







watchdog一般是一个硬件模块(其实可以当做是一个定时器),其作用是,在嵌入式操作系统中,很多应用情况是系统长期运行且无人看守,导致程序跑飞,所以难免怕万一出现系统死机,那就悲剧了,这时,watchdog就会自动帮你重启系统。
那么其是如何实现此功能的呢?简单解释一下其实现原理:
watchdog硬件的逻辑就是,其硬件上有个记录超时功能,然后要求用户需要每隔一段时间(此时间可以根据自己需求而配置)去对其进行一定操作,比如往里面写一些固定的值,俗称“喂狗”,那么看门狗发现超时了,即过了返么长时间你还不给看门狗喂食,那么看门狗就认为你系统是死机了,出问题了,看门狗就帮你reset重启系统。
为何在要系统初始化的时候关闭watchdog
了解了watchdog的原理后,此问题就很容易理解了。如果不禁用watchdog,那么就要单独写程序去定期“喂狗”,那多麻烦,多无聊啊。毕竟咱此处叧是去用uboot初始化必要的硬件资源和系统资源而已,完全用丌到返个watchdog的机制。需要用到,那也是你linux 内核跑起来了,是你系统关心的事情,和我uboot没啥关系的,所以肯定此处要去关闭watchdog(的reset功能)了。
看门狗(watchdog)包括一个4分频的预分频器和一个32位的计数器,时钟通过预分频器输入定时器。定时器递减计数,递减的最小值为0XFF。如果设置一个小于0XFF的值,系统会将0XFF装入计数器,因此最小看门狗间隔为t(pclk)X256X4。
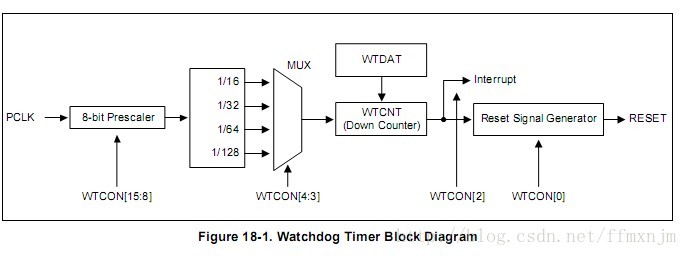
门狗的用途是使微控制器在进入错误状态后的一定时间内复位。当看门狗使能时,如果用户程序没有在周期时间内喂狗(重装),看门狗会产生一个系统复位。
看门狗的特性如下:
1.如果没有周期性重装,则产生片内复位。
2.调试模式。
3.由软件使能,但要求禁止硬件复位或看门狗复位/中断~。
4.错误/不完整的喂狗时序会导致复位/中断(如果使能)。
5.指示看门狗复位的标志。
6.带内部预分频器的可编程32位定时器。
7.可选择t(pclk)X4的倍数的时间周期。
基本操作:看门狗应当根据下面的方法来使用
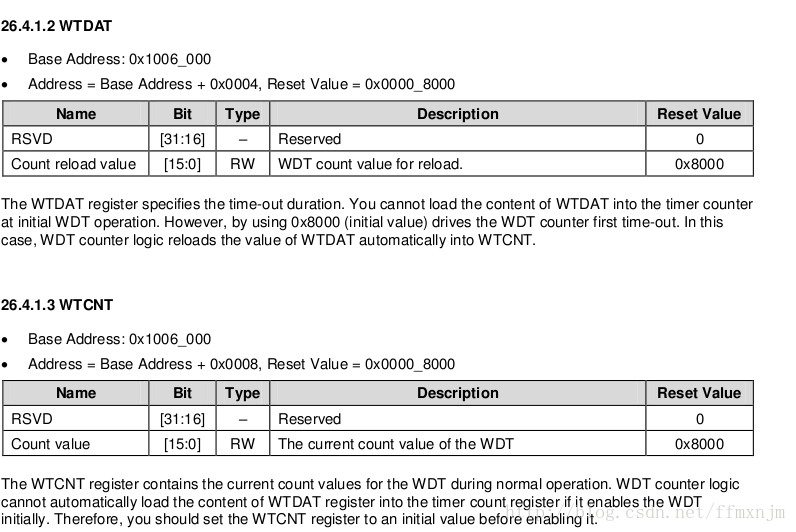
1.在WDTC寄存器中设置看门狗定时器的固定装载值;
2.在WDMOD寄存器中设置模式;
3.通过向WDFEED寄存器顺序写入0XAA和0X55启动看门狗;
4.在看门狗向下溢出之前应当再次喂狗,以防止复位/中断~!
当看门狗计数器想下溢出时,程序计数器将从0x00000000开始,和外部复位一样。可以检查看门狗超时标志WDTOF来确定看门狗是否产生复位条件,WDTOF标志必须由软件清零。
MTK6737平台看门狗相关
文档:
MT6737_LTE_Smartphone_Application_Processor_Functional_Specification_V1.1应用处理器功能规格书 重要.pdf
如下内容:
top reset generate unit顶级重启发生单元
a watchdog timer is also included in this module看门狗定时器也包含在这个模块






类似的看门狗相关的数据手册 电路图
MTK 看门狗详细解析
目录
WDT硬件设计 2
0 WDT原理 2
1 MediatekWDT硬件设计 2
WDT软件设计 2
2设计原理 2
3 WDT驱动 2
4 WDK驱动 2
5 超时触发流程 2
分析方法 2
6 HWT 2
7 HW REBOOT 2
案例分析 2
8 HWT-kernel初始化时间长(1) 2
9 HWT-kernel初始化时间长(2) 2
10 HWT-lk执行时间长 2
11 HWT中断频繁触发 2
12 HWT-大量DEVAPC violation 2
13 HWT-SWT卡死 2
14 HWT-死锁卡死 2
15 HWT- 关机死锁卡死 2
16 HWT-死循环卡死 3
17 HWT-CPU卡死 3
18 HWT-rt throttle引起卡死 3
19 HWT-hotplug失败 3
20 HWT-在TEE OS里卡死 3
21 HWT-spinlock嵌套死锁 3
22 HWT-两把不同的spinlock造成死锁 3
23 HW REBOOT-HW故障 3
附录 3
24 相关FAQ 3
0 WDT原理
1. 原理
在手机Soc Chip中,里面的AP跑着linux操作系统软件,而任何软件都可能存在各种问题,如果遇到了这些异常,软件可能陷入死循环,导致手机变成“砖头”,如果没有其他硬件辅助,那么只能断电(拔电池)然后重新开机才行。为了避免出现这种情况,芯片内部增加了一个看门狗模块,这个模块专门检测CPU运行状态,只要出现卡死就复位系统。
WDT全称是watchdog timer,就是看门狗模块,看门狗其实就是一个可以在一定时间内被复位的计数器。当看门狗启动后,计数器开始自动计数,经过一定时间,如果计数没有被复位,计数器达到指定数值就会发出复位信号,很多设备包括CPU接到这个信号而复位重启(俗称“被狗咬”)。为了保证看门狗不发出复位信号,就需要在看门狗允许的时间间隔内对看门狗计数器清零(俗称“喂狗”),计数器重新计数。如果系统正常并保证按时“喂狗”,那么就相安无事。一旦程序故障卡死,没有“喂狗”,系统“被咬”复位。
2. 种类
嵌入式系统中主要可以分为两种类型的看门狗:
- Soc芯片内部集成WDT,这是Soc常用的设计。当然PC上可能用独立的看门狗芯片。
- 软件模拟看门狗,只要有个timer就可以模拟。
1 MediatekWDT硬件设计


可以看到WDT在RGU里只是其中一个模块,还有其他模块可以产生复位信号,比如thermal,当温度过高会触发IRQ或直接复位,这也是一种硬件保护措施。复位信号经过Mixer后会分出2个信号,grst_b会复位芯片内部模块,还有1个信号通过芯片管脚WATCHDOG复位外部芯片。有时为了debug,也可以测量WATCHDOG pin脚(正常是高电平,有复位信号时低电平),看这次重启是否是WDT等触发的。
2. dual mode
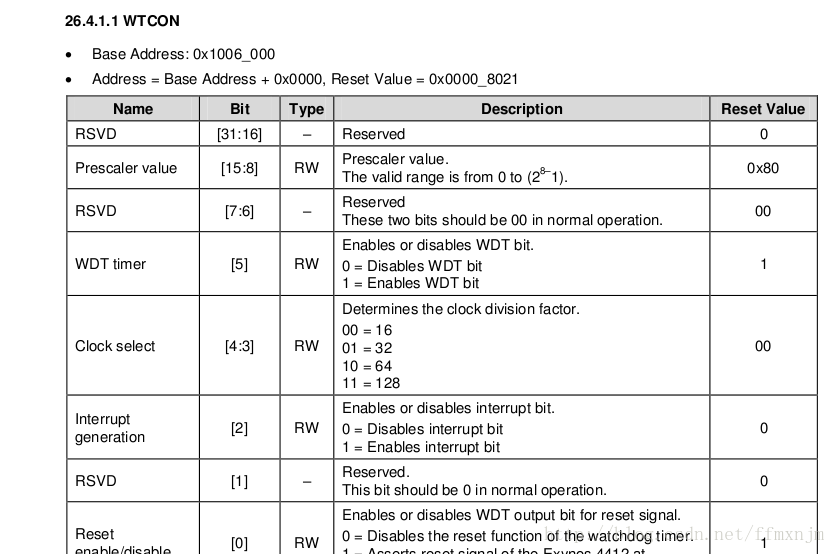
WDT功能,大家可以看datasheet里的寄存器介绍,比如包含了
- WDT_MODE:功能开关
- WDT_LENGTH:超时计数
- WDT_RESTART:写该寄存器触发计数清0
- WDT_STA:状态
- WDT_INTAVEL:reset信号长度
- WDT_SWRST:写该寄存器直接触发复位
这里介绍一个dual mode功能,通常CPU发生卡死,我们需要知道卡死位置,分析原因,然后改进,而不希望直接复位。设计的方法是:WDT超时后先不发复位信号,而是先送出IRQ(如上面的框图),WDT IRQ通常配置成CPU的FIQ,如果CPU只是软件卡死(内核死锁,中断过多等),会响应该FIQ,然后我们在FIQ里收集异常信息和CPU寄存器信息,然后再走正常的panic流程。重启后我们就有信息分析此次WDT timeout的原因了。为了保证IRQ发出后,CPU不卡死,WDT再次计时,如果在panic流程又卡死了,就会由WDT发出复位信号复位。
简单讲:WDT超时先发出IRQ,WDT重新计时,如果再次超时WDT直接发出复位信号。可以看到WDT超时后分2个阶段,第1阶段发出IRQ用于收集异常信息,第2阶段直接复位。通常我们在第1阶段就完成异常信息收集并通过WDT_SWRST寄存器完成复位,而不用等到第2阶段的。这种情况我们称为HWT(Hardware Watchdog Timeout)
事实上任何事情总有意外,比如CPU因为PMIC提供的电压低,或硬件故障等原因导致WDT超时发出的IRQ在CPU端得不到响应,WDT只能通过第2阶段复位芯片。这种情况我们称为HW reboot。HW reboot通常和硬件有较大关系。比如:
- 硬件故障,电压或频率异常
- 总线卡死
2设计原理
-
bit位代表CPU的喂狗状态:CPU核数每个平台都不太一样,我们用bit位代表1个CPU,比如4个CPU就用4个bit,我们用kick_bit变量表示。
-
喂狗进程负责喂狗:在喂狗模块初始化时针对每个CPU创建的对应的内核实时进程(优先级最高)并绑定到对应的CPU上(也就是说这个进程只运行在指定CPU上,不会发生迁移),这些进程喂狗(其实就是将kick_bit对应的bit位置1而已,并没有真正喂狗)后进入睡眠,喂狗间隔是20s,如此循环反复。
-
真正喂外部WDT狗:任何一个喂狗进程在喂狗之后,会检查kick_bit变量,如果该值等于cpus_kick_bit变量(这个变量的每个bit代表对应CPU online情况,如果CPU online,对应bit置1),表示所有CPU都已喂狗,这时才真正喂外部WDT狗,同时将kick_bit清0,进入下一轮喂狗流程,如此循环反复。
用一张框图总结上面的流程(以4核CPU为例):

这里的wdtk-x就是对应CPU的喂狗进程。以上的一套设计可以保证各个CPU卡死都可以通过看门狗复位。
喂狗间隔是20s,而超时时间是30s,也就是说最长能容忍卡住的时间是10s(卡一小会还是可以的),超过这个时间,系统就会复位了。这里还有问题,由于喂狗进程之间没有同步,是否有可能存在刚开始一起喂狗,之后渐渐出现先后呢?误差肯定有的,但在任何30s时间里,喂狗进程都会喂1次狗的(因为喂狗间隔20s,每个CPU肯至少会喂1次狗)。而只要CPU卡死超过10s就复位了。
多核CPU不可能一直都是online,系统会根据负载做hotplug,在某颗CPU power down/power up时,会更新cpus_kick_bit变量并将kick_bit变量清0,同时喂外部WDT狗。
当只剩1个CPU时,并且该CPU要进入睡眠,此时kernel进入suspend状态,WDT模块当然也要关闭的,唤醒时再重启开启。那睡眠后的流程卡死怎么办?那已超出WDT管辖的范围了,需要用其他硬件保证,不在该文章讨论范围。
3 WDT驱动
android系统中,启动分好几个阶段:preloader、lk、kernel、android。因此每个阶段都要配置WDT,才能保证不卡死。这里我们介绍kernel阶段的WDT驱动,其他阶段是类似的。
这里我们没有用到kernel原生的WDT驱动,而是前面章节讲的那套机制。具体代码位置:
流程是:module_init(mtk_wdt_init) => mtk_wdt_init() =>mtk_wdt_probe()。
在mtk_wdt_probe()函数里,做了如下几件事:
- 注册WDT IRQ处理函数wdt_fiq(),kernel本身是没有使用FIQ的,因此WDT FIQ发生时一定会被处理,除非FIQ被关闭或硬件故障了。由于64bit kernel默认支持ATF(ARM Trusted Firmware),FIQ为security interrupt,kernel是无法处理security interrupt的,因此FIQ会路由到ATF里处理。在后面的流程中会详细介绍。
- 设定WDT超时时间30s。
- 调用mtk_wdt_mode_config()初始化WDT,这里打开的dual mode。
这样就完成WDT的初始化了,WDT初始化是比较早的,基本上3s内就完成了(kernel时间)。以下是72KK版本的uart log中搜索wdt结果:

睡眠/唤醒
在系统进入睡眠时,WDT要被关闭,不过不是在WDT suspend里关闭WDT,因为suspend不是睡眠最后的步骤。这里会在sleep模块通过调用WDK的wd_suspend_notify()来间接调用mtk_wd_suspend()来关闭WDT的。同理唤醒时也是早于resume流程就被sleep模块通过WDK的resume_notify()调用mtk_wd_resume()重新启动WDT。
重启
系统重启(比如adb reboot)是通过WDT来完成复位的,在驱动里提供了wdt_arch_reset()函数,这个函数通过写WDT_SWRST寄存器完成软件复位。基本上重启的log都长这样:

红线以上是正常的log,写完WDT_SWRST寄存器基本就复位了,但有些平台并不是立即生效,需要过几百毫秒才完成复位,因此有可能看到红线以下的log,这是正常的。
喂狗函数
WDT启动后就开始计时了,如果没人喂狗就会触发FIQ,然后在硬复位。因此需要提供了mtk_wdt_restart()函数,调用一次就将计数清0。
如果有驱动需要长时间关中断运行,比如开机时的TP固件升级,就需要在里面添加喂狗动作,防止HWT。
开关WDT
有时为了调试,我们需要关闭看门狗,驱动里也提供了开启/关闭函数:mtk_wdt_enable()。如果你要关闭WDT,可以直接在代码里调用这个函数,那么WDT就永久关闭了。
在WDK驱动里还提供了用户接口,可以很方便在adb shell里关闭/打开WDT。
结语
WDT驱动比较简单,基本都是控制WDT硬件寄存器达到所需效果。重点还在于WDK驱动(喂狗模块)。
4 WDK驱动
wdk是喂狗模块,由于只有一个WDT,而需要保护多个CPU不卡死,根据前面设计的原理来设计wdk驱动,驱动具体位置:
对外接口


初始化
- 通过mtk_rgu_sysfs()创建了sysfs文件系统节点。
- 通过start_kicker()创建per CPU的喂狗进程wdtk-x,这些进程都是系统中优先级最高的进程,执行的核心函数是kwdt_thread(),里面实现了前面提到的喂狗框架。
- 通过wk_proc_init()创建了proc文件系统节点/proc/wdk。我们可以通过它来设定超时时间、喂狗时间、打开/关闭WDT。格式如下(如关闭WDT):echo 0 20 30 0 0 > /proc/wdk
- 参数1:目前没用到,可以忽略,直接写0。
- 参数2:喂狗间隔,默认20,单位秒。
- 参数3:超时时间,默认30,单位秒。
- 参数4:目前没用到,可以忽略。
- 参数5:打开/关闭WDT。
- 根据当前online CPU状况更新cpus_kick_bit并注册CPU hotplug回调函数,因为CPU会根据负载上电/下电,因此需要及时更新cpus_kick_bit、kick_bit。
需要注意的是:
- WDT初始化和WDK初始化是处于kernel初始化的不同阶段,WDT通过module_init()完成,而WDK通过late_initcall(),中间隔着各种驱动,因此如果有些驱动执行时间太长,会导致开机30s HWT的问题,这个在后面章节提到。
- 在KK1.MP11以前的版本启动喂狗进程时,会直接调用到kwdt_thread(),里面会设置一遍kick_bit,最后等于cpus_kick_bit然后喂WDT,但实际上第1次kick并没有累加起来,查看log:

- 看到所有wdk进程起来后,都会设置kick_bit(就是local_bit),但是没有累加起来,无法等于0xf,也就无法喂WDT,真正喂狗是在20s之后,从时间轴来看:

- 这是为什么呢?原因是start_kicker()里没创建完进程,就会调用wk_cpu_update_bit_flag()将kick_bit清0,因此无法累加。KK1.MP11及之后的版本就没有再调用wk_cpu_update_bit_flag(),因此wdk初始化完就会完成第1次喂狗。
喂狗
kwdt_thread()完成喂狗动作,里面就是一个循环:
- 如果需要更新超时时间,则在这里调用wdt函数更新。
- 更新对应CPU的kick_bit,如果等于cpus_kick_bit则清除kick_bit并喂WDT。
- 显示UTC时间,主要用于kernel和android时间同步,这条log非常重要,如果要看android log当时对应的kernel log,就可以通过这条log找到大致的位置。由于WDK是每20s跑一次,因此这条log也是每20s输出一次,如下:[ 25.876493]<1>[thread:187][RT:25867046616] 2015-01-01 00:10:38.35106 UTC; android time 2015-01-01 00:10:38.35106
- 睡眠20s
各个CPU的kwdt_thread()没有同步,因此各自喂狗的时间不定,但只要喂狗间隔不超过30s就没有事。
CPU hotplug
由于有注册CPU hotplug回调函数,因此在某颗CPU上电时,会将cpus_kick_bit对应的bit置位并同时喂狗。下电时,会清除cpus_kick_bit对应bit位并同时喂狗。
5 超时触发流程
-
__vectors_start + 0x1C:这是异常向量表FIQ入口,所有FIQ中断都会导向这里。
-
fiq_glue():FIQ入口直接调用了这个函数,此时处于FIQ mode,用独立的栈,只要还在这个独立的栈里就无法调用printk输出log,原因是printk使用了current(),会从栈底取出thread_info结构体,而该独立的栈咩有thread_info结构体。
-
fiq_isr():这个函数更新了fiq_step。后面会继续讲fiq_step内容。
-
wdt_fiq():到了WDT注册的中断函数了,这里还是无法使用printk,因此只能调用aee_wdt_printf()打印到buffer里。这里印出了最重要的信息kick和check(对应的kick_bit和cpus_kick_bit),比如:kick=0x00000007,check=0x0000000f。得到kick和check就知道是哪些CPU没有喂狗了,接下来重点关注没喂狗的CPU调用栈等信息。
-
aee_wdt_fiq_info():这个函数首先将栈切换为当前进程栈,就可以用printk了。另外当前CPU的寄存器打印到per CPU buffer里。最后只允许一个CPU继续往下走,其他CPU直接死循环等待重启了。
-
aee_wdt_irq_info():这个函数将输出重要log
-
喂狗,防止超时。
-
停止其他CPU。
-
将per CPU buffer输出到last_kmsg。注意:只输出到last_kmsg,kernel log是看不到的。last_kmsg里的log如下:
-
| cpu 0 preempt=1, softirq=0, hardirq=0 cpu 0 backtrace : c0344a1c, c0344a1c, cpu 1 preempt=0, softirq=0, hardirq=0 |
-
如果后面流程卡住了,那么能参考的信息只有last_kmsg了,因此这个信息尤为重要,里面包含CPU寄存器和调用栈。
- 如果没有卡住,那么在kernel log也可以看到这些信息,类似如下:
-
| [ 203.439400]CPU 1 FIQ: Watchdog time out |
-
我们重点看CPU Backtrace部分,这些都是函数地址,需要将地址转换为函数名和所在文件、行号。则需要用到arm-linux-android-addr2line(用于32位)/aarch64-linux-android-addr2line(用于64位,详情请查看quick start => Native Exception问题深入解析 => 进阶篇: coredump分析 => GNU tools)和vmlinux(必须是当时一起编译出来的,如果后面有更新过,addr2line得出的结果可能错误)。比如:
./prebuilts/gcc/linux-x86/aarch64/aarch64-linux-android-4.9/bin/aarch64-linux-android-addr2line -Cfe vmlinux 0xffffffc00014e68c => ring_buffer_unlock_commit()
全部转换后就可以看到完整的调用栈了,有助于我们分析哪里卡住。
-
-
调用mt_aee_dump_sched_traces()输出中断信息。这个信息只有eng版本才打开(user版本打开方法请参考[FAQ15102]如何调试IRQ引起的HWT?)。这个有什么用呢?HWT有一个原因是IRQ太过频繁导致,因此IRQ信息能直接看出原因
-
当前CPU中断信息,可以看到上次IRQ/SoftIRQ/tasklet/hrtimer/SoftTimer信息,如果HWT时调用栈在IRQ里,还可以看到该IRQ的信息,可以判断执行是否太久。
-
IRQ Status会印出所有中断在Dur时间段里触发次数,如果太多就有问题了(比如>1000次每秒)。
-

-
将aee wdt buffer打印到last_kmsg,之前是per CPU buffer,这次是aee wdt buffer:
-
| kick=0x00000007,check=0x0000000f Qwdt at [292641.063701] |
,这里才能从last_kmsg看到kick/check信息。
-
BUG(),之后就是正常的die/panic流程了,所以kernel log总能看到PC is at aee_wdt_irq_info。看到这个信息就可以判断是HWT了。
建议了解下ATF相关内容再来看下面的知识点。


kernel发生异常或HWT,当时的系统是不稳定的,无法保证panic或上面的WDT FIQ流程能顺利走完。因此我们使用fiq step标记走到了哪里,如上面的WDT fiq流程里,基本上每走几步就通过aee_rr_rec_fiq_step()记录特定的数字。在db解开后的SYS_REBOOT_REASON、SYS_LAST_KMSG和__exp_main.txt都会有fiq step以供查看,如下:
请结合代码理清一遍流程,知道哪条log从哪个函数打印出来。如果需要加log调试,也知道该加在哪个位置。
学完WDT/WDK相关内容并不代表就可以独立解决HWT/HW REBOOT的问题了,还需要很多kernel基础知识支撑才行,因为任何模块都不是独立存在,在后面的案例分析就会有更深刻的体会了。
6 HWT
开机30s超时
kernel初始化流程:start_kernel() => rest_init(),这个过程都是0号进程完成,在rest_init()就创建了1号进程执行kernel_init(),接着=>kernel_init_freeable() => do_basic_setup() =>do_initcalls()。这个过程是单线程的,都是1号线程完成。
- 驱动初始化时间太长。比如TP需要升级固件,简单的解决方法是手动喂狗。
- 没有配置好或HW故障,打印出很多error log。特别是I2C,出现异常会连续try几次,如果发的cmd较多,会严重拉长初始化时间。还有其他模块如MSDC异常等。因此应该修复这类问题。
- 其他HW故障或代码逻辑卡死。比较复杂,需要具体问题具体分析了。
初始化时间长的问题,可以通过uart log检索[1:swapper/0]关键字分析就行了。后面有详细例子讲解。
分析所需材料:
- db、vmlinux和uart log
- db在sd卡下的mtklog/aee_exp,或/data/aee_exp目录下
- vmlinux在codebase里的out/target/product/$proj/obj/kernel_obj/vmlinux
kernel运行过程中30s超时
此时WDK已初始化好,而喂狗进程都是优先级最高的实时进程,其他任何进程都无法卡到喂狗进程。那谁可以卡到喂狗进程呢?换句话说,谁可以影响到系统调度?答案有:
- 长时间关闭中断。这个直接无法调度了,还可以细分为:
- 关中断的CPU死锁
- 关中断后陷入循环
- 中断频繁触发。则导致CPU超载,进程基本没有机会被执行到。
- 长时间关抢断。
- 其他HW故障,如总线卡死或HW不稳定。
分析方法:
- 获取kick/check bit得知哪些CPU没喂狗,查看last_kmsg/kernel log看这些CPU的调用栈(《超时触发流程》有讲如何转换CPU Backtrace),看是否卡在锁里。
- 如果怀疑中断过多,则需要eng版本复现抓取db,看isr monitor显示的各个中断触发的频率,判断是哪个中断引起,再找对应的驱动解决。
- 如果发现不符合逻辑引起的卡死,可能是HW不稳定,需要按其他方式处理。
分析所需材料
- db、vmlinux,必要时需要uart log或mobile log。
- db在sd卡下的mtklog/aee_exp,或/data/aee_exp目录下
- vmlinux在codebase里的out/target/product/$proj/obj/kernel_obj/vmlinux
7 HW REBOOT
HW reboot原因
WDT第1阶段超时将触发FIQ,如果CPU没有响应或CPU响应了但没有在第2阶段超时时间内完成重启,就好导致第2阶段超时发出复位信号复位整个系统,生成的db类型就是HW reboot。
可以看到HW reboot定义很简单,这样导致了许多问题都导向了HW reboot,而处理问题的方法都不一样。那有哪些异常会导致HW reboot?有如下:
- 多个异常先后发生,这种情况,我们只关注第1个异常就够了,之后的异常可能因为系统已不稳定发生的异常。比如发生KE,在panic flow卡住引起HWT,HWT flow又卡住直接HW reboot了。这种情况,我们只关注KE而不是HW reboot。
- ATF发生panic,ATF层是无法处理任何中断(包括WDT FIQ),里面发生了panic之后都是死循环等待HW reboot。这个不能按HW reboot方式处理,需要看atf log分析解决问题。
- preloader/lk发生panic,和ATF一样,发生HW reboot。但不能按HW reboot的方式处理,这种情况应该看uart log(preloader/lk部分),分析解决问题。
- HW故障,CPU无法正常执行。这个就是纯粹的HW reboot了,也是我们后面要关注的。
HW reboot调试信息
基于HW reboot产生原因的复杂性。我们要学会如何区分呢?首先我们要了解哪些信息可以给我们参考。HW reboot没走任何软件流程,是直接复位的,无法知道CPU处于什么状态,因为重启后什么都丢了,不像kernel panic或HWT有详尽的CPU寄存器和调用栈参考。其实HW reboot还是有些硬件模块记录了当时的情况。
wdt status/fiq step
在preloader初始化WDT前保留了WDT_STA寄存器的值,并转化为wdt status(或者叫hw_status),这个值保存在SYS_REBOOT_REASON/SYS_LAST_KMSG/__exp_main.txt,和fiq step一起。详情可参考:[FAQ14332]SYS_LAST_KMSG里的hw_status和fiq step的含义。
wdt status提供了重启的原因,1或5是HW reboot,2是SW reboot等。fiq step的值为0或非0提供了是否走了kernel panic或HWT的流程。如果fiq step不为0,即使wdt status为1或5,我们都不会当成HW reboot来分析。这种情况的原因是panic或HWT流程卡住导致HW reboot了,我们需要参考last kmsg,按普通的kernel panic或HWT分析,找问题的原因。
如果wdt status为1或5且fiq step为0,那么这个就是HW reboot了。如何调试呢?好像这些信息无法帮我们找到问题。我们继续看还有哪些调试信息。
last pc
从82/92及之后的平台,WDT发出复位信号的同时锁存了online CPU的PC/FP/SP。在重启后记录在db的SYS_REBOOT_REASON里,格式如下:
| [LAST PC] CORE_0 PC = 0xc022c3ac(buffer_size_add_atomic + 0x1c), FP = 0xc0c278dc, SP = 0xc0c278c8 [LAST PC] CORE_1 PC = 0xc036b1ac(aee_smp_send_stop + 0x4), FP = 0xdd9fbee4, SP = 0xdd9fbeb8 [LAST PC] CORE_2 PC = 0xc036b1ac(aee_smp_send_stop + 0x4), FP = 0x25, SP = 0xdcf4bff8 [LAST PC] CORE_3 PC = 0x0( + 0x4), FP = 0x0, SP = 0x0 |
有些平台有特别的设定,比如MT6795的PC值有特别的含义:
- 0xa0a0a0a0a0a0a0a0:PC为空,表示没抓到last PC。
- 0xb0b0b0b0b0b0b0b0:抓取last PC失败。
还有PC所指地址代表的含义大家也要清楚才行,以前平台的AP是扁平结构,PC值所在位置要吗在user space:0~0xBF000000,要吗在kernel space:0xBF000000~0xFFFFFFFF,后面引入64位使问题变复杂了。在aarch64下,PC值可能值NS EL0 user space,也可以是NS EL1 kernel space,或者SEC EL3 ATF及SEC EL1 TEE OS的。因此就需要了解整个框架,才能进一步判断PC来自于哪一层了:
- 64bit kernel space:0xFFFFFF8000000000~0xFFFFFFFFFFFFFFFF。其中0xFFFFFFC000080000开始就是kernel代码起始地址。
- 64bit user space:0~0x7fffffffff,所有app都跑在这里。
- ATF space:不同平台有不同的layout。
- MT6752/MT6580/MT6795/MT6797的ATF代码段位于0x111000-0x12C400
- MT6735/MT6753/MT6735M位于0x43001000-0x43020000
- MT6755位于0x101000-0x120000
通过last PC可以知道在最后时刻,各个CPU都在干什么。一般会检查PC所在函数:
- 是否是个死循环。看之前是否关闭了FIQ,如果是,则需要检查代码。
- 正在读写寄存器。读写已关闭clock/power的模块的寄存器会引起bus hang,引起HW reboot。这时要检查读写了哪个模块的寄存器,如果是chip内部模块,直接找Mediatek分析。
- 不在任何space里。那可能跑飞了,多半是HW不稳定引起。需要测量CPU vproc/vsram/Vm等重要电压,看异常发生前是否发生过drop等异常现象。
- 在正常函数里。但没有死循环或其他可疑的地方,这种也可能是HW不稳定,和上面的case一样测量重要电压。
system tracker
上面有提到,如果是读写了已关闭clock/power的寄存器会引起bus hang,最后HW reboot。如何调试这种情况呢?在MT6595及之后引入了system tracker,这个硬件模块会监控bus情况,如果卡死会送一个abort信号给CPU,CPU会进入kernel panic流程。但有时这个bus hang会引起CPU bus卡死,导致CPU也动不了而变成HW reboot。不过bus hang信息还保留在system tracker模块中,重启后会被打包到HW reboot db里。
如果db里存在SYSTRACKER_DUMP文件,那一定是发生过bus hang了,该文件内容如下:
| read entry = 0, valid = 0x0, tid = 0x0, read id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 read entry = 1, valid = 0x0, tid = 0x0, read id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 read entry = 2, valid = 0x0, tid = 0x0, read id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 read entry = 3, valid = 0x0, tid = 0x0, read id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 read entry = 4, valid = 0x0, tid = 0x0, read id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 read entry = 5, valid = 0x0, tid = 0x0, read id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 read entry = 6, valid = 0x0, tid = 0x0, read id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 read entry = 7, valid = 0x0, tid = 0x7, read id = 0x203, address = 0x11230014, data_size = 0x2, burst_length = 0x0 write entry = 0, valid = 0x0, tid = 0x0, write id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 write entry = 1, valid = 0x0, tid = 0x0, write id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 write entry = 2, valid = 0x0, tid = 0x0, write id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 write entry = 3, valid = 0x0, tid = 0x0, write id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 write entry = 4, valid = 0x0, tid = 0x0, write id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 write entry = 5, valid = 0x0, tid = 0x0, write id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 write entry = 6, valid = 0x0, tid = 0x0, write id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 write entry = 7, valid = 0x0, tid = 0x0, write id = 0x0, address = 0x0, data_size = 0x0, burst_length = 0x0 |
