






存储结构
数据存储结构在计算机科学中根据元素的组织方式和访问机制主要可以分为以下四类:
顺序存储结构:
- 数据元素在内存中是连续存放的,每个元素占据固定大小的空间。
- 访问数据时通过下标(索引)直接计算地址来定位,如数组、顺序表等。
- 优点在于随机访问速度快,缺点是插入和删除操作可能需要大量移动元素。
链式存储结构:
- 数据元素不再要求连续存放,而是通过指针链接各个元素。
- 每个元素包含自身数据和指向下一个(或前一个)元素的指针。
- 链表(包括单链表、双链表、循环链表等)就是典型的链式存储结构。
- 优点是可以动态分配空间,插入和删除相对灵活,缺点是访问速度受指针跳转影响较大,无法像顺序存储那样实现随机访问。
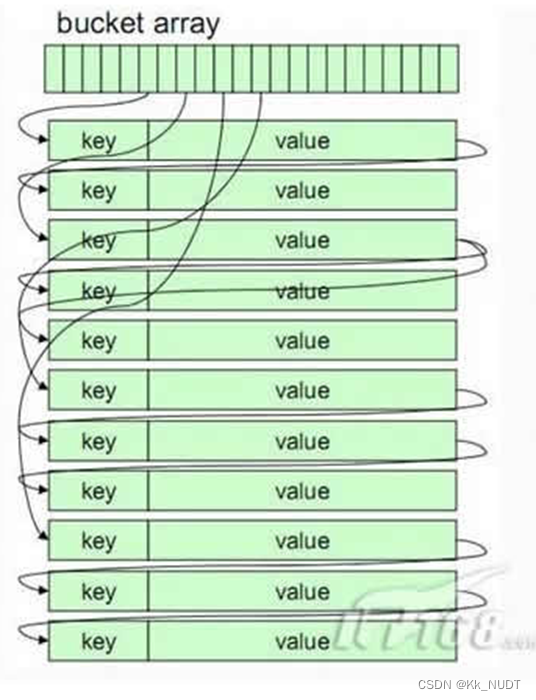
散列存储结构(哈希存储结构):
- 根据关键字通过散列函数计算出对应的存储位置(哈希地址),将数据元素存放在散列表(哈希表)中。
- 目标是实现快速查找,理想情况下,查找、插入和删除的时间复杂度接近O(1)。
- 散列冲突处理是散列存储的一个关键问题,通常采用开放寻址法或链地址法解决冲突。
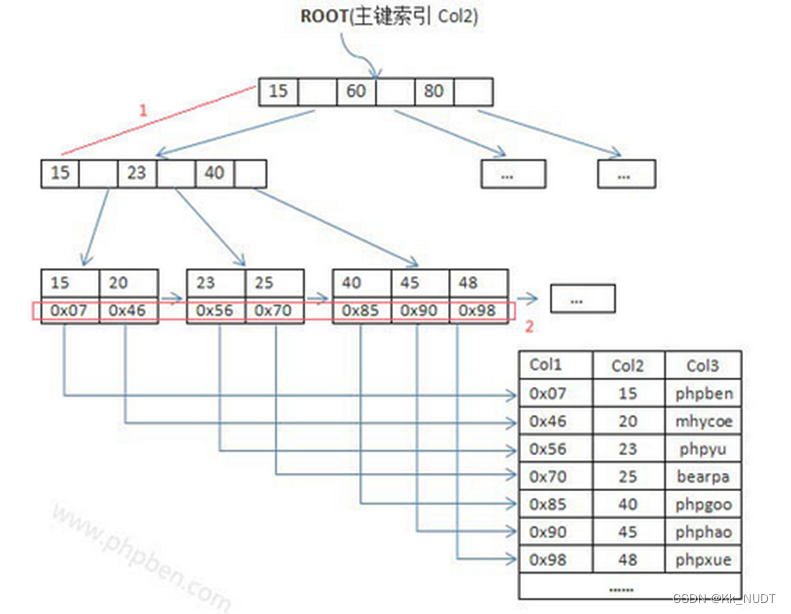
索引存储结构:
- 在实际的数据存储区域外,还建立了一个用于检索数据元素的额外数据结构,即索引。
- 索引可以是顺序的也可以是非顺序的,比如B树、B+树等多级索引结构常被用作数据库和文件系统的底层支持。
- 索引存储使得即使数据量很大,也能高效地找到所需数据,同时保证了数据的实际物理存储不一定是连续的。
每种存储结构都有其适用场景和优缺点,选择哪种结构取决于具体的应用需求。
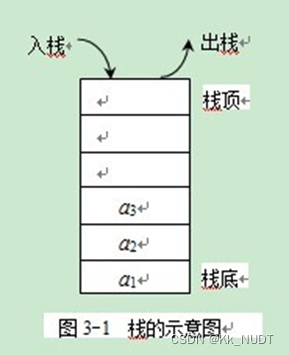
顺序存储结构
用一组地址连续的存储单元依次存储线性表的各个数据元素, 适用于频繁查询时使用。
链式存储结构
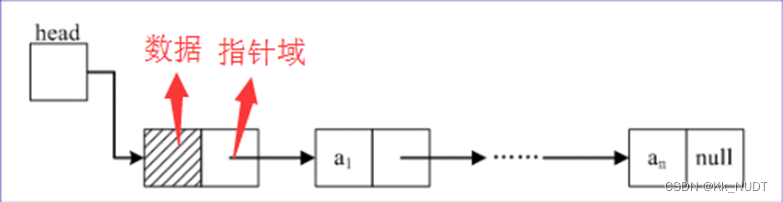
在计算机中用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的),适用于在较频繁地插入、删除、更新元素时使用。
单链表
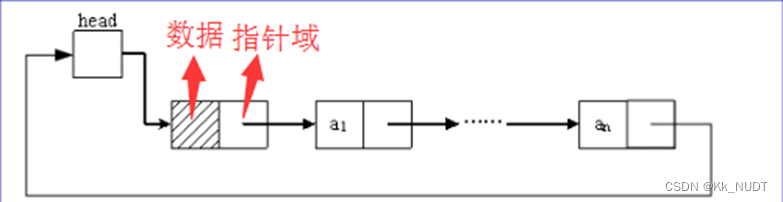
循环链表
双链表
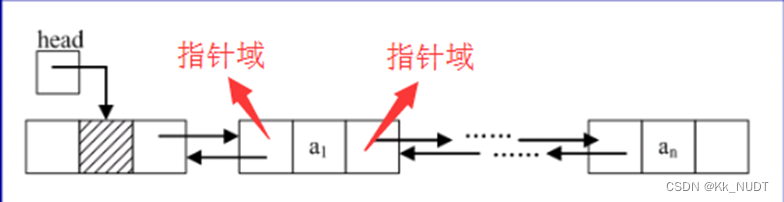
各链表的比较
因为双链表有两个指针域,因此,双链表的灵活度优于单链表,但是双链表的开支要大一些
散列存储结构
将数据元素的存储位置与关键码之间建立确定对应关系的查找技术,即键值对。
索引存储结构
索引是一个单独的、物理的数据库结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。比如数据库




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











