







Darknet深度学习框架:YOLO背后的强大支持
Darknet,一个由Joseph Redmon开发的轻量级神经网络框架,以其在计算机视觉任务,特别是目标检测中的卓越表现而闻名。本文将详细介绍Darknet的基本概念、结构以及它在深度学习领域的应用。
一、Darknet简介
YOLO:目标检测的革新者
YOLO(You Only Look Once)是Darknet的标志性应用之一,它是一种实时目标检测算法,能够在单次前向传播中检测图像中的多个对象,并输出它们的边界框和类别。YOLO的速度和效率使其成为自动驾驶、监控和无人机视觉等实时目标检测应用的理想选择。
轻量级与高效
Darknet使用C语言编写,这使得它在嵌入式设备和资源受限的环境中运行非常高效。它的轻量级特性使其在边缘计算和嵌入式系统上得到了广泛应用。
支持多种深度学习任务
Darknet不仅限于目标检测,它还支持图像分类、语义分割和生成对抗网络(GANs)等多种深度学习任务。
开源框架
作为一个开源项目,Darknet的源代码可在GitHub上获得,这使得它能够受益于广泛的社区贡献,不断进行发展和改进。
模型训练与部署
Darknet允许用户从头开始训练深度神经网络模型,并提供了模型部署的能力,使用户能够将其模型集成到不同的应用中。
二、Darknet的结构
Darknet53:构建基础
以Darknet53为例,它通过重复堆叠下采样卷积和残差块(Residual Block)的结构组成。残差块是Darknet53的基础构建模块,下面将详细介绍。
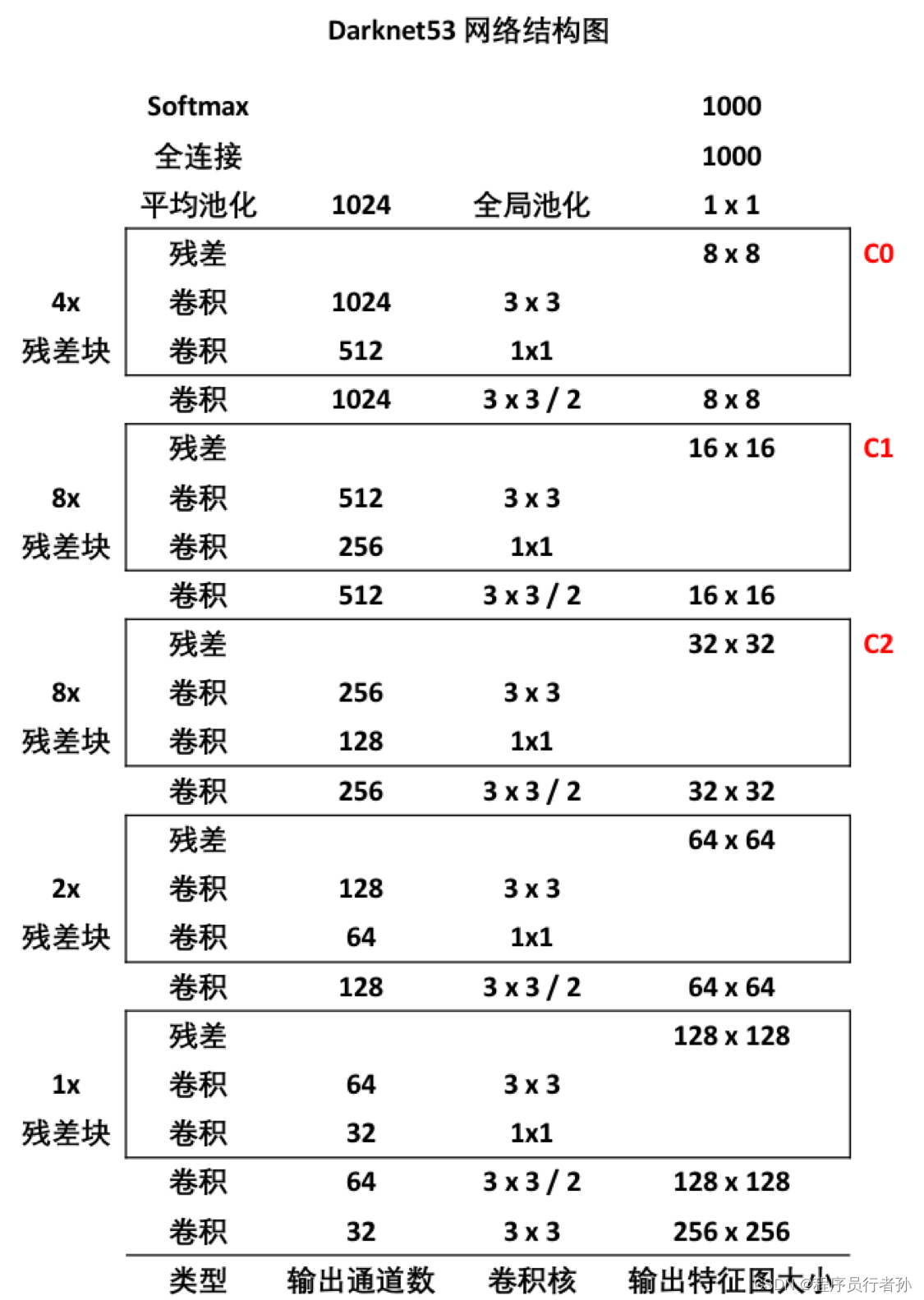
在Darknet框架中,特别是在构建卷积神经网络(CNN)时,“filters”、“size/stride” 和 “output” 是卷积层中的关键概念:
Filters(滤波器或卷积核)
- 概念:在卷积神经网络中,“filters”(或称为卷积核)是用于从输入数据中提取特征的小矩阵。每个filter都通过在输入图像上滑动(卷积操作)并计算点积来生成输出特征图(feature map)的一个通道。
- 作用:不同的filters可以捕捉不同的特征,如边缘、角点或更复杂的纹理模式。在更深的网络中,filters可以学习到更高级的特征表示。
Size/Stride(尺寸/步长)
- Size:指的是卷积核的尺寸,常见的尺寸有3x3、5x5等。Size决定了每个卷积核在输入图像上覆盖的区域大小。
- Stride:指的是卷积核在输入图像上滑动的步长。步长为1表示每次滑动一个像素;步长大于1表示每次滑动多个像素。
- 作用:卷积核的尺寸和步长共同决定了输出特征图的空间维度(宽度和高度)。步长越大,输出特征图的空间尺寸减小得越多,这相当于一种下采样操作。
Output(输出)
- 概念:“output” 在卷积层的上下文中通常指的是输出特征图,它是卷积操作的结果。
- 组成:输出特征图由多个通道组成,每个通道对应一个filters生成的结果。输出特征图的总通道数与filters的数量相同。