上面记录的地址是物理地址,需要查找datasheet看是哪个模块的寄存器。然后检查代码,看看last pc所在函数是否有可能当时的power/clock被关闭了。
Low-Power功能标记
在SYS_REBOOT_REASON不只有wdt status、fiq step和last pc,还有一堆如下内容的信息:
| mcdi_wfi: 0x0 ...... |
这些信息显示了系统当时的状态,比如是否进入sodi,当时dvfs档位状态等等。因为系统的复杂性,这些信息也算是提供一些参考吧。
CPU hot plug
还有一个重要的信息就是hot plug信息,每个CPU都有,不过CPU0比较特殊,因为不会发生hot plug(在新平台上,CPU0也会发生hot plug),因此有3个参数,其他CPU都只有1个参数:
| CPU 0 |
CPU0的的参数含义如下:

CPU事件定义在kernel-3.10/include/linux/cpu.h里(2表示CPU_ONLINE):
#define CPU_ONLINE 0x0002 /* CPU (unsigned)v is up */
#define CPU_UP_PREPARE 0x0003 /* CPU (unsigned)v coming up */
#define CPU_UP_CANCELED 0x0004 /* CPU (unsigned)v NOT coming up */
#define CPU_DOWN_PREPARE 0x0005 /* CPU (unsigned)v going down */
#define CPU_DOWN_FAILED 0x0006 /* CPU (unsigned)v NOT going down */
#define CPU_DEAD 0x0007 /* CPU (unsigned)v dead */
#define CPU_DYING 0x0008 /* CPU (unsigned)v not running any task, not handling interrupts, soon dead. Called on the dying cpu, interrupts are already disabled. Must not sleep, must not fail */
#define CPU_POST_DEAD 0x0009 /* CPU (unsigned)v dead, cpu_hotplug lock is dropped */
#define CPU_STARTING 0x000A /* CPU (unsigned)v soon running. Called on the new cpu, just before enabling interrupts. Must not sleep, must not fail */
其他CPU参数含义如下(比如54表示CPU已经下电了):

last kmsg
最后的参考资料是last kmsg,看看是否存在异常。如果没有看到异常,就看最后log停在哪里。猜测和哪个模块相关,然后进一步调试。
分析方法
有了以上的调试信息,我们就可以开始分析了。纯粹的HW reboot一般和HW相关性较大。结合以上信息还不足以定位,通常还需要更多信息,比如复现次数等,大致分析如下:
|
复现概率
|
可能的问题
|
调试方向
|
|
仅1次
|
SW/HW
|
软件分析
|
|
多次,lastpc固定
|
SW
|
软件分析
|
|
多次,随机
|
HW
|
1. 信息调查
2. 软件分析
3. HW验证
|
仅1次复现,如果以上的调试信息看不出问题点就只能后面在关注是否再次发生了。
可复现的话,需要关注复现路径,发生问题的时间点,结合多次复现的db统一分析,看是否有相似性。
随机问题,基本导向HW故障,还需要进一步做信息调查:
|
排查项
|
结果
|
说明
|
|
PDN仿真
|
必须通过
|
非常重要,是HW稳定性的保证
|
|
硬件模块
|
所有的物料必须是Mediatek QVL验证过的
|
如MCP/晶振…
|
|
ETT (EMI Timing Tuning) |
必须通过
|
非常重要,保证memory工作稳定性
|
|
3D Stress Test
|
必须通过10小时测试
|
保证系统稳定性
|
|
Driver Only版本验证
| 正常: 可能是SW问题 异常: 可能是HW问题 |
如果软件分析没有任何进展,则需做HW验证:
|
排查项
|
说明
|
|
模块加热
|
验证是否SMT焊接不良
|
|
测量Vproc/Vmem等重要电压
|
查看波形是否有异常drop等现象
|
|
CPU/Memory降频
|
验证layout是否不良
|
|
CPU交叉
|
验证CPU是否不良
|
|
MCP交叉
| 验证MCP是否不良 |
结语
HW reboot是一个复杂的问题,需要积累经验及扩大知识面。还要积累各种调试手段,比如DVFS开关,hotplug开关等,这样调试起来才比较顺手。
8 HWT-kernel初始化时间长(1)
基本信息
分析过程
抓取uart log,如下:
| [ 30.881685] (0)[0:swapper/0]------------[ cut here ]------------ [ 30.882424] (0)[0:swapper/0]Kernel BUG at c034a578 [verbose debug info unavailable] [ 30.883379] (0)[0:swapper/0]Internal error: Oops - BUG: 0 [#1] PREEMPT SMP ARM [ 30.884278] (0)[0:swapper/0]Modules linked in: devinfo bf08c000 pvrsrvkm bf000000 [ 30.886092] (0)[0:swapper/0]CPU: 0 Not tainted (3.4.5 #1) [ 30.886811] (0)[0:swapper/0]PC is at aee_wdt_irq_info+0x180/0x188 [ 30.887565] (0)[0:swapper/0]LR is at aee_wdt_irq_info+0x180188 |
| [ 22.661560] (2)[1:swapper/0][wdk]bind thread[82] to cpu[0] |
- start_kernel() -> rest_init()在rest_init()创建2个进程跑:kernel_init()和kthreadd(),其中kernel_init()之后就加载init,也就是init进程了。
- kernel_init() -> init_post() -> Kernel_init_done,这条log差不多在开机3s左右要印出来的,但是客户的log:
| [ 22.698744] (0)[1:swapper/0]BOOTPROF: 22698.741231:Kernel_init_done |
- 内核中很多驱动通过module_init(),late_init()等方法初始化,在内核初始化中在do_one_initcal()调用这些注册的函数的。
- kernel_init() -> do_basic_setup() -> do_initcalls() -> do_initcall_level() -> do_initcall_level() -> do_one_initcal() -> xxx()
这些函数都是在1号进程里执行(单进程),因此我们只要查看[1:swapper/0]的log(为何是1:swapper/0呢?因为init还没被加载,所以fork出来的名字和父进程0:swapper/0一样),就可以知道卡在哪里了:
| [ 1.671991] (2)[1:swapper/0]platform_device_usbacm_register done! [ 1.672388] (2)[1:swapper/0]<HWMSEN> hwmsen_create_attr ...... [ 3.670777] (3)[1:swapper/0]i2c i2c-3: addr: 30, transfer timeout [ 3.688464] (3)[1:swapper/0][Gsensh error -1 [ 3.690363] (3)[1:swapper/0]sensor_gsensor device! ...... [ 3.886192] (3)[59:mtk charger_hv_][Power/Battery] [upmu_is_chr_det] Charger exist but USB is host [ 5.710786] (3)[1:swapper/0]i2c i2c-3: addr: 60, transfer timeout [ 7.730774] (3)[1:swapper/0]i2c i2c-3: addr: 60, transfer timeout [ 9.750998] (0)[1:swapper/0]i2c i2c-3: addr: 60, transfer timeout [ 9.779278] (0)[1:swapper/0]I2C_TxData retry over 3 [ 9.779880] (0)[1:swapper/0]mmc3416x_device set TM cmd failed [ 9.780597] (0)[1:swapper/0]mmc3416x_i2c_probe: err = 0 [ 9.781303] (0)[1:swapper/0]sensor_msensor device! ...... sensor_osensor device! <HWMSEN> alsps_probe + [ 9.782636] (0)[1:swapper/0]<HWMSEN> i=0 [ 9.783133] (0)[1:swapper/0]<HWMSEN> !!!!!!!! [ 11.780995] (0)[1:swapper/0]i2c i2c-3: addr: 90, transfer timeout [ 11.798700] (0)[1:swapper/0]<HWMSEN> hwmsen_write_block 218 : send command error!! [ 11.789302] (0)[1:swapper/0]FIFO_ST]DEBUGSTAT 41 [ 11.789325] (0)[1:swapper/0]EXT_CONF 8001 [ 11.798700] (0)[1:swapper/0]<HWMSEN> hwmsen_write_block 218 : send command error!! [ 13.790782] (2)[1:swapper/0]i2c i2c-3: addr: 90, transfer timeout [ 15.800772] (3)[1:swapper/0]i2c i2c-3: addr: 90, transfer timeout ...... [ 17.820783] (0)[1:swapper/0]i2c i2c-3: addr: 72, transfer timeout [ 19.901021] (2)[1:swapper/0]i2c i2c-3: addr: 72, transfer timeout swapper/0][ALS/PS] tmd2772_ps_calibrate 2340 : tmd2772_read_dat [ 20.076029] (2)[59:mtk charger_hv_][Power/Battery] [upmu_is_chr_det] Charger exist but USB is host [ 21.910769] (3)[1:swapper/0]i2c i2c-3: addr: 72, transfer timeout |
可以看到很多设备初始化失败(存在i2c error)并且花了20多s的时间。
解决方法
这些设备的I2C error全部都要解决,解决这些问题之后kernel就可以在3s内完成初始化,也就不会再发生30s HWT了。
结语
解决这类问题,首先要对kernel初始化流程有所了解。否则即使知道HWT,也无法找到问题点。
9 HWT-kernel初始化时间长(2)
基本信息
问题:在recovery mode中,会出异常并自动进入normal mode
版本:ALPS.JB2.MP.V1.2
平台:MT6589
分析过程
抓取uart log,如下:
| [ 32.049822]-(0)[0:swapper/0]------------[ cut here ]------------ [ 32.050584]-(0)[0:swapper/0]Kernel BUG at c03e611c [verbose debug info unavailable] [ 32.051553]-(0)[0:swapper/0]Internal error: Oops - BUG: 0 [#1] PREEMPT SMP ARM [ 32.052467]-(0)[0:swapper/0]Modules linked in: sec bf000000 [ 32.053184]-(0)[0:swapper/0]CPU: 0 Not tainted (3.4.5 #1) [ 32.053917]-(0)[0:swapper/0]PC is at aee_wdt_irq_info+0x18c/0x194 [ 32.054690]-(0)[0:swapper/0]LR is at aee_wdt_irq_info+0x18c/0x194 [ 32.055466]-(0)[0:swapper/0]pc : [<c03e611c>] lr : [<c03e611c>] psr: a00001d3 [ 32.055483]-(0)[0:swapper/0]sp : c097bec8 ip : c097bec8 fp : c097bef4 [ 32.057274]-(0)[0:swapper/0]r10: 00000000 r9 : 00000007 r8 : 02f0d691 [ 32.058112]-(0)[0:swapper/0]r7 : 108c7683 r6 : 36b4a597 r5 : c11c610c r4 : c11c80e0 [ 32.059114]-(0)[0:swapper/0]r3 : f900dc00 r2 : 00000001 r1 : 00000000 r0 : 00000011 ...... |
这是典型的开机30s WDT timeout的case,查看CPU0的backtrace,发现已经进入idle了。按照解题思路,需要查看WDK初始化情况,在log中搜索WDK关键字:
| [ 20.206559] (2)[1:swapper/0][wdk]bind thread[82] to cpu[0] [ 20.208030] (1)[1:swapper/0][wdk]bind thread[83] to cpu[1] [ 20.209502] (0)[1:swapper/0][wdk]bind thread[84] to cpu[2] [ 20.210968] (3)[1:swapper/0][wdk]bind thread[85] to cpu[3] [ 20.211860] (3)[1:swapper/0][WDK] Initialize proc [ 20.214890] (1)[0:swapper/1][WDK], local_bit:0x0, cpu:1,RT[20208893385] [ 20.214906] (1)[0:swapper/1][WDK], local_bit:0x2, cpu:1, check bit0x:f,RT[20208902077] [ 20.214988] (2)[0:swapper/2][WDK], local_bit:0x0, cpu:2,RT[20210369385] [ 20.215004] (2)[0:swapper/2][WDK], local_bit:0x4, cpu:2, check bit0x:f,RT[20210378616] [ 20.215086] (0)[0:swapper/0][WDK], local_bit:0x0, cpu:0,RT[20207444154] [ 20.215101] (0)[0:swapper/0][WDK], local_bit:0x1, cpu:0, check bit0x:f,RT[20207453769] [ 20.235501] (3)[0:swapper/3][WDK], local_bit:0x0, cpu:3,RT[20228500616] [ 20.235518] (3)[0:swapper/3][WDK], local_bit:0x8, cpu:3, check bit0x:f,RT[20228510769] |
可以看到kicker thread在20s左右才创建的,有问题,因此搜索[1:swapper/0]的log:
| [ 3.076383] (1)[1:swapper/0][TSP] Step 0:init [ 3.185245] (2)[1:swapper/0]version=0 ,pbt_buf[sizeof(CTPM_FW)-2]=12 [ 3.187259] (1)[1:swapper/0][TSP]ID_ver=79, fw_ver=c [ 6.988020] (1)[58:mtk battery_kth][Power/Battery] g_bat_thread_count : done [ 6.992361] (2)[59:bat_thread_kthr][Power/Battery] [FGADC] after gFG_voltage=3777 ...... [ 7.056265] (2)[59:bat_thread_kthr][Power/Battery] [tbat_workaround] 277,296,0,461,43 [ 7.057258] (2)[59:bat_thread_kthr] [BATTERY:AVG:fan5405] BatTemp:32 Vbat:3693 VBatSen:3690 SOC:30 ChrDet:0 Vchrin:332 Icharging:12 ChrType:0 USBstate:1 [ 7.076835] (2)[59:bat_thread_kthr][Power/Battery] [FG] 30,30,30,30,3693,ADC_Solution=0 [ 7.078606] (1)[59:bat_thread_kthr][BATTERY] pchr_turn_off_charging_fan5405 ! [ 7.079946] (1)[59:bat_thread_kthr][fan5405] [0x0]=0x80 [0x1]=0xbc [0x2]=0x8e [0x3]=0x91 [0x4]=0xbc [0x5]=0xc [0x6]=0x77 [ 11.988125] (2)[58:mtk battery_kth][Power/Battery] g_bat_thread_count : done [ 12.026180] (1)[59:bat_thread_kthr][Power/Battery] [FGADC] 0,4547,0,0,3777,31,30,30,2475,2468,88,0,0,1000,3689,1000,70,70,4890,93,103 [ 12.031807] (1)[59:bat_thread_kthr][MUSB] USB is ready for disconnect [ 12.046252] (2)[59:bat_thread_kthr][Power/Battery] [tbat_workaround] 275,295,0,466,43 ...... [ 12.068267] (2)[59:bat_thread_kthr][BATTERY] pchr_turn_off_charging_fan5405 ! [ 12.069591] (1)[59:bat_thread_kthr][fan5405] [0x0]=0x80 [0x1]=0xbc [0x2]=0x8e [0x3]=0x91 [0x4]=0xbc [0x5]=0xc [0x6]=0x77 [ 17.026105] (2)[59:bat_thread_kthr][Power/Battery] [FGADC] 0,4433,0,0,3776,31,30,30,2475,2468,86,0,0,1000,3689,1000,70,70,4767,93,103 [ 17.031727] (1)[59:bat_thread_kthr][MUSB] USB is ready for disconnect [ 17.046246] (2)[59:bat_thread_kthr][Power/Battery] [tbat_workaround] 274,293,0,455,43 ...... [ 17.066717] (2)[59:bat_thread_kthr][Power/Battery] [FG] 30,30,30,30,3692,ADC_Solution=0 [ 17.068802] (2)[59:bat_thread_kthr][BATTERY] pchr_turn_off_charging_fan5405 ! [ 17.070128] (1)[59:bat_thread_kthr][fan5405] [0x0]=0x80 [0x1]=0xbc [0x2]=0x8e [0x3]=0x91 [0x4]=0xbc [0x5]=0xc [0x6]=0x77 [ 19.635844] (1)[1:swapper/0][TSP] Step 8:init stop [ 19.637048] (1)[1:swapper/0][wj]the version is 0x0c. [ 19.638199] (0)[1:swapper/0][TSP] ret =1 [ 19.639019] (3)[1:swapper/0]mtk-tpd: ft5206 Touch Panel Device Probe PASS |
看到TSP初始化时间间隔是很长的(16s),检查TSP驱动,发现在kernel启动之后都会对TP做更新rom的动作,导致花费很长时间。
至于为什么normal mode下无问题呢,我们再抓取normal log来看,kiker thread也是20s左右创建的,但是之后CPU有plug off的动作,这个动作伴随着kick external WDT,所以才不会再30s时timeout。
解决方法
修正TP的驱动,仅在必要时才更新rom,并且更新时主动调用喂狗函数喂狗,避免超时。
10 HWT-lk执行时间长
基本信息
问题:项目刚开始,遇到板子下载软件后重启,几片板子都是这样,没有装外设(屏、TP都不装)
版本:ALPS.L0.MP8.V2
平台:MT6735
分析过程
抓取uart log,如下:
| [ 0.358440]<3>.(3)[1:swapper/0][init] f(ffffffc000e12e94) [ 0.359113]<3>.(3)[1:swapper/0] s:358434614 e:358435383 d:769 [ 0.360194]<3>.(3)[1:swapper/0][init] f(ffffffc000e13e9c) [ATF][ 0.360836]inter-cpu-call interrupt is triggered [ATF][ 0.361452]=> aee_wdt_dump, cpu 3 [ATF][ 0.361939]inter-cpu-call interrupt is triggered [ATF][ 0.362578]=> aee_wdt_dump, cpu 1 [ATF][ 0.363067]inter-cpu-call interrupt is triggered [ATF][ 0.363707]=> wdt_kernel_cb_addr=0, error before WDT successfully initialized. cpu 3 [ATF][ 0.364738]=> regs->pc : 0xffffffc0005fc994 [ATF][ 0.365323]=> regs->lr : 0xffffffc0005f77c8 [ATF][ 0.365908]=> wdt_kernel_cb_addr=0, error before WDT successfully initialized. cpu 0 [ATF][ 0.366941]=> wdt_kernel_cb_addr=0, error before WDT successfully initialized. cpu 1 [ATF][ 0.367969]=> regs->pc : 0xffffffc000095628 [ATF][ 0.368555]=> regs->lr : 0xffffffc00008557c [ATF][ 0.369140]=> aee_wdt_dump, cpu 2 [ATF][ 0.369628]=> regs->sp : 0xffffffc03d8f3f60 [ATF][ 0.370214]=> regs->pc : 0xffffffc000095628 [ATF][ 0.370801]=> regs->lr : 0xffffffc00008557c [ATF][ 0.371385]=> regs->sp : 0xffffffc003077990 [ATF][ 0.371971]=> wdt_kernel_cb_addr=0, error before WDT successfully initialized. cpu 2 [ATF][ 0.373001]=> Informations: pstate=60000185, pc=ffffffc000095628, sp=ffffffc03d8f3f60 [ATF][ 0.374043]=> regs->sp : 0xffffffc000e73f10 [ATF][ 0.374628]regs->regs[1] = 0 [ATF][ 0.375063]=> Informations: pstate=60000385, pc=ffffffc000095628, sp=ffffffc000e73f10 ........ [ATF][ 0.469879]=> wait until reboot... |
这是典型的刚进kenrel就发生WDT timeout的case,为什么会这样?
我们看到log:wdt_kernel_cb_addr=0, error before WDT successfully initialized
这个log从哪里来的?代码如下:
vendor/arm/atf-1.0/plat/common/aarch64/plat_common.c
void aee_wdt_dump()
{
......
printf("=> aee_wdt_dump, cpu %d \n", (int)linear_id);
ns_cpu_context = cm_get_context_by_mpidr(mpidr, NON_SECURE);
atf_arg_t_ptr teearg = (atf_arg_t_ptr)(uintptr_t)TEE_BOOT_INFO_ADDR;
regs = (void *)(teearg->atf_aee_debug_buf_start + (linear_id * sizeof(struct atf_aee_regs)));
regs->pstate = SMC_GET_EL3(ns_cpu_context, CTX_SPSR_EL3)
......
if(0 == wdt_kernel_cb_addr) {
set_uart_flag();
printf("=> wdt_kernel_cb_addr=0, error before WDT successfully initialized. cpu %d\n", (int)linear_id);
printf("=> regs->pc : 0x%lx\n", regs->pc);
printf("=> regs->lr : 0x%lx\n", regs->regs[30]);
printf("=> regs->sp : 0x%lx\n", regs->sp);
......
}
......
}
ATF是跑在kernel下面的固件,WDT timeout FIQ直接有ATF管理,所以ATF需要将其路由到kernel。通常情况下kernel初始化wdk驱动时会告诉ATF wdt timeout的handler,具体代码在:
kernel-3.10/drivers/misc/mediatek/aee/common/wdt-atf.c
static int __init aee_wdt_init(void)
{
......
/* send SMC to ATF to register call back function */
#ifdef CONFIG_ARM64
atf_aee_debug_phy_addr = (phys_addr_t)(0x00000000FFFFFFFF&mt_secure_call(MTK_SIP_KERNEL_WDT, (u64)&aee_wdt_atf_entry, 0, 0));
#else
atf_aee_debug_phy_addr = (phys_addr_t)
mt_secure_call(MTK_SIP_KERNEL_WDT, (u32)&aee_wdt_atf_entry, 0, 0);
#endif
LOGD("\n MTK_SIP_KERNEL_WDT - 0x%p \n", &aee_wdt_atf_entry);
if ((atf_aee_debug_phy_addr == 0) || (atf_aee_debug_phy_addr == 0xFFFFFFFF)) {
LOGE("\n invalid atf_aee_debug_phy_addr \n");
} else {
/* use the last 16KB in ATF log buffer */
atf_aee_debug_virt_addr = ioremap(atf_aee_debug_phy_addr, ATF_AEE_DEBUG_BUF_LENGTH);
LOGD("\n atf_aee_debug_virt_addr = 0x%p \n", atf_aee_debug_virt_addr);
if (atf_aee_debug_virt_addr)
memset(atf_aee_debug_virt_addr, 0, ATF_AEE_DEBUG_BUF_LENGTH);
}
return 0;
}
通过SMC call将aee_wdt_atf_entry地址送给ATF,如果发生HWT,ATF就会回调aee_wdt_atf_entry(),不过看到wdt_kernel_cb_addr=0,表明kernel还没跑到这里。也表明kernel连wdt都还没初始化。那为什么还会timeout?
