点 S/PLR 节点无法得到PQ节点。在应用了TI-LFA之后,计算节点 S/PLR 节点将插入相应2段SID将以此流量依次转发给P2,P4,P3和PE2。计算节点 S/PLR 节点自身收敛完成后,不在进行SID插入或封装隧道。此时P2如果未感知 P1—P3 链路故障,将在 P1—P2 之间发生流量短时微环。
如上图所示,在P1—P3链路故障时,计算节点 S/PLR 节点无法得到PQ节点。在应用了TI-LFA之后,计算节点 S/PLR 节点将插入相应2段SID将以此流量依次转发给P2,P4,P3和PE2。计算节点 S/PLR 节点自身收敛完成后,不在进行SID插入或封装隧道。此时P2如果未感知 P1—P3 链路故障,将在 P1—P2 之间发生流量短时微环。
基本逻辑为:
- 正常转发。
- P1—P3 链路故障,触发 P1/PLR 节点的TI-LFA备份路径。流量经P2,P4,P3和PE2到达目的节点。
- P1/PLR 节点优先收敛完成,走转发面下发的路径信息。流量导向P2。
- P2 节点如果未感知故障未收敛完成,此时P2 节点认为到达PE2的最优路径为 P1—>P3—>PE2。
- 最终流量在 P1—P2 之间发生环路。
解决办法:在PLR节点启用定时器,确保网络收敛完成后在撤销TI-LFA的备份路径。
远端正切防微环:PE1—>PE2
 如上图所示,在P2—P4链路故障时,计算节点 S/PLR 节点无法得到PQ节点。在应用了TI-LFA之后,计算节点 S/PLR 节点将插入相应2段SID将以此流量依次转发给P,P1,P3和PE2。计算节点 S/PLR 节点自身收敛完成后,不在进行SID插入或封装隧道。此时P如果优先P1感知 P2—P4 链路故障,将在 P1—P 之间发生流量短时微环。
如上图所示,在P2—P4链路故障时,计算节点 S/PLR 节点无法得到PQ节点。在应用了TI-LFA之后,计算节点 S/PLR 节点将插入相应2段SID将以此流量依次转发给P,P1,P3和PE2。计算节点 S/PLR 节点自身收敛完成后,不在进行SID插入或封装隧道。此时P如果优先P1感知 P2—P4 链路故障,将在 P1—P 之间发生流量短时微环。
基本逻辑为:
- 正常转发。
- P2—P4 链路故障,触发 P2/PLR 节点的TI-LFA备份路径。流量经P,P1,P3和PE2到达目的节点。
- P 节点优先P1收敛完成,P 节点认为到达PE2的最优路径为 P1—>P3—>PE2。
- P1 节点如果未感知故障未收敛完成,此时P2 节点认为到达PE2的最优路径为 P1—>P3—>PE2。
- 最终流量在 P1—P 之间发生环路。
解决办法:由于此时流量不经过 P2/PLR 节点,则此时TI-LFA备份路径完全无法生效导致环路。在P节点开启定时器插入了防微环Segment List <P3,P1>,所以消除了网络中潜在的环路。
防微环Segment List也可选择 P3—P1 的End.X SID。
回切防微环:相似的在故障恢复时也可能产生环路。
本端正切防微环:PE1—>PE2
本端回切防微环的逻辑在于其他节点优于PLR收敛导致环路,也即 P2 节点优于 P1/PLR 节点收敛导致流量在 P1—P2 上的环路。
解决办法:由于回切不会进入 P1/PLR 节点的 TI-LFA 转发流程,所以无法像正切一样使用延时收敛的方式解决回切微环问题。可通过在P2节点开启定时器插入了防微环Segment List <P3,P1>,消除了网络中潜在的环路。
远端正切防微环:PE1—>PE2
远端回切防微环的逻辑在于如果离故障点更远的节点先于离故障点近的节点收敛,就可能会导致环路,也即 P1节点优于 P 节点收敛导致流量在 P1—P 上的环路。
解决办法:可通过在P1节点开启定时器插入了防微环Segment List <P4,P2>,消除了网络中潜在的环路。
1.3.IP FRR的实现
 //ipv6 avoid-microloop segment-routing rib-update-delay:在ISIS视图下配置SRv6场景IS-IS路由的延迟下发时间。
//ipv6 avoid-microloop segment-routing rib-update-delay:在ISIS视图下配置SRv6场景IS-IS路由的延迟下发时间。
需要提前开启ipv6 avoid-microloop segment-routing防微环功能,在IGP收敛期间,头节点严格按照显式路径转发流量,转发过程不依赖于各设备的IGP收敛,可以避免各设备的IGP收敛,可以避免环路产生。
 //loop-free-alternate level-2ti-lfa命令配置的Level依赖loop-free-alternate命令配置的Level,即只有LFA使能了相应的Level,ti-lfa才可能在指定Level生效,否则配置不成功。
//loop-free-alternate level-2ti-lfa命令配置的Level依赖loop-free-alternate命令配置的Level,即只有LFA使能了相应的Level,ti-lfa才可能在指定Level生效,否则配置不成功。
2.SRH压缩之G-SRv6/C-SID
2.1.背景介绍
SRv6使用128bits的IPv6地址作为SID填充在SL中,如果SRH需要封装的SID较多,则会使得SRv6报文头明显增大。
携带过多的SID有如下后果:
@:数据包携带有效载荷量下降。在给定数据包长度的前提下,包头越长可携带的有效数据就越短。这是由于客观上IPv6/SID的长度所决定的。
@:老旧设备兼容问题。SRv6报文头开销过大带来的第二个问题是SID栈太深。在博客SRv6(BE)-原理介绍+报文解析+配置示例中我们提出目前设备对SRH扩展头中的SL处理是有限制,一大限制因素是芯片本身处理能力的限制。因此某些节点在处理携带过多的SID的SRH时,可能无法处理造成流量黑洞。
