






目录
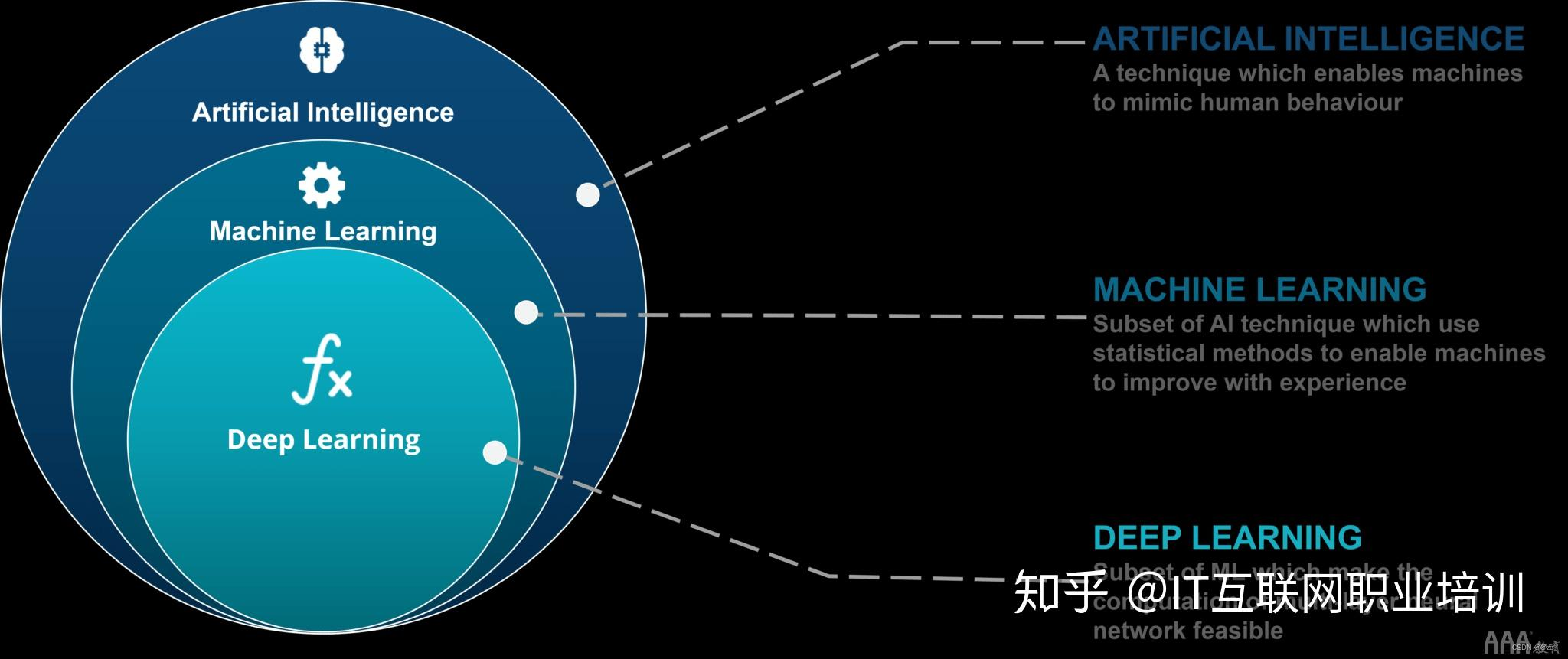
人工智能三大概念:人工智能(AI) 机器学习(ML) 深度学习(DL)
人工智能三大概念:人工智能(AI) 机器学习(ML) 深度学习(DL)
1.人工智能(Artificial Intelligence):概念: 人工智能是一种广泛的概念,指的是使计算机系统能够执行类似于人类智能的任务的技术和方法。这些任务包括但不限于语音识别、图像识别、自然语言处理、决策制定和问题解决等。人工智能的目标是创建能够模拟人类智能的系统,以便能够执行复杂的认知任务。
2. 机器学习(ML)的基本原理
机器学习是人工智能的一个重要分支,它通过让计算机系统从数据中学习模式和规律,从而实现自主学习和智能决策。机器学习的基本原理包括以下几个关键要素:
- 数据:机器学习的基础是大量的数据,包括输入数据和对应的输出(标签)数据。
- 模型:模型是机器学习算法从数据中学到的知识的表示形式,它可以根据输入数据进行预测或分类。
- 算法:机器学习算法是用来训练模型的数学方法,包括监督学习、无监督学习和强化学习等不同类型的算法
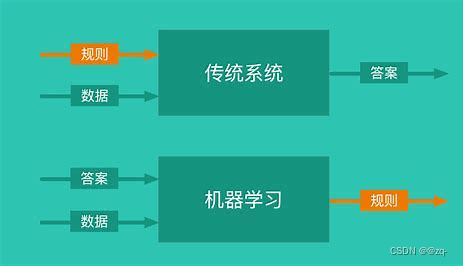
- 机器学习是实现人工智能的一种途径
3. 深度学习(DL)的特点与应用
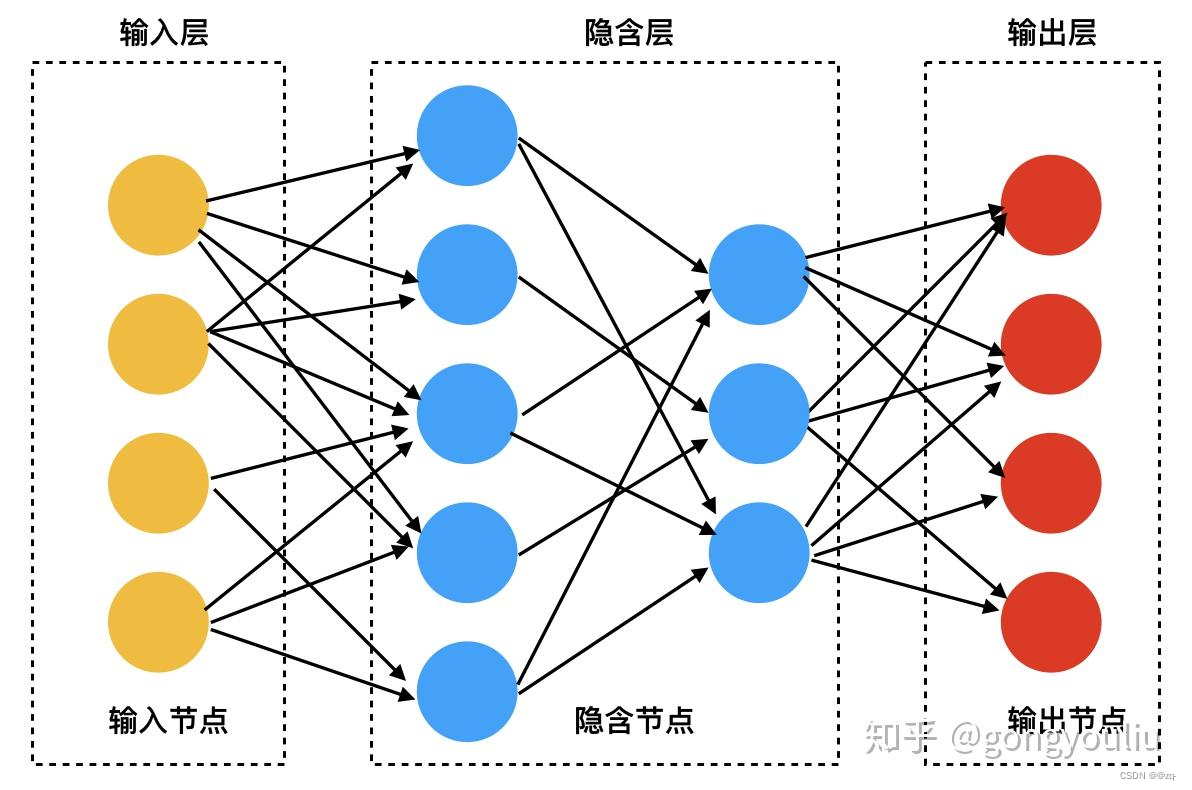
深度学习是机器学习的一个分支,它使用多层神经网络来模拟人类大脑的结构和功能。深度学习的特点包括:
- 多层结构:深度学习模型通常包含多个隐藏层,使其能够学习更复杂的模式和规律。
- 端到端学习:深度学习模型能够直接从原始数据中学习特征表示,而无需手工设计特征。
- 大数据依赖:深度学习模型通常需要大量的数据进行训练,才能达到较好的性能。
深度学习在各个领域都有广泛的应用,包括但不限于:
- 计算机视觉:深度学习在图像识别、目标检测、图像生成等方面取得了巨大的成功,例如人脸识别、自动驾驶等。
- 自然语言处理:深度学习在机器翻译、语言模型、情感分析等方面也取得了重要进展,例如智能助手、智能客服等。
- 医疗健康:深度学习被广泛应用于医学影像分析、疾病诊断、药物研发等领域,提高了医疗诊断的准确性和效率。
- 金融领域:深度学习在信用评分、风险管理、股票预测等方面也有重要应用,为金融机构提供了更好的决策支持。
- 深度学习是机器学习的一种方法
结论
人工智能、机器学习和深度学习是当前科技领域的热点,它们正在推动着人类社会向着智能化和自动化的方向发展。随着技术的不断进步和应用的不断拓展,人工智能将为我们的生活带来更多便利和可能性。
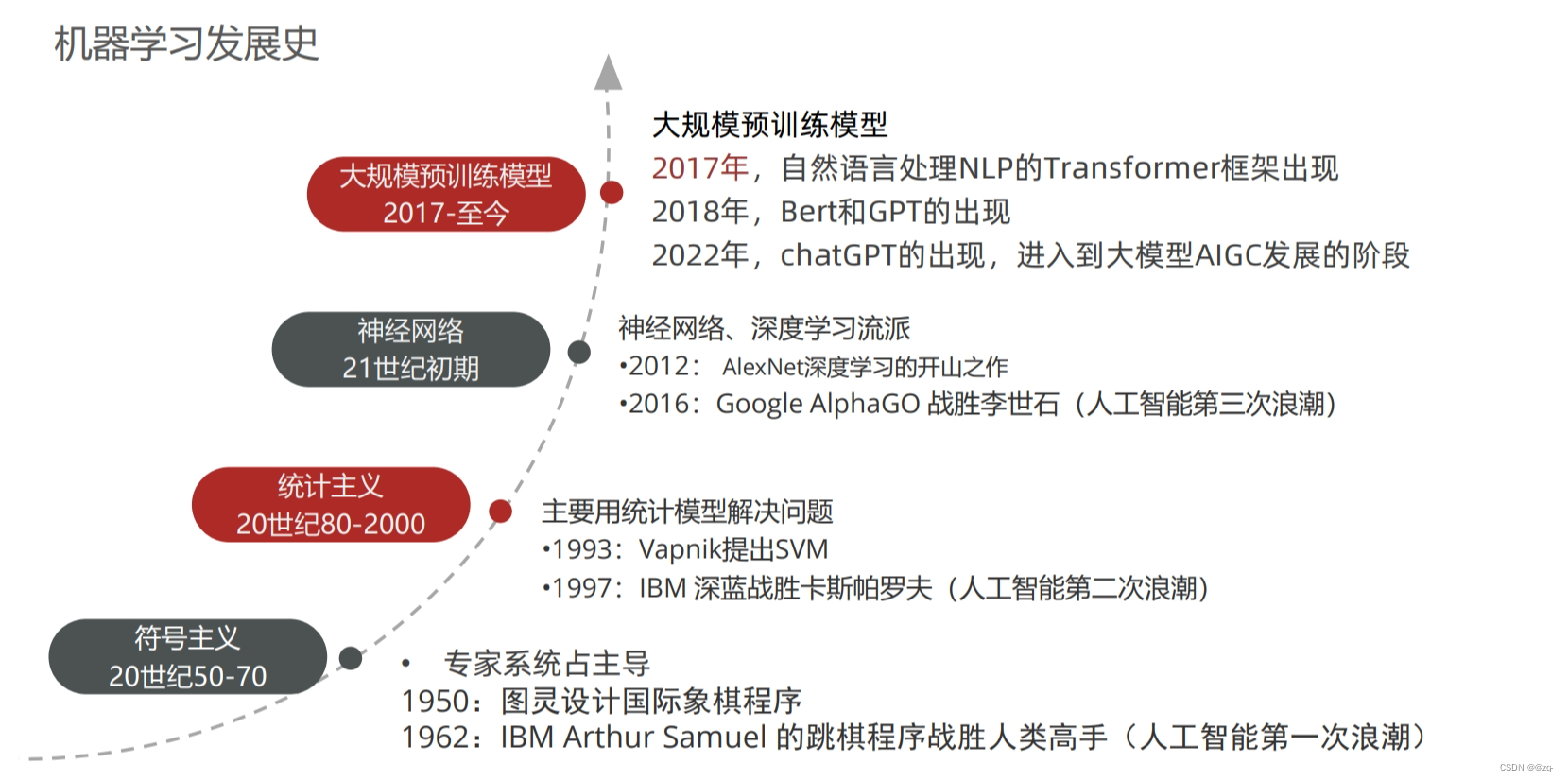
机器学习的应用领域和发展史
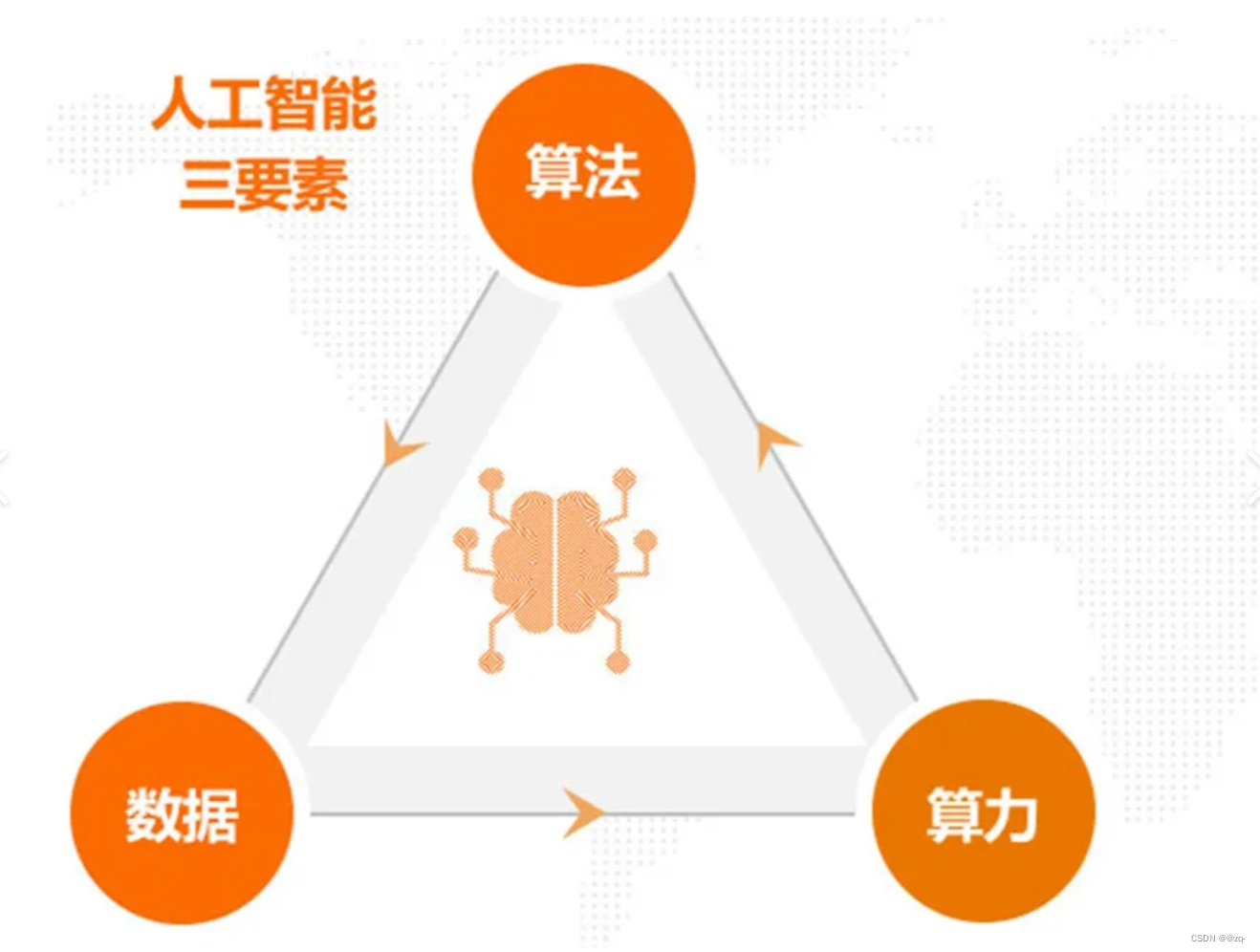
人工智能三要素
- 1.数据 在我们的生活中充满着各种各样的数据,坐地铁会留下进出站的信息,去图书馆借书会留下借书的信息,在学校学习会留下电子成长档案 (包括我们的身高、体重、课程表等信息),以上信息都是数据。 ...