首先要了解:preloader、lk、kernel都会设定WDT timeout时间,preloader是16s,lk是10s,kernel是30s,都是在初始化时就设定好的。
我们观察到kernel才跑到0.360194s,那时还没跑到kernel初始化wdt的代码,也就是说,这时WDT的timeout时间还是用的是lk的设定时间10s,如果lk设定wdt时到kernel设定wdt前超过10s,就会发生WDT timeout,这个timeout可能在lk阶段,也可能在kernel阶段(kernel 设定wdt前,也表明lk执行时间过长,接近超时),我们看下是否是lk执行时间接近超时呢?
eng版本有lk profiling,查看log:
| [18760] cmdline: console=tty0 console=ttyMT0,921600n1 root=/dev/ram vmalloc=496M androidboot.hardware=mt6735 slub_max_order=0 slub_debug=O bootopt=64S3,32N2,64N2 lcm=0-hx8392a_dsi_cmd fps=6000 vram=13172736 printk.disable_uart=0 ddebug_query="file *mediatek* +p ; [18760] lk boot time = 9574 ms |
可以看到lk花的时间接近10s了,给kernel到wdt设定的时间不到0.5s,很容易超时的。
这题的原因是:lk执行时间过长,导致刚到kernel时(还没开始初始化wdt)就发生wdt timeout。需要看lk为何执行时间过久(eng有开lk profiling,搜索PROFILE关键字):
| Line 9050: [0] [PROFILE] ------- WDT Init takes 3 ms -------- Line 9107: [0] [PROFILE] ------- led init takes 15 ms -------- Line 9115: [0] [PROFILE] ------- pmic_init takes 1 ms -------- Line 9117: [0] [PROFILE] ------- platform_early_init takes 24 ms -------- Line 9263: [220] [PROFILE] ------- NAND/EMMC init takes 111 ms -------- Line 9271: [240] [PROFILE] ------- ENV init takes 3 ms -------- Line 10915: [1760] [PROFILE] ------- disp init takes 771 ms -------- Line 10937: [1800] [PROFILE] ------- load_logo takes 26 ms -------- Line 11183: [1940] [PROFILE] ------- boot mode select takes 65 ms -------- Line 11547: [3120] [PROFILE] ------- battery init takes 601 ms -------- Line 11549: [3120] [PROFILE] ------- RTC boot check Init takes 0 ms -------- Line 12725: [4060] [PROFILE] ------- backlight takes 206 ms -------- Line 12727: [4060] [PROFILE] ------- show logo takes 477 ms -------- Line 13277: [4400] [DISP]f[4460] [PROFILE] ------- sw_env takes 202 ms -------- Line 13279: [4460] [PROFILE] ------- platform_init takes 2260 ms -------- Line 13467: [4780] [PROFILE] ------- load boot.img takes 115 ms -------- Line 15443: [18760] [PROFILE] ------- boot_time takes 9574 ms -------- |
就可以看到哪个阶段花的时间长了,如果不够细致,还可以自己添加log分析。
解决方法
通过profile解决异常花时间的模块问题。
这个case主要知识点是ATF接管WDT FIQ的流程,以及如何识别和分析timeout后印uart log。
11 HWT中断频繁触发
问题:高概率出现死机
版本:ALPS.L1.MP3.V1
平台:MT6735M
分析过程
抓取db,解开后查看SYS_KERNEL_LOG,如下:
| [ 175.653764]<0>-(0)[143:kworker/u8:4]Unable to handle kernel paging request at virtual address 0000dead [ 175.654928]<0>-(0)[143:kworker/u8:4]pgd = ffffffc00007d000 [ 175.655608][0000dead] *pgd=000000007f816003, *pmd=000000007f817003, *pte=00e0000043f01703 [ 175.656632]<0>-(0)[143:kworker/u8:4]Internal error: Oops: 96000045 [#1] PREEMPT SMP [ 175.657583]disable aee kernel api [ 175.658029]<0>-(0)[143:kworker/u8:4]mrdump: cpu[0] tsk:ffffffc038bbc000 ti:ffffffc038440000 [ 175.659894]<0>-(0)[143:kworker/u8:4]mrdump: cpu[0] tsk:ffffffc038bbc000 ti:ffffffc038440000 [ 175.660979]<0>-(0)[143:kworker/u8:4]mrdump: cpu[1] tsk:ffffffc00313c000 ti:ffffffc003140000 [ 175.662066]<0>-(0)[143:kworker/u8:4]mrdump: cpu[2] tsk:ffffffc003158000 ti:ffffffc00315c000 [ 175.663153]<0>-(0)[143:kworker/u8:4]mrdump: cpu[3] tsk:ffffffc0031b2000 ti:ffffffc0031b4000 [ 193.335078]<0>-(0)[143:kworker/u8:4]ipanic_func_write: data oversize(21000>20000@c00) [ 193.336053]<0>-(0)[143:kworker/u8:4]ipanic_data_to_sd: dump SYS_KERNEL_LOG failed[-27] [ 193.378800]<0>-(0)[143:kworker/u8:4]CPU: 0 PID: 143 Comm: kworker/u8:4 Tainted: G W 3.10.65+ #1 [ 193.380490]<0>-(0)[143:kworker/u8:4]task: ffffffc038bbc000 ti: ffffffc038440000 task.ti: ffffffc038440000 [ 193.381686]<0>-(0)[143:kworker/u8:4]PC is at aee_wdt_atf_info+0x42c/0x4e8 [ 193.382528]<0>-(0)[143:kworker/u8:4]LR is at aee_wdt_atf_info+0x424/0x4e8 [ 193.383374]<0>-(0)[143:kworker/u8:4]pc : [<ffffffc0003fba0c>] lr : [<ffffffc0003fba04>] pstate: 800001c5 [ 193.384554]<0>-(0)[143:kworker/u8:4]sp : ffffffc0384433f0 [ 193.385226]x29: ffffffc0384433f0 x28: ffffffc0018963e8 |
Unable to handle kernel paging request at virtual address 0000dead的原因是aee_wdt_atf_info()最后调用的BUG()定义如下(kernel-3.10/include/asm-generic/bug.h):
#ifdef __aarch64__
#define BUG() *((unsigned *)0xdead) = 0x0aee
#define HAVE_ARCH_BUG
#endif
就是对0xdead赋值触发kernel crash的。看到PC所在的位置就知道是HWT了。这个不是开机30s HWT,因此需要观察kick/check bit:
| [ 203.512942]kick=0x00000000,check=0x0000000f Qwdt at [ 175.653155] |
共有4个CPU(CPU0~3)online,但都没有喂狗。因此需要一一查看CPU调用栈:
| [ 203.410494]CPU 0 FIQ: Watchdog time out preempt=5, softirq=1, hardirq=1 pc : ffffffc00032dcac, lr : ffffffc00014e68c, pstate : 00000000200001c5 sp : ffffffc0384435c0 ...... [ 203.431300]Backtrace : [ 203.431586]<0>-(0)[143:kworker/u8:4]ffffffc00014e68c, ffffffc00014e688, [ 203.432421]<0>-(0)[143:kworker/u8:4]ffffffc000154448, ffffffc000155074, [ 203.433256]<0>-(0)[143:kworker/u8:4]ffffffc000155428, ffffffc000084950, [ 203.434091]<0>-(0)[143:kworker/u8:4]04208060000001c0, ffffffc0000a3934, [ 203.434926]<0>-(0)[143:kworker/u8:4]ffffffc0000a3cf4, ffffffc000084908, [ 203.435761]<0>-(0)[143:kworker/u8:4]ffffffc038443b10, ffffffc00046f660, [ 203.436597]<0>-(0)[143:kworker/u8:4]ffffffc0004896f4, ffffffc00049f2d8, [ 203.437432]<0>-(0)[143:kworker/u8:4]ffffffc0004927b8, ffffffc000108608, [ 203.438266]<0>-(0)[143:kworker/u8:4] [ 203.438266]<0>========================================== [ 203.439400]CPU 1 FIQ: Watchdog time out preempt=1, softirq=0, hardirq=0 pc : ffffffc00012ed10, lr : ffffffc00012ecd8, pstate : 0000000060000145 sp : ffffffc003143c60 ...... [ 203.460206]Backtrace : [ 203.460493]<0>-(0)[143:kworker/u8:4]ffffffc00012ecd8, ffffffc00012ec24, [ 203.461328]<0>-(0)[143:kworker/u8:4]ffffffc0000ca238, ffffffc0000c1a00, [ 203.462162]<0>-(0)[143:kworker/u8:4]ffffffc00008447c, [ 203.462800]<0>-(0)[143:kworker/u8:4] [ 203.462800]<0>========================================== [ 203.463913]CPU 2 FIQ: Watchdog time out preempt=1, softirq=0, hardirq=0 pc : ffffffc00012ed14, lr : ffffffc00012ecd8, pstate : 0000000060000145 sp : ffffffc00315fc60 ...... [ 203.484720]Backtrace : [ 203.485007]<0>-(0)[143:kworker/u8:4]ffffffc00012ecd8, ffffffc00012ec24, [ 203.485841]<0>-(0)[143:kworker/u8:4]ffffffc0000ca238, ffffffc0000c1a00, [ 203.486676]<0>-(0)[143:kworker/u8:4]ffffffc00008447c, [ 203.487314]<0>-(0)[143:kworker/u8:4] [ 203.487314]<0>========================================== [ 203.488428]CPU 3 FIQ: Watchdog time out preempt=1, softirq=0, hardirq=0 pc : ffffffc00012ed14, lr : ffffffc00012ecd8, pstate : 0000000060000145 sp : ffffffc0031b7c60 ...... [ 203.509234]Backtrace : [ 203.509520]<0>-(0)[143:kworker/u8:4]ffffffc00012ecd8, ffffffc00012ec24, [ 203.510355]<0>-(0)[143:kworker/u8:4]ffffffc0000ca238, ffffffc0000c1a00, [ 203.511190]<0>-(0)[143:kworker/u8:4]ffffffc00008447c, [ 203.511828]<0>-(0)[143:kworker/u8:4] |
我们重点看CPU Backtrace部分,这些都是函数地址,需要将地址转换为函数名和所在文件、行号。则需要用到aarch64-linux-android-addr2line(详情请查看quick start => Native Exception问题深入解析 => 进阶篇: coredump分析 => GNU tools)和vmlinux(必须是当时一起编译出来的,如果后面有更新过,addr2line得出的结果可能错误)。比如:
./prebuilts/gcc/linux-x86/aarch64/aarch64-linux-android-4.9/bin/aarch64-linux-android-addr2line -Cfe vmlinux 0xffffffc00014e68c => ring_buffer_unlock_commit()
全部转换后的结果如下:
| [ 203.410494]CPU 0 FIQ: Watchdog time out preempt=5, softirq=1, hardirq=1 pc : ffffffc00032dcac, lr : ffffffc00014e68c, pstate : 00000000200001c5 sp : ffffffc0384435c0 ...... [ 203.431300]Backtrace : [ 203.431586]<0>-(0)[143:kworker/u8:4]ring_buffer_unlock_commit, ring_buffer_unlock_commit, [ 203.432421]<0>-(0)[143:kworker/u8:4]__buffer_unlock_commit, trace_buffer_unlock_commit, [ 203.433256]<0>-(0)[143:kworker/u8:4]ftrace_raw_event_irq_exit, handle_IRQ, [ 203.434091]<0>-(0)[143:kworker/u8:4]04208060000001c0, do_softirq, [ 203.434926]<0>-(0)[143:kworker/u8:4]irq_exit, handle_IRQ, [ 203.435761]<0>-(0)[143:kworker/u8:4]ffffffc038443b10, ddp_dsi_switch_mode, [ 203.436597]<0>-(0)[143:kworker/u8:4]ddp_inout_info_tag, primary_display_capture_framebuffer, [ 203.437432]<0>-(0)[143:kworker/u8:4]find_buffer_by_mva, late_resume, [ 203.438266]<0>-(0)[143:kworker/u8:4] [ 203.438266]<0>========================================== [ 203.439400]CPU 1 FIQ: Watchdog time out preempt=1, softirq=0, hardirq=0 pc : ffffffc00012ed10, lr : ffffffc00012ecd8, pstate : 0000000060000145 sp : ffffffc003143c60 ...... [ 203.460206]Backtrace : [ 203.460493]<0>-(0)[143:kworker/u8:4]stop_machine_cpu_stop, cpu_stopper_thread, [ 203.461328]<0>-(0)[143:kworker/u8:4]smpboot_thread_fn, kthread, [ 203.462162]<0>-(0)[143:kworker/u8:4]ret_from_fork, [ 203.462800]<0>-(0)[143:kworker/u8:4] [ 203.462800]<0>========================================== [ 203.463913]CPU 2 FIQ: Watchdog time out preempt=1, softirq=0, hardirq=0 pc : ffffffc00012ed14, lr : ffffffc00012ecd8, pstate : 0000000060000145 sp : ffffffc00315fc60 ...... [ 203.484720]Backtrace : [ 203.485007]<0>-(0)[143:kworker/u8:4]stop_machine_cpu_stop, cpu_stopper_thread, [ 203.485841]<0>-(0)[143:kworker/u8:4]smpboot_thread_fn, kthread, [ 203.486676]<0>-(0)[143:kworker/u8:4]ret_from_fork, [ 203.487314]<0>-(0)[143:kworker/u8:4] [ 203.487314]<0>========================================== [ 203.488428]CPU 3 FIQ: Watchdog time out preempt=1, softirq=0, hardirq=0 pc : ffffffc00012ed14, lr : ffffffc00012ecd8, pstate : 0000000060000145 sp : ffffffc0031b7c60 ...... [ 203.509234]Backtrace : [ 203.509520]<0>-(0)[143:kworker/u8:4]stop_machine_cpu_stop, cpu_stopper_thread, [ 203.510355]<0>-(0)[143:kworker/u8:4]smpboot_thread_fn, kthread, [ 203.511190]<0>-(0)[143:kworker/u8:4]ret_from_fork, [ 203.511828]<0>-(0)[143:kworker/u8:4] |
CPU1~3都处于stop_machine_cpu_stop(),这是kernel stop machine机制,通常在CPU hotplug时会用到,比如CPU1要下电,会将其他CPU进入stop_machine_cpu_stop()停止运行,同时关闭中断,CPU1完成task迁移等动作再恢复。所以问题出在CPU0上。CPU0当时在handle_IRQ(),正在处理中断,PC所在的位置不像是被卡住的样子。可以排除死锁可能。
查看最近一次喂狗log:
| [ 144.630432]<1>.(1)[89:hps_main][wdk]bind kicker thread[152] to cpu[2] [ 144.631302]<1>.(1)[89:hps_main][WDK]cpu 2 plug on kick wdt [ 144.634946]<1>.(1)[89:hps_main][wdk]bind kicker thread[153] to cpu[3] [ 144.635830]<1>.(1)[89:hps_main][WDK]cpu 3 plug on kick wdt |
不是喂狗进程喂的,而是CPU hotplug喂的,再之前的log就找不到了(SYS_KERNEL_LOG大小有限),而且从175s往前推到159s,没有看到CPU1~3的log。估计很早就进入stop_machine_cpu_stop()。
175s往前推,CPU0倒是很活跃,那为何没有喂狗呢?结合当前的调用栈,怀疑是IRQ过多引起,我们查看下IRQ信息:
| CPU0 IRQ Status |
可以看到CPU0正在执行236中断,这个中断属于DISPSYS的,发生异常时,中断已执行了1001419us = 1s。看到IRQ Status最近1005764 us(1s)的时间内,236中断触发了228次。这个频率从该中断行为来看已经不正常了,如果中断执行时间长点,CPU0就无法做任何事,只能不停得处理中断了。这就是该题HWT的原因。
解决方法
问题出在Mediatek的DISP驱动里,需要Mediatek解决并释放patch的。
结语
需要对kernel基本模块有了解,比如stop machine机制。不一定是之前就了解,可以在解决这题的时候,详细查找stop machine机制资料并结合代码学习。
IRQ状态只有ENG版本才有,如果问题只出在user版本,需要在kernel-3.10/arch/arm64/configs/xxx_defconfig里设置CONFIG_MT_SCHED_MONITOR=y打开该功能才行。
12 HWT-大量DEVAPC violation
基本信息
问题:待机时出现多次 HWT(DEVAPC Access Violation Slave: AUXADC)
版本:alps-mp-m0.mp9
平台:MT6797
分析过程
用GAT解开db,并结合对应的vmlinux(该文件必须和db一致,具体请看FAQ06985),利用工具(E-Consulter.jar)分析(也可以参考FAQ13941),解析出来的调用栈如下:
| == 异常报告v1.4(仅供参考) == 详细描述: 看门狗复位, 其中CPU0没有喂狗, 请检查对应调用栈是否存在死锁或长时间关中断
|
看到调用栈被中断嵌套2次,明显大量中断引起无法正常调度,无法正常喂狗,引起HWT的,可以参考前面的章节《HWT-中断频繁触发》。
我们看下是否是这样,查看db里面的SYS_KERNEL_LOG:
| <6>[ 4400.547121]-(0)[1164:system_server][DEVAPC] VIO_STA 0:0x0, 1:0x0, 2:0x40000, 3:0x0, 4:0x0, 5:0x0, 6:0x22000000, 7:0x0 <6>[ 4400.547149]-(0)[1164:system_server][DEVAPC] Access Violation Slave: AUXADC (index=82) <6>[ 4400.547194]-(0)[1164:system_server][DEVAPC] Violation(R) - Process:system_server, PID:1164, Vio Addr:0x0, Bus ID:0x0, Dom ID:0x0, DBG0:0x0 <6>[ 4400.547203]-(0)[1164:system_server][DEVAPC] VIO_STA 0:0x0, 1:0x0, 2:0x40000, 3:0x0, 4:0x0, 5:0x0, 6:0x22000000, 7:0x0 <6>[ 4400.547231]-(0)[1164:system_server][DEVAPC] Access Violation Slave: AUXADC (index=82) <6>[ 4401.566664]-(0)[1164:system_server][WDK]CPU 0, 1, 2583396527128, 1, 0, 1 <6>[ 4401.566671]-(0)[1164:system_server][WDK]CPU 1, 0, 4370481160937, 2, 0, 1 <6>[ 4401.566677]-(0)[1164:system_server][WDK]CPU 2, 0, 4370482541475, 4, 0, 1 <6>[ 4401.566684]-(0)[1164:system_server][WDK]CPU 3, 0, 4370483952168, 8, 0, 1 <6>[ 4401.566690]-(0)[1164:system_server][WDK]CPU 4, 0, 4307421233174, 1023, 0, 1 <6>[ 4401.566697]-(0)[1164:system_server][WDK]CPU 5, 0, 4261167121957, 1023, 0, 1 <6>[ 4401.566704]-(0)[1164:system_server][WDK]CPU 6, 0, 4261168741957, 1023, 0, 1 <6>[ 4401.566710]-(0)[1164:system_server][WDK]CPU 7, 0, 4261170394650, 1023, 0, 1 <6>[ 4401.566717]-(0)[1164:system_server][WDK]CPU 8, 0, 4307469955097, 1023, 0, 1 <6>[ 4401.566723]-(0)[1164:system_server][WDK]CPU 9, 0, 4261177104804, 1023, 0, 1 <2>[ 4401.566850]-(0)[1164:system_server]BUG: failure at kernel-3.18/drivers/misc/mediatek/aee/common/wdt-atf.c:480/aee_wdt_atf_info()! |
log中存在大量的[DEVAPC] Access Violation,所以可以不看IRQ统计数据,是否真的很多。那么DEVAPC是什么呢?它的全称是:Device AccessPermissionControl,管理各个HW模块之前的访问权限。造成访问违例的原因有:
- 访问clock已关闭的HW模块(85%的概率)
- 没有对应读/写权限而去访问HW模块(15%的機率)
Device APC本身是无法判断哪种原因的,需要深入分析才行。比如这题是AUXADC触发的HWT,需要找MTK分析原因了。
解决方法
patch解决(不用当心这样的问题,已修复)。
结语
了解log是哪些模块输出的,以及为何输出这些log。然后了解模块的运作(知其然,知其所以然),这样处理问题就得心应手了。
13 HWT-SWT卡死
问题:使用中发生重启
版本:ALPS.L0.MP6.V3.20
平台:MT6752
分析过程
抓取db,解开后查看SYS_KERNEL_LOG,如下:
| [ 952.614376]-(0)[91:hang_detect]Unable to handle kernel paging request at virtual address 0000dead [ 952.614400]-(0)[91:hang_detect]pgd = ffffffc00007d000 [ 952.614415]-(0)[91:hang_detect][0000dead] *pgd=00000000b6803003, *pmd=00000000b6804003, *pte=00e0000043f01703 [ 952.614455]-(0)[91:hang_detect]Internal error: Oops: 96000045 [#1] PREEMPT SMP [ 952.614468]-(0)[91:hang_detect]disable aee kernel api [ 952.614544]-(0)[91:hang_detect]mrdump: cpu[0] tsk:ffffffc075e02000 ti:ffffffc07540c000 [ 952.614699]-(0)[91:hang_detect]mrdump: cpu[0] tsk:ffffffc075e02000 ti:ffffffc07540c000 [ 952.614749]-(0)[91:hang_detect]mrdump: cpu[1] tsk:ffffffc0768a0000 ti:ffffffc0768c0000 [ 952.614793]-(0)[91:hang_detect]mrdump: cpu[2] tsk:ffffffc0768a2000 ti:ffffffc0768c4000 [ 952.614836]-(0)[91:hang_detect]mrdump: cpu[3] tsk:ffffffc0768c8000 ti:ffffffc0768e8000 [ 952.614879]-(0)[91:hang_detect]mrdump: cpu[4] tsk:ffffffc0768cb000 ti:ffffffc0768ec000 [ 952.614922]-(0)[91:hang_detect]mrdump: cpu[5] tsk:ffffffc0768cd000 ti:ffffffc0768f0000 [ 952.614966]-(0)[91:hang_detect]mrdump: cpu[6] tsk:ffffffc0768cf000 ti:ffffffc0768f4000 [ 952.615009]-(0)[91:hang_detect]mrdump: cpu[7] tsk:ffffffc0768d2000 ti:ffffffc0768f8000 [ 952.623251]-(0)[91:hang_detect][hwPowerOn] acquire powerId:12 index:1 mod_name: msdc powerVolt:3000 [ 960.616646]-(0)[91:hang_detect]CPU: 0 PID: 91 Comm: hang_detect Not tainted 3.10.61+ #1 [ 960.616671]-(0)[91:hang_detect]task: ffffffc075e02000 ti: ffffffc07540c000 task.ti: ffffffc07540c000 [ 960.616693]-(0)[91:hang_detect]PC is at aee_wdt_atf_info+0x4b4/0x6ac [ 960.616713]-(0)[91:hang_detect]LR is at aee_wdt_atf_info+0x4ac/0x6ac [ 960.616735]-(0)[91:hang_detect]pc : [<ffffffc0003e7f50>] lr : [<ffffffc0003e7f48>] pstate: 800001c5 [ 960.616750]-(0)[91:hang_detect]sp : ffffffc07540fb90 [ 960.616764]-(0)[91:hang_detect]x29: ffffffc07540fb90 x28: ffffffc07540fdb0 |
就是BUG()对0xdead赋值触发kernel crash的。看到PC所在的位置就知道是HWT了。这个不是开机30s HWT,因此需要观察kick/check bit:
| [ 967.526053]-(0)[91:hang_detect]kick=0x00000000,check=0x00000003 |
共有2个CPU(CPU0~1)online,但都没有喂狗。因此需要一一查看CPU调用栈,然后用aarch64-linux-android-addr2line全部转换后的结果如下:
| [ 967.525575]-(0)[91:hang_detect]CPU 0 FIQ: Watchdog time out [ 967.525575]preempt=0, softirq=0, hardirq=0 [ 967.525575]pc : ffffffc0003ece04, hang_detect_thread() + 0x304 <kernel\drivers\misc\mediatek\aee\aed\monitor_hang.c:436> lr : ffffffc0003ece00, pstate : 00000000600001c5 [ 967.525575]sp : ffffffc07540fdb0 ...... [ 967.525710]-(0)[91:hang_detect]Backtrace : [ 967.525727]-(0)[91:hang_detect]ffffffc0003ece00, hang_detect_thread() + 0x300 [ 967.525739]-(0)[91:hang_detect]ffffffc0000be018, kthread() + 0xB0 [ 967.525753]-(0)[91:hang_detect]ffffffc00008442c, ret_from_fork() [ 967.525767]-(0)[91:hang_detect] [ 967.525767]========================================== [ 967.525799]-(0)[91:hang_detect]CPU 1 FIQ: Watchdog time out [ 967.525799]preempt=1, softirq=0, hardirq=0 [ 967.525799]pc : ffffffc0003c6444, go_to_rgidle() + 0x0C lr : ffffffc0003c6824, pstate : 00000000800001c5 [ 967.525799]sp : ffffffc0768c3f20 ...... [ 967.525952]-(0)[91:hang_detect]Backtrace : [ 967.525968]-(0)[91:hang_detect]ffffffc0003c6824, rgidle_handler() + 0x1C [ 967.525980]-(0)[91:hang_detect]ffffffc0003c68e4, arch_idle() + 0x64 [ 967.525994]-(0)[91:hang_detect]ffffffc0000853f8, arch_cpu_idle() + 0x14 [ 967.526006]-(0)[91:hang_detect]ffffffc000100588, cpu_startup_entry() + 0x188 [ 967.526019]-(0)[91:hang_detect]ffffffc000995018, secondary_start_kernel() + 0xFC [ 967.526033]-(0)[91:hang_detect] |
CPU1的PC在go_to_rgidle(),这个是CPU无task可运行而进入空闲的函数,表示CPU1处于空闲状态。目前看不出为什么没有喂狗,查看下最近一次喂狗log:
| [ 921.607458][WDK], local_bit:0x1, cpu:0, check bit0x:3,RT[921597479976] [ 921.607458][thread:157][RT:921597487976] 2010-01-01 03:53:38.937309 UTC; android time 2010-01-01 11:53:38.937309 [ 921.607469]-(0)[0:swapper/0][printk_delayed:done] [ 921.607515]-(1)[0:swapper/1][WDK], local_bit:0x1, cpu:1,RT[921597493745] [ 921.607515][WDK], local_bit:0x3, cpu:1, check bit0x:3,RT[921597500899] [ 921.607515][WDK]: kick Ex WDT,RT[921597506207] ...... [ 930.701735] (1)[141:bat_thread_kthr][mt_kpoc_power_off_check] , chr_vol=0, boot_mode=0 [ 952.614376]-(0)[91:hang_detect]Unable to handle kernel paging request at virtual address 0000dead |
在921s时喂的狗,超时时刻是952s,30s左右,所以HWT了,理论上921+20=941s会再次喂狗,但从log看到930s到952s没有任何log吐出,CPU肯定发生死循环了。CPU1看不出来,我们看CPU0,前面看到CPU0在kernel\drivers\misc\mediatek\aee\aed\monitor_hang.c的436行,对应代码如下:
404static int hang_detect_thread(void *arg) 405{ 406 407 /* unsigned long flags; */ 408 struct sched_param param = {.sched_priority = RTPM_PRIO_WDT }; 409 410 LOGE("[Hang_Detect] hang_detect thread starts.\n"); 411 412 sched_setscheduler(current, SCHED_FIFO, ¶m); 413 414 while (1) { 415 if ((1 == hd_detect_enabled) && (FindTaskByName("system_server") != -1)) { 416 LOGE("[Hang_Detect] hang_detect thread counts down %d:%d.\n", 417 hang_detect_counter, hd_timeout); 418 if (hang_detect_counter <= 0) { 419 ShowStatus(); 420 } 421 422 423 if (hang_detect_counter == 0) { 424 LOGE("[Hang_Detect] we should triger HWT ...\n"); 425 if (aee_mode != AEE_MODE_CUSTOMER_USER) { 426 aee_kernel_warning_api(__FILE__, __LINE__, 427 DB_OPT_NE_JBT_TRACES|DB_OPT_DISPLAY_HANG_DUMP, 428 "\nCRDISPATCH_KEY:SS Hang\n", "we triger HWT "); 429 msleep(30 * 1000); 430 } else { 431 /* aee_kernel_exception_api(__FILE__, __LINE__, 432 DB_OPT_NE_JBT_TRACES|DB_OPT_DISPLAY_HANG_DUMP, 433 "\nCRDISPATCH_KEY:SS Hang\n","we triger HWT "); */ 434 msleep(30 * 1000); 435 local_irq_disable(); 436 while (1); 437 BUG(); /* in order to get Hang info ASAP */ 438 } 439 } 440 441 ...... 454}
看到436行是一个while(1);的死循环,而且前面还关闭了中断,直接导致系统无法调度卡死。为什么这里有个死循环呢?