- 空间尺寸:输出特征图的空间尺寸(宽度和高度)可以通过输入特征图的尺寸、卷积核的尺寸和步长来计算。
为什么这些概念重要?
这些概念对于设计和理解卷积神经网络至关重要:
- 特征提取:filters的数量和类型直接影响到网络能够学习到的特征的种类和丰富性。
- 感受野:filters的尺寸决定了每个神经元的感受野,即它能够接收的输入图像区域的大小。
- 计算效率:filters的尺寸和步长影响计算的复杂度,较小的filters和较大的步长可以减少计算量,但可能会损失一些细节信息。
- 空间维度变换:通过调整filters和步长,可以控制特征图的空间尺寸,实现特征图的下采样或上采样。
在Darknet的配置文件中,这些参数通常需要用户根据具体任务和数据集来设置,以获得最佳的模型性能。
残差块
残差块是深度学习中的一种常用建筑模块,最初由Kaiming He等人在ResNet中引入。它旨在解决深层神经网络训练中的梯度消失和梯度爆炸问题,提高网络性能和收敛速度。
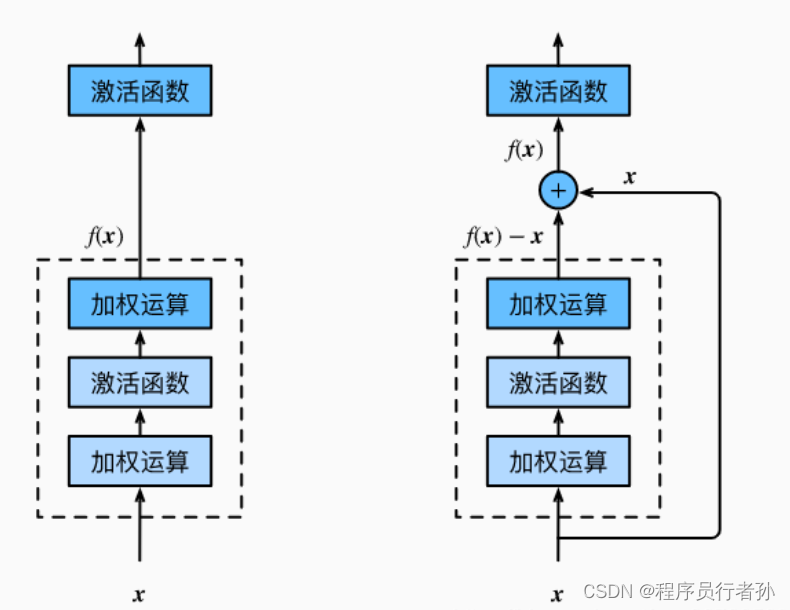 有无残差对比
有无残差对比
跳跃连接
残差块通过跳跃连接将输入直接添加到输出中,以学习残差映射,即输入和输出之间的差异。
残差学习
残差块的目标是学习残差函数,即网络的期望映射和实际映射之间的差异。
非线性激活函数
残差块通常包括ReLU等激活函数,以增加网络的非线性表达能力。
批归一化
批归一化层用于标准化输入数据,加速网络收敛。
批量归一化(Batch Normalization)概述
批量归一化是一种用于提升神经网络训练效率和性能的技术,由Sergey Ioffe和Christian Szegedy在2015年提出。
工作原理
-
归一化:计算每个小批量数据的均值和方差,将激活值归一化至均值为0,方差为1的分布。
-
可学习参数:引入缩放因子(γ)和偏移量(β),允许模型学习归一化后特征的最佳尺度和位置。
-
融合层:作为融合层,批量归一化通常位于非线性激活函数之前。
优点
- 加速训练:允许使用更高的学习率,加快训练过程。
- 提高稳定性:减少内部协变量偏移,稳定训练过程。
- 改善泛化:提高模型泛化能力,减少过拟合。
- 支持深层网络:稳定化效果使得训练更深层次的网络成为可能。
缺点
- 计算开销:增加模型计算负担,但可通过训练加速技术补偿。
- 对批量大小敏感:效果可能受批量大小影响,小批量可能导致不稳定。
上下采样(Upsampling 和 Downsampling)
上下采样是信号处理和图像处理领域的关键技术,也在深度学习特别是卷积神经网络(CNNs)中扮演重要角色。
下采样(Downsampling)
import torch
import torch.nn as nn
# 假设有一个输入特征图,例如4x8的矩阵
input_feature_map = torch.randn(1, 1, 8, 8) # (batch_size, channels, height, width)
