






大数据时代,中大型企业数据的爆发式增长,几乎每天都能产生约 100GB 到 10TB 的数据。而企业数据分系统构建与扩张,导致不同应用场景下大数据冗余严重。行业亟需一个高效、统一的融合数仓,从海量数据中快速获取有效信息,从而洞察机遇、规避风险。
在这样的现状下,CarbonData 诞生了,作为首个由中国贡献给Apache社区的顶级开源项目,CarbonData 提供了一种新的融合数据存储方案,以一份数据同时支持多种大数据应用场景,并通过丰富的索引技术、字典编码、列存等特性提升了 IO 扫描和计算性能,实现了PB数据级的秒级响应。
为了帮助开发者深入了解并学习这项大数据开源技术,华为 CarbonData PMC 陈亮牵头,携手技术社区的核心开发者及合作伙伴,举办了一场Apache CarbonData+Spark 主题的技术交流会,就 CarbonData+Spark 的重要特性和使用介绍,做了全面而细致的分享,本文简单整理了其中的部分精彩内容,同时,作为本次活动的承办方,InfoQ整理上传了所有讲师的演讲PPT,感兴趣的同学可以下载讲师PPT获取完整资料 。
Spark SQL的发展史概述
来自美国Databricks公司的范文臣首先讲述了Spark SQL的发展史,范文臣同时也是Apache Spark PMC member,主导 Spark SQL 一些主要功能的设计和研发,定期审计项目代码质量等。现场,他将Spark SQL过去的发展分为四个阶段:

2009年,著名的Spark框架诞生。它是一个围绕速度、易用性和复杂分析构建的大数据处理框架,由伯克AMP实验室创建。相比于当时流行的Hadoop,Spark提供了更高效的MapReduce模型,减少数据落地,也降低了编程难度。
2011年,Spark团队将Hive的底层物理执行模块从Hadoop切换成Shark,启动了Shark项目。然而,由于Hive自身的代码复杂性以及和Hadoop MapReduce的耦合,Shark的开发举步维艰,进展缓慢。
2014年,Spark团队舍弃Shark,重新建立了一套完整的查询框架Catalyst。Catalyst利用了函数式风格的不可变特性,使Query Plan不可变,优化器通过遍历优化策略生成新的 Query Plan。这样优化规则之间的影响更容易理解,提升了代码的可读性和可维护性,也方便了新特性的开发。下图为Spark SQL控制框架:
2015年,Spark团队提出了钨丝计划,通过建立Tungsten格式、后端优化、代码生成等手段,将Spark的查询性能和执行速度提升到了一个新的台阶。
- 2017年,持续探索中……
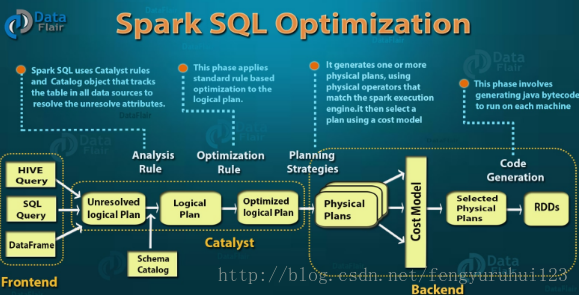
那么,沿着查询性能这条路,Spark的未来还会有哪些优化方向?范文臣在最后的演讲中总结到:Spark的愿景是管理各种不同性质数据集和数据源的大数据处理的需求。Spark这样一个角色,只关注于计算层,快速查询处理是Spark唯一的衡量标准,也是未来不变的发展方向。也因此,在之后的Spark2.3里面,在计算框架下如何更快的和储存系统桥接、Spark代码生成都是未来着重关注的方向。
CarbonData应用实践+2.0新技术规划介绍
CarbonData诞生之初是希望以一份数据去满足企业各种各样的场景需求,包括详单过滤和海量数仓以及数据集式操作等。那么,开发者该如何正确使用CarbonData技术?华为CarbonData总设计师李昆结合实际案例,详细讲解了CarbonData应用实践+2.0新技术规划。
CarbonData大数据生态
Carbondata在数据查询方面选择和Spark结合,据李昆现场介绍,Carbondata+Spark可以打造一个相对于传统系统来说,更好的交互分析体验,目前Carbondata和Spark1.5、1.6、2.1,Hive,Presto都做了集成,未来还将对Spark2.2做支持;在接口方面,Carbondata提供SQL接口,也支持Spark DataFrame API;在操作方面,支持查询、数据管理如批量入库、更新、删除等操作。

