







如何向别人介绍 spark
Apache Spark™ is a fast and general engine for large-scale data processing.
Apache Spark is a fast and general-purpose cluster computing system.
It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs.
It also supports a rich set of higher-level tools including :
- Spark SQL for SQL and structured data processing, extends to DataFrames and DataSets
- MLlib for machine learning
- GraphX for graph processing
- Spark Streaming for stream data processing
spark 诞生的一些背景
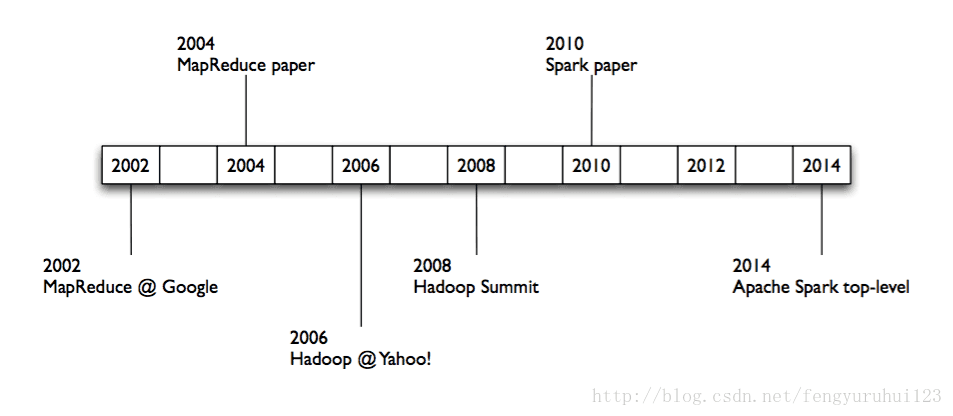

Spark started in 2009, open sourced 2010, unlike the various specialized systems[hadoop, storm], Spark’s goal was to :
generalize MapReduce to support new apps within same engine
- it’s perfectly compatible with hadoop, can run on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
speed up iteration computing over hadoop.
use memory + disk instead of disk as data storage medium
design a new programming modal, RDD, which make the data processing more graceful.
[RDD transformation, action, distributed jobs, stages and tasks]
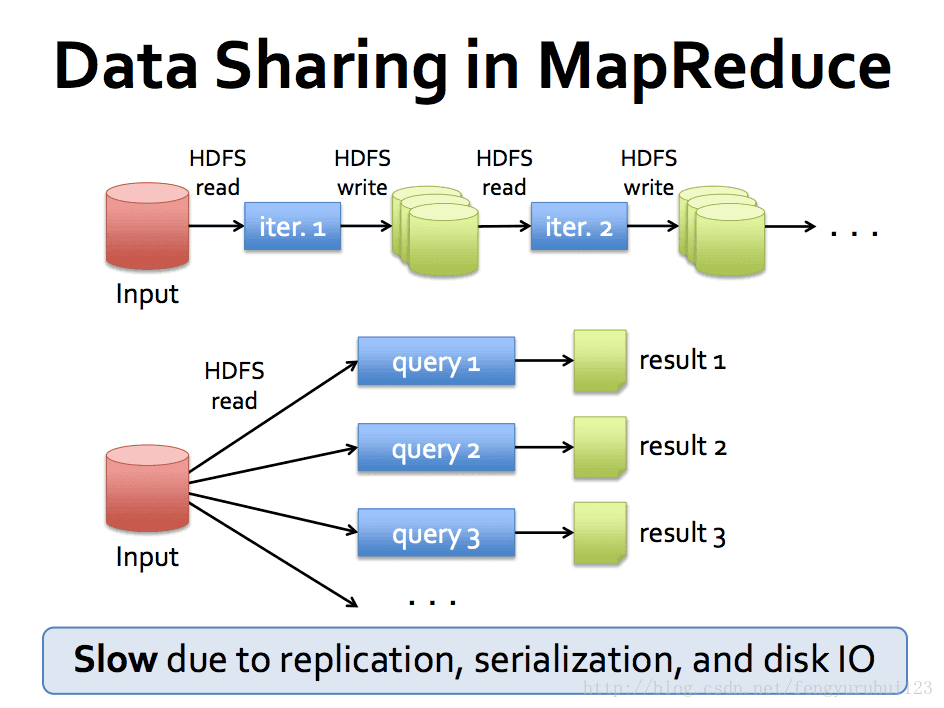
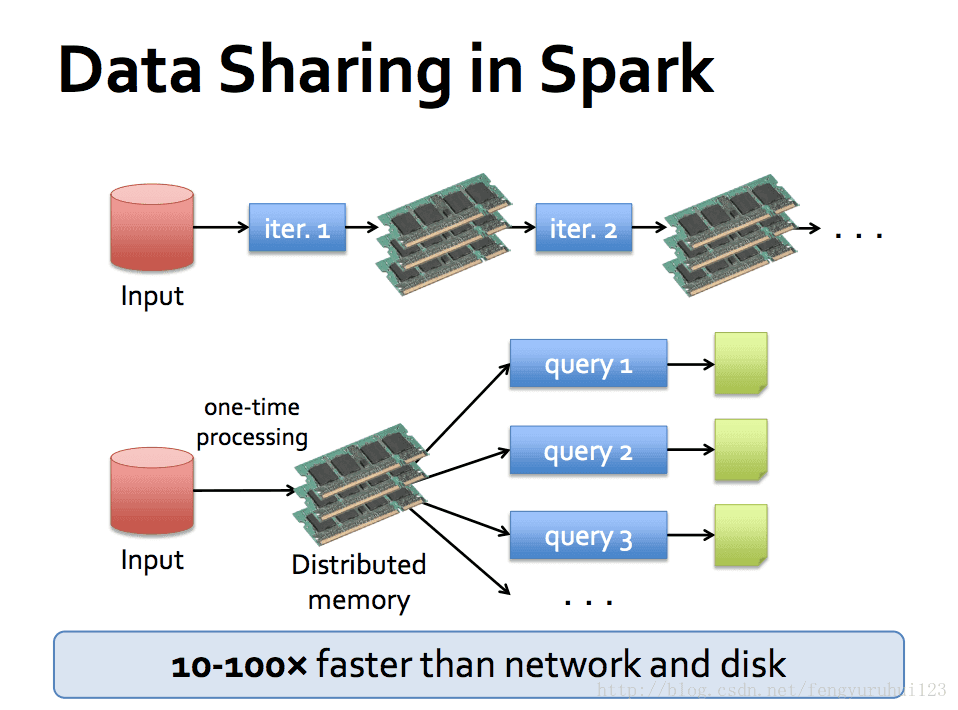
为何选用 spark
- designed, implemented and used as libs, instead of specialized systems;
- much more useful and maintainable

- from history, it is designed and improved upon hadoop and storm, it has perfect genes;
- documents, community, products and trends;
- it provides sql, dataframes, datasets, machine learning lib, graph computing lib and activitily growth 3-party lib, easy to use, cover lots of use cases in lots field;
- it provides ad-hoc exploring, which boost your data exploring and pre-processing and help you build your data ETL, processing job;















 6312
6312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









