







Hadoop伪分布式 datanode节点启动不了
一,当出现namenode和datanode不能同时工作时,显示的问题如下
<1>当不启动namenode的时候可以启动datanode,情况如下图。

<2>当启动namenode节点的时候,datanode直接挂掉,情况如下图。
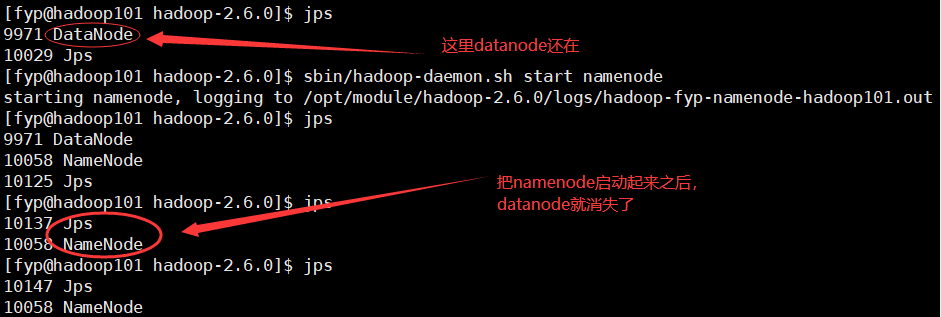
<3>这是因为多次格式化namenode导致的问题,namenode在格式化之后会生成一个clusterID,datanode在启动后也会生成一个和namenode一样的clusterID,多次格式化namenode后会生成新的clusterID,此时与未删除的datanode的clusterID不一样,导致不能同时工作。
二,我们可以先去看一下,现在两个分别的clusterID
<1>查看官方的默认存放位置如下

<2>下面是自己配置数据储存位置的方法
这里我们可以在Hadoop配置文件里面,在core-site.xml里配置数据储存位置
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.6.0/data/tmp</value>
</property>
hadoop.tmp.dir --代表数据存储目录的配置,我这里配置到了/opt/module/hadoop-2.6.0/data/tmp目录下,你们可以自行配置目录
<3>查看namenode和datanode的clusterID
找到自己的数据存储目录,进入tmp目录,再进入dfs目录,可以看到如下图
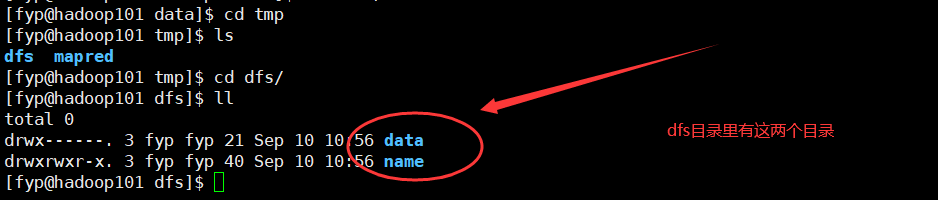
1.先进入data目录下的current可以看到如下 -----这一步是查看datanode的clusterID
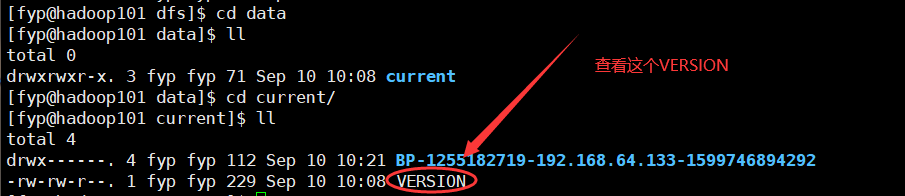
2.查看VERSION
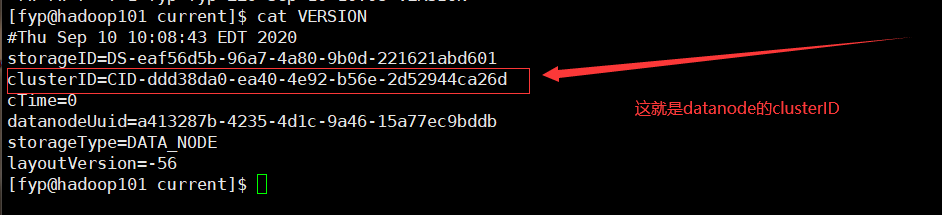
datanode的clusterID=CID-ddd38da0-ea40-4e92-b56e-2d52944ca26d
同理查看namenode的clusterID,进入dfs里的name目录下,查看
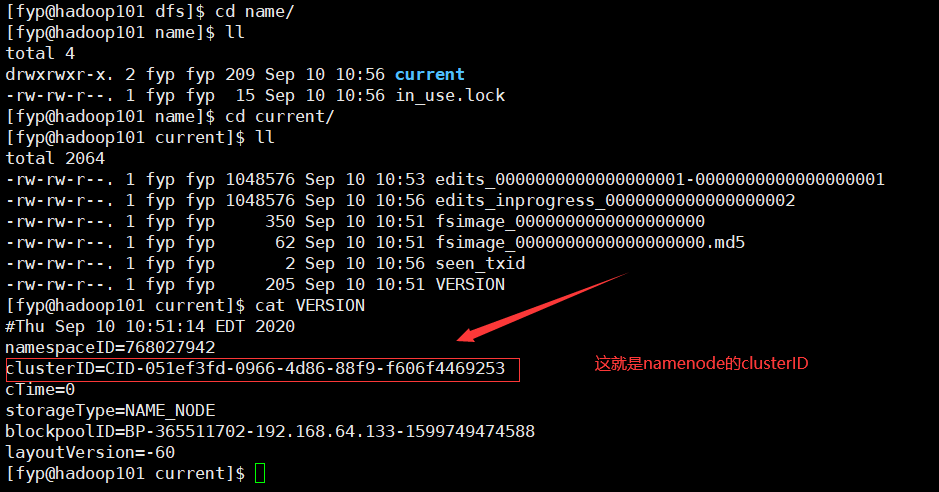
namenode的clusterID=CID-051ef3fd-0966-4d86-88f9-f606f4469253
我们对比上面的datanode的clusterID,我复制下来对比一下
datanode的clusterID=CID-ddd38da0-ea40-4e92-b56e-2d52944ca26d
可以看到明显不相同,所以就是这里的问题!
三,解决方案
<1>关闭namenode节点或者datanode节点,全都停止。 ----这里得退回到Hadoop根目录哦