- 2.算法 算法是解决问题、实现目的的方法和过程。
- 3.算力 算力通常表示计算机的计算能力。
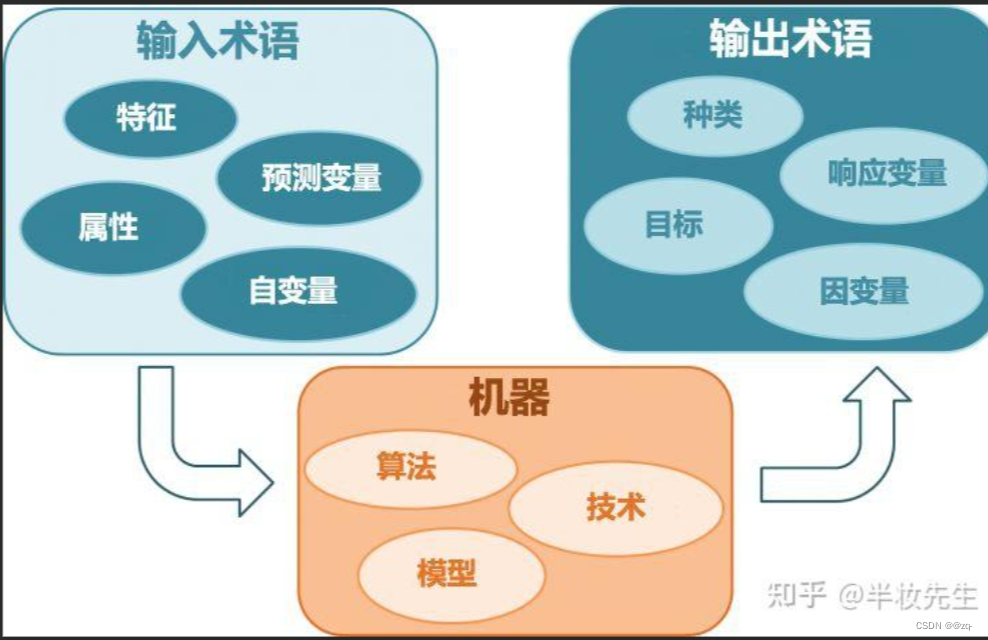
机器学习常用术语
-
数据集(Dataset):用于训练和评估机器学习模型的数据集合。
-
特征(Feature):数据集中的输入变量,用于描述样本的属性或特性。
-
标签(Label):数据集中的输出变量,用于表示样本的类别或目标值。
-
样本(Sample):数据集中的单个数据点,包括特征和对应的标签。
-
训练集(Training Set):用于训练机器学习模型的数据子集。
-
验证集(Validation Set):用于调整模型超参数和评估模型性能的数据子集。
-
测试集(Test Set):用于最终评估模型性能的独立数据子集,模型在训练和验证过程中没有接触过。
-
模型(Model):描述数据间关系的数学或统计表示,用于进行预测或分类任务。