@:MTU超限风险较大。报文头增大,可能导致MTU(Maximum Transmission Unit,最大传输单元)超限。通常只有IPv6源节点和目的节点才会解析IPv6扩展头部,所以只有IPv6源节点始发IPv6报文时才会进行IPv6 MTU分片,中间节点转发IPv6报文时不进行IPv6 MTU分片。当IPv6报文长度大于出接口IPv6 MTU时,设备会丢弃报文,并进行Path MTU发现。SRv6使用IPv6作为数据平面协议,MTU问题对SRv6的影响较大
即使有Binding SID可以进行SL的交换,但是数据报文仍然可能较大。因此,提出了G-SRv6(Generalized Segment Routing over IPv6,通用SRv6)技术以解决SRv6报文头开销过大的问题。
目前G-SRv6方案已在《Internet-Draft-Compressed SRv6 Segment List Encoding》草案中融合为C-SID(Compressed-SID)方案。在 C-SID 方案中,新定义了两种 flavors:NEXT-C-SID 和 REPLACE-C-SID。每种 C-SID 都可用于指导 End, End.X, End.T, End.B6.Encaps, End.B6.Encaps.Red, 和 End.BM 行为转发。
NEXT-C-SID flavors 和 REPLACE-C-SID flavors 都利用 SID Argument 来确定如何处理下一个 segment,但采用不同的 Segment List 压缩方案。
- NEXT-C-SID flavors 表示所处理的每一个 C-SID container 为完整的 SRv6 SID。其中包含了 C-SID 集合中所有 C-SID container 公共的 Locator-Block,并且其 Argument 携带后续 C-SIDs 信息。
- REPLACE-C-SID flavors 表示仅有第一个 C-SID 中的元素为完整的 SRv6 SID。其中包含了 C-SID 集合中所有 C-SID container 公共的 Locator-Block,并且 C-SID 集合的其余元素不在携带公共的 Locator-Block。
后文介绍的 G-SRv6 也即 REPLACE-C-SID flavors。
2.2.设计思想
为了解决上述问题,G-SRv6需要兼容现有SRv6环境包括支持SRH以及相应的Behavior。并且需要考虑方案的可扩展性和字节对齐等因素。目前主流的方式是进行32-bits的SID压缩方案。这一考虑是压缩效率和兼容性综合考虑的结果。
方案逻辑:
通常我们指定的SID由三部分组成:Locator+Function+Arg。其中Arg为增强功能可选参数,使用较少。Function为自定义设置,不具备压缩适用性。Locator虽然基于节点进行分配,但通常其部分前缀具有相同属性。因此可以将SID中Locator中相同的部分进行压缩。
在某些时候有可进行上图细分:Locator=Block和Node ID。Block是区域的Common Prefix公共前缀,Node ID是相应的节点标识。
《Internet-Draft-Compressed SRv6 Segment List Encoding》草案将其分别定义为 Locator-Block 和 Locator-Node。
自动换行
比如,我们通常可以为PE1分配2001:DB8:1:1::/64,P分配2001:DB8:2:2::/64,PE2分配2001:DB8:3:3::/64。其中有Common Prefix公共前缀2001:DB8::/32。
//SL栈深为6的SRH进行32-bit压缩示例。这里的G-SID指的就是G-SRv6压缩后的SID,相似的概念还有G-SRH。
每4个G-SID组成一个G-SID Container,也即一个G-SID Container相当于一个标准的SID。
一个G-SID Container只有128bits长,可封装1-4个32-bits的G-SID。对于未填充满G-SID的Container,其余字节为全0的Padding字段。通过这种方式从而实现格式上的兼容性。
G-SRH也可以允许G-SID和标准SID共存的情况出现。
 //此时Segment List的效果如上图所示,SRv6子路径可以是标准SID也可以是128 bit的G-SID。
//此时Segment List的效果如上图所示,SRv6子路径可以是标准SID也可以是128 bit的G-SID。
报文转发:
为了指示SRH中G-SID的存在,G-SRv6定义了一种COC Flavor。当节点处理携带COC Flavor的SID时,SL指针不在偏移128-bits而是32-bits。
@:常见的Flavor行为可参考博客SRv6(BE)-原理介绍+报文解析+配置示例的3.1.2.章节。
@:这里简单说明下COC Flavor的实现原理及效果:在SID全网泛洪时,IGP报文中的相应字段可标识相应的SID为具有COC Flavor行为的SID。源节点在进行SRH封装时,可依照G-SRv6相应规则压入G-SID。转发面在收到Destination为特定G-SID的IPv6报文时,进行特定Segment Index的偏移完成SWAP操作。
@:在2023年10月发布的最新草案《Internet-Draft Compressed SRv6 Segment List Encoding》中,这种 Flavor 已被更新为 REPLACE-C-SID。