成功案例介绍
随后,李昆通过电信详单分析场景的举例介绍,详细说明CarbonData如何以一份数据支持多种应用场景的。李昆表示,在电信跟金融领域经常需要明细数据分析,优化之前,老的系统需要用Impala和Hbase两个系统,建立4个二级索引才可以完成业务需要的性能。这其中,Impala用来做报表输出,Hbase做关键维度查询。这两个系统有各自存在不足:Impala没有办法很好的扩展,HBase要做很多二级索引,无法使用yarn统一资源管理,只能是一个个集群单独维护。
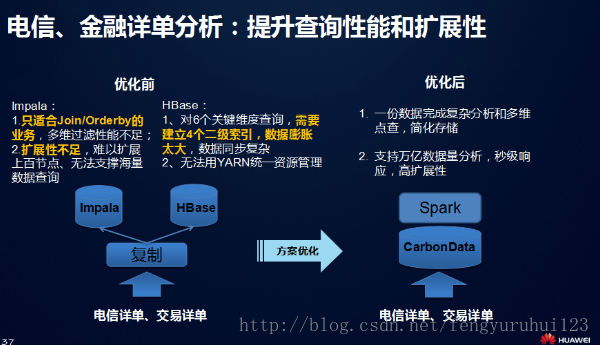
用Carbondata+Spark数据优化后,可以解决既要点查又要处理报表的情况。下图是一个从2000亿到1万亿的性能测试数据,Q1是过滤查询,Q2也是过滤查询,Q1跟Q2数据查询因为用了Carbondata索引,需要扫描的数据不会增长很多,数据量增长5倍,查询时间增长不到1倍。第三个查询是full scan查询,主要考察的是spark和carbon的可扩展性,测试过程中发现扩展性是非常线性的,scalability很好。

CarbonData2.0未来规划
现在,Carbondata的主要特性是对多场景的支持,不过在大数据时代,更多的场景正扑面而来。包括SQL分析、时间序列分析、位置轨迹、文本检索、图查询和机器学习等。这就需要Carbondata2.0在各领域的应用上有更多的准备。包括:
入库方面,需要考虑实时事件的流式入库、历史事件的批量入库等;
存储方面分三层,一层是界面,每一个领域有自己的术语,会针对领域常见操作做些SQL上的扩展;二是数据组织层,对不同领域做不同的分区、索引和预处理等,以便于它更高效地存储领域数据;三是存储格式层,Carbondata目前是列存,为了支撑更多查询和分析,数据格式本身也需要具有扩展能力,比如行存、时序、面向AI的格式等;
Spark 2.2 核心特性CBO介绍
在Spark SQL的Catalyst优化器中,许多基于规则的优化技术已经实现,但优化器本身仍然有很大的改进空间。Spark 2.2在Spark SQL引擎内添加了一个基于成本的优化器框架,此框架通过可靠的统计和精确的估算,能够在以下领域做出好的判定:选择散列连接操作的正确构建端,选择正确的连接算法,调整连接的顺序等等,这个基于成本的优化器就是CBO。据华为研究工程师王振华介绍,CBO的目标是希望优化器能够自动为用户选择最优的执行计划,要达到这件事情,需要以下三个步骤:
第一步收集、推断和传播关于源/中间数据的表/列统计信息
用户运行 ANALYZE TABLE 命令会收集表格信息比如表的行数、大小,列的统计信息比如最大值、最小值、不同值个数等,并将这些信息存储到metastore里面。