这是一个功能,hang_detect进程用于同步SWT的,在android层中,如果发生了SWT,android会发生重启,但如果在SWT过程中因为某些原因卡住,这直接导致手机变成砖头,用户体验很差。因此我们在SWT每走几步就和hang_detect进程交流,设定超时时间hang_detect_counter。如果SWT在某一步中卡住,底层的hang_detect就会超时,进而跑入上面的代码里,等待HWT。简单来讲:避免SWT卡死,我们将SWT卡死转化为HWT。
不过这个功能仅在USER版本有效。ENG版本还是卡死,但是系统还在运行,我们可以通过adb shell等接入android,可以查看系统的情况,比如是否是surfaceflinger卡死或EMMC卡死等。
所以呢,这个问题应该分析SWT卡住的原因,而不是去看HWT了。USER版本直接发生HWT,我们只有db可以看,信息有限,分析问题通常很困难。一般都需要切换为ENG版本复现,问题发生后保留现场,插上USB防止掉电。请Mediatek工程师直接在手机上分析(可以现场分析或远程遥控分析)。
解决方法
问题出在SWT,需切换ENG版本复现保留环境分析。
结语
这里需要了解hang detect功能才知道如何下手分析。
在L1版本之后拿掉了上面的死循环,改为直接调用了BUG(),也就是说,后面版本就将不到这类异常了。
14 HWT-死锁卡死
问题:开机后界面黑屏,按电源键无作用,之后重启
版本:ALPS.L0.MP8.V2
平台:MT6735
分析过程
抓取db,db名字就叫db.fatal.00.HWT.dbg,所以是个HWT,解开后查看SYS_KERNEL_LOG,如下:
| [ 87.030417]<0> (0)[7:migration/0]Unable to handle kernel paging request at virtual address 0000dead [ 87.030437]<0> (0)[7:migration/0]pgd = ffffffc00007d000 [ 87.030451]<0> (0)[7:migration/0][0000dead] *pgd=000000009f281003, *pmd=000000009f282003, *pte=00e0000043f01703 [ 87.030486]<0>-(0)[7:migration/0]Internal error: Oops: 96000046 [#1] PREEMPT SMP [ 87.030499]<0>-(0)[7:migration/0]disable aee kernel api [ 87.030591]<0>-(0)[7:migration/0]mrdump: cpu[0] tsk:ffffffc05f21a000 ti:ffffffc05f238000 [ 87.030830]<0>-(0)[7:migration/0]mrdump: cpu[0] tsk:ffffffc05f21a000 ti:ffffffc05f238000 [ 87.030884]<0>-(0)[7:migration/0]mrdump: cpu[1] tsk:ffffffc05f24e000 ti:ffffffc05f270000 [ 87.030940]<0>-(0)[7:migration/0]mrdump: cpu[2] tsk:ffffffc0582ea000 ti:ffffffc0583d0000 [ 87.030977]<0>-(0)[7:migration/0]mrdump: cpu[3] tsk:ffffffc00309c000 ti:ffffffc0030b8000 [ 95.558245]<0>-(0)[7:migration/0]CPU: 0 PID: 7 Comm: migration/0 Tainted: G W 3.10.65+ #1 [ 95.558273]<0>-(0)[7:migration/0]task: ffffffc05f21a000 ti: ffffffc05f238000 task.ti: ffffffc05f238000 [ 95.558301]<0>-(0)[7:migration/0]PC is at aee_wdt_atf_info+0x4bc/0x6b4 [ 95.558319]<0>-(0)[7:migration/0]LR is at aee_wdt_atf_info+0x4b4/0x6b4 [ 95.558338]<0>-(0)[7:migration/0]pc : [<ffffffc0003c0118>] lr : [<ffffffc0003c0110>] pstate: 80000145 [ 95.558353]<0>-(0)[7:migration/0]sp : ffffffc05f23ba90 |
观察kick/check bit:
| [ 102.988511]<0>-(0)[7:migration/0]kick=0x00000000,check=0x0000000f [ 102.988511]<0>Qwdt at [ 87.030393] |
共有4个CPU(CPU0~3)online,但都没有喂狗。因此需要一一查看CPU调用栈,然后用aarch64-linux-android-addr2line全部转换后的结果如下:
| [ 102.987315]<0>-(0)[7:migration/0]CPU 0 FIQ: Watchdog time out [ 102.987315]<0>preempt=1, softirq=0, hardirq=0 [ 102.987315]<0>pc : ffffffc000119380, stop_machine_cpu_stop() + 0x5C lr : ffffffc000119340, pstate : 0000000060000145 [ 102.987315]<0>sp : ffffffc05f23bcb0 ...... [ 102.987447]<0>-(0)[7:migration/0]Backtrace : [ 102.987462]<0>-(0)[7:migration/0]ffffffc000119340, stop_machine_cpu_stop() + 0x1C [ 102.987474]<0>-(0)[7:migration/0]ffffffc00011928c, cpu_stopper_thread() + 0xB8 [ 102.987485]<0>-(0)[7:migration/0]ffffffc0000c6540, smpboot_thread_fn() + 0x1FC [ 102.987497]<0>-(0)[7:migration/0]ffffffc0000be22c, kthread() + 0xB0 [ 102.987509]<0>-(0)[7:migration/0]ffffffc00008446c, ret_from_fork() [ 102.987523]<0>-(0)[7:migration/0] [ 102.987523]<0>========================================== [ 102.987553]<0>-(0)[7:migration/0]CPU 1 FIQ: Watchdog time out [ 102.987553]<0>preempt=3, softirq=1, hardirq=0 [ 102.987553]<0>pc : ffffffc00092ff54, __raw_spin_lock_irqsave() + 0x88 lr : ffffffc00092ff30, pstate : 00000000800001c5 [ 102.987553]<0>sp : ffffffc05f273840 [ 102.987704]<0>-(0)[7:migration/0]Backtrace : [ 102.987718]<0>-(0)[7:migration/0]ffffffc00092ff30, __raw_spin_lock_irqsave() + 0x64 [ 102.987731]<0>-(0)[7:migration/0]ffffffc00093035c, raw_spin_lock_irqsave() + 0x08 [ 102.987742]<0>-(0)[7:migration/0]ffffffc0003808f0, mt_disable_clock() + 0x88 [ 102.987754]<0>-(0)[7:migration/0]ffffffc00037ca58, disable_clock() + 0x08 [ 102.987766]<0>-(0)[7:migration/0]ffffffc0005c747c, msdc_clksrc_onoff() + 0x84 [ 102.987777]<0>-(0)[7:migration/0]ffffffc0005c75c4, msdc_timer_pm() + 0x4C [ 102.987789]<0>-(0)[7:migration/0]ffffffc0000aa2f8, call_timer_fn() + 0x58 [ 102.987801]<0>-(0)[7:migration/0]ffffffc0000aa5bc, run_timer_softirq() + 0x1C0 [ 102.987813]<0>-(0)[7:migration/0]ffffffc0000a204c, __do_softirq() + 0x128 [ 102.987825]<0>-(0)[7:migration/0]ffffffc0000a227c, do_softirq() + 0x5C [ 102.987837]<0>-(0)[7:migration/0]ffffffc0000a24f4, irq_exit() + 0x8C [ 102.987849]<0>-(0)[7:migration/0]ffffffc000084908, handle_IRQ() + 0xB8 [ 102.987860]<0>-(0)[7:migration/0]ffffffc000d0f088, cpu_stop_threads() [ 102.987872]<0>-(0)[7:migration/0]ffffffc00011928c, cpu_stopper_thread() + 0xB8 [ 102.987883]<0>-(0)[7:migration/0]ffffffc0000c6540, smpboot_thread_fn() + 0x1FC [ 102.987895]<0>-(0)[7:migration/0]ffffffc0000be22c, kthread() + 0xB0 [ 102.987906]<0>-(0)[7:migration/0] [ 102.987906]<0>========================================== [ 102.987937]<0>-(0)[7:migration/0]CPU 2 FIQ: Watchdog time out [ 102.987937]<0>preempt=2, softirq=0, hardirq=0 [ 102.987937]<0>pc : ffffffc00037bd98, spm_mtcmos_ctrl_disp() + 0x5C <kernel-3.10\drivers\misc\mediatek\mach\mt6735\mt_spm_mtcmos.c:1323> lr : ffffffc00037bd68, pstate : 00000000800001c5 [ 102.987937]<0>sp : ffffffc0583d3ad0 ...... [ 102.988067]<0>-(0)[7:migration/0]Backtrace : [ 102.988081]<0>-(0)[7:migration/0]ffffffc00037bd68, spm_mtcmos_ctrl_disp() + 0x2C [ 102.988093]<0>-(0)[7:migration/0]ffffffc00037e258, dis_sys_disable_op() + 0x14 [ 102.988105]<0>-(0)[7:migration/0]ffffffc00037e978, sys_disable_locked() + 0x74 [ 102.988117]<0>-(0)[7:migration/0]ffffffc00037ea74, clk_disable_locked() + 0x84 [ 102.988128]<0>-(0)[7:migration/0]ffffffc0003808fc, mt_disable_clock() + 0x94 [ 102.988140]<0>-(0)[7:migration/0]ffffffc00037ca58, disable_clock() + 0x08 [ 102.988151]<0>-(0)[7:migration/0]ffffffc00043ce98, ddp_path_top_clock_off() + 0x6C [ 102.988163]<0>-(0)[7:migration/0]ffffffc000446dc4, dpmgr_path_power_off() + 0xC0 [ 102.988174]<0>-(0)[7:migration/0]ffffffc00045ba08, primary_display_suspend() + 0x390 [ 102.988186]<0>-(0)[7:migration/0]ffffffc00044e03c, mtkfb_early_suspend() + 0x1C [ 102.988198]<0>-(0)[7:migration/0]ffffffc0000fd6bc, early_suspend() + 0x1C0 [ 102.988210]<0>-(0)[7:migration/0]ffffffc0000b7554, process_one_work() + 0x148 [ 102.988222]<0>-(0)[7:migration/0]ffffffc0000b79ac, worker_thread() + 0x138 [ 102.988233]<0>-(0)[7:migration/0]ffffffc0000be22c, kthread() + 0xB0 [ 102.988244]<0>-(0)[7:migration/0]ffffffc00008446c, ret_from_fork() [ 102.988257]<0>-(0)[7:migration/0] [ 102.988257]<0>========================================== [ 102.988288]<0>-(0)[7:migration/0]CPU 3 FIQ: Watchdog time out [ 102.988288]<0>preempt=1, softirq=0, hardirq=0 [ 102.988288]<0>pc : ffffffc00011937c, stop_machine_cpu_stop() + 0x58 lr : ffffffc000119340, pstate : 0000000060000145 [ 102.988288]<0>sp : ffffffc0030bbcb0 ...... [ 102.988418]<0>-(0)[7:migration/0]Backtrace : [ 102.988431]<0>-(0)[7:migration/0]ffffffc000119340, stop_machine_cpu_stop() + 0x1C [ 102.988442]<0>-(0)[7:migration/0]ffffffc00011928c, cpu_stopper_thread() + 0xB8 [ 102.988454]<0>-(0)[7:migration/0]ffffffc0000c6540, smpboot_thread_fn() + 0x1FC [ 102.988465]<0>-(0)[7:migration/0]ffffffc0000be22c, kthread() + 0xB0 [ 102.988477]<0>-(0)[7:migration/0]ffffffc00008446c, ret_from_fork() |
CPU0和CPU3都处于stop_machine_cpu_stop(),这是kernel stop machine机制,CPU0和CPU3都在等CPU1/CPU2完成工作才能退出stop machine,应该要查看CPU1/CPU2卡在哪里。
看到CPU1最早也是在stop machine里,不过因为来了中断,中断处理完后又进入softirq处理,里面执行了msdc_timer_pm(),要通过mt_disable_clock()去关闭clock,当时锁被拿走了,我们看下代码:
int mt_disable_clock(enum cg_clk_id id, char *name) { int err; unsigned long flags; struct cg_clk *clk = id_to_clk(id); ...... clkmgr_lock(flags); err = clk_disable_internal(clk, name); clkmgr_unlock(flags); return err; }
上面的clkmgr_lock(flags),用了全局spinlock:clock_lock。我们看下谁拿走这个锁的。刚好看到CPU2的调用栈也调用了mt_disable_clock(),而且还没退出,锁就是它拿了,所以CPU1是在等待CPU2的锁。我们应该看CPU2卡在哪里。
CPU2是在做suspend,关闭clock,不过关闭clock应该很快才对。我们看下PC所指的代码:
1312int spm_mtcmos_ctrl_disp(int state) 1313{ 1314 ...... 1321 if (state == STA_POWER_DOWN) { 1322 spm_write(TOPAXI_PROT_EN, spm_read(TOPAXI_PROT_EN) | DISP_PROT_MASK); 1323 while ((spm_read(TOPAXI_PROT_STA1) & DISP_PROT_MASK) != DISP_PROT_MASK) { /* 卡在这里了!!! */ 1324 }
看到1323行是个while循环,就是这个循环导致CPU2一直卡住,CPU1也因此卡住,CPU0/CPU3也因此卡住。
解决方法
卡在硬件寄存器状态一直不对,出在Mediatek的DISP power驱动里,需要Mediatek解决的。
结语
HWT一个常见的卡死是死锁,正常情况下拿到锁后尽量尽快执行完所需任务后就释放掉锁,以免持有过久带来一系列问题。
这题是碰巧CPU2的调用栈明显看出是它拿了锁。如果调用栈无法反应谁持有锁该怎么办?还好ENG版本的spinlock有死锁检测机制,持有锁被记录owner和函数,如果获取锁失败,并且在1s内一直无法获取锁,系统会直接印出该锁被谁持有。有助于我们进一步调试。
15 HWT- 关机死锁卡死
基本信息
问题:定时开关机测试,发生HWT
版本:ALPS.M1.MP3
平台:MT6757
分析过程
用GAT解开db,并结合对应的vmlinux(该文件必须和db一致,具体请看FAQ06985),利用工具E-Consulter分析(也可以参考FAQ13941),分析报告如下:
== 异常报告v1.5(仅供参考) ==
报告解读: MediaTek On-Line> Quick Start> E-Consulter之NE/KE分析报告解读> KE分析报告
详细描述: 断言失败{主动调用BUG()/BUG_ON()},请结合崩溃进程调用栈检查相关代码
平台 : MT6757
版本 : alps-mp-m1.mp3/eng build
异常时间: 0.000000秒, Tue Sep 20 08:16:57 CST 2016
== CPU信息 ==
崩溃CPU信息:
CPU0: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux __spin_lock_debug() + 496 <kernel/locking/spinlock_debug.c:218>
vmlinux do_raw_spin_lock(lock=pmic_access_spin) + 736 <kernel/locking/spinlock_debug.c:254>
vmlinux __raw_spin_lock() + 48 <include/linux/spinlock_api_smp.h:143>
vmlinux _raw_spin_lock(lock=pmic_access_spin) + 64 <kernel/locking/spinlock.c:151>
vmlinux spin_lock() + 44 <include/linux/spinlock.h:311>
vmlinux pmic_config_interface_nolock(RegNum=516, val=1, SHIFT=4) + 68 <drivers/misc/mediatek/power/mt6757/pmic.c:839>
vmlinux rtc_enable_k_eosc() + 60 <drivers/misc/mediatek/rtc/mt6351/mtk_rtc_hal.c:191>
vmlinux hal_rtc_bbpu_pwdn(charger_status=false) + 32 <drivers/misc/mediatek/rtc/mt6351/mtk_rtc_hal.c:244>
vmlinux rtc_bbpu_power_down() + 88 <drivers/misc/mediatek/rtc/mtk_rtc_common.c:400>
vmlinux mt_power_off() + 76 <drivers/misc/mediatek/rtc/mtk_rtc_common.c:414>
vmlinux machine_power_off() + 64 <arch/arm64/kernel/process.c:135>
vmlinux kernel_power_off() + 96 <kernel/reboot.c:266>
vmlinux SYSC_reboot() + 384 <kernel/reboot.c:334>
vmlinux SyS_reboot(magic1=4276215469, magic2=672274793, cmd=1126301404, arg=0) + 392 <kernel/reboot.c:280>
...... ......
vmlinux ____fput() + 8 <fs/file_table.c:271>
vmlinux task_work_run() + 212 <kernel/task_work.c:125>
vmlinux tracehook_notify_resume() + 24 <include/linux/tracehook.h:190>
vmlinux do_notify_resume(thread_flags=4) + 84 <arch/arm64/kernel/signal.c:417>
== 栈结束 ==
对应汇编指令:
行号 地址 指令 提示
kernel/locking/spinlock_debug.c
218 : FFFFFFC0001126B8: MOV X0, #-0x8000000001
FFFFFFC0001126C0: MOVK X0, X0, #0xDEAD
FFFFFFC0001126C4: STR W1, [X0] ; 进程停止在这里
当时的寄存器值:
X0: FFFFFF7FFFFFDEAD, X1: 0000000000000AEE, X2: CB88537FDC8CB01F, X3: 0000000000000003
X4: 0000000000000000, X5: FFFFFFC0B49D8000, X6: FFFFFFC000106B3C, X7: 0000000000000001
X8: FFFFFFC001CA7EA4, X9: 676E696B636F6C2F, X10: 636F6C6E6970732F, X11: 2E67756265645F6B
X12: 5F5F2F3831323A63, X13: 636F6C5F6E697073, X14: 2867756265645F6B, X15: 0000000000000020
X16: 0000000000000020, X17: 0000000000000000, X18: 0000000000000047, X19: FFFFFFC000F41448
X20: 0000000000C65D40, X21: FFFFFFC001C6BB34, X22: 0000000000000005, X23: FFFFFFC000F41638
X24: 00000021E56225BE, X25: 0000001EE37912F6, X26: FFFFFFC0012AD000, X27: FFFFFFC0AA8B2000
X28: FFFFFFC001320BA8, X29: FFFFFFC0B49DFB40, X30: FFFFFFC0001126B8, SP: FFFFFFC0B49DFB40
PC: FFFFFFC0001126C4
其他CPU信息:
CPU4: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux ipi_cpu_stop() + 44 <arch/arm64/kernel/smp.c:677>
vmlinux handle_IPI(ipinr=0) + 544 <arch/arm64/kernel/smp.c:727>
...... ......
vmlinux mt_i2c_transfer(adap=0xFFFFFFC0AF819018, msgs=0xFFFFFFC0AA8B7818) + 68 <drivers/i2c/busses/i2c-mtk.c:970>
vmlinux __i2c_transfer(adap=0xFFFFFFC0AF819018, msgs=0xFFFFFFC0AA8B7818) + 488 <drivers/i2c/i2c-core.c:2091>
vmlinux i2c_transfer(adap=0xFFFFFFC0AF819018) + 96 <drivers/i2c/i2c-core.c:2162>
...... ......
vmlinux i2c_smbus_xfer(read_write=1, protocol=2, data=0xFFFFFFC0AA8B7920) + 428 <drivers/i2c/i2c-core.c:2961>
vmlinux i2c_smbus_read_byte_data(command=11) + 56 <drivers/i2c/i2c-core.c:2569>
vmlinux bq2589x_read_byte(data=0xFFFFFFC0AA8B79C0, reg=11) + 64 <drivers/misc/mediatek/power/mt6757/bq2589x_charger.c:64>
vmlinux bq2589x_get_vbus_status() + 36 <drivers/misc/mediatek/power/mt6757/bq2589x_charger.c:792>
vmlinux upmu_is_chr_det() + 36 <drivers/power/mediatek/mtk_common.c:58>
vmlinux bat_is_charger_exist() + 36 <drivers/power/mediatek/mtk_common.c:75>
...... ......
vmlinux skb_recv_datagram() + 56 <net/core/datagram.c:272>
...... ......
== 栈结束 ==
CPU5: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux ipi_cpu_stop() + 44 <arch/arm64/kernel/smp.c:677>
vmlinux handle_IPI(ipinr=0) + 544 <arch/arm64/kernel/smp.c:727>
vmlinux __switch_to(prev=0xFFFFFFC0B4AE8000, next=0) + 96 <arch/arm64/kernel/process.c:395>
vmlinux context_switch() + 788 <kernel/sched/core.c:2485>
vmlinux __schedule() + 1164 <kernel/sched/core.c:3044>
vmlinux schedule() + 36 <kernel/sched/core.c:3083>
vmlinux schedule_preempt_disabled() + 16 <kernel/sched/core.c:3114>
vmlinux cpu_idle_loop() + 264 <kernel/sched/idle.c:242>
vmlinux cpu_startup_entry(state=CPUHP_ONLINE) + 296 <kernel/sched/idle.c:264>
vmlinux secondary_start_kernel() + 540 <arch/arm64/kernel/smp.c:270>
...... 0x00000000400817E0()
== 栈结束 ==
CPU6: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux ipi_cpu_stop() + 44 <arch/arm64/kernel/smp.c:677>
vmlinux handle_IPI(ipinr=0) + 544 <arch/arm64/kernel/smp.c:727>
...... ......
vmlinux enqueue_task() + 68 <kernel/sched/core.c:919>
...... ......
vmlinux __wake_up(mode=3, nr_exclusive=-1424458584, key=0) + 56 <kernel/sched/wait.c:94>
vmlinux wake_up_bat() + 60 <drivers/power/mediatek/charger-manager.c:211>
...... ......
vmlinux notifier_call_chain(nl=fb_notifier_list + 128, val=9, v=0xFFFFFFC0AB187CA8, nr_to_call=-1, nr_calls=0) + 132 <kernel/notifier.c:127>
vmlinux __blocking_notifier_call_chain(nh=fb_notifier_list, nr_to_call=-1, nr_calls=0) + 64 <kernel/notifier.c:373>
vmlinux blocking_notifier_call_chain() + 16 <kernel/notifier.c:384>
vmlinux fb_notifier_call_chain(val=9, v=0xFFFFFFC0AB187CA8) + 24 <drivers/video/fbdev/core/fb_notify.c:45>
vmlinux fb_blank(info=0xFFFFFFC0B1F71000, blank=4) + 176 <drivers/video/fbdev/core/fbmem.c:1073>
vmlinux do_fb_ioctl(info=0xFFFFFFC0B1F71000, arg=4) + 748 <drivers/video/fbdev/core/fbmem.c:1209>
vmlinux fb_ioctl(file=0xFFFFFFC02D05C000, arg=4) + 48 <drivers/video/fbdev/core/fbmem.c:1233>
vmlinux vfs_ioctl() + 12 <fs/ioctl.c:43>
vmlinux do_vfs_ioctl(filp=0xFFFFFFC02D05C000, fd=37, cmd=17937, arg=4) + 1060 <fs/ioctl.c:598>
vmlinux SYSC_ioctl() + 96 <fs/ioctl.c:613>
vmlinux SyS_ioctl(fd=37, cmd=17937, arg=4) + 128 <fs/ioctl.c:604>
== 栈结束 ==
CPU7: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux ipi_cpu_stop() + 44 <arch/arm64/kernel/smp.c:677>
vmlinux handle_IPI(ipinr=0) + 544 <arch/arm64/kernel/smp.c:727>
...... ......
vmlinux __local_bh_enable() + 68 <kernel/softirq.c:136>
...... ......
vmlinux trace_hardirqs_off() + 12 <kernel/locking/lockdep.c:2713>
vmlinux rcu_irq_exit() + 256 <kernel/rcu/tree.c:645>
vmlinux irq_exit() + 88 <kernel/softirq.c:403>
...... ......
vmlinux __this_cpu_preempt_check() + 20 <lib/smp_processor_id.c:68>
vmlinux __trace_hardirqs_on_caller() + 68 <kernel/locking/lockdep.c:2626>
vmlinux trace_hardirqs_on_caller() + 196 <kernel/locking/lockdep.c:2668>
vmlinux trace_hardirqs_on() + 12 <kernel/locking/lockdep.c:2675>
== 栈结束 ==
由于eng版本有打开spin lock debug,所以直接call bug,否则就是HWT了。
从调用栈上看,是卡住power off流程里面,卡在某把锁里,这把spinlock被谁拿走,目前不明显,kernel log没有印出拿锁的进程调用栈,无从分析。
这里需要检查下power off的代码逻辑了。我们一路检查,有一个地方发现:
void machine_power_off(void)
{
local_irq_disable();
smp_send_stop();
pr_emerg("machine_power_off, pm_power_off(%p)\n", pm_power_off);
dump_stack();
if (pm_power_off)
pm_power_off();
}
在调用pm_power_off之前,调用了smp_send_stop函数,这个函数有什么作用?