并且为了特定标明G-SID的具体位置,额外定义了2-bits的SID Index标识位。
@:SID Index效果有点类似SRH头部中的Segment Left字段,都是为了标识SID的存在位置以便将特定Segment List[]填充到IPv6报文的Destination中。
@:SID Index初始值为0,取值0-3标识了G-SID Container中G-SID的选择位置。
@:与Segment List相似,SID Index的取值也是倒数计数。从底层至上层SID Index降序排列,并且大序号SID Index先填充入IPv6报文的Destination中。
 //最终有类似上图效果。
//最终有类似上图效果。
压缩路径在Segment List中的编码规则为:
- SRv6压缩路径的开始由一个128 bit的携带COC Flavor的SID指示,该COC Flavor SID携带了完整的SID信息,包含Common Prefix等信息,可用于与后续G-SID恢复出完整的下一个SID。
- 压缩路径中间的G-SID均为携带COC Flavor的G-SID,指示下一个G-SID是32 bit G-SID。
- 压缩路径的最后一个G-SID不能携带COC Flavor。其与目的地址中其他部分组成的完整SID将被节点按照128 bit SRv6 SID处理:更新下一个128 bit的SRv6 SID到IPv6目的地址字段,从而实现从32 bit G-SID到普通SRv6 SID的变化。
2.3.实现效果
实际转发案例分析:
控制面:
@:具有COC Flavor行为的SID在全网进行泛洪,以便所有SRv6节点知晓网络中有哪些设备支持SID压缩功能。
@:控制器或头节点收集SID信息,以便在头节点创建SRH压入相应的SID。
转发面
@:头节点依照全网信息进行相应的SID压入并创建SRH。
@:中间节点,(如果支持SID压缩功能),依照收到报文的Destination IPv6地址与本地SID表的匹配程度来判断后续进行Segment Left指针偏移还是Segment Index的指针偏移。
通常SRH中的第一需转发的SID不加入Segment List栈中。
纯压缩域的报文转发:图中结果仅用于示例,相应错误请忽略。
 //如上图所示的SRH转发行为
//如上图所示的SRH转发行为
N0:节点创建SRH填充相应SID,Segment Left取3,Destination IPv6地址填充2001:DB8:A:1:1::。随后向邻居节点N1进行转发。
N1:收到该数据报文后,根据2001:DB8:A:1:1::指示下一个SID是32bit的G-SID。将2:1填充入相应的字段,并将Segment Index初始化为3进行相应转发。
…
N10:收到表示End.DT4的Destination IPv6地址2001:DB8:A:10:10::3后。脱掉SRH和IPv6头部向对应VPN实例进行转发。
自动换行
混合场景的报文转发:
 //如上图所示的SRH转发行为与纯压缩场景基本类似。这里仅作简单介绍。
//如上图所示的SRH转发行为与纯压缩场景基本类似。这里仅作简单介绍。
N4:收到Destination IPv6地址2001:DB8:A:4:2::1后匹配到本地发布的普通SID,直接Segment Left-1并读取相应的SID填充入Destination IPv6地址中。
@:通常IGP在发布SID时,会发布两套SID。一套为普通SID另一套为携带COC Flavor的SID。
@:普通SID则可通过判断“Node ID+Function ID”的长度是否等于32,以及Arguments字段长度是否不短于2 bits且值为0(避免有的SID使用了Arguments导致不可压缩)来判断SID格式支持G-SRv6压缩。
因此压缩功能的实现实际上与上一节点的选择相关。
@:最后一个SID通常用于标识业务,一般不进行G-SRv6压缩。
最后我们以9个栈深SID浅谈下G-SRv6的压缩效果:
首先定义压缩效果
压缩效率
=
(
压缩前长度
−
压缩后长度
)
/
压缩前长度
压缩效率=(压缩前长度-压缩后长度)/压缩前长度
压缩效率=(压缩前长度−压缩后长度)/压缩前长度
因此这里
压缩前长度为
9
∗
16
字节。
压缩前长度为9*16字节。
压缩前长度为9∗16字节。
由于G-SRv6的第一个SID需要携带相应的Common Prefix公共前缀,实际上不进行压缩。
所以
压缩后长度为
1
∗
16
+
8
/
4
∗
16
字节。
压缩后长度为1*16+8/4*16字节。
压缩后长度为1∗16+8/4∗16字节。
因此,
压缩效率
=
(
9
∗
16
−
1
∗
16
−
8
/
4
∗
16
)
/
9
∗
16
,为
66.67
%
。
压缩效率=(9∗16-1*16-8/4*16)/9∗16,为66.67\%。
压缩效率=(9∗16−1∗16−8/4∗16)/9∗16,为66.67%。
这是一个理论上的最优效率,该效率随着栈深的增加压缩效率随之提升。但如果栈深非4的倍数,G-SID Container 就需要有 Padding 字段进行填充。此时效率就会下降。
3.Flexible Algorithms
3.1.背景及术语
传统的IGP协议等都是基于链路的开销值来计算到达目的地的最优路径,但是采用这种方式往往存在很大的局限性。运营商处于业务SLA或者业务分级的需求,希望能根据自己的需求去定义路径计算规则。
一种实现方式是通过Traffic Engineering流量工程的技术实现基于一定的约束条件,使网络流量按照指定的路径进行传输。但是TE存在配置复杂、扩展性差的问题,并且设备上还需要维护大量的状态信息 。