# 定义一个最大池化层,使用2x2的池化核,步长为2
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 应用最大池化层进行下采样
downsampled_feature_map = max_pool(input_feature_map)
print("原始特征图尺寸:", input_feature_map.shape)
print("下采样后特征图尺寸:", downsampled_feature_map.shape)
定义:减少数据采样率,降低分辨率或尺寸。
方法:
- 池化(Pooling):如最大池化和平均池化,通过选取区域内的统计量来降低空间维度。
- 步幅卷积(Strided Convolution):增加卷积核步幅,跨过更多像素,减少特征图尺寸。
作用:
- 降低计算量。
- 提取高级特征,实现特征抽象。
上采样(Upsampling)
import torch
import torch.nn.functional as F
# 假设有一个低分辨率的特征图,例如4x2的矩阵
low_resolution_feature_map = torch.randn(1, 1, 2, 4) # (batch_size, channels, height, width)
# 使用双线性插值进行上采样,目标尺寸为4x8
upsampled_feature_map = F.interpolate(low_resolution_feature_map, size=(4, 8), mode='bilinear', align_corners=False)
print("低分辨率特征图尺寸:", low_resolution_feature_map.shape)
print("上采样后特征图尺寸:", upsampled_feature_map.shape)
定义:增加数据采样率,提高分辨率或尺寸。
方法:
- 插值:如最近邻、双线性、双三次插值,填充放大后的像素。
- 转置卷积(Deconvolution):特殊卷积层,增加特征图空间维度。
作用:
- 恢复高分辨率输出,如图像分割。
- 学习性重建,从低分辨率特征中重建细节。
应用
在CNN中,下采样用于特征提取和降维,上采样用于恢复分辨率,构建具有不同分辨率特征的网络结构。
结论
上下采样是深度学习中处理图像和其他高维数据的重要技术,通过合理使用,可以设计出既高效又能生成高质量输出的深度学习模型。
结语
Darknet是一个快速、轻量级且多功能的深度学习框架,特别擅长目标检测任务。它在嵌入式系统、无人机、自动驾驶、监控等领域具有广泛的应用前景。对于计算机视觉和深度学习的研究者和开发者来说,Darknet无疑是一个宝贵的工具。
















 3883
3883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