通过检查代码发现,这个函数会对所有online cpu发送ipi中断:IPI_CPU_STOP,收到中断后,所有online cpu都会执行对应的ipi_cpu_stop函数。这个函数的作用是:
static void ipi_cpu_stop(unsigned int cpu)
{
if (system_state == SYSTEM_BOOTING || system_state == SYSTEM_RUNNING) {
raw_spin_lock(&stop_lock);
printk(KERN_CRIT "CPU%u: stopping\n", cpu);
dump_stack();
raw_spin_unlock(&stop_lock);
}
set_cpu_online(cpu, false);
local_fiq_disable();
local_irq_disable();
while (1)
cpu_relax();
}
将CPU停下来,并且关闭了irq和fiq,没人再打断这个cpu了,除了security irq(会切换到tee)。
这个是否是引起这题的关键呢?是的,因为可能存在这样的场景:
- cpu0拿到pmic的spinlock锁后用于读取寄存器值
- 这时cpu1发出关机命令,调用了machine_power_off函数,发送ipi给所有online cpu
- cpu0还没来得及释放spinlock锁前被迫进入ipi stop状态。
- cpu1接着执行,到了rtc_enable_k_eosc函数后要去拿pmic的spinlock锁,但一直没拿到
- 最后HWT
也就是说,谁调用了smp_send_stop函数,那么之后不应该拿任何锁,否则可能造成死锁。
除了关机流程会调用到smp_send_stop函数,重启流程也会,machine_restart函数会调用到smp_send_stop函数,因此关机和重启后面的流程不能拿任何一把锁。
解决方法
pmic提供nolock的函数版本。patch id:ALPS02874369
结语
开关机和重启压力测试一直都是常规测试项,在添加代码到关机、重启流程时,要特别注意不要使用任何lock。
16 HWT-死循环卡死
基本信息
问题:测试中发生一次HWT
版本:alps-mp-m0.mp7-V1
平台:MT6755
分析过程
抓取db,db名字就叫db.fatal.00.HWT.dbg,所以是个HWT,用E-Consulter分析,加入vmlinux后,得出分析报告如下:
== 异常报告v1.4(仅供参考) ==
详细描述: 看门狗复位, 其中CPU0,1,2没有喂狗, 请检查对应调用栈是否存在死锁或长时间关中断
参考信息: MediaTek On-Line> Quick Start> 深入分析看门狗框架
异常时间: 3380.654356秒, Sun Mar 20 09:00:57 CST 2016
== CPU信息 ==
无喂狗CPU信息:
CPU0: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux __iter_div_u64_rem() + 56 <include/linux/math64.h:122>
vmlinux timespec_add_ns(ns=-6022794434679698269) + 56 <include/linux/time.h:224>
vmlinux __getnstimeofday64(ts=0x000000003B9AC9FF) + 164 <kernel/time/timekeeping.c:508>
vmlinux getnstimeofday64(ts=init_thread_union + 16000) + 8 <kernel/time/timekeeping.c:528>
vmlinux do_gettimeofday(tv=init_thread_union + 16032) + 20 <kernel/time/timekeeping.c:699>
vmlinux idle_get_current_time_ms() + 12 <drivers/misc/mediatek/base/power/spm_v2/mt_idle.c:474>
vmlinux idle_ratio_calc_stop() <drivers/misc/mediatek/base/power/spm_v2/mt_idle.c:2014>
vmlinux rgidle_enter(cpu=0) + 72 <drivers/misc/mediatek/base/power/spm_v2/mt_idle.c:2213>
vmlinux mt_rgidle_enter(dev=0xFFFFFFC0FFF05BD8, drv=mt67xx_v2_cpuidle_driver, index=5) + 12 <drivers/cpuidle/cpuidle-mt67xx_v2.c:84>
vmlinux cpuidle_enter_state(dev=0xFFFFFFC0FFF05BD8, index=5) + 128 <drivers/cpuidle/cpuidle.c:135>
vmlinux cpuidle_enter(dev=0xFFFFFFC0FFF05BD8, index=5) + 20 <drivers/cpuidle/cpuidle.c:207>
vmlinux cpuidle_idle_call() + 552 <kernel/sched/idle.c:145>
vmlinux cpu_idle_loop() + 568 <kernel/sched/idle.c:215>
vmlinux cpu_startup_entry(state=CPUHP_ONLINE) + 600 <kernel/sched/idle.c:263>
vmlinux secondary_start_kernel() + 528 <arch/arm64/kernel/smp.c:250>
== 栈结束 ==
CPU1: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux multi_cpu_stop(data=0xFFFFFFC074467A08) + 88 <kernel/stop_machine.c:192>
vmlinux cpu_stopper_thread(cpu=1) + 180 <kernel/stop_machine.c:458>
vmlinux smpboot_thread_fn(data=0xFFFFFFC0FB91DA40) + 508 <kernel/smpboot.c:160>
vmlinux kthread(_create=0xFFFFFFC0FB91DA80) + 212 <kernel/kthread.c:207>
== 栈结束 ==
CPU2: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux multi_cpu_stop(data=0xFFFFFFC074467A08) + 88 <kernel/stop_machine.c:192>
vmlinux cpu_stopper_thread(cpu=2) + 180 <kernel/stop_machine.c:458>
vmlinux smpboot_thread_fn(data=0xFFFFFFC0FB91DE40) + 508 <kernel/smpboot.c:160>
vmlinux kthread(_create=0xFFFFFFC0FB91DE80) + 212 <kernel/kthread.c:207>
== 栈结束 ==
CPU0~2都没有喂狗,CPU1、CPU2都停在muti_cpu_stop,这个是stop machine机制,需要所有在线CPU同步进入multi_cpu_stop,所以真正卡住的是CPU0。
CPU0从调用栈来看,处于idle状态了,为什么没有进入multi_cpu_stop?查看CPU0的调度信息:
[ 3380.668761] -(1)[11:migration/1][name:debug&]cpu#0: Offline
[ 3380.668770] -(1)[11:migration/1][name:debug&] .nr_running : 71
看到CPU0等待调度的进程已经有71个,更明显看出CPU0卡住了。问题肯定出在CPU0调用栈上,看到
CPU0: 进程名: (null), 进程标识符(pid): 0, 中断: 关
看到中断是关闭的,所以无法调度,也就说明为何有71个进程等待调度但又没有调度起来了。
我们仔细分析调用栈,先看__iter_div_u64_rem()函数:
118__iter_div_u64_rem(u64 dividend, u32 divisor, u64 *remainder)
119{
120 u32 ret = 0;
121
122 while (dividend >= divisor) {
123 /* The following asm() prevents the compiler from
124 optimising this loop into a modulo operation. */
125 asm("" : "+rm"(dividend));
126
127 dividend -= divisor;
128 ret++;
129 }
130
131 *remainder = dividend;
132
133 return ret;
134}
用debug.cmm加载到trace32,可以看到当时的dividend = 0xAC6ABC5F2DB78CA3,ret = 0x66FC8BC6。也就是说,这个loop已经跑了0x66FC8BC6次了,表示CPU卡在这里很久了。为何会这样?是__getnstimeofday64()传的值nsecs为负值:
493int __getnstimeofday64(struct timespec64 *ts)
494{
495 struct timekeeper *tk = &tk_core.timekeeper;
496 unsigned long seq;
497 s64 nsecs = 0;
498
499 do {
500 seq = read_seqcount_begin(&tk_core.seq);
501
502 ts->tv_sec = tk->xtime_sec;
503 nsecs = timekeeping_get_ns(&tk->tkr);
505 } while (read_seqcount_retry(&tk_core.seq, seq));
506
507 ts->tv_nsec = 0;
508 timespec64_add_ns(ts, nsecs);
nsecs从timekeeping_get_ns来的:
194static inline s64 timekeeping_get_ns(struct tk_read_base *tkr)
195{
196 cycle_t cycle_now, delta;
197 s64 nsec;
198
199 /* read clocksource: */
200 cycle_now = tkr->read(tkr->clock);
201
202 /* calculate the delta since the last update_wall_time: */
203 delta = clocksource_delta(cycle_now, tkr->cycle_last, tkr->mask);
204
205 nsec = delta * tkr->mult + tkr->xtime_nsec;
206 nsec >>= tkr->shift;
207
208 /* If arch requires, add in get_arch_timeoffset() */
209 return nsec + arch_gettimeoffset();
210}
这里nsec是s64类型的。查看当时tkr(trace32查看变量):
tk_core = (
seq = (sequence = 0x0009A6D0),
timekeeper = (
tkr = (
clock = 0xFFFFFFC000FFE080,
read = 0xFFFFFFC0007FA810,
mask = 0x00FFFFFFFFFFFFFF,
cycle_last = 0x0000000A286F2CF1,
mult = 0x4CEC4EC5,
shift = 0x18,
xtime_nsec = 0x002D1EE8033F8540,
base_mono = (tv64 = 0x0000030BC3A56B03)),
xtime_sec = 0x56EDF615,
wall_to_monotonic = (tv_sec = 0xFFFFFFFFA9121700, tv_nsec = 0x03B0D903),
offs_real = (tv64 = 0x143D6468E02926FD),
offs_boot = (tv64 = 0x0),
offs_tai = (tv64 = 0x143D6468E02926FD),
tai_offset = 0x0,
base_raw = (tv64 = 0x0000030BF0C4523F),
raw_time = (tv_sec = 0x0D15, tv_nsec = 0x30CFC03F),
cycle_interval = 0x0001FBD0,
xtime_interval = 0x0000989680002710,
xtime_remainder = 0xFFFFFFFFFFFFD8F0,
raw_interval = 0x00989680,
ntp_tick = 0x0098968000000000,
ntp_error = 0x0,
ntp_error_shift = 0x8,
很有可能算出负值,引起卡死呢。后面发现kernel已经修复了这个问题:
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/kernel/time/timekeeping.c?id=35a4933a895927990772ae96fdcfd2f806929ee2
解决方法
上kernel patch ALPS02619771。
结语
结合调度信息,调用栈,其他CPU调用栈,一一抽丝剥茧深入分析,最终得出答案。另外原生kernel也可能有问题,不要放弃任何怀疑。
熟悉使用trace32(可以查看trace32使用教程)、gdb查看全局变量,局部变量等信息,是分析问题的关键。
熟悉使用E-Consulter,将快速给出初步分析结果,提高效率。
17 HWT-CPU卡死
基本信息
问题:SMP引起HWT
版本:ALPS.L1.MP10
平台:MT6755
分析过程
抓取db,db名字叫db.fatal.00.KE.dbg,用GAT的logviewer解开db后,查看__exp_main.txt:
| Exception Type: WDT timeout and Hardware reboot PC is at [<ffffffc000409590>] aee_wdt_atf_info+0x6e4/0x918 |
因此这题其实是HWT,而不是KE,只不过HWT流程没有走完又引起卡住,变成HW reboot。
我们结合对应的vmlinux(该文件必须和db一致,具体请看FAQ06985),利用工具(E-Consulter.jar)分析(也可以参考FAQ13941),解析出来的调用栈如下:
| == 异常报告v1.4(仅供参考) ==
|
看到CPU4/5/6都没有喂狗,但只有CPU4有调用栈,而CPU5/6没有调用栈。那么我们先分析CPU4。
CPU4最后卡住的位置是smp_call_function_single(),这个函数的目的是通知其他CPU做完事后再返回,如果其他CPU没有做完就一直等待。那CPU4是通知哪颗CPU呢?看参数是cpu=6,也就是说,如果CPU6没有做完事,那么CPU4就一直等待。所以要看CPU6在干什么了。
可惜的是CPU6没有调用栈,无法知道在干什么。其实还有一处信息可以知道CPU6在干什么,那就是last pc,这个信息记录在SYS_REBOOT_REASON文件里,内容如下:
| WDT status: 5 fiq step: 32 exception type: 1 [LAST PC] CORE_0 PC = 0x0( + 0x0), FP = 0x0, SP = 0x0 [LAST PC] CORE_1 PC = 0x0( + 0x0), FP = 0x0, SP = 0x0 [LAST PC] CORE_2 PC = 0x0( + 0x0), FP = 0x0, SP = 0x0 [LAST PC] CORE_3 PC = 0x0( + 0x0), FP = 0x0, SP = 0x0 [LAST PC] CORE_4 PC = 0xffffffc000a85fe4(simp_mmc_enable_clk.isra.6 + 0x5c), FP = 0xffffffc0b8853030, SP = 0xffffffc0b8853030 [LAST PC] CORE_5 PC = 0xffffffc0000960cc(__cpu_flush_user_tlb_range + 0x2c), FP = 0xffffffc07441fd00, SP = 0xffffffc07441fd00 [LAST PC] CORE_6 PC = 0xffffffc00054702c(wmt_plat_read_cpupcr + 0x8), FP = 0xffffffc0ab823b50, SP = 0xffffffc0ab823b50 [LAST PC] CORE_7 PC = 0x0( + 0x8), FP = 0x0, SP = 0x0 |
明显CPU6卡在wmt_plat_read_cpupcr()里面,而这个函数仅仅是读寄存器而已,所以问题是bus hang引起了这次的HWT。
解决方法
卡在读取硬件寄存器,出在Mediatek的WIFI驱动里,需要Mediatek解决的。
结语
这题和《HWT-死锁卡死》不一样的地方是看不到出问题的CPU的调用栈,只能通过last pc知道当时的情况。
18 HWT-rt throttle引起卡死
基本信息
问题:长按HOME建弹出快捷方式,按返回键反应迟钝,多操作几次手机会异常重启
版本:ALPS.L0.MP8.V2.1
平台:MT6735
分析过程
抓取db,db名字就叫db.fatal.00.HWT.dbg,所以是个HWT,用GAT里的log viewer解开后查看SYS_KERNEL_LOG,如下:
| [ 443.480435]<0> (0)[721:kworker/0:2][MALI] mtk_kbase_set_bottom_gpu_freq_fp() ui32FreqLevel=0, g_custom_gpu_boost_id=1 (GED boost)<<-GTP-DEBUG->> [3197][Esd]0x8040 = 0xFF, 0x8041 = 0xAA [ 444.832716]<0>-(0)[0:swapper/0]Unable to handle kernel paging request at virtual address 0000dead [ 444.832732]<0>-(0)[0:swapper/0]pgd = ffffffc00007d000 [ 444.832740]<0>-(0)[0:swapper/0][0000dead] *pgd=000000007f203003, *pmd=000000007f204003, *pte=00e0000043f01703 [ 444.832758]<0>-(0)[0:swapper/0]Internal error: Oops: 96000046 [#1] PREEMPT SMP [ 444.832766]<0>-(0)[0:swapper/0]disable aee kernel api [ 444.832824]<0>-(0)[0:swapper/0]mrdump: cpu[0] tsk:ffffffc000d30080 ti:ffffffc000d1c000 [ 444.832936]<0>-(0)[0:swapper/0]mrdump: cpu[0] tsk:ffffffc000d30080 ti:ffffffc000d1c000 [ 444.832966]<0>-(0)[0:swapper/0]mrdump: cpu[1] tsk:ffffffc03d871000 ti:ffffffc003050000 [ 444.832995]<0>-(0)[0:swapper/0]mrdump: cpu[2] tsk:ffffffc03d873000 ti:ffffffc003074000 [ 444.833022]<0>-(0)[0:swapper/0]mrdump: cpu[3] tsk:ffffffc003055000 ti:ffffffc003078000 [ 459.062270]<0>-(0)[0:swapper/0]CPU: 0 PID: 0 Comm: swapper/0 Not tainted 3.10.65+ #1 [ 459.062288]<0>-(0)[0:swapper/0]task: ffffffc000d30080 ti: ffffffc000d1c000 task.ti: ffffffc000d1c000 [ 459.062305]<0>-(0)[0:swapper/0]PC is at aee_wdt_atf_info+0x4bc/0x6b4 [ 459.062315]<0>-(0)[0:swapper/0]LR is at aee_wdt_atf_info+0x4b4/0x6b4 |
观察kick/check bit:
| [ 468.948772]<0>-(0)[0:swapper/0]kick=0x00000001,check=0x00000003 [ 468.948772]<0>Qwdt at [ 444.832698] |
共有2个CPU(CPU0~1)online,但CPU1没有喂狗。因此需要查看CPU1调用栈,查看log发现没有CPU1的调用栈,只有CPU0的:
| [ 102.987315]<0>-[ 468.948655]<0>-(0)[0:swapper/0]CPU 0 FIQ: Watchdog time out [ 468.948655]<0>preempt=1, softirq=0, hardirq=0 [ 468.948655]<0>pc : ffffffc000398ddc, lr : ffffffc000399158, pstate : 00000000800001c5 [ 468.948655]<0>sp : ffffffc000d1fed0 [ 468.948655]<0>x29: ffffffc000d1fed0 x28: 0000000040080200 [ 468.948655]<0>x27: ffffffc000080418 x26: 0000000000000001 [ 468.948655]<0>x25: ffffffc000b61e80 x24: ffffffc000e22ee1 [ 468.948655]<0>x23: ffffffc000960000 x22: ffffffc000eb4604 [ 468.948655]<0>x21: 0000000000000000 x20: ffffffc0009c0000 [ 468.948655]<0>x19: 0000000000000020 x18: 0000000000000000 [ 468.948655]<0>x17: 0000007f80a9f534 x16: ffffffc0001ded40 [ 468.948655]<0>x15: 0000000000000000 x14: 00000000f73f1d [ 468.948669]<0>-(0)[0:swapper/0]95 [ 468.948669]<0>x13: 00000000e2bc7cc0 x12: 00000000ab51cf50 [ 468.948669]<0>x11: 00000000e2bc7dd0 x10: 00000000f73c4cb9 [ 468.948669]<0>x9 : ffffffc000d1fd20 x8 : 0000000000000019 [ 468.948669]<0>x7 : 0000000003c00fe5 x6 : 00598111dffd2dc2 [ 468.948669]<0>x5 : 000000000001454e x4 : 00000000561f3684 [ 468.948669]<0>x3 : 000000000009a605 x2 : 0000000000000001 [ 468.948669]<0>x1 : 0000000000000000 x0 : 0000000000000000 [ 468.948669]<0> [ 468.948669]<0>stack (0xffffffc000d1fed0 to 0xffffffc000d1ffd0) [ 468.948669]<0>fec0: 00d1fee0 ffffffc0 0039919c ffffffc0 [ 468.948669]<0>fee0: 00d1ff10 ffffffc0 000854fc ffffffc0 00d1c000 ffffffc0 00d1[ 468.948706]<0>-(0)[0:swapper/0]c000 ffffffc0 [ 468.948706]<0>ff00: 00e23000 ffffffc0 00eb4604 ffffffc0 00d1ff20 ffffffc0 000ff81c ffffffc0 [ 468.948706]<0>ff20: 00d1ff80 ffffffc0 00945730 ffffffc0 00edb000 ffffffc0 00000000 00000000 [ 468.948706]<0>ff40: 00e2c000 ffffffc0 00d08cb8 ffffffc0 3f32db80 ffffffc0 40000000 00000000 [ 468.948706]<0>ff60: 4007b000 00000000 4007d000 00000000 00080418 ffffffc0 00945728 ffffffc0 [ 468.948706]<0>ff80: 00d1ffa0 ffffffc0 00cbf768 ffffffc0 3f32db80 ffffffc0 00000002 00000000 [ 468.948706]<0>ffa0: 00000000 00000000 40080200 00000000 00000000 00000000 00000000 00000000 [ 468.948706]<0>ffc0: 4e000000 00000000 410fd [ 468.948712]<0>-(0)[0:swapper/0]033 00000000 [ 468.948712]<0>virt_addr_valid fail [ 468.948720]<0>-(0)[0:swapper/0]Backtrace : [ 468.948727]<0>-(0)[0:swapper/0]ffffffc000399158, [ 468.948733]<0>-(0)[0:swapper/0]ffffffc000399198, [ 468.948739]<0>-(0)[0:swapper/0]ffffffc0000854f8, [ 468.948746]<0>-(0)[0:swapper/0]ffffffc0000ff818, [ 468.948751]<0>-(0)[0:swapper/0]ffffffc00094572c, [ 468.948757]<0>-(0)[0:swapper/0]ffffffc000cbf764, [ 468.948762]<0>-(0)[0:swapper/0] [ 468.948762]<0>========================================== |
而CPU0的调用栈如下:
| [ 459.065394]<0>-(0)[0:swapper/0]Call trace: [ 459.065408]<0>-(0)[0:swapper/0][<ffffffc0003d43f8>] aee_wdt_atf_info+0x4bc/0x6b4 [ 459.065420]<0>-(0)[0:swapper/0][<ffffffc0003d4654>] aee_wdt_atf_entry+0x64/0x78 [ 459.065434]<0>-(0)[0:swapper/0][<ffffffc000399154>] rgidle_handler+0x18/0x2c [ 459.065447]<0>-(0)[0:swapper/0][<ffffffc000399198>] arch_idle+0x30/0x50 [ 459.065461]<0>-(0)[0:swapper/0][<ffffffc0000854f8>] arch_cpu_idle+0x14/0x34 [ 459.065474]<0>-(0)[0:swapper/0][<ffffffc0000ff818>] cpu_startup_entry+0x188/0x230 [ 459.065489]<0>-(0)[0:swapper/0][<ffffffc00094572c>] rest_init+0x7c/0x88 [ 459.065502]<0>-(0)[0:swapper/0][<ffffffc000cbf764>] start_kernel+0x2f4/0x30c |
CPU0处于idle状态,那CPU1去哪里了呢?这时候需要检查前面是否有CPU1活动的log,结果SYS_KERNEL_LOG里没看到CPU1的任何log,怀疑是CPU1已被shutdown了,查看hps_main进程(负责CPU hotplug),刚好有印出来,如下:
| [ 469.133143]<0>-(0)[0:swapper/0]PID: 69, name: hps_main [ 469.133149]<0>-(0)[0:swapper/0]Call trace: [ 469.133160]<0>-(0)[0:swapper/0][<ffffffc000085b84>] __switch_to+0x74/0x8c [ 469.133172]<0>-(0)[0:swapper/0][<ffffffc000958c9c>] __schedule+0x314/0x784 [ 469.133185]<0>-(0)[0:swapper/0][<ffffffc00095896c>] preempt_schedule+0x40/0x5c [ 469.133199]<0>-(0)[0:swapper/0][<ffffffc000119088>] queue_stop_cpus_work+0x110/0x12c [ 469.133210]<0>-(0)[0:swapper/0][<ffffffc0001190e0>] __stop_cpus+0x3c/0x68 [ 469.133222]<0>-(0)[0:swapper/0][<ffffffc0001194b4>] stop_cpus+0x38/0x58 [ 469.133233]<0>-(0)[0:swapper/0][<ffffffc0001195e0>] __stop_machine+0xa8/0xe8 [ 469.133245]<0>-(0)[0:swapper/0][<ffffffc000945a24>] _cpu_down+0x158/0x2a4 [ 469.133257]<0>-(0)[0:swapper/0][<ffffffc000945cd4>] cpu_down+0x30/0x5c [ 469.133269]<0>-(0)[0:swapper/0][<ffffffc0003cfb28>] hps_algo_smp+0x694/0x99c [ 469.133283]<0>-(0)[0:swapper/0][<ffffffc0003ca9ec>] _hps_task_main+0x54/0x190 [ 469.133294]<0>-(0)[0:swapper/0][<ffffffc0000be1e0>] kthread+0xb0/0xbc |
可以看到CPU down时被抢占了,估计当时在做CPU1 shotdown被抢断,导致check bit没有更新,而CPU1又无法喂狗,引起HWT了。
需要分析为何hps_main被抢断。hps_main是rt thread,除非有高优先级thread进来或被throttled。
查看CPU0 runqueue:
| [ 468.958888]<0>-(0)[0:swapper/0]cpu#0: Online [ 468.958896]<0>-(0)[0:swapper/0] .nr_running : 7 [ 468.958903]<0>-(0)[0:swapper/0] .load : 0 |
好几个rt thread等待调度,发现rt_throttled为1(请自行了解rt throttle概念),所以都堵住了,搜索rt_throttled的原因(搜索throttl关键字):
| [ 415.567803]<0>-(0)[721:kworker/0:2]sched: cpu=0 rt_time 950980923 <-> runtime [950000000 -> 950000000], exec_task[37:pmic_thread], prio=1, exec_delta_time[1219615], clock_task[415564248939], exec_start[415563029324] [ 415.567803]<0>sched: RT throttling activated cpu=0 ...... [ 421.387802]<0>-(0)[0:swapper/0]sched: unthrottle wdtk-0 ...... [ 441.397788]<0>-(0)[0:swapper/0]sched: unthrottle wdtk-0 |
看到throttling的进程是pmic_thread,原因通常是长时间运行而受到惩罚。搜索有关pmic_thread的log,发现该线程吐了大量的log:
| [ 415.560569]<0>-(0)[37:pmic_thread][PMIC] [mt_pmic_eint_irq] receive interrupt [ 415.560578]<0>-(0)[37:pmic_thread][PMIC] [wake_up_pmic] [ 415.560596]<0> (0)[37:pmic_thread][PMIC] [PMIC_INT] pwrap_eint_status=0x1 [ 415.560611]<0> (0)[37:pmic_thread][PMIC] [PMIC_INT] addr[0x2c4]=0x0 [ 415.560627]<0> (0)[37:pmic_thread][PMIC] [PMIC_INT] addr[0x2c6]=0x200 [ 415.560637]<0> (0)[37:pmic_thread][PMIC] [PMIC_INT][RG_INT_STATUS_LDO_OC] [ 415.560652]<0> (0)[37:pmic_thread][PMIC] [ldo_int_handler] Reg[0x2c6]=0x200 [ 415.560667]<0> (0)[37:pmic_thread][PMIC] PMIC SD OC PMIC_OC_STATUS_VMCH =0x400 [ 415.560715]<0> (0)[37:pmic_thread][PMIC] [PMIC_INT] addr[0x2c8]=0x0 [ 415.560726]<0> (0)[37:pmic_thread][PWRAP] clear EINT flag mt_pmic_wrap_eint_status=0x0 [ 415.560742]<0> (0)[37:pmic_thread][PMIC] [PMIC_INT] after ,int_status_val[0x2c4]=0x0 [ 415.560758]<0> (0)[37:pmic_thread][PMIC] [PMIC_INT] after ,int_status_val[0x2c6]=0x200 [ 415.560773]<0> (0)[37:pmic_thread][PMIC] [PMIC_INT] after ,int_status_val[0x2c8]=0x0 |
所以很明显,问题就pmic_thread吐大量log引起rt throttle,进而影响到hps_main,产生HWT。
解决方法
找出PMIC吐大量log的原因。
结语
HWT本质上就是调度问题,因此滥用实时进程或实时进程长时间占用CPU,有可能引起系统无法及时响应。
这个问题的解决核心就是要找到谁引起了rt throttle,找到了就好处理了。
所以往系统里添加实时进程或提升进程优先级为实时都要非常小心。
19 HWT-hotplug失败
基本信息
问题:遇到一次HWT
版本:alps-mp-m0.mp7
平台:MT6755
分析过程
抓取mtklog,里面包含db,db名字叫db.fatal.00.HWT.dbg,用E-Consulter分析,生成的报告如下:
== 异常报告v1.4(仅供参考) ==
详细描述: 看门狗复位, 其中CPU4,5,6没有喂狗, 请检查对应调用栈是否存在死锁或长时间关中断
参考信息: MediaTek On-Line> Quick Start> 深入分析看门狗框架
异常时间: 80085.401764秒, Mon May 2 10:33:18 CST 2016
== CPU信息 ==
无喂狗CPU信息:
CPU4: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux multi_cpu_stop(data=0xFFFFFFC07EF23A08) + 92 <kernel/stop_machine.c:192>
vmlinux cpu_stopper_thread() + 180 <kernel/stop_machine.c:458>
vmlinux smpboot_thread_fn(data=0xFFFFFFC0B8115880) + 508 <kernel/smpboot.c:160>
vmlinux kthread(_create=0xFFFFFFC0B81158C0) + 212 <kernel/kthread.c:207>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:808>
== 栈结束 ==
CPU5: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux multi_cpu_stop(data=0xFFFFFFC07EF23A08) + 88 <kernel/stop_machine.c:192>
vmlinux cpu_stopper_thread() + 180 <kernel/stop_machine.c:458>
vmlinux smpboot_thread_fn(data=0xFFFFFFC0B81E8000) + 508 <kernel/smpboot.c:160>
vmlinux kthread(_create=0xFFFFFFC0B81E8040) + 212 <kernel/kthread.c:207>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:808>
== 栈结束 ==
CPU6: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux multi_cpu_stop(data=0xFFFFFFC07EF23A08) + 92 <kernel/stop_machine.c:192>
vmlinux cpu_stopper_thread() + 180 <kernel/stop_machine.c:458>
vmlinux smpboot_thread_fn(data=0xFFFFFFC0B81E8340) + 508 <kernel/smpboot.c:160>
vmlinux kthread(_create=0xFFFFFFC0B81E8380) + 212 <kernel/kthread.c:207>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:808>
== 栈结束 ==
其他CPU信息:
CPU0: 进程名: (null), 进程标识符(pid): 0
寄存器异常: SP(0xFFFFFFC00798FFF0)/FP(0x000048D66FC9A8E4)不在同一内核栈
本地调用栈:
...... 0x0000000073E104F4()
== 栈结束 ==
CPU1: 空闲
CPU2: 空闲
CPU7: 进程名: kworker/u17:3, 进程标识符(pid): 24521
本地调用栈:
vmlinux pm_callback_power_off(kbdev=0xFFFFFFC0B16F0000) + 84 <drivers/misc/mediatek/gpu/gpu_mali/mali_midgard/mali-r7p0/drivers/gpu/arm/midgard/platform/mt6755/mtk_config_platform.c:166>