@例如OSPF的默认开销计算为100M/链路带宽,一般来说带宽越大开销越小。通过这种方式实现的路径选择,往往不是所需的最优路径。一个简单的比喻就是节假日的高速路(高带宽链路)往往比乡道(低速链路)行驶体验更差。传统的IGP无法针对此种情况做优化。
@也即,传统的IGP无法根据额外的约束条件或依照时延调整选路。
因此Flexible Algorithm灵活算法应用而生,Flex-Algo可以允许IGP(IS-IS和OSPF)自己计算基于约束的网络路径,能够更简单和灵活的实现网络的TE能力。
Flexible Algorithm技术的基本原理在于定义了其他非IGP开销计算算法,全网依照新算法计算SPF路径。
Flexible Algorithm技术和传统的IGP算法都要计算路径,并要保证路径无环。区别在于形成路径树的计算逻辑不同。
Flexible Algorithm技术需要经过定义算法、通告算法、生成拓扑、计算路径。而传统IGP省略了定义和通告算法一步,因为默认进行携带基于链路开销的SPF算法。两者都根据相应算法形成邻居表、拓扑表和路由表。
相关术语:
FAD:Flexible Algorithm Definition,由calculation-type计算类型,metric-type度量类型和一系列constraints约束组成的的集合。
Flex-Algorithm:128-255范围内的数字标识符,通过配置与FAD相关联。
IGP-Algorithm:也即传统的IGP路径算法。可以理解为metric-type度量类型和constraints约束未指定的特殊FAD。
FADF:Flexible Algorithm Definition Flags,FAD标志位。
FAPM:Flexible Algorithm Prefix Metric,FA前缀度量。
3.2.基本原理
详细内容可参考 2023 年发布的《RFC9350-IGP Flexible Algorithm》或其他资料。
为了实现以上功能,IGP协议做出了相应的协议扩展。
这里的IGP协议主要指集成ISIS协议、OSPFv2和OSPFv3。
ISIS协议扩展:以 ISIS 为例进行介绍。OSPF 报文字段与之类似也就不在说明,感兴趣者可查阅 RFC9350 等相关资料。
IS-IS Router CAPABILITY TLV(Type=242,RFC7981)中新定义Sub-TLV IS-IS FAD sub-TLV(Type=26)
 Flex-Algorithm:1字节。取值128-255,通过配置与FAD相关联。用户可以自定义这些值代表的具体算法。
Flex-Algorithm:1字节。取值128-255,通过配置与FAD相关联。用户可以自定义这些值代表的具体算法。
Metric-Type:1字节。目前仅定义了3种–0表示IGP Metric,1表示最小单向链路延迟,2表示TE默认Metric。
Calc-Type:1字节。取值0-127,指定相应的计算类型。Metric和Constraints不得继承。如果取0表示SPF,1表示严格SPF算法。
Priority:1字节。取值0-255,
Sub-TLVs:不定长,可选的Sub-TLV。
@IS-IS FAD Sub-TLV 可以在任何编号的LSP中通告。
@L1/L2 路由器不得从Level-1重新生成任何 FAD Sub-TLV 到级Level-2。
Sub-TLV IS-IS FAD sub-TLV(Type=26)还定义了Sub-TLV的Sub-TLV,这里进行简单介绍:主要与FAD三要素的约束条件对应。
IS-IS Flexible Algorithm Exclude Admin Group Sub-TLV(Type=1):用于通告Flex-Algo算法约束条件中亲和属性的Exclude-Any排除规则。也即不能包含任何一个引用的亲和属性名称,不满足的链路将被排除,不能参与算路。
IS-IS Flexible Algorithm Include-Any Admin Group Sub-TLV(Type=2):用于通告Flex-Algo算法约束条件中亲和属性的Include-Any规则。也即只要包含一个引用的亲和属性名称,该链路就可以参与算路。
IS-IS Flexible Algorithm Include-All Admin Group Sub-TLV(Type=3):通告Flex-Algo算法约束条件中亲和属性的Include-All规则。也即要包含所有引用的亲和属性名称,不满足的链路将被排除,不能参与算路。
IS-IS Flexible Algorithm Definition Flags Sub-TLV(Type=4):特定功能标识,目前仅定义M-bit。设置后,必须使用特定于 Flex 算法的前缀指标进行区域间和外部前缀计算。此标志不适用于通告为SRv6 locators的前缀。
IS-IS Flexible Algorithm Exclude SRLG Sub-TLV(Type=5):通告Flex-Algo算法约束条件中的共享风险链路组Exclude SRLG规则。是具有相同故障风险的一组链路集合,使用Exclude SRLG来描述对风险共享链路组的约束。
不同类型的子TLV只能在ISIS FAD Sub-TLV中出现一次。如果出现了多次,则该ISIS FAD Sub-TLV不会被接收者处理。
除以上TLV外,RFC9350 还定义 IS-IS Flexible Algorithm Prefix Metric Sub-TLV(Type=6)主要在 Extended IP reachability(Type=135),MT IP. Reach(Type=235),IPv6 IP. Reach(Type=236)和MT IPv6 IP. Reach(Type=137)中携带,用于通告指定前缀携带特定Flexible Algorithm Prefix Metric。