第二步Cardinality Estimation,根据收集到的信息,计算每个操作符的成本,包括输出行数、输出大小等
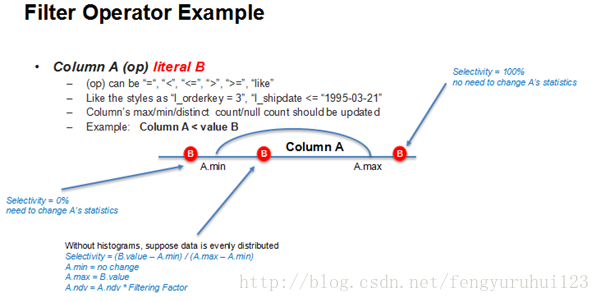
如下图,为一个A小于等于某数字的估算,如果A的value比A的最小值更小,或者是比A的最大值更大,那么过滤率肯定是0或者100%,当落在定义域中间的时候,假设是均匀分布,概率则是A.min到B的区间所占A的定义域的百分比,这个是Filter条件最终的selectivity,有了selectivity,即可再相应的更新filter以后的统计信息。
第三步根据成本计算,选择最优的查询执行计划
通过建造方选择(Build Side Selection)、散列连接实现:广播与洗牌(Hash Join Implementation: Broadcast vs. Shuffle)、多路连接重新排序(Multi-way Join Reorder)、连接成本计算公式(Join Cost Formula)四个方面阐述了最优计划的选择过程。
其中,在多路连接重新排序方法上,采用了动态规划算法。以四表连接为例,首先,将所有项(基本连接节点)放到0级;然后,从第0级的计划中构建所有的两表连接;第三,从以前的层级(单节点和两表连接)中构建出可能的三表连接;最后,构建所有的4路连接,并在其中选出最优的计划。而在构建m-路径连接时,只需保留同一组m项的最佳计划(最优子解决方案)。如,对于A、B、C的三表连接顺序,只保留三个候选计划:(A J B)J C,(A J C)J B和(B J C)J A 当中最优的计划。
Join cost计算方式如下,首先Cost一般来说传统的数据库里是基于CPU和IO,这两个Cost是线性加合。在Spark中,用Cardinality模拟CPU的开销,用size模拟IO的开销。
王振华最后介绍到,华为在2016年7月份开始将CBO贡献给Spark社区,并建立了umbrella ticket - SPARK-16026。截至目前为止,创建了超过40个sub-tasks、提交了50余个pull requests并被合入,同时吸引了十余个社区贡献者的参与。
CBO的第一个版本已经在Spark 2.2中发布,感兴趣的开发者和使用者,如要使用CBO,可以在收集统计信息之后,打开spark.sql.cbo.enable来使用CBO。
Partition 功能详解+上汽实践分享
CarbonData的partition特性将在Apache CarbonData 1.2.0版本里正式发布,此特性将显著提升大数据查询性能。上汽集团大数据将CarbonData作为平台基础组件,以应对迅猛增长的数据量,那么上汽集团在使用CarbonData过程中遇到了哪些问题?上汽集团大数据平台开发经理曹鲁就CarbonData的partition特性以及上汽集团在CarbonData项目的实践和测试数据做了分享。
曹鲁首先介绍了文件结构,索引生成过程,初次性能测试等主题内容,引出Partition特性带来改变,主要包括两点:
1、数据将基于Partition列更为集中存储,查询时可过滤掉大量block,减少spark task数量;
2、可以使其他列在排序中更靠前,提升查询性能。
Partition Table的数据加载及查询过程详解
随后,曹鲁详细介绍了CarbonData Partition相关的DDL语法,如Create Partition Table、Show Partition等,以及CarbonData Partition Table的数据加载以及查询过程。下图可以很清晰的看到CarbonData Partition的整个数据加载过程。
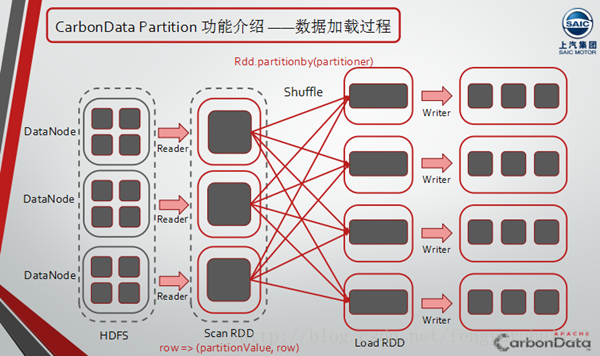
关于CarbonData Partition Table查询过程,大概分为两个部分:
- 根据SQL中的过滤条件=, <=, <, >, >=, in, not in以及表达式右值确定命中的partitionId

如果有其他在排过序的维度列有过滤条件,则在driver端根据B-tree索引获取blocklet 所在的文件名,如没有则获取全部,再根据文件名中的partitionId,筛选得到需要读取的文件,最后再下发spark task进行读取
之后,曹鲁就Partition的新增(add)、拆分(split)及删除(drop)功能的语法和实现过程展开了分析,其中重点区分了Drop Partition但保留数据RangePartition/ListPartition两种Drop Partition类型的不同语法与实现,感兴趣的读者可以下载讲师PPT深入了解

上汽在CarbonData项目的实践分享
在案例分享环节,曹鲁以上汽的数据作为测试数据,分析了CarbonData Partition table和非Partition table条件下的加载性能和查询性能对比。并给出了CarbonData Partition的性能调优建议。本文为大家展示其中的无排序维度列作为过滤条件,有partition列上的范围过滤条件的聚合查询情况的对比结果,如图不难看出,原始查询方式的耗时是添加partition性能查询方式耗时的25倍。
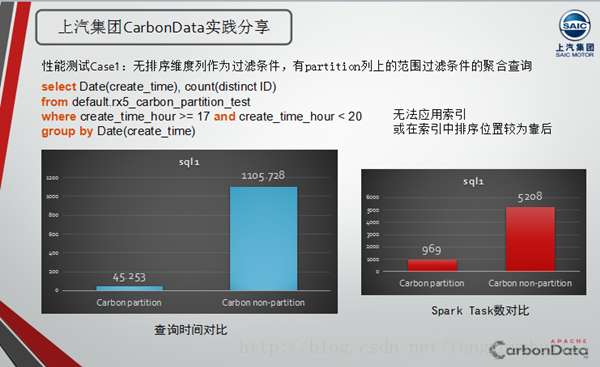
曹鲁给出的CarbonData Partition的性能调优建议:1、 选择最合适的Partition列;2、尽可能的使用Partition列作为过滤条件,例如Partition列为A,开发者根据业务需求在Column B上有筛选条件,但注意到A与B列之间存在某种固定的mapping关系,这时就可以根据B列的过滤条件再新增一个partition列的过滤条件,以提高查询效率。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