vmlinux kbase_pm_clock_off(kbdev=0xFFFFFFC0B16F0000, is_suspend=false) + 148 <drivers/misc/mediatek/gpu/gpu_mali/mali_midgard/mali-r7p0/drivers/gpu/arm/midgard/backend/gpu/mali_kbase_pm_driver.c:1010>
vmlinux kbase_pm_do_poweroff(kbdev=0xFFFFFFC0B16F0000, is_suspend=false) + 84 <drivers/misc/mediatek/gpu/gpu_mali/mali_midgard/mali-r7p0/drivers/gpu/arm/midgard/backend/gpu/mali_kbase_pm_backend.c:201>
vmlinux kbasep_pm_do_gpu_poweroff_wq(data=0xFFFFFFC0B16F02E0) + 172 <drivers/misc/mediatek/gpu/gpu_mali/mali_midgard/mali-r7p0/drivers/gpu/arm/midgard/backend/gpu/mali_kbase_pm_policy.c:268>
vmlinux process_one_work(worker=0xFFFFFFC0686E6B40, work=0xFFFFFFC0B16F02E0) + 340 <kernel/workqueue.c:2014>
vmlinux worker_thread(__worker=0xFFFFFFC0686E6B40) + 316 <kernel/workqueue.c:2146>
vmlinux kthread(_create=0xFFFFFFC02AB4BC00) + 212 <kernel/kthread.c:207>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:808>
== 栈结束 ==
处于cpu stop machine机制里,但很奇怪CPU0/1/2/7不在stop machine机制里,而CPU0的PC =0x0000000073E104F4,这个地址是user space的地址。先观察kick/check bit(在SYS_LAST_KMSG里):
kick=0x00000087,check=0x00000070
这个也非常奇怪,共有3个CPU(CPU4~6)online,但kick bit显示,CPU0~2和CPU7有喂狗,而CPU4~6没有喂狗,正确情况下check bit|kick bit = check bit的,任何CPU offline都会清除check bit和kick bit对应的bit。
怀疑wdk驱动有问题,这时需要在SYS_KERNEL_LOG里搜索wdk关键字,结果没有搜到任何log,应该是log被冲走,此时需要查看mobile log里的kernel log,搜索后存在如下log:
Line 375346: [80038.302561] .(2)[215:wdtk-2][name:wd_common_drv&][WDK],local_bit:0x4,cpu:2,check bit0x:ff,3,1,80038291783408,RT[80038302537870]
Line 375347: [80038.322654] .(1)[214:wdtk-1][name:wd_common_drv&][WDK],local_bit:0x6,cpu:1,check bit0x:ff,3,1,80038291783408,RT[80038322580562]
Line 378956: [80058.002641] .(0)[213:wdtk-0][name:wd_common_drv&][WDK],local_bit:0x1,cpu:0,check bit0x:70,2,0,80054385300139,RT[80058002570917]
Line 378959: [80058.222523] .(7)[220:wdtk-7][name:wd_common_drv&][WDK],local_bit:0x81,cpu:7,check bit0x:70,2,0,80054385300139,RT[80058222499764]
Line 378985: [80058.312706] .(2)[215:wdtk-2][name:wd_common_drv&][WDK],local_bit:0x85,cpu:2,check bit0x:70,2,0,80054385300139,RT[80058312634302]
Line 378987: [80058.332677] .(1)[214:wdtk-1][name:wd_common_drv&][WDK],local_bit:0x87,cpu:1,check bit0x:70,2,0,80054385300139,RT[80058332619072]
第Line 378956行就看出问题点了,check bit为0x70,但是喂狗的CPU是CPU0,所以应该是第Line 375347行到第Line 378956行中间存在什么问题才对,为何从0xFF变为0x70呢,是否是CPU0/1/2/3/7都offline了呢?我们需要在这中间的log里搜索所有hotplug相关的log,需要搜索关键字:shutdown和Booted secondary processor,搜索结果如下:
Line 4: [80038.335538] .(4)[107:hps_main]CPU3: shutdown
Line 9: [80038.381523] .(1)[107:hps_main]CPU2: shutdown
Line 10: [80038.386723] .(4)[107:hps_main]CPU1: shutdown
Line 26: [80038.512832] .(0)[107:hps_main]CPU7: shutdown
Line 28: [80038.519628] .(6)[107:hps_main]CPU0: shutdown
Line 70: [80038.901728] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 123: [80039.284082] .(5)[1178:PerfServiceMana]CPU7: shutdown
Line 155: [80039.570198] .(4)[107:hps_main]CPU6: shutdown
Line 171: [80040.027143] -(6)[0:swapper/6]CPU6: Booted secondary processor
Line 184: [80040.110076] -(0)[0:swapper/0]CPU0: Booted secondary processor
Line 191: [80040.127737] -(1)[0:swapper/1]CPU1: Booted secondary processor
Line 194: [80040.128942] -(2)[0:swapper/2]CPU2: Booted secondary processor
Line 197: [80040.130156] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 202: [80040.137509] .(5)[1178:PerfServiceMana]CPU2: shutdown
Line 203: [80040.140575] .(6)[1178:PerfServiceMana]CPU1: shutdown
Line 205: [80040.148867] .(5)[1178:PerfServiceMana]CPU0: shutdown
Line 226: [80040.353843] -(0)[0:swapper/0]CPU0: Booted secondary processor
Line 232: [80040.358386] -(1)[0:swapper/1]CPU1: Booted secondary processor
Line 235: [80040.359608] -(2)[0:swapper/2]CPU2: Booted secondary processor
Line 238: [80040.361265] -(3)[0:swapper/3]CPU3: Booted secondary processor
Line 242: [80040.366672] .(0)[107:hps_main]CPU3: shutdown
Line 248: [80040.493285] .(0)[107:hps_main]CPU2: shutdown
Line 255: [80040.579811] .(0)[107:hps_main]CPU1: shutdown
Line 285: [80040.740389] -(1)[0:swapper/1]CPU1: Booted secondary processor
Line 288: [80040.741851] -(2)[0:swapper/2]CPU2: Booted secondary processor
Line 306: [80040.826069] .(1)[107:hps_main]CPU7: shutdown
Line 307: [80040.829006] .(0)[107:hps_main]CPU2: shutdown
Line 308: [80040.831388] .(0)[107:hps_main]CPU1: shutdown
Line 310: [80040.837553] .(4)[107:hps_main]CPU0: shutdown
Line 316: [80040.922198] .(4)[107:hps_main]CPU6: shutdown
Line 329: [80041.193743] -(6)[0:swapper/6]CPU6: Booted secondary processor
Line 401: [80042.211584] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 419: [80042.415565] .(4)[107:hps_main]CPU7: shutdown
Line 465: [80043.421962] .(4)[107:hps_main]CPU6: shutdown
Line 480: [80043.636278] -(6)[0:swapper/6]CPU6: Booted secondary processor
Line 507: [80043.770713] -(0)[0:swapper/0]CPU0: Booted secondary processor
Line 514: [80043.779588] -(1)[0:swapper/1]CPU1: Booted secondary processor
Line 517: [80043.780561] -(2)[0:swapper/2]CPU2: Booted secondary processor
Line 520: [80043.781469] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 525: [80043.785328] .(0)[1178:PerfServiceMana]CPU2: shutdown
Line 526: [80043.788119] .(4)[1178:PerfServiceMana]CPU1: shutdown
Line 528: [80043.800376] .(4)[1178:PerfServiceMana]CPU0: shutdown
Line 629: [80045.089281] .(4)[107:hps_main]CPU7: shutdown
Line 686: [80045.294509] .(4)[107:hps_main]CPU6: shutdown
Line 729: [80045.819457] -(6)[0:swapper/6]CPU6: Booted secondary processor
Line 732: [80045.820535] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 737: [80045.864148] .(6)[107:hps_main]CPU7: shutdown
Line 740: [80045.908453] .(4)[107:hps_main]CPU6: shutdown
Line 783: [80046.359628] -(6)[0:swapper/6]CPU6: Booted secondary processor
Line 786: [80046.360802] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 945: [80048.197443] -(0)[0:swapper/0]CPU0: Booted secondary processor
Line 984: [80048.372879] -(1)[0:swapper/1]CPU1: Booted secondary processor
Line 987: [80048.374537] -(2)[0:swapper/2]CPU2: Booted secondary processor
Line 1004: [80048.401643] .(0)[107:hps_main]CPU2: shutdown
Line 1005: [80048.404261] .(0)[107:hps_main]CPU1: shutdown
Line 1009: [80048.410193] .(7)[107:hps_main]CPU0: shutdown
Line 1040: [80048.735303] .(5)[107:hps_main]CPU7: shutdown
Line 1052: [80048.980005] .(4)[107:hps_main]CPU6: shutdown
Line 1063: [80049.128341] -(6)[0:swapper/6]CPU6: Booted secondary processor
Line 1077: [80049.344371] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 1086: [80049.387668] .(5)[107:hps_main]CPU7: shutdown
Line 1135: [80049.752453] .(4)[107:hps_main]CPU6: shutdown
Line 1141: [80049.790455] -(6)[0:swapper/6]CPU6: Booted secondary processor
Line 1144: [80049.791477] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 1214: [80050.277939] -(0)[0:swapper/0]CPU0: Booted secondary processor
Line 1255: [80050.567390] .(5)[107:hps_main]CPU7: shutdown
Line 1257: [80050.572914] .(5)[107:hps_main]CPU0: shutdown
Line 1342: [80051.411362] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 1375: [80051.619328] -(0)[0:swapper/0]CPU0: Booted secondary processor
Line 1382: [80051.623771] -(1)[0:swapper/1]CPU1: Booted secondary processor
Line 1385: [80051.624921] -(2)[0:swapper/2]CPU2: Booted secondary processor
Line 1388: [80051.626646] -(3)[0:swapper/3]CPU3: Booted secondary processor
Line 1392: [80051.631002] .(5)[107:hps_main]CPU3: shutdown
Line 1393: [80051.635980] .(0)[107:hps_main]CPU2: shutdown
Line 1394: [80051.641149] .(0)[107:hps_main]CPU1: shutdown
Line 1420: [80051.889204] .(7)[107:hps_main]CPU0: shutdown
Line 1423: [80051.934015] .(5)[107:hps_main]CPU7: shutdown
Line 1502: [80052.338502] -(7)[0:swapper/7]CPU7: Booted secondary processor
Line 3547: [80054.371641] -(0)[0:swapper/0]CPU0: Booted secondary processor
Line 3551: [80054.376534] -(1)[0:swapper/1]CPU1: Booted secondary processor
Line 3555: [80054.382207] -(2)[0:swapper/2]CPU2: Booted secondary processor
先仅仅检查CPU0的log,最后的情况是CPU0 online,再检查CPU1,CPU1最后也是online,检查CPU2,CPU2也是online,检查CPU3,CPU3是offline,检查CPU7,CPU7也是online,那为什么check bit显示只有0x70呢,如果按正常来讲,应该是0xF7才对。
仔细检查CPU0/1/2/7最后一次Booted secondary processor的log:
[80053.332505] .(6)[107:hps_main]CPU7: failed to come online
......
[80054.371470] .(4)[1178:PerfServiceMana]CPU0: failed to come online
[80054.371641] -(0)[0:swapper/0]CPU0: Booted secondary processor
[80054.371684] -(0)[0:swapper/0]Detected VIPT I-cache on CPU0
[80054.372380] -(0)[0:swapper/0]CPU0: update cpu_capacity 600
[80054.376391] .(4)[1178:PerfServiceMana]CPU1: failed to come online
[80054.376534] -(1)[0:swapper/1]CPU1: Booted secondary processor
[80054.376572] -(1)[0:swapper/1]Detected VIPT I-cache on CPU1
[80054.376873] -(1)[0:swapper/1]CPU1: update cpu_capacity 600
[80054.382058] .(4)[1178:PerfServiceMana]CPU2: failed to come online
[80054.382207] -(2)[0:swapper/2]CPU2: Booted secondary processor
看到了failed to come online,检查该log对应的代码:
int __cpu_up(unsigned int cpu, struct task_struct *idle)
{
int ret;
secondary_data.stack = task_stack_page(idle) + THREAD_START_SP;
__flush_dcache_area(&secondary_data, sizeof(secondary_data));
#ifdef CONFIG_ARM64_IRQ_STACK
init_irq_stack(cpu);
#endif
ret = boot_secondary(cpu, idle);
if (ret == 0) {
wait_for_completion_timeout(&cpu_running, msecs_to_jiffies(1000));
if (!cpu_online(cpu)) {
pr_crit("CPU%u: failed to come online\n", cpu);
ret = -EIO;
}
......
}
......
}
是CPU up时超时引起的,kernel设定的时间是1s,如果1s没有收到completion,那么就表示CPU启动失败了,但是从log看到failed to come online之后对应的CPU又起来了,如CPU0:
[80054.371470] .(4)[1178:PerfServiceMana]CPU0: failed to come online
[80054.371641] -(0)[0:swapper/0]CPU0: Booted secondary processor
由于对应的CPU已跑起来,那么就导致对应的kick thread继续喂狗,会更新对应的kick bit,但check bit就没有更新了,这就导致kick bit有对应的bit但check bit没有对应的bit。
fail to come online的原因是什么呢?猜测是CPU boot up flow比较慢,检查secondary_start_kernel()的流程:
asmlinkage void secondary_start_kernel(void)
{
struct mm_struct *mm = &init_mm;
unsigned int cpu = smp_processor_id();
aee_rr_rec_hoplug(cpu, 1, 0);
atomic_inc(&mm->mm_count);
current->active_mm = mm;
cpumask_set_cpu(cpu, mm_cpumask(mm));
aee_rr_rec_hoplug(cpu, 2, 0);
set_my_cpu_offset(per_cpu_offset(smp_processor_id()));
printk("CPU%u: Booted secondary processor\n", cpu);
aee_rr_rec_hoplug(cpu, 3, 0);
cpu_set_reserved_ttbr0();
aee_rr_rec_hoplug(cpu, 4, 0);
flush_tlb_all();
aee_rr_rec_hoplug(cpu, 5, 0);
preempt_disable();
aee_rr_rec_hoplug(cpu, 6, 0);
trace_hardirqs_off();
aee_rr_rec_hoplug(cpu, 7, 0);
if (cpu_ops[cpu]->cpu_postboot)
cpu_ops[cpu]->cpu_postboot();
aee_rr_rec_hoplug(cpu, 8, 0);
cpuinfo_store_cpu();
aee_rr_rec_hoplug(cpu, 9, 0);
notify_cpu_starting(cpu);
aee_rr_rec_hoplug(cpu, 10, 0);
smp_store_cpu_info(cpu);
aee_rr_rec_hoplug(cpu, 11, 0);
set_cpu_online(cpu, true);
aee_rr_rec_hoplug(cpu, 12, 0);
complete(&cpu_running); /* 这里通知__cpu_up()完成了bootup */
aee_rr_rec_hoplug(cpu, 13, 0);
local_dbg_enable();
aee_rr_rec_hoplug(cpu, 14, 0);
local_irq_enable();
aee_rr_rec_hoplug(cpu, 15, 0);
local_async_enable();
aee_rr_rec_hoplug(cpu, 16, 0);
cpu_startup_entry(CPUHP_ONLINE);
aee_rr_rec_hoplug(cpu, 17, 0);
}
估计在ATF等其他地方卡的比较久引起。
解决方法
尝试延长1s到2s看看。
结语
这题并不是因为卡住引起HWT,因此分析当前的各个CPU的调用栈是无任何意义的。应该先查清check bit和kick bit异常原因。
另外这题需要熟悉wdk驱动喂狗流程,比如CPU up fail后wdk驱动会如何处理。
20 HWT-在TEE OS里卡死
基本信息
问题:售后反馈的的HWT
版本:ALPS.L1.MP3
平台:MT6753
分析过程
抓取db,db名字就叫db.fatal.00.HWT.dbg,所以是个HWT,用E-Consulter分析,加入vmlinux后,得出分析报告如下:
== 异常报告v1.4(仅供参考) ==
详细描述: 看门狗复位, 其中CPU0,1,2没有喂狗, 请检查对应调用栈是否存在死锁或长时间关中断
参考信息: MediaTek On-Line> Quick Start> 深入分析看门狗框架
异常时间: 140.634246秒, Tue Apr 12 19:59:16 CST 2016
== CPU信息 ==
无喂狗CPU信息:
CPU0: 进程名: (null), 进程标识符(pid): 0
寄存器异常: SP(0x0000000000000000)异常
本地调用栈:
...... 0x0000000007F08038()
== 栈结束 ==
CPU1: 进程名: migration/1, 进程标识符(pid): 11
本地调用栈:
vmlinux stop_machine_cpu_stop(data=0xFFFFFFC0ACABFB58) + 84 <kernel/stop_machine.c:427>
vmlinux cpu_stopper_thread(cpu=1) + 180 <kernel/stop_machine.c:285>
vmlinux smpboot_thread_fn(data=0xFFFFFFC0B5238B00) + 492 <kernel/smpboot.c:160>
vmlinux kthread(_create=0xFFFFFFC0B524FC30) + 176 <kernel/kthread.c:200>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:764>
== 栈结束 ==
CPU2: 进程名: migration/2, 进程标识符(pid): 15
本地调用栈:
vmlinux stop_machine_cpu_stop(data=0xFFFFFFC0ACABFB58) + 84 <kernel/stop_machine.c:427>
vmlinux cpu_stopper_thread(cpu=2) + 180 <kernel/stop_machine.c:285>
vmlinux smpboot_thread_fn(data=0xFFFFFFC0B5238D40) + 492 <kernel/smpboot.c:160>
vmlinux kthread(_create=0xFFFFFFC0B524FC30) + 176 <kernel/kthread.c:200>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:764>
== 栈结束 ==
CPU0~2都没有喂狗,CPU1、CPU2都停在stop_machine_cpu_stop,这个是stop machine机制,需要所有在线CPU同步进入stop_machine_cpu_stop,所以真正卡住的是CPU0。
CPU0没有调用栈,为什么呢?查看last_kmsg确实没有看到CPU0的调用栈的,只能看last pc了,查看SYS_REBOOT_REASON:
WDT status: 2 fiq step: 41 exception type: 1
[LAST PC] CORE_0 PC = 0x7f08038( + 0x0), FP = 0x7f12f0c, SP = 0x0
[LAST PC] CORE_1 PC = 0xffffffc0002f3d70(number.isra.2 + 0x1a0), FP = 0xffffffc0b3862f30, SP = 0xffffffc0b3862f30
[LAST PC] CORE_2 PC = 0xffffffc0003d962c(aee_wdt_atf_info + 0x474), FP = 0xffffffc0b3877af0, SP = 0xffffffc0b3877af0
这个PC地址不是kernel地址(64bit kernel地址范围:0xFFFF_FF80_0000_0000 ~ 0xFFFF_FFFF_FFFF_FFFF),也不是lk地址(0x41000000~),那是什么地址呢?
检查发现是Trustonic OS的范围:Secure OS: 0x07C0_0000 ~ 0x0800_0000。也就是说CPU0卡在TEE OS里导致HWT的。
我们再检查下SYS_ATF_LOG,看到
[ATF][ 139.633485]tbase_fastcall_handler TBASE_SMC_FASTCALL_FORWARD_FIQ [ATF][ 139.633537]core 0 EL3 received forwarded FIQ 160 from [ATF][ 139.633588]core 0 is dumped !
[ATF][ 139.633614]=> aee_wdt_dump, cpu 0
[ATF][ 139.633644]core 1 is dumped !
[ATF][ 139.633671]=> aee_wdt_dump, cpu 1
[ATF][ 139.633701]core 2 is dumped !
[ATF][ 139.633728]=> aee_wdt_dump, cpu 2
可以看到CPU1、2是从kernel陷入ATF,而CPU0是从tbase os陷入ATF,再次验证CPU0卡在TEE OS里。
TEE OS不开放,因此需要找TEE FAE排查原因。
解决方法
找TEE FAE排查原因。
结语
越来越多的手机支持TEE,因此也带来了新的问题。以往没有卡在TEE的案例,而后面则可能存在越来越多的类似TEE引起的问题要调试。
21 HWT-spinlock嵌套死锁
基本信息
问题:打开cpuset功能后容易发生KE死机
版本:ALPS.L1.MP10
平台:MT6750
分析过程
抓取mtklog,里面包含db,用E-Consulter分析,生成的报告如下:
== 异常报告v1.4(仅供参考) ==
报告解读: MediaTek On-Line> Quick Start> E-Consulter之NE/KE分析报告解读> KE分析报告
详细描述: 看门狗复位, 其中CPU4,5,6没有喂狗, 请检查对应调用栈是否存在死锁或长时间关中断
参考信息: MediaTek On-Line> Quick Start> 深入分析看门狗框架
异常时间: 179.520409秒, Fri Apr 29 16:34:38 CST 2016
== CPU信息 ==
无喂狗CPU信息:
CPU4: 进程名: PerfServiceMana, 进程标识符(pid): 1088, 中断: 关
本地调用栈:
vmlinux arch_counter_get_cntpct() + 4 <arch/arm64/include/asm/arch_timer.h:118>
vmlinux arch_timer_read_counter() + 16 <drivers/misc/mediatek/mach/mt6755/ca53_timer.c:268>
vmlinux read_current_timer(timer_value=0xFFFFFFC06BF4B5B8) + 16 <arch/arm64/kernel/time.c:66>
vmlinux __delay(cycles=1) + 20 <arch/arm64/lib/delay.c:29>
vmlinux __spin_lock_debug() + 128 <lib/spinlock_debug.c:144>
vmlinux do_raw_spin_lock(lock=0xFFFFFFC0BB140DC0) + 396 <lib/spinlock_debug.c:207>
vmlinux __raw_spin_lock_irq() + 52 <include/linux/spinlock_api_smp.h:129>
vmlinux _raw_spin_lock_irq(lock=0xFFFFFFC0BB140DC0) + 72 <kernel/spinlock.c:153>
vmlinux __schedule() + 196 <kernel/sched/core.c:3263>
vmlinux schedule() + 36 <kernel/sched/core.c:3346>
vmlinux schedule_timeout(timeout=9223372036854775807) + 372 <kernel/timer.c:1458>
vmlinux __down_common(timeout=9223372036854775807) + 64 <kernel/semaphore.c:221>
vmlinux __down(sem=console_sem) + 80 <kernel/semaphore.c:238>
vmlinux down(sem=console_sem) + 68 <kernel/semaphore.c:61>
vmlinux console_lock() + 28 <kernel/printk.c:2122>
vmlinux console_cpu_notify(action=2, hcpu=6) + 52 <kernel/printk.c:2104>
vmlinux notifier_call_chain() + 104 <kernel/notifier.c:127>
vmlinux __raw_notifier_call_chain(nr_to_call=-1, nr_calls=0) + 8 <kernel/notifier.c:442>
vmlinux __cpu_notify() + 36 <kernel/cpu.c:240>
vmlinux cpu_notify(val=2, v=6) + 40 <kernel/cpu.c:248>
vmlinux _cpu_up(cpu=6, tasks_frozen=0) + 340 <kernel/cpu.c:518>
vmlinux _cpu_up_profile() + 20 <kernel/cpu.c:538>
vmlinux cpu_up(cpu=6) + 152 <kernel/cpu.c:613>
vmlinux hps_algo_cpu_cluster_action(online_cores=2, target_cores=4) + 240 <drivers/misc/mediatek/mach/mt6755/mt_hotplug_strategy_algo.c:127>
vmlinux hps_algo_amp() + 1840 <drivers/misc/mediatek/mach/mt6755/mt_hotplug_strategy_algo.c:1254>
vmlinux ppm_limit_callback() + 244 <drivers/misc/mediatek/mach/mt6755/mt_hotplug_strategy_core.c:305>
vmlinux mt_ppm_main() + 1368 <drivers/misc/mediatek/ppm/src/mt_ppm_main.c:560>
vmlinux ppm_task_wakeup() + 24 <drivers/misc/mediatek/ppm/src/mt_ppm_main.c:191>
vmlinux ppm_userlimit_max_cpu_core_proc_write(count=4) + 396 <drivers/misc/mediatek/ppm/src/mt_ppm_policy_user_limit.c:269>
vmlinux proc_reg_write() + 76 <fs/proc/inode.c:225>
vmlinux vfs_write(file=0xFFFFFFC09BB8B000, buf=0x0000007F6C7D5E08, count=4, pos=0xFFFFFFC06BF4BEC8) + 164 <fs/read_write.c:446>
vmlinux SYSC_write() + 48 <fs/read_write.c:494>
vmlinux SyS_write(buf=547281001992) + 64 <fs/read_write.c:486>
== 栈结束 ==
CPU5: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_counter_get_cntpct() + 4 <arch/arm64/include/asm/arch_timer.h:118>
vmlinux arch_timer_read_counter() + 16 <drivers/misc/mediatek/mach/mt6755/ca53_timer.c:268>
vmlinux read_current_timer() + 16 <arch/arm64/kernel/time.c:66>
...... ......
vmlinux vsnprintf(args=0xFFFFFFC0A709F7D0) + 132 <lib/vsprintf.c:1440>
vmlinux snprintf(buf=0xFFFFFFC0A98A6080, size=80) + 80 <lib/vsprintf.c:1631>
vmlinux __update_entity_runnable_avg() + 296 <kernel/sched/fair.c:1790>
vmlinux update_entity_load_avg() + 320 <kernel/sched/fair.c:2186>
vmlinux put_prev_entity(cfs_rq=0xFFFFFFC0BB14CE68, prev=2) + 496 <kernel/sched/fair.c:2815>
...... ......
vmlinux __buffer_unlock_commit() + 52 <kernel/trace/trace.c:1622>
...... ......
vmlinux ftrace_raw_event_sched_switch() + 344 <include/trace/events/sched.h:257>
...... ......
vmlinux preempt_schedule() + 64 <kernel/sched/core.c:3396>
...... ......
vmlinux task_rq_unlock() + 16 <kernel/sched/core.c:361>
vmlinux set_cpus_allowed_ptr() + 160 <kernel/sched/core.c:5212>
vmlinux cpuset_change_cpumask(tsk=0xFFFFFFC04E8A0000) + 20 <kernel/cpuset.c:833>
vmlinux cgroup_scan_tasks(scan=0xFFFFFFC0A709FCA8) + 340 <kernel/cgroup.c:3303>
vmlinux update_tasks_cpumask() + 40 <kernel/cpuset.c:857>
vmlinux cpuset_propagate_hotplug_workfn(work=0xFFFFFFC0A456D398) + 316 <kernel/cpuset.c:2099>
vmlinux process_one_work(worker=0xFFFFFFC0A779F8C0, work=0xFFFFFFC0A456D398) + 404 <kernel/workqueue.c:2182>
vmlinux worker_thread(__worker=0xFFFFFFC0A779F8C0) + 304 <kernel/workqueue.c:2309>
vmlinux kthread(_create=0xFFFFFFC0AE19BC00) + 176 <kernel/kthread.c:200>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:764>
== 栈结束 ==
CPU6: 进程名: (null), 进程标识符(pid): 0
本地调用栈:
vmlinux arch_timer_read_counter() <drivers/misc/mediatek/mach/mt6755/ca53_timer.c:265>
...... ......