在同一个IGP域内,不同设备可能定义算法值相同但是含义不同的算法,当出现灵活算法定义不一致时,各个设备按如下规则进行处理:
- 选择优先级(Priority)最大的Flex-Algo定义。
- 当有多个节点通告优先级相同的算法定义时,选择System-ID最大的节点发布的算法定义。
RFC8667还定义IS-IS Router CAPABILITY TLV(Type=242,RFC7981)的子TLV==SR-Algorithm Sub-TLV(Type=19)用于通告自己所使用的算法。
 每种算法占1字节,且必须携带Algorithm 0表示最基本的SPF算法。SR-Algorithm Sub-TLV只能在同一个IS-IS Level里传播,不能传播到该Level区域之外。也即distribution flags应进行相应设置。与FAD的Calc-Type相对应。
每种算法占1字节,且必须携带Algorithm 0表示最基本的SPF算法。SR-Algorithm Sub-TLV只能在同一个IS-IS Level里传播,不能传播到该Level区域之外。也即distribution flags应进行相应设置。与FAD的Calc-Type相对应。
3.3.SRv6 Flex-Algo实现
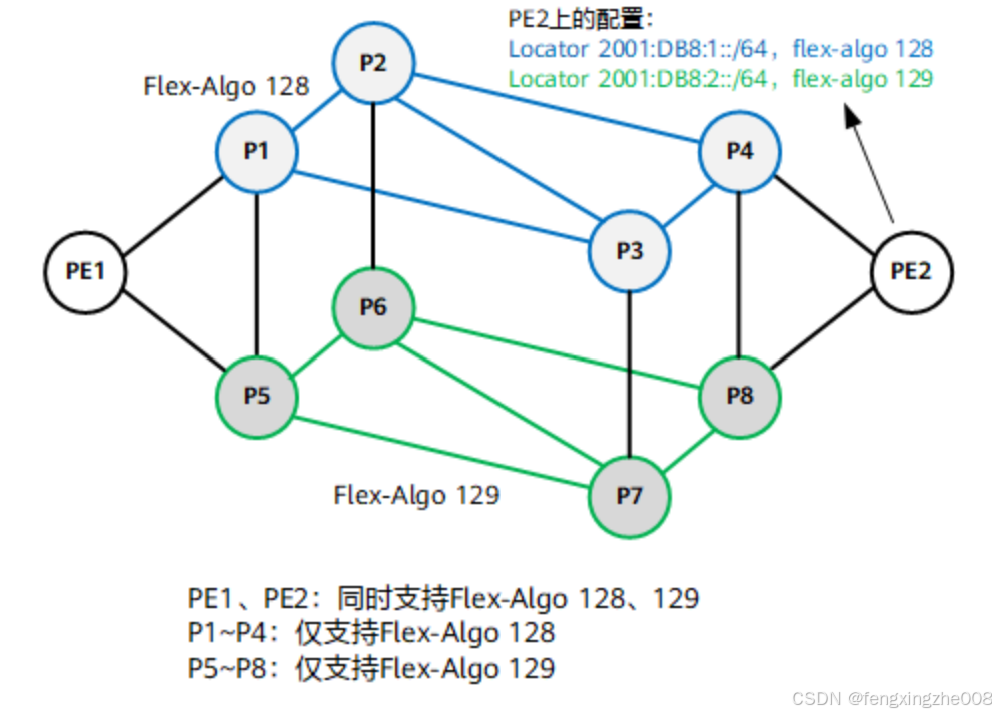 单个IGP,多Locator方案。
单个IGP,多Locator方案。
一方面各个设备的IGP协议会通过FAD Sub-TLV对外通告本机支持的算法,以及某一个Flex-Algo的具体计算规则。
另外一方面,用户在配置Locator时,可以配置关联的算法。IGP会将算法和Locator一起通过SRv6 Locator TLV对外发布。当使用SRv6 Locator TLV中定义的算法来表示Flex-Algorithm时,也必须使用与该算法关联的Locator prefix路径。
2023年发布的《RFC9350-IGP Flexible Algorithm的第14章》中还介绍了 SR-MPLS 作为转发面时的相应程序动作。
1@:首先IGP通告的Prefix-SID中将包含特定的SR-Algorithm,当该算法值可匹配Flex-Algorithm时,Prefix-SID将与Flex-Algorithm的拓扑路径计算结果相关联。并在转发时必须使用Prefix-SID携带的SR-MPLS Label。
2@:当Flex-Algorithm路径无法匹配对应的Prefix-SID信息时,应将其流量丢弃。
3@:当Flex-Algorithm拓扑使用LFA及其变体算法保护时,也仅应当仅使用与计算该 Flex-Algorithm 的主路径相同的约束来计算。
 以上图为例对Flex-Algo基于链路静态时延的SRv6 BE的应用进行说明:主要介绍PE1上关于Flex-Algo与普通SRv6的区别,关于流量的引入、约束路径的详细使用、Flex-Algo的SRv6 TE等内容不做详细说明。
以上图为例对Flex-Algo基于链路静态时延的SRv6 BE的应用进行说明:主要介绍PE1上关于Flex-Algo与普通SRv6的区别,关于流量的引入、约束路径的详细使用、Flex-Algo的SRv6 TE等内容不做详细说明。
仅供参考不具备实际意义。
te attribute enable
#
flex-algo identifier 128
priority 100
metric-type delay
affinity include-all green
#
//主要定义FAD的三要素calculation-type,metric-type和constraints约束。
//灵活算法metric-type默认为IGP,constraints默认不约束
path-constraint affinity-mapping
attribute green bit-sequence 1
attribute red bit-sequence 9
#
//定义约束路径映射
segment-routing ipv6
encapsulation source-address 1::1
locator as1 ipv6-prefix 10:: 64 static 32 flex-algo 128
#
//通告携带 flex-algo 的Locator。
isis 1
is-level level-1
cost-style wide
network-entity 10.0000.0000.0001.00
flex-algo 128 level-1
#
ipv6 enable topology ipv6
ipv6 traffic-eng level-1
segment-routing ipv6 locator as1
#
#
//定义IGP携带Flex-Algo
interface GigabitEthernet1/0/0
undo shutdown
ipv6 enable
ipv6 address 2001:db8:1::1/96
isis ipv6 enable 1
te link-attribute-application flex-algo
delay 10
link administrative group name red
#
//接口指定Flex-Algo基本条件
4.SRv6与网络切片
网络切片是指在同一个共享的网络基础设施上提供多个逻辑网络,每个逻辑网络服务于特定的业务类型或者行业用户。运营商将基于一套共享的网络基础设施来为多租户提供不同的网络切片服务,满足不同行业的差异化网络需求,各垂直行业客户将会以切片租户的形式来使用网络。