<2>删除你tmp目录里的全部内容

然后返回到Hadoop根目录,重新格式化namenode,然后重新启动namenode和datanode就可以了
四,下面我们使用伪分布式执行wordcount案例试试

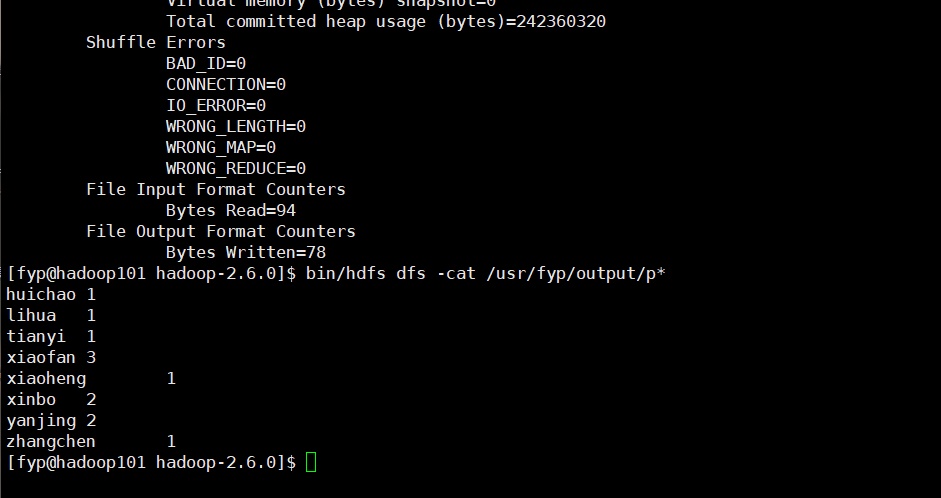
可以看到可以完美执行wordcount案例!
关注我,期待与你一起进步!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