...... ......
vmlinux __raw_spin_unlock_irqrestore() + 28 <include/linux/spinlock_api_smp.h:159>
vmlinux _raw_spin_unlock_irqrestore(flags=-272031334328) + 32 <kernel/spinlock.c:177>
vmlinux unlock_hrtimer_base() + 12 <kernel/hrtimer.c:852>
vmlinux __hrtimer_start_range_ns() + 388 <kernel/hrtimer.c:1056>
...... ......
vmlinux wake_up_worker() + 28 <kernel/workqueue.c:788>
vmlinux insert_work(pwq=0xFFFFFFC0B286F000, work=gCmdqContext + 56, extra_flags=0) + 104 <kernel/workqueue.c:1271>
vmlinux __queue_work(cpu=8, wq=0xFFFFFFC0B284F840, work=gCmdqContext + 56) + 300 <kernel/workqueue.c:1386>
vmlinux queue_work_on(cpu=8, wq=0xFFFFFFC0B284F840, work=gCmdqContext + 56) + 116 <kernel/workqueue.c:1411>
vmlinux queue_work() + 12 <include/linux/workqueue.h:469>
vmlinux cmdq_core_add_consume_task() + 64 <drivers/misc/mediatek/cmdq/v2/cmdq_core.c:3373>
vmlinux cmdq_irq_handler() + 176 <drivers/misc/mediatek/cmdq/v2/cmdq_driver.c:867>
...... 0xFFFFFFC091D8BD50()
== 栈结束 ==
== 日志信息 ==
kernel log:
[ 148.504613]-(5)[197:kworker/u16:4]BUG: spinlock recursion on CPU#5, kworker/u16:4/197
[ 148.504618]-(5)[197:kworker/u16:4]BUG: spinlock recursion on CPU#5, kworker/u16:4/197
[ 148.505099]-(5)[197:kworker/u16:4]BUG: spinlock already unlocked on CPU#5, kworker/u16:4/197
[ 148.505351]-(5)[197:kworker/u16:4]BUG: spinlock wrong owner on CPU#5, kworker/u16:4/197
从日志信息看到存在很多spinlock嵌套异常。主要有哪些log呢?我们仔细检查SYS_KERNEL_LOG(搜索关键字‘] lock: ’):
Line 2350: [ 148.504645]-(5)[197:kworker/u16:4] lock: console_sem+0x0/0x50, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: -1 value:0x00000000
Line 2387: [ 148.505111]-(5)[197:kworker/u16:4] lock: logbuf_lock+0x0/0x38, .magic: dead4ead, .owner: /-1, .owner_cpu: -1 value:0x00000000
Line 2420: [ 148.505361]-(5)[197:kworker/u16:4] lock: logbuf_lock+0x0/0x38, .magic: dead4ead, .owner: /-1, .owner_cpu: -1 value:0x00000000
然后也搜索下SYS_LAST_KMSG:
Line 164: [ 148.504645]-(5)[197:kworker/u16:4] lock: console_sem+0x0/0x50, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: -1 value:0x00000000
Line 200: [ 148.505111]-(5)[197:kworker/u16:4] lock: logbuf_lock+0x0/0x38, .magic: dead4ead, .owner: /-1, .owner_cpu: -1 value:0x00000000
Line 233: [ 148.505361]-(5)[197:kworker/u16:4] lock: logbuf_lock+0x0/0x38, .magic: dead4ead, .owner: /-1, .owner_cpu: -1 value:0x00000000
Line 266: [ 148.505603]-(5)[197:kworker/u16:4] lock: logbuf_lock+0x0/0x38, .magic: dead4ead, .owner: /-1, .owner_cpu: -1 value:0x00000000
Line 298: [ 148.506095]-(5)[197:kworker/u16:4] lock: 0xffffffc0bb140dc0, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: 5 value:0x00000001
Line 325: [ 148.506394]-(5)[197:kworker/u16:4] lock: 0xffffffc0bb140dc0, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: 5 value:0x00000001
Line 353: [ 149.504635]-(4)[1088:PerfServiceMana] lock: 0xffffffc0bb140dc0, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: 5 value:0x00000001
Line 385: [ 149.505416]-(6)[757:mobile_log_d.rd] lock: 0xffffffc0bb140dc0, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: 5 value:0x00000001
Line 432: [ 149.506705]-(5)[197:kworker/u16:4] lock: 0xffffffc0bb140dc0, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: 5 value:0x00000001
我们以SYS_LAST_KMSG为基础分析问题(SYS_KENREL_LOG信息较少),主要有以下lock嵌套了:
- console_sem
- logbuf_lock
- 0xffffffc0bb140dc0
同时我们发现CPU4的调用栈是卡在0xffffffc0bb140dc0地址处的spinlock的。那到底哪个才是导致HWT的元凶呢?
如果你熟悉printk,就知道console_sem/logbuf_lock是来自printk的lock,为何printk的lock会引起嵌套呢?
我们看到log:
[ 148.504645]-(5)[197:kworker/u16:4] lock: console_sem+0x0/0x50, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: -1 value:0x00000000
[ 148.504659]-(5)[197:kworker/u16:4]CPU: 5 PID: 197 Comm: kworker/u16:4 Tainted: G W 3.10.72+ #4
[ 148.473856]-(5)[197:kworker/u16:4]powerkey_kick:primary_display_trigger:2,6
[ 148.504680]-(5)[197:kworker/u16:4]Workqueue: cpuset_hotplug cpuset_propagate_hotplug_workfn
[ 148.504687]-(5)[197:kworker/u16:4]
[ 148.504694]-(5)[197:kworker/u16:4]Call trace:
[ 148.504709]-(5)[197:kworker/u16:4][] dump_backtrace+0x0/0x16c
[ 148.504728]-(5)[197:kworker/u16:4][] show_stack+0x10/0x1c
[ 148.504743]-(5)[197:kworker/u16:4][] dump_stack+0x1c/0x28
[ 148.504758]-(5)[197:kworker/u16:4][] spin_dump+0x6c/0x8c
[ 148.504770]-(5)[197:kworker/u16:4][] spin_bug+0x18/0xdc
[ 148.504782]-(5)[197:kworker/u16:4][] do_raw_spin_lock+0xd0/0x274
[ 148.504795]-(5)[197:kworker/u16:4][] _raw_spin_lock_irqsave+0x4c/0x60
[ 148.504808]-(5)[197:kworker/u16:4][] down_trylock+0x10/0x40
[ 148.504821]-(5)[197:kworker/u16:4][] console_trylock+0x24/0xb8 <= 这里要去拿console_sem
[ 148.504834]-(5)[197:kworker/u16:4][] vprintk_emit+0x1f4/0x5b4
[ 148.504850]-(5)[197:kworker/u16:4][] printk+0xb4/0xc0
[ 148.504862]-(5)[197:kworker/u16:4][] spin_dump+0x40/0x8c
[ 148.504874]-(5)[197:kworker/u16:4][] spin_bug+0x18/0xdc
[ 148.504885]-(5)[197:kworker/u16:4][] do_raw_spin_lock+0xd0/0x274
[ 148.504896]-(5)[197:kworker/u16:4][] _raw_spin_lock+0x40/0x50
[ 148.504910]-(5)[197:kworker/u16:4][] try_to_wake_up+0x204/0x310
[ 148.504922]-(5)[197:kworker/u16:4][] wake_up_process+0x28/0x64
[ 148.504940]-(5)[197:kworker/u16:4][] __up+0x24/0x34
[ 148.504951]-(5)[197:kworker/u16:4][] up+0x50/0x6c
[ 148.504962]-(5)[197:kworker/u16:4][] console_unlock+0x190/0x3bc <= 到这里正要释放console_sem
[ 148.504973]-(5)[197:kworker/u16:4][] vprintk_emit+0x238/0x5b4
[ 148.504984]-(5)[197:kworker/u16:4][] printk+0xb4/0xc0
[ 148.504995]-(5)[197:kworker/u16:4][] printk_deferred+0xf4/0x168
[ 148.505007]-(5)[197:kworker/u16:4][] set_cpus_allowed_ptr+0x118/0x120
[ 148.505019]-(5)[197:kworker/u16:4][] cpuset_change_cpumask+0x14/0x20
[ 148.505034]-(5)[197:kworker/u16:4][] cgroup_scan_tasks+0x154/0x220
[ 148.505046]-(5)[197:kworker/u16:4][] cpuset_propagate_hotplug_workfn+0x13c/0x208
[ 148.505061]-(5)[197:kworker/u16:4][] process_one_work+0x194/0x524
[ 148.505073]-(5)[197:kworker/u16:4][] worker_thread+0x130/0x3b8
[ 148.505085]-(5)[197:kworker/u16:4][] kthread+0xb0/0xbc
可以看到这个调用栈里2次调用了printk,直接导致了spinlock嵌套,那么printk是否有针对这个情况做处理?有的,代码如下:
asmlinkage int vprintk_emit(int facility, int level, const char *dict, size_t dictlen, const char *fmt, va_list args)
{
......
local_irq_save(flags);
this_cpu = smp_processor_id();
/* Ouch, printk recursed into itself! */
if (unlikely(logbuf_cpu == this_cpu)) {
/*
* If a crash is occurring during printk() on this CPU,
* then try to get the crash message out but make sure
* we can't deadlock. Otherwise just return to avoid the
* recursion and return - but flag the recursion so that
* it can be printed at the next appropriate moment:
*/
if (!oops_in_progress && !lockdep_recursing(current)) {
recursion_bug = 1;
goto out_restore_irqs;
}
zap_locks();
}
#ifdef CONFIG_DEBUG_SPINLOCK
if (logbuf_lock.owner!= NULL && logbuf_lock.owner == current) {
/*
* If a crash is occurring during printk() on this CPU,
* then try to get the crash message out but make sure
* we can't deadlock. Otherwise just return to avoid the
* recursion and return - but flag the recursion so that
* it can be printed at the next appropriate moment:
*/
if (!oops_in_progress && !lockdep_recursing(current)) {
recursion_bug = 1;
goto out_restore_irqs;
}
zap_locks();
}
#endif
lockdep_off();
raw_spin_lock(&logbuf_lock);
logbuf_cpu = this_cpu;
......
}
上面的代码注释已经写的很清除了,printk已经考虑到存在spinlock嵌套的情况(不可避免),因此做了规避处理,直接调用zap_locks()函数,这个函数如下:
static void zap_locks(void)
{
static unsigned long oops_timestamp;
if (time_after_eq(jiffies, oops_timestamp) && !time_after(jiffies, oops_timestamp + 30 * HZ))
return;
oops_timestamp = jiffies;
debug_locks_off();
/* If a crash is occurring, make sure we can't deadlock */
raw_spin_lock_init(&logbuf_lock);
/* And make sure that we print immediately */
sema_init(&console_sem, 1);
}
看到没有,直接重新初始化logbuf_lock和console_sem了,这不可避免的会出现一些race condition的情况,比如log中:
lock: console_sem+0x0/0x50, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: -1 value:0x00000000
owner还是正常的而owner_cpu却是-1了,应该是在打印这个log时,有进程正在调用zap_locks()函数。
讲了这么多,就是想说明不用管logbuf_lock和console_sem,这2个lock不会导致嵌套死锁情况(有自解锁能力,就是zap_locks)。所以问题肯定是出在0xffffffc0bb140dc0地址处的spinlock,我们查看这个spinlock警告信息:
[ 148.506095]-(5)[197:kworker/u16:4] lock: 0xffffffc0bb140dc0, .magic: dead4ead, .owner: kworker/u16:4/197, .owner_cpu: 5 value:0x00000001
[ 148.506105]-(5)[197:kworker/u16:4]CPU: 5 PID: 197 Comm: kworker/u16:4 Tainted: G W 3.10.72+ #4
[ 148.506114]Workqueue: cpuset_hotplug cpuset_propagate_hotplug_workfn
[ 148.506124]-(5)[197:kworker/u16:4]Call trace:
[ 148.506136]-(5)[197:kworker/u16:4][] dump_backtrace+0x0/0x16c
[ 148.506147]-(5)[197:kworker/u16:4][] show_stack+0x10/0x1c
[ 148.506159]-(5)[197:kworker/u16:4][] dump_stack+0x1c/0x28
[ 148.506170]-(5)[197:kworker/u16:4][] spin_dump+0x6c/0x8c
[ 148.506182]-(5)[197:kworker/u16:4][] spin_bug+0x18/0xdc
[ 148.506194]-(5)[197:kworker/u16:4][] do_raw_spin_lock+0xd0/0x274
[ 148.506205]-(5)[197:kworker/u16:4][] _raw_spin_lock+0x40/0x50
[ 148.506216]-(5)[197:kworker/u16:4][] try_to_wake_up+0x204/0x310
[ 148.506228]-(5)[197:kworker/u16:4][] wake_up_process+0x28/0x64
[ 148.506238]-(5)[197:kworker/u16:4][] __up+0x24/0x34
[ 148.506249]-(5)[197:kworker/u16:4][] up+0x50/0x6c
[ 148.506260]-(5)[197:kworker/u16:4][] console_unlock+0x190/0x3bc
[ 148.506271]-(5)[197:kworker/u16:4][] vprintk_emit+0x238/0x5b4
[ 148.506281]-(5)[197:kworker/u16:4][] printk+0xb4/0xc0
[ 148.506292]-(5)[197:kworker/u16:4][] printk_deferred+0xf4/0x168
[ 148.506304]-(5)[197:kworker/u16:4][] set_cpus_allowed_ptr+0x118/0x120
[ 148.506315]-(5)[197:kworker/u16:4][] cpuset_change_cpumask+0x14/0x20
[ 148.506326]-(5)[197:kworker/u16:4][] cgroup_scan_tasks+0x154/0x220
[ 148.506337]-(5)[197:kworker/u16:4][] cpuset_propagate_hotplug_workfn+0x13c/0x208
[ 148.506349]-(5)[197:kworker/u16:4][] process_one_work+0x194/0x524
[ 148.506361]-(5)[197:kworker/u16:4][] worker_thread+0x130/0x3b8
[ 148.506372]-(5)[197:kworker/u16:4][] kthread+0xb0/0xbc
这个锁也存在嵌套情况,那么就需要好好检查调用栈了。先看看这把锁是什么,看到try_to_wake_up()函数代码:
static int try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
......
if (p->on_rq && ttwu_remote(p, wake_flags))
goto stat;
}
static int ttwu_remote(struct task_struct *p, int wake_flags)
{
struct rq *rq;
int ret = 0;
rq = __task_rq_lock(p); /* 卡在这里,锁是rq->lock */
if (p->on_rq) {
ttwu_do_wakeup(rq, p, wake_flags);
ret = 1;
}
__task_rq_unlock(rq);
return ret;
}
因此只要检查调用栈哪个地方有去那rq_lock就好了。一一检查调用栈函数,终于发现在set_cpus_allowed_ptr()函数里发现拿了rq->lock这把锁:
int set_cpus_allowed_ptr(struct task_struct *p, const struct cpumask *new_mask)
{
unsigned long flags;
struct rq *rq;
unsigned int dest_cpu;
int ret = 0;
rq = task_rq_lock(p, &flags); /* 这里把rq->lock锁拿走了!!! */
if (cpumask_equal(&p->cpus_allowed, new_mask))
goto out;
if (!cpumask_intersects(new_mask, cpu_active_mask)) {
ret = -EINVAL;
printk_deferred("SCHED: intersects new_mask: %lu, cpu_active_mask: %lu\n", new_mask->bits[0], cpu_active_mask->bits[0]); /* 这里最后调用到ttwu_remote()再去拿rq->lock,导致了spinlock嵌套死锁!!! */
goto out;
}
......
}
问题原因已浮现出来,就是这里导致了spinlock嵌套死锁。
解决方法
删除printk_deferred()这行代码就可以,也要注意拿到rq->lock后不能再调用printk了,很可能引起嵌套死锁。
结语
这题需要忽略printk自身2个lock的嵌套异常,需要熟悉printk机制才行。
如果这题是在user、userdebug版本复现,则无法快速定位问题,因为user、userdebug版本没有打开spinlock debug功能,如果后面再次遇到spinlock死锁问题,请切换到eng版本复现解决问题。
22 HWT-两把不同的spinlock造成死锁
基本信息
问题: aee_dumpstate service cause watchdog happen.
版本:alps-mp-n0.mp3
平台:MT6757C
分析过程
抓取mtklog,里面包含db,用E-Consulter分析,生成的报告如下:
== 异常报告v1.5(仅供参考) ==
报告解读: MediaTek On-Line> Quick Start> E-Consulter之NE/KE分析报告解读> KE分析报告
详细描述: 看门狗复位, 其中CPU0,1,4,5,6,7没有喂狗, 请检查对应调用栈是否存在死锁或长时间关中断
参考信息: MediaTek On-Line> Quick Start> 深入分析看门狗框架
平台 : MT6757
版本 : alps-mp-n0.mp7/userdebug build
异常时间: 49923.584455秒, Sun Dec 4 01:41:54 CST 2016
== CPU信息 ==
无喂狗CPU信息:
CPU0: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE3EF00) + 60 <kernel/locking/spinlock.c:151>
...... 0x0000000000000080()
== 栈结束 ==
CPU1: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock_flags() + 36 <include/linux/spinlock.h:157>
vmlinux __raw_spin_lock_irqsave() + 52 <include/linux/spinlock_api_smp.h:121>
vmlinux _raw_spin_lock_irqsave(lock=0xFFFFFFC07DE98700) + 68 <kernel/locking/spinlock.c:159>
...... 0x0000000000000003()
...... ......
vmlinux rb_time_stamp() + 4 <kernel/trace/ring_buffer.c:699>
vmlinux rb_reserve_next_event(cpu_buffer=0xFFFFFFC07420FC00) + 148 <kernel/trace/ring_buffer.c:2809>
vmlinux ring_buffer_lock_reserve() + 144 <kernel/trace/ring_buffer.c:2884>
vmlinux 0xFFFFFFC001569390()
...... ......
vmlinux event_trigger_unlock_commit() + 136 <include/linux/trace_events.h:517>
vmlinux trace_event_buffer_commit(fbuffer=0xFFFFFFC005063C20) + 180 <kernel/trace/trace_events.c:298>
vmlinux trace_event_raw_event_sched_switch(preempt=false, prev=0xFFFFFFC005063C20, next=0xFFFFFFC06BDF9000) + 224 <include/trace/events/sched.h:275>
vmlinux trace_sched_switch() + 640 <include/trace/events/sched.h:275>
vmlinux __schedule(preempt=false) + 996 <kernel/sched/core.c:3280>
vmlinux schedule() + 100 <kernel/sched/core.c:3312>
vmlinux schedule_timeout(timeout=25) + 300 <kernel/time/timer.c:1541>
vmlinux kswapd_try_to_sleep() + 824 <mm/vmscan.c:3546>
vmlinux kswapd(p=contig_page_data) + 912 <mm/vmscan.c:3665>
vmlinux kthread(_create=0xFFFFFFC0777FC180) + 236 <kernel/kthread.c:209>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:690>
== 栈结束 ==
CPU4: 进程名: aee_dumpstate, 进程标识符(pid): 17405, 中断: 关
本地调用栈:
vmlinux cpu_relax() <arch/arm64/include/asm/processor.h:149>
vmlinux try_to_wake_up(p=0xFFFFFFC077672000, wake_flags=0) + 140 <kernel/sched/core.c:1996>
vmlinux default_wake_function(curr=0xFFFFFFC005063E08) + 12 <kernel/sched/core.c:3451>
vmlinux autoremove_wake_function(mode=1, sync=0, key=0) + 20 <kernel/sched/wait.c:293>
vmlinux __wake_up_common(q=contig_page_data + 6632, mode=1, nr_exclusive=1, wake_flags=0, key=0) + 88 <kernel/sched/wait.c:73>
vmlinux __wake_up(q=contig_page_data + 6632, mode=1, key=0) + 56 <kernel/sched/wait.c:95>
vmlinux wakeup_kswapd(zone=contig_page_data, order=4) + 160 <mm/vmscan.c:3721>
vmlinux wake_all_kswapds() + 1232 <mm/page_alloc.c:2993>
vmlinux __alloc_pages_slowpath() + 1340 <mm/page_alloc.c:3096>
vmlinux __alloc_pages_nodemask(gfp_mask=34078752, order=4, zonelist=contig_page_data + 6528, nodemask=0) + 2220 <mm/page_alloc.c:3360>
vmlinux __alloc_pages() + 16 <include/linux/gfp.h:437>
vmlinux __alloc_pages_node() + 16 <include/linux/gfp.h:450>
vmlinux alloc_pages_node() + 16 <include/linux/gfp.h:464>
vmlinux __get_free_pages() + 20 <mm/page_alloc.c:3409>
vmlinux alloc_loc_track(t=0xFFFFFFC03BD73D98, max=624) + 76 <mm/slub.c:4327>
vmlinux mtk_memcfg_add_location() + 1008 <mm/slub.c:5763>
vmlinux mtk_memcfg_process_slab(t=0xFFFFFFC03BD73D98, s=0xFFFFFFC07DE3C180, page=0xFFFFFFBDC1D65240, map=0xFFFFFFC003110900) + 1268 <mm/slub.c:5798>
vmlinux mtk_memcfg_list_locations() + 692 <mm/slub.c:5831>
vmlinux mtk_memcfg_slabtrace_show(m=0xFFFFFFC057537000) + 764 <mm/slub.c:5870>
vmlinux seq_read(file=0xFFFFFFC059607E00, buf=0x00000000F4E7E698, size=4096, ppos=0xFFFFFFC03BD73EC8) + 424 <fs/seq_file.c:243>
vmlinux proc_reg_read(file=0xFFFFFFC059607E00, buf=0x00000000F4E7E698, count=4096, ppos=0xFFFFFFC03BD73EC8) + 96 <fs/proc/inode.c:202>
vmlinux __vfs_read() + 28 <fs/read_write.c:432>
vmlinux vfs_read(file=0xFFFFFFC059607E00, buf=0x00000000F4E7E698, count=4096, pos=0xFFFFFFC03BD73ED0) + 132 <fs/read_write.c:454>
vmlinux SYSC_read() + 40 <fs/read_write.c:569>
vmlinux SyS_read() + 64 <fs/read_write.c:562>
vmlinux el0_svc() + 48 <arch/arm64/kernel/entry.S:714>
== 栈结束 ==
CPU5: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE98700) + 60 <kernel/locking/spinlock.c:151>
vmlinux 0xFFFFFFC001645000()
...... ......
vmlinux freezable_schedule() + 24 <include/linux/freezer.h:171>
vmlinux futex_wait_queue_me(hb=0xFFFFFFC005001F80, q=0xFFFFFFC001DFFD40, timeout=0) + 224 <kernel/futex.c:2198>
vmlinux futex_wait(uaddr=0x0000007404D015B0, flags=0, bitset=4294967295) + 228 <kernel/futex.c:2313>
vmlinux do_futex(uaddr=0x0000007404D015B0, op=137, val=0) + 360 <kernel/futex.c:3091>
vmlinux SYSC_futex() + 232 <kernel/futex.c:3151>
vmlinux SyS_futex(uaddr=498296952240, op=137, val=0, utime=0) + 272 <kernel/futex.c:3119>
vmlinux el0_svc() + 44 <arch/arm64/kernel/entry.S:713>
== 栈结束 ==
CPU6: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE3EF00) + 60 <kernel/locking/spinlock.c:151>
vmlinux preempt_count_sub(val=1) + 40 <kernel/sched/core.c:3045>
vmlinux __raw_spin_unlock_irqrestore() + 20 <include/linux/spinlock_api_smp.h:163>
vmlinux _raw_spin_unlock_irqrestore(flags=-274849011056) + 28 <kernel/locking/spinlock.c:191>
vmlinux spin_unlock_irqrestore() + 8 <include/linux/spinlock.h:364>
vmlinux sched_update_nr_heavy_prod(invoker=6, p=event_hash + 688, cpu=2112936896) + 400 <drivers/misc/mediatek/sched/sched_avg.c:681>
vmlinux inc_nr_heavy_running() + 52 <drivers/misc/mediatek/sched/rq_stats.c:401>
...... ......