网络切片从广义上来说,是一整套解决方案,涉及无线接入网、IP网络和移动核心网三个部分,这里主要介绍 IP 网络的网络切片。
4.1.背景及相关术语
5G时代存在三种主要业务需求:
eMBB:Enhanced Mobile Broadband,增强型移动宽带。聚焦对带宽有高要求的业务。
uRLLC:Ultra-Reliable Low-Latency Communication,超高可靠超低时延通信。聚焦对时延有高要求的业务。
mMTC:Massive Machine Type Communication,大规模机器通信。聚焦对复杂业务类型有高要求的业务。
5G核心网:
UPF:User Plane Function,用户面功能。
MEC:Mobile Edge Compute,移动边缘计算。
网络切片实现需求:
业务隔离:针对不同业务在公共网络中建立不同的网络切片,提供业务连接和访问的隔离。
资源隔离:网络切片所使用的网络资源与其他网络切片所使用资源之间是否存在共享。
运维隔离:对运营商分配的网络切片进行独立的管理和维护操作,即做到对网络切片的使用近似于使用一张专用网络。
网络切片方案:
基于亲和属性的方案:每个亲和属性对应一个网络切片。亲和属性可以标识不同切片的转发资源接口,每个切片资源接口均需要配置IP地址和SR SID。
控制平面:每个切片基于亲和属性计算 SR-MPLS 和 SRv6 Policy 路径,用于业务承载。
功能实现上使用亲和属性将链路标识成不同颜色(如蓝、黄等),相同颜色的链路组成一个网络。将不同的亲和属性配置在各个网络切片对应的预留资源接口或子接口上,实现基于亲和属性划分出独立的网络切片。
数据平面:切片基于 SR-MPLS 标签栈或 SRv6 SRH 头封装和逐跳转发业务报文。
不同网络切片预留的资源接口或子接口具有不同的 SRv6 End.X SID,这样网络中每一个转发节点在转发报文时可以根据 SID 确定用于执行报文转发的接口或子接口资源。
基于Slice ID的方案:
引入全局唯一的 Slice ID 标识网络切片,每个Slice ID 对应一个网络切片。Slice ID 可以标识切片内转发资源接口,不需要为每个切片接口配置独立的 IP 地址和 SR SID。
控制平面:基于 Slice ID 计算SR-MPLS或 SRv6 BE 或 TE Policy 路径,用于业务承载。
功能实现上为不同平面网络引入了二维地址标识网络切片。通过网络物理节点 IP 地址+网络切片 ID 来唯一标识网络切片中的逻辑节点。
数据平面:各转发节点根据数据报文中携带的 Slice ID 匹配切片资源接口转发业务。为了进行区分,数据报文中需要额外携带全局的网络切片标识。一种典型的实现方式是,在 IPv6 的逐跳选项(Hop-by-Hop options,HBH) 扩展报文头中携带网络切片的 Slice ID。
网络切片和FlexE技术结合:
FlexE 技术通过 FlexE Shim 把物理接口资源按时隙池化,在大带宽物理端口上通过时隙资源池灵活划分出若干子通道端口(FlexE接口),实现对接口资源的灵活、精细化管理。
每个 FlexE 接口之间带宽资源严格隔离,等同于物理口。FlexE 接口相互之间的时延干扰极小,可提供超低时延。FlexE 接口的这一特性使其可用于承载对时延 SLA 要求极高的 uRLLC 业务。
4.2.基于Slice ID的网络切片
SDN 控制器通过 BGP SR Policy 邻居关系或手工下发对应的 SR TE Policy 将业务路径与 Network Slice 进行绑定并进行网络通告。为了满足自动 SR Policy 下发功能,在当前 2024-11-11 最新发布的草案《Internet-Draft-Advertising Segment Routing Policies in BGP》中定义了当 AFI=1(表示IPv4) 或 2(表示IPv6) 且 SAFI=73 用于表示 SR TE Policy SAFI。此 SAFI 可用于标明携带 BGP SR Policy NLRI。
BGP SR Policy NLRI。
自动换行同时SR Policy SAFI NLRI格式为上图所示。
自动换行
为了描述Tunnel attribute信息,BGP还在Path Attribute Type=23路由属性中定义了多个TLV用于描述隧道信息。
BGP Attribute Code=23携带的BGP SRv6 TE Policy信息示例。
同时为了事先 BGP 下发切片信息,《Internet-Draft- BGP SR Policy Extensions for Network Resource Partition 》在隧道封装属性 Tunnel Encapsulation Attribute (Type=23) 的 Tunnel-Type TLV (Type=15) 中新定义了一个 NRP Sub-TLV。
NRP Sub-TLV的Type值,当前为123。
SRv6 TE Policy可以通过静态配置生成,也可以由控制器通过BGP IPv6 SR-Policy扩展来下发。在静态配置场景,Slice ID也是静态配置指定;在控制器下发场景,控制器下发SRv6 TE Policy路由时需要携带Slice ID信息。
自动换行
关于BGP下发SRv6 TE Policy原理的相关内容,可参考博客SRv6 TE Policy场景-原理浅谈及配置示例的《2.1.场景介绍及BGP SRv6 TE Policy属性》。
在控制面上至少需实现以下几部分内容:
1@SR TE Policy:通过手工配置或 SDN 控制器下发,来完成设备上的转发路径隧道建立。
2@切片创建:通过手工配置或 SDN 控制器下发,创建对应的网络切片及切片对应网络预留资源。
3@切片关联:将切片与 SR TE Policy 进行绑定。通常以 Slice ID 与 SR TE Policy 中的 color 等属性进行关联,以便业务流进入 SR 隧道时可享用对应的切片预留资源。
4@业务路由迭代:PE 之间互相传递的 VPNv4/EVPN 等业务路由应包含 Color,下一跳和 VPN SID 等信息以便业务路由可正常迭代入 SR TE Policy 隧道中。
4.2.1.网络切片的HBH方案
在网络切片的 HBH转发面方案中,使用 IPv6 的扩展选项头 Hop-by-Hop Options header 来携带 Slice ID 值进行业务区分。在《RFC8200-IPv6 Specification》定义中这是一个与 SRH 同级别的 IPv6 扩展选项头,Next Header Type = 0。该 IPv6 扩展报头主要用于为在传送路径上的每跳转发指定发送参数,传送路径上的每台中间节点都要读取并处理该字段。
在 2024-11-03 当前最新的草案《Internet-Draft-Carrying Network Resource (NR) related Information in IPv6 Extension Header》中定义了该网络切片数据面的 HBH 方案。在该草案中将网络切片称为 NRP(Network Resource Partition,网络资源分区),对应的切片 ID 称为 NRP ID。
草案中定义的 HBH 扩展头中携带的 Network Resource option:
 1@Option Type:8-bits,类型标识符。
1@Option Type:8-bits,类型标识符。
2@Option Data length:8-bits,用于表示 Option Data 的字节长。
3@Flags:8-bit, flags 标识。
目前仅定义最高 bit 的 S-bit,用于指示是否必须严格匹配 NR ID 才能处理数据包。当收到的数据包的 NR 选项中的 S 标志设置为 1 时,如果数据包中的 NR ID 与网络节点上配置的任何网络资源不匹配,则必须丢弃该数据包。否则应使用默认的网络资源转发数据包。
4@Context Type:8-bit, 标识携带 NR ID 的语义。通常取 0。
5@Unassigned:2 字节,保留字段。
6@NR ID:4 字节,网络资源集合的标识。语义由 Context Type 字段确认。
自动换行
相应的报文转发封装:
网络切片的 HBH 方案中,业务报文经封装进入对应的 SRv6 TE Policy 隧道中时,依照外层 IPv6 包头中相应的 Segment List 进行转发,并在转发时读取 Hop-by-Hop Options header 中的 Slice ID。由于是事先为 Slice ID 预留了相应的网络资源,业务流量便可享用对应的业务资源。
//指定携带Slice ID的扩展头,默认为HBH(Next Header=0)携带Slice ID。
切片转发实例:
 CE1 向 PE1 发送一个普通 IPv4 单播报文。
CE1 向 PE1 发送一个普通 IPv4 单播报文。
-
PE1 接收到 CE1 发送的报文之后,根据 Color 属性和下一跳信息迭代路由的出接口是 SRv6 TE Policy。PE1 为报文插入 SRH 信息,封装 SRv6 TE Policy 的 SID List,然后封装 HBH 扩展头。HBH 扩展头里携带 SRv6 TE Policy 的 Slice ID 信息,最后封装 IPv6 基本报文头。完成之后,PE1 将报文对 P1 转发,转发时通过 Slice ID 信息关联到指定的网络切片接口。
-
中间 P1 设备根据 SRH 信息转发,转发时使用 HBH 扩展头里的 Slice ID 信息关联到指定的网络切片接口。P3 和 P5 的转发过程与 P1 类似。
-
PE2 使用内层 VPN SID 查找 My Local SID 表,命中到 End.DT4 SID,PE2 解封装报文,去掉 SRH 扩展头、HBH 扩展头和 IPv6 报文头,使用内层 IPv4 报文的目的地址 10.2.2.2 查找 VPN SID 对应的 VPN 实例路由表,然后将报文转发给 CE2。
4.2.2.网络切片的源地址方案
从以上内容中,我们可以发现 Slice ID 并不参与业务报文的实际转发,业务报文的转发仍与 SRH 扩展头的 Segment List 相关。而转发面仅需要做的是标识携带 Slice ID,并在完整的 SR TE Policy 转发过程中始终携带对应 Slice ID,以便告知途径设备所应享用的网络资源。
在当前最新的草案《Internet-Draft-Encoding Network Slice Identification for SRv6》中定义了一种使用外层 IPv6 源地址来携带 Slice ID 的方案。
 在此仅介绍相关内容,IPv6 Header 其他字段不做相应介绍。这里的 SPI 为 SLID Presence Indicator,也即 Slice ID 存在标识。SPI 用于通知传输路由器数据包中编码了 Slice ID。
在此仅介绍相关内容,IPv6 Header 其他字段不做相应介绍。这里的 SPI 为 SLID Presence Indicator,也即 Slice ID 存在标识。SPI 用于通知传输路由器数据包中编码了 Slice ID。
1@SPI (Option A):SPI 标识位置 A。该字段原本为 IPv6 头部的 Traffic class,功能类似于 IPv4 的 DSCP 字段可用于 QOS 等相关功能。SPI 在 Traffic Class 字段中编码为特定 bit,称为 SPI-bit。其选择受本地策略的约束,并在 SR 域中统一。