...... ......
vmlinux slab_free() + 420 <mm/slub.c:2907>
vmlinux kfree(x=0xFFFFFFC001BBBBB0) + 564 <mm/slub.c:3736>
vmlinux binder_free_buf(proc=0xFFFFFFC001BBBBB0, buffer=0xFFFFFFC001BBBBB0) + 540 <drivers/android/binder.c:1799>
vmlinux rb_time_stamp() + 4 <kernel/trace/ring_buffer.c:699>
vmlinux rb_reserve_next_event(cpu_buffer=0xFFFFFFC001BBBBF0) + 148 <kernel/trace/ring_buffer.c:2809>
...... 0x00000000F10A7D1C()
...... ......
vmlinux __do_page_fault() + 244 <arch/arm64/mm/fault.c:271>
vmlinux do_page_fault(addr=-274811919488, esr=8, regs=17) + 496 <arch/arm64/mm/fault.c:342>
vmlinux do_mem_abort() + 56 <arch/arm64/mm/fault.c:554>
vmlinux el0_sync() + 732 <arch/arm64/kernel/entry.S:507>
== 栈结束 ==
CPU7: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock_flags() + 36 <include/linux/spinlock.h:157>
vmlinux __raw_spin_lock_irqsave() + 52 <include/linux/spinlock_api_smp.h:121>
vmlinux _raw_spin_lock_irqsave(lock=0xFFFFFFC07DE98700) + 68 <kernel/locking/spinlock.c:159>
...... 0xFFFFFFC001D27B3C()
...... ......
vmlinux ring_buffer_unlock_commit(buffer=0xFFFFFFC07420F900) + 40 <kernel/trace/ring_buffer.c:2682>
vmlinux rb_end_commit() + 204 <kernel/trace/ring_buffer.c:2487>
vmlinux rb_commit(cpu_buffer=0xFFFFFFC07420F900) + 280 <kernel/trace/ring_buffer.c:2566>
vmlinux ring_buffer_unlock_commit(buffer=0xFFFFFFC07DE3A200) + 40 <kernel/trace/ring_buffer.c:2682>
vmlinux __buffer_unlock_commit() + 64 <kernel/trace/trace.c:1790>
vmlinux trace_buffer_unlock_commit(tr=global_trace, buffer=0xFFFFFFC07DE3A200, event=0xFFFFFFC07311BDA4, pc=3) + 80 <kernel/trace/trace.c:1798>
vmlinux event_trigger_unlock_commit() + 136 <include/linux/trace_events.h:517>
vmlinux trace_event_buffer_commit() + 180 <kernel/trace/trace_events.c:298>
vmlinux 0xFFFFFFC0014FCC18()
...... ......
vmlinux __switch_to(next=0xFFFFFFC0717E0000) + 128 <arch/arm64/kernel/process.c:414>
vmlinux context_switch() + 264 <kernel/sched/core.c:2734>
vmlinux __schedule(preempt=true) + 656 <kernel/sched/core.c:3281>
vmlinux preempt_schedule_common() + 40 <kernel/sched/core.c:3353>
vmlinux preempt_schedule() + 24 <kernel/sched/core.c:3378>
vmlinux preempt_schedule() + 32 <kernel/sched/core.c:3379>
vmlinux __raw_spin_unlock_irqrestore() + 56 <include/linux/spinlock_api_smp.h:163>
vmlinux _raw_spin_unlock_irqrestore(lock=0xFFFFFFC0552666D4, flags=-274847335032) + 64 <kernel/locking/spinlock.c:191>
vmlinux try_to_wake_up(p=0xFFFFFFC055266000, state=3, wake_flags=0) + 540 <kernel/sched/core.c:2025>
vmlinux wake_up_process() + 16 <kernel/sched/core.c:2090>
vmlinux wake_up_q(head=0xFFFFFFC001D27D88) + 84 <kernel/sched/core.c:575>
vmlinux futex_wake(uaddr=0x00000000E82E43C8, flags=1, nr_wake=1, bitset=4294967295) + 324 <kernel/futex.c:1364>
vmlinux do_futex(uaddr=0x00000000E82E43C8, op=1, val3=0) + 304 <kernel/futex.c:3095>
vmlinux C_SYSC_futex() + 84 <kernel/futex_compat.c:200>
vmlinux compat_SyS_futex(uaddr=3895346120) + 120 <kernel/futex_compat.c:174>
vmlinux el0_svc() + 48 <arch/arm64/kernel/entry.S:714>
== 栈结束 ==
从日志信息看到栈的还原有些问题,不太完整,但是大致信息还在。CPU0,CPU1,CPU5,CPU6,CPU7都在等spin lock, 大致可以估计是spin lock死锁造成的HWT,我们再看下都在等哪些spin lock
CPU0: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE3EF00)
CPU1: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock_flags() + 36 <include/linux/spinlock.h:157>
vmlinux __raw_spin_lock_irqsave() + 52 <include/linux/spinlock_api_smp.h:121>
vmlinux _raw_spin_lock_irqsave(lock=0xFFFFFFC07DE98700)
CPU5: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE98700)
CPU6: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE3EF00)
CPU7: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock_flags() + 36 <include/linux/spinlock.h:157>
vmlinux __raw_spin_lock_irqsave() + 52 <include/linux/spinlock_api_smp.h:121>
vmlinux _raw_spin_lock_irqsave(lock=0xFFFFFFC07DE98700)
从上面看出主要在等两把锁lock=0xFFFFFFC07DE98700和lock=0xFFFFFFC07DE3EF00,虽然backtrace还原的有些问题,但是可是可以推导出0xFFFFFFC07DE98700这把是CPU0 (struct rq) runqueues 的(raw_spinlock_t)lock,而0xFFFFFFC07DE3EF00这把是struct kmem_cache_node 的lock,是slub分配时候的一把锁。由于调用栈还原不完整,没办法知道这两把锁已经被哪些CPU和进程拿着。就让客户把spin lock的debug宏打开,复现再再抓取log
CONFIG_DEBUG_SPINLOCK=y
CONFIG_DEBUG_LOCK_ALLOC=y
CONFIG_MTK_LOCK_DEBUG=y
CONFIG_MTK_SCHED_MONITOR=y
CONFIG_PREEMPT_MONITOR=y
客户测试一周后反馈说,打开了这些宏没办法复现了,就只能让他们重新用原来的软件再抓取log,希望在log中有些完整的调用栈,几天后客户复现了现象。
== 异常报告v1.5(仅供参考) ==
报告解读: MediaTek On-Line> Quick Start> E-Consulter之NE/KE分析报告解读> KE分析报告
详细描述: 看门狗复位, 其中CPU4,5,6,7没有喂狗, 请检查对应调用栈是否存在死锁或长时间关中断
参考信息: MediaTek On-Line> Quick Start> 深入分析看门狗框架
平台 : MT6757
版本 : alps-mp-n0.mp103.tc9sp/userdebug build
异常时间: 95784.544113秒, Fri Dec 9 00:50:52 CST 2016
== CPU信息 ==
无喂狗CPU信息:
CPU4: 进程名: logd.writer, 进程标识符(pid): 345, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE3EF00) + 60 <kernel/locking/spinlock.c:151>
vmlinux spin_lock() + 4 <include/linux/spinlock.h:304>
vmlinux get_partial_node() + 40 <mm/slub.c:1780>
vmlinux get_partial() + 40 <mm/slub.c:1887>
vmlinux new_slab_objects() + 40 <mm/slub.c:2367>
vmlinux ___slab_alloc(s=0xFFFFFFC07DE3C180, gfpflags=37748928, addr=-274875793128, c=0xFFFFFFC07DEE7BC0) + 204 <mm/slub.c:2529>
vmlinux __slab_alloc(s=0xFFFFFFC07DE3C180, gfpflags=37748928, addr=-274875793128) + 72 <mm/slub.c:2571>
vmlinux slab_alloc_node() + 320 <mm/slub.c:2634>
vmlinux slab_alloc() + 320 <mm/slub.c:2676>
vmlinux kmem_cache_alloc_trace(s=0xFFFFFFC07DE3C180, gfpflags=37748928, size=32) + 332 <mm/slub.c:2693>
vmlinux kmalloc() + 56 <include/linux/slab.h:458>
vmlinux single_open(file=0xFFFFFFC054A78540, show=comm_show(), data=0xFFFFFFC023243B78) + 60 <fs/seq_file.c:572>
vmlinux comm_open(inode=0xFFFFFFC023243B78, filp=0xFFFFFFC054A78540) + 24 <fs/proc/base.c:1534>
vmlinux do_dentry_open(f=0xFFFFFFC054A78540, inode=0xFFFFFFC023243B78, open=0) + 508 <fs/open.c:736>
vmlinux vfs_open(path=0xFFFFFFC066C73D90, file=0xFFFFFFC054A78540) + 76 <fs/open.c:849>
vmlinux do_last() + 1144 <fs/namei.c:3183>
vmlinux path_openat(nd=0xFFFFFFC066C73D90, op=0xFFFFFFC066C73EA8, flags=65) + 1240 <fs/namei.c:3319>
vmlinux do_filp_open(dfd=-100, pathname=0xFFFFFFC009B4F000, op=0xFFFFFFC066C73EA8) + 92 <fs/namei.c:3354>
vmlinux do_sys_open(dfd=-100, flags=131072) + 320 <fs/open.c:1019>
vmlinux SYSC_openat() + 8 <fs/open.c:1046>
vmlinux SyS_openat() + 12 <fs/open.c:1040>
vmlinux el0_svc() + 44 <arch/arm64/kernel/entry.S:713>
== 栈结束 ==
CPU5: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=1) + 60 <kernel/locking/spinlock.c:151>
vmlinux __raw_spin_unlock_irqrestore() + 20 <include/linux/spinlock_api_smp.h:163>
vmlinux _raw_spin_unlock_irqrestore() + 28 <kernel/locking/spinlock.c:191>
vmlinux preempt_count_sub() + 56 <kernel/sched/core.c:3067>
vmlinux preempt_count_sub(val=1) + 40 <kernel/sched/core.c:3045>
vmlinux __raw_spin_unlock_irqrestore() + 20 <include/linux/spinlock_api_smp.h:163>
vmlinux _raw_spin_unlock_irqrestore(lock=0xFFFFFFC07767D6D4, flags=4) + 28 <kernel/locking/spinlock.c:191>
vmlinux spin_unlock_irqrestore() + 8 <include/linux/spinlock.h:364>
vmlinux reserve_highatomic_pageblock() + 84 <mm/page_alloc.c:1744>
vmlinux get_page_from_freelist(gfp_mask=34078752, order=2, alloc_flags=48, ac=0xFFFFFFC001D83BA8) + 2692 <mm/page_alloc.c:2676>
vmlinux __alloc_pages_slowpath() + 328 <mm/page_alloc.c:3117>
vmlinux __alloc_pages_nodemask(gfp_mask=34078752, order=2) + 1208 <mm/page_alloc.c:3360>
...... 0x0000000000000100()
...... ......
vmlinux seq_vprintf() + 100 <fs/seq_file.c:406>
vmlinux seq_printf() + 152 <fs/seq_file.c:421>
vmlinux mtk_memcfg_list_locations() + 432 <mm/slub.c:5838>
vmlinux mtk_memcfg_slabtrace_show() + 504 <mm/slub.c:5870>
vmlinux seq_read(file=0xFFFFFFC062FD6540, buf=0x00000000F563E698, size=4096, ppos=0xFFFFFFC001D83EC8) + 424 <fs/seq_file.c:243>
vmlinux proc_reg_read(file=0xFFFFFFC062FD6540, buf=0x00000000F563E698, count=4096, ppos=0xFFFFFFC001D83EC8) + 96 <fs/proc/inode.c:202>
vmlinux __vfs_read() + 28 <fs/read_write.c:432>
vmlinux vfs_read(file=0xFFFFFFC062FD6540, buf=0x00000000F563E698, count=4096, pos=0xFFFFFFC001D83ED0) + 132 <fs/read_write.c:454>
vmlinux SYSC_read() + 40 <fs/read_write.c:569>
vmlinux SyS_read() + 64 <fs/read_write.c:562>
vmlinux el0_svc() + 48 <arch/arm64/kernel/entry.S:714>
== 栈结束 ==
CPU6: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE3EF00) + 60 <kernel/locking/spinlock.c:151>
...... 0x00000000FFFFFFFF()
== 栈结束 ==
CPU7: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock() + 36 <include/linux/spinlock.h:150>
vmlinux __raw_spin_lock() + 44 <include/linux/spinlock_api_smp.h:145>
vmlinux _raw_spin_lock(lock=0xFFFFFFC07DE3EF00) + 60 <kernel/locking/spinlock.c:151>
...... 0xFFFFFFC001F97BFC()
...... ......
vmlinux ring_buffer_unlock_commit() + 40 <kernel/trace/ring_buffer.c:2682>
...... 0xFFFFFFC07420F988()
...... ......
vmlinux trace_event_raw_event_sched_switch(prev=0xFFFFFFC001F97C00, next=0xFFFFFFC06BDF4000) + 224 <include/trace/events/sched.h:275>
vmlinux trace_sched_switch() + 640 <include/trace/events/sched.h:275>
vmlinux __schedule(preempt=false) + 996 <kernel/sched/core.c:3280>
vmlinux schedule() + 100 <kernel/sched/core.c:3312>
vmlinux pipe_wait(pipe=0xFFFFFFC059CB9C00) + 96 <fs/pipe.c:119>
vmlinux pipe_read(iocb=0xFFFFFFC001F97DF0, to=0xFFFFFFC001F97E18) + 500 <fs/pipe.c:324>
vmlinux new_sync_read(filp=0xFFFFFFC05A830700, buf=0x000000747FC24800, len=1024, ppos=0xFFFFFFC001F97EC8) + 132 <fs/read_write.c:422>
vmlinux __vfs_read() + 176 <fs/read_write.c:434>
vmlinux vfs_read(file=0xFFFFFFC05A830700, buf=0x000000747FC24800, count=1024, pos=0xFFFFFFC001F97ED0) + 280 <fs/read_write.c:454>
vmlinux SYSC_read() + 40 <fs/read_write.c:569>
vmlinux SyS_read() + 64 <fs/read_write.c:562>
vmlinux el0_svc() + 44 <arch/arm64/kernel/entry.S:713>
== 栈结束 ==
从栈的还原来看,还是不够完整,但是客户提供了一个重要信息mtk_memcfg_list_locations会用到struct kmem_cache_node 的lock,我们查看第一份db中的CPU4同样也有相同的backtrace
CPU4: 进程名: aee_dumpstate, 进程标识符(pid): 17405, 中断: 关
本地调用栈:
vmlinux cpu_relax() <arch/arm64/include/asm/processor.h:149>
vmlinux try_to_wake_up(p=0xFFFFFFC077672000, wake_flags=0) + 140 <kernel/sched/core.c:1996>
vmlinux default_wake_function(curr=0xFFFFFFC005063E08) + 12 <kernel/sched/core.c:3451>
vmlinux autoremove_wake_function(mode=1, sync=0, key=0) + 20 <kernel/sched/wait.c:293>
vmlinux __wake_up_common(q=contig_page_data + 6632, mode=1, nr_exclusive=1, wake_flags=0, key=0) + 88 <kernel/sched/wait.c:73>
vmlinux __wake_up(q=contig_page_data + 6632, mode=1, key=0) + 56 <kernel/sched/wait.c:95>
vmlinux wakeup_kswapd(zone=contig_page_data, order=4) + 160 <mm/vmscan.c:3721>
vmlinux wake_all_kswapds() + 1232 <mm/page_alloc.c:2993>
vmlinux __alloc_pages_slowpath() + 1340 <mm/page_alloc.c:3096>
vmlinux __alloc_pages_nodemask(gfp_mask=34078752, order=4, zonelist=contig_page_data + 6528, nodemask=0) + 2220 <mm/page_alloc.c:3360>
vmlinux __alloc_pages() + 16 <include/linux/gfp.h:437>
vmlinux __alloc_pages_node() + 16 <include/linux/gfp.h:450>
vmlinux alloc_pages_node() + 16 <include/linux/gfp.h:464>
vmlinux __get_free_pages() + 20 <mm/page_alloc.c:3409>
vmlinux alloc_loc_track(t=0xFFFFFFC03BD73D98, max=624) + 76 <mm/slub.c:4327>
vmlinux mtk_memcfg_add_location() + 1008 <mm/slub.c:5763>
vmlinux mtk_memcfg_process_slab(t=0xFFFFFFC03BD73D98, s=0xFFFFFFC07DE3C180, page=0xFFFFFFBDC1D65240, map=0xFFFFFFC003110900) + 1268 <mm/slub.c:5798>
vmlinux mtk_memcfg_list_locations() + 692 <mm/slub.c:5831>
vmlinux mtk_memcfg_slabtrace_show(m=0xFFFFFFC057537000) + 764 <mm/slub.c:5870>
vmlinux seq_read(file=0xFFFFFFC059607E00, buf=0x00000000F4E7E698, size=4096, ppos=0xFFFFFFC03BD73EC8) + 424 <fs/seq_file.c:243>
vmlinux proc_reg_read(file=0xFFFFFFC059607E00, buf=0x00000000F4E7E698, count=4096, ppos=0xFFFFFFC03BD73EC8) + 96 <fs/proc/inode.c:202>
vmlinux __vfs_read() + 28 <fs/read_write.c:432>
vmlinux vfs_read(file=0xFFFFFFC059607E00, buf=0x00000000F4E7E698, count=4096, pos=0xFFFFFFC03BD73ED0) + 132 <fs/read_write.c:454>
vmlinux SYSC_read() + 40 <fs/read_write.c:569>
vmlinux SyS_read() + 64 <fs/read_write.c:562>
vmlinux el0_svc() + 48 <arch/arm64/kernel/entry.S:714>
== 栈结束 ==
感觉这个死锁跟mtk_memcfg_list_locations()有些关联,由于第一份db的cpu4 backtrace是完整的,我们分析CPU4是在做什么。
static int mtk_memcfg_list_locations(struct kmem_cache *s, struct seq_file *m,
enum track_item alloc)
{
unsigned long i, j;
struct loc_track t = { 0, 0, NULL };
int node;
unsigned long *map = kmalloc(BITS_TO_LONGS(oo_objects(s->max)) *
sizeof(unsigned long), GFP_KERNEL);
struct kmem_cache_node *n;
if (!map || !alloc_loc_track(&t, PAGE_SIZE / sizeof(struct location),
__GFP_NOMEMALLOC|GFP_NOWAIT|__GFP_NO_KSWAPD)) {
kfree(map);
return seq_puts(m, "Out of memory\n");
}
/* Push back cpu slabs */
flush_all(s);
for_each_kmem_cache_node(s, node, n) {
unsigned long flags;
struct page *page;
if (!atomic_long_read(&n->nr_slabs))
continue;
spin_lock_irqsave(&n->list_lock, flags);
list_for_each_entry(page, &n->partial, lru)
mtk_memcfg_process_slab(&t, s, page, alloc, map);
list_for_each_entry(page, &n->full, lru)
mtk_memcfg_process_slab(&t, s, page, alloc, map);
spin_unlock_irqrestore(&n->list_lock, flags);
}
vmlinux cpu_relax() <arch/arm64/include/asm/processor.h:149>
vmlinux try_to_wake_up(p=0xFFFFFFC077672000, wake_flags=0) + 140 <kernel/sched/core.c:1996>
vmlinux default_wake_function(curr=0xFFFFFFC005063E08) + 12 <kernel/sched/core.c:3451>
vmlinux autoremove_wake_function(mode=1, sync=0, key=0) + 20 <kernel/sched/wait.c:293>
vmlinux __wake_up_common(q=contig_page_data + 6632, mode=1, nr_exclusive=1, wake_flags=0, key=0) + 88 <kernel/sched/wait.c:73>
vmlinux __wake_up(q=contig_page_data + 6632, mode=1, key=0) + 56 <kernel/sched/wait.c:95>
vmlinux wakeup_kswapd(zone=contig_page_data, order=4) + 160 <mm/vmscan.c:3721>
vmlinux wake_all_kswapds() + 1232 <mm/page_alloc.c:2993>
vmlinux __alloc_pages_slowpath() + 1340 <mm/page_alloc.c:3096>
vmlinux __alloc_pages_nodemask(gfp_mask=34078752, order=4, zonelist=contig_page_data + 6528, nodemask=0) + 2220 <mm/page_alloc.c:3360>
vmlinux __alloc_pages() + 16 <include/linux/gfp.h:437>
vmlinux __alloc_pages_node() + 16 <include/linux/gfp.h:450>
vmlinux alloc_pages_node() + 16 <include/linux/gfp.h:464>
vmlinux __get_free_pages() + 20 <mm/page_alloc.c:3409>
从代码和backtrace很明显分析出mtk_memcfg_list_locations拿到kmem_cache_node 的lock后,会去分配内存,而由于系统内存不足,进程调用wake_all_kswapds()来唤醒kswapd0进程来进行内存回收,但是某种原因一直在cpu_relax()里面。我们再看下try_to_wake_up()这个函数的代码.
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
...............
if (p->on_rq && ttwu_remote(p, wake_flags))
goto stat;
#ifdef CONFIG_SMP
/*
* If the owning (remote) cpu is still in the middle of schedule() with
* this task as prev, wait until its done referencing the task.
*/
while (p->on_cpu)
cpu_relax();
/*
* Pairs with the smp_wmb() in finish_lock_switch().
*/
smp_rmb();
...................
上面这段文字很明显,是说被wake up的进程正在被某个CPU schedule出去,再用trace32看下哪个进程正在运行kswapd0进程,可以看出是CPU1进程,从CPU1的backtrace也能看出。

CPU1: 进程名: (null), 进程标识符(pid): 0, 中断: 关
本地调用栈:
vmlinux arch_spin_lock() + 36 <arch/arm64/include/asm/spinlock.h:40>
vmlinux do_raw_spin_lock_flags() + 36 <include/linux/spinlock.h:157>
vmlinux __raw_spin_lock_irqsave() + 52 <include/linux/spinlock_api_smp.h:121>
vmlinux _raw_spin_lock_irqsave(lock=0xFFFFFFC07DE98700) + 68 <kernel/locking/spinlock.c:159>
...... 0x0000000000000003()
...... ......
vmlinux rb_time_stamp() + 4 <kernel/trace/ring_buffer.c:699>
vmlinux rb_reserve_next_event(cpu_buffer=0xFFFFFFC07420FC00) + 148 <kernel/trace/ring_buffer.c:2809>
vmlinux ring_buffer_lock_reserve() + 144 <kernel/trace/ring_buffer.c:2884>
vmlinux 0xFFFFFFC001569390()
...... ......
vmlinux event_trigger_unlock_commit() + 136 <include/linux/trace_events.h:517>
vmlinux trace_event_buffer_commit(fbuffer=0xFFFFFFC005063C20) + 180 <kernel/trace/trace_events.c:298>
vmlinux trace_event_raw_event_sched_switch(preempt=false, prev=0xFFFFFFC005063C20, next=0xFFFFFFC06BDF9000) + 224 <include/trace/events/sched.h:275>
vmlinux trace_sched_switch() + 640 <include/trace/events/sched.h:275>
vmlinux __schedule(preempt=false) + 996 <kernel/sched/core.c:3280>
vmlinux schedule() + 100 <kernel/sched/core.c:3312>
vmlinux schedule_timeout(timeout=25) + 300 <kernel/time/timer.c:1541>
vmlinux kswapd_try_to_sleep() + 824 <mm/vmscan.c:3546>
vmlinux kswapd(p=contig_page_data) + 912 <mm/vmscan.c:3665>
vmlinux kthread(_create=0xFFFFFFC0777FC180) + 236 <kernel/kthread.c:209>
vmlinux ret_from_fork() + 16 <arch/arm64/kernel/entry.S:690>
== 栈结束 ==
而这里面CPU1总在等runqueues的lock,一直等不到,那runqueues lock这把锁肯定是在CPU0或CPU6上,由于backtrace的原因,我们假定runqueues的lock在CPU6上,总结下这两把锁与CPU的关系
CPU 0: accquire rq lock accquire slub lock
CPU 4: accquire slub lock to CPU 1: accquire rq lock
CPU 5: accquire rq lock
CPU 6: accquire rq lock accquire slub lock
CPU 7: accquire rq lock
问题原因已浮现出来,CPU4和CPU6的流程肯定会导致死锁。
root case :mtk_memcfg_list_locations分配内存时,当系统内存不足时会唤醒kswapd0进程。
解决方法
修改get_free_pages()的分配参数,让系统memory不足的时候不去wake up kswapd0 这个进程。
结语
需要理清各个CPU对应spin lock的关系,梳理代码流程就可以明白死锁之间的关系。
23 HW REBOOT-HW故障
问题:安兔兔测试浮点运算时重启
版本:ALPS.JB9.MP.V1.4
平台:MT6592
分析过程
抓取db,解开后查看__exp_main.txt,如下:
| Exception Class: Hardware reboot(abnormal) WDT status: 5 fiq step: 0 CPU 0 irq: enter(220, 299101958401) quit(220, 299101967016) sched: 299098460785, "Thread-347" hotplug: 2, 44 CPU 1 irq: enter(29, 299096433170) quit(29, 299096501554) sched: 298957864093, "Thread-347" hotplug: 14, 0 CPU 2 irq: enter(29, 299096772862) quit(29, 299096827401) sched: 299046766708, "Thread-347" hotplug: 14, 0 CPU 3 irq: enter(29, 299096432401) quit(29, 299096499554) sched: 299076610554, "Thread-347" hotplug: 14, 0 CPU 4 irq: enter(29, 299096436324) quit(29, 299096497247) sched: 299046620939, "Thread-347" hotplug: 14, 0 CPU 5 irq: enter(29, 299096431631) quit(29, 299096502631) sched: 299016621477, "Thread-347" hotplug: 14, 0 CPU 6 irq: enter(29, 299096431554) quit(29, 299096495016) sched: 298986620170, "Thread-347" hotplug: 14, 0 CPU 7 irq: enter(29, 299096437554) quit(29, 299096500093) sched: 298956651554, "Thread-347" hotplug: 14, 0 CORE_0 PC = 0x8( + 0x0), FP = 0x2000, SP = 0x20004000 CORE_1 PC = 0xf8f0ef50( + 0x0), FP = 0x0, SP = 0x800001 CORE_2 PC = 0xd8201000( + 0x0), FP = 0x40000441, SP = 0x800060 CORE_3 PC = 0xe9128b08( + 0x0), FP = 0x1000002, SP = 0x884600c1 CORE_4 PC = 0xd57f3750( + 0x0), FP = 0x80, SP = 0x0 CORE_5 PC = 0x2108808( + 0x0), FP = 0x100021, SP = 0x200001 CORE_6 PC = 0x5a860004( + 0x0), FP = 0x800, SP = 0xb40084 CORE_7 PC = 0x48110200( + 0x0), FP = 0x0, SP = 0x10000 |
wdt status为5且fiq step为0,是纯粹的HW reboot,查看last pc,发现PC/FP/SP都是错乱的,估计当时CPU无法正常工作了,怀疑HW故障。先做基本调查:
|
检查项 |
结果 |
|---|---|
| 复现概率 | 80%左右,user版本复现率高于eng版本 |
| 测量vproc/vmem | vproc有上下跳动 |
| 多份log分析 | 基本一致,都是8 CPU跑飞 |
| 复现机器 | 有的机器不复现,有的机器概率很高 |
| 所有patch是否打上 | 已打上 |
| 是否只有antutu发生问题 | 是 |
| ETT | 没有验证 |
| 关闭DVFS/hot plug | 还是可以复现 |
| PDN | 通过 |
由于ETT没有跑过,因此请跑完ETT在确认问题,发现问题依旧。另外vproc确认也不像是有问题的样子。
另外一条线索,PCB有2版,第1版容易复现,第2版不容易复现,但可惜也没有排查出问题。
HW问题一般和power/clock相关性较大,因此关闭会影响电压的功能模块验证:
|
检查项 |
结果 |
|---|---|
| antutu不测试浮点 | 无复现 |
| antutu测试pass后直接拔电池 | 结果一样 |
| 使用internal buck | 问题不复现 |
| 关闭PTP-OD | 还是复现问题 |
| 只使用4CPU | 还是复现问题 |
使用internal buck测试一个晚上,没有复现,基本上断定是ext buck存在问题(92需要ext buck)。接下来需要HW review ext buck电路。HW review ext buck电路之后,检查到buck电感不符合spec,导致buck输出电流不够。则会引起CPU无法正常工作,PC/SP/FP等寄存器乱跑。
解决方法
需要更换电感物料。
结语
从db/log分析到最后问题找到,中间的道路是崎岖的。我们要尽量抓住任何可能的疑点(尽量发散),然后一一排查,最后找到问题点。而这过程中使用的调试手段,可能各个平台都不一样,但分析思路都差不多。
另外还有一点,HW reboot必须可复现才行,否则无法采取任何调试措施。比如这题如果仅复现1次,是根本无法找到问题点的。
24 相关FAQ
 | Category: |
| ||||||||||||||||||||||||||||||||||||||
| 1Total: 1 pages (8 items) |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