SPI-bit位于Traffic Class的第二个bit。
2@SPI (Option B):SPI 标识位置 B。该字段为 IPv6 头部的源地址,也即 SPI 被编码为源地址。相应的内容被称为 SPI-prefix,其分配受本地策略的约束,并在 SR 域中统一。此外,SPI 前缀中的某些位可以被屏蔽,为IPv6规划提供更大的灵活性。
Source Address字段分类。
自动换行
同时在此草案中还定义有:
SLID的最高S-bit可用于表示是否必须严格使用与SLID关联的网络资源转发数据包。当与SLID关联的网络资源不存在或不可用时,如果S标志设置为1,则必须丢弃数据包。未置位则应使用默认网络资源或忽略SLID字段。
自动换行
相应的报文转发封装:
 首先定义公共 SPI-prefix = AA::/64,并将 IPv6 address 的最低 32-bits 预留为 Slice ID。
首先定义公共 SPI-prefix = AA::/64,并将 IPv6 address 的最低 32-bits 预留为 Slice ID。
 在数据包转发时,由首发 PE1 节点将 Slice ID = 5 压入 IPv6 header 形成 AA::1:0:5 的源地址。转发路径检查其源地址可与本地定义的 SP-prefix = AA::/64 匹配时,解析源地址最低 32-bits 中的 Slice ID,享用与该 Slice ID 关联的网络资源。
在数据包转发时,由首发 PE1 节点将 Slice ID = 5 压入 IPv6 header 形成 AA::1:0:5 的源地址。转发路径检查其源地址可与本地定义的 SP-prefix = AA::/64 匹配时,解析源地址最低 32-bits 中的 Slice ID,享用与该 Slice ID 关联的网络资源。
4.3.网络切片实现
相比于传统 SRv6,PE 节点上需要实现:
1@创建网络切片实例:
network-slice instance 10
description Basic
#
network-slice instance 20
description vpn1
#
2@网络切片与业务进行绑定:
segment-routing ipv6
encapsulation source-address 2001:DB8:1::1
locator <PE1> ipv6-prefix 2001:DB8:100:: 64 static 32
opcode ::10 end psp
#
srv6-te-policy locator <PE1>
segment-list <list1>
index 5 sid ipv6 2001:DB8:120::20
index 10 sid ipv6 2001:DB8:130::30
#
srv6-te policy <policy1> endpoint 2001:DB8:3::3 color 101
candidate-path preference 100
network-slice 20 data-plane
segment-list <list1>
#
3@网络切片与接口绑定:
interface GigabitEthernet1/0/0
undo shutdown
ipv6 enable
ipv6 address 2001:DB8:10::1/64
isis ipv6 enable 1
network-slice 10 data-plane
#
interface GigabitEthernet1/0/0.1
vlan-type dot1q 11
ipv6 enable
mode channel enable
mode channel bandwidth 500
basic-slice 10
network-slice 20 data-plane
#
如果采用BE模式,则需要在PE节点上为Network Slice进行着色以便进行相应区分。
network-slice color-mapping color 101 network-slice 20 # ip vpn-instance vpn1 import route-policy <rp11> # route-policy <rp11> permit node 10 apply extcommunity color 0:101 #
P节点上需要实现:
1@创建网络切片并与接口绑定:
network-slice instance 10
description Basic
#
network-slice instance 20
description vpn1
#
interface GigabitEthernet1/0/0
undo shutdown
ipv6 enable
ipv6 address 2001:DB8:10::2/64
isis ipv6 enable 1
network-slice 10 data-plane
#
interface GigabitEthernet1/0/0.1
vlan-type dot1q 11
ipv6 enable
ipv6 address auto link-local
mode channel enable
mode channel bandwidth 500
basic-slice 10
network-slice 20 data-plane
#


















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