-
算法(Algorithm):用于从数据中学习模型的计算方法或步骤。
-
监督学习(Supervised Learning):通过标注好的数据集进行训练,从而使模型能够预测或分类新的数据。
-
无监督学习(Unsupervised Learning):使用未标注的数据集进行训练,模型尝试发现数据中的模式和结构。
-
半监督学习(Semi-supervised Learning):结合有标签和无标签数据进行训练,通常用于数据集中只有少量标签的情况。
-
强化学习(Reinforcement Learning):通过试错的方式学习最优策略,根据环境的反馈调整行为。
-
超参数(Hyperparameters):影响模型训练过程的参数,需要在训练之前设定,并通过验证集进行调整。
-
损失函数(Loss Function):衡量模型预测结果与真实标签之间差异的函数,用于评估模型性能并指导参数优化。
-
优化算法(Optimization Algorithm):用于调整模型参数以最小化损失函数的算法,例如梯度下降算法。
-
过拟合(Overfitting):模型在训练集上表现良好,但在测试集上表现较差的现象,表示模型过度学习了训练集中的噪声或特定样本。
-
欠拟合(Underfitting):模型未能充分学习数据中的模式和规律,导致在训练集和测试集上都表现不佳的现象。
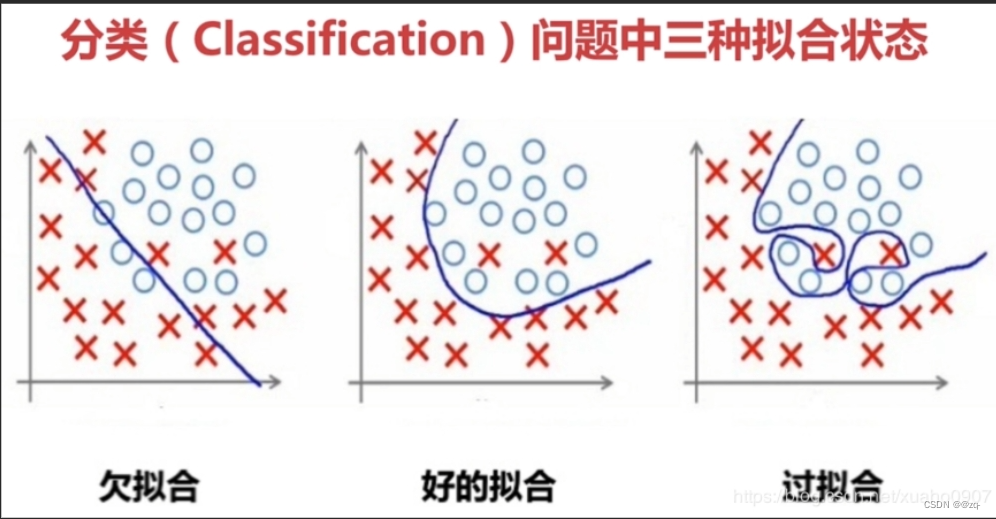
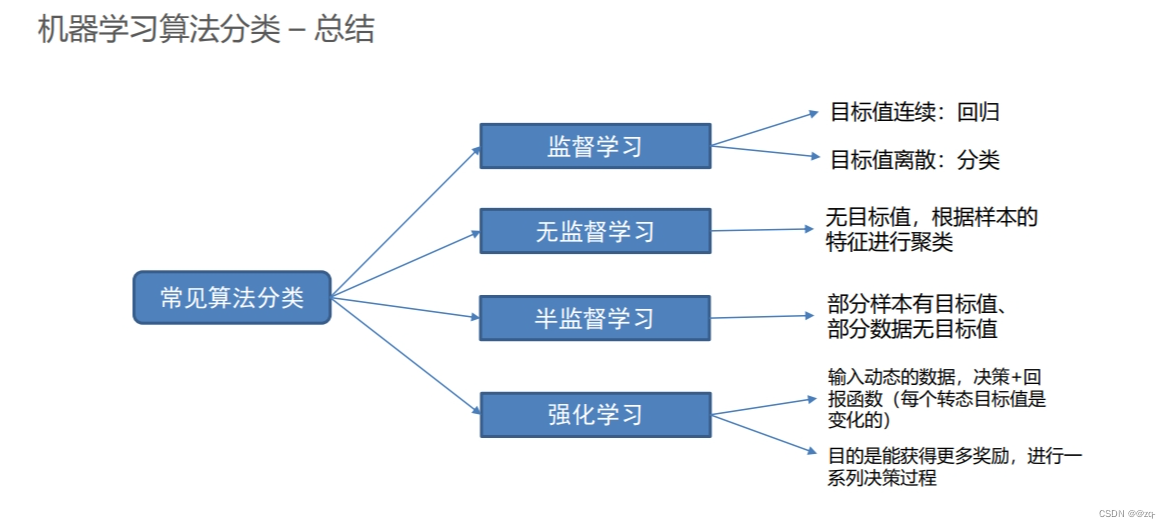
机器学习算法分类
有监督学习
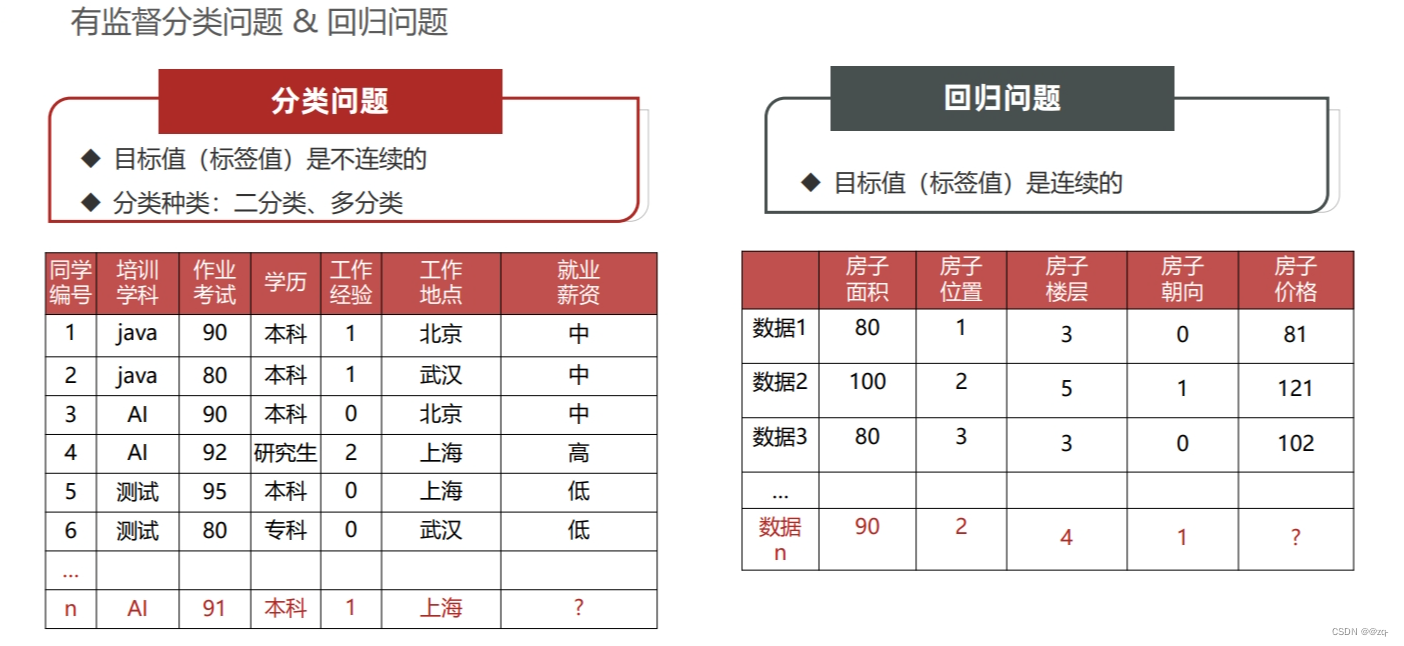
有监督学习是机器学习中一种常见的学习方法,其训练数据包含了输入和对应的输出标签。在有监督学习中,模型通过学习输入和输出之间的关系来进行预测和分类。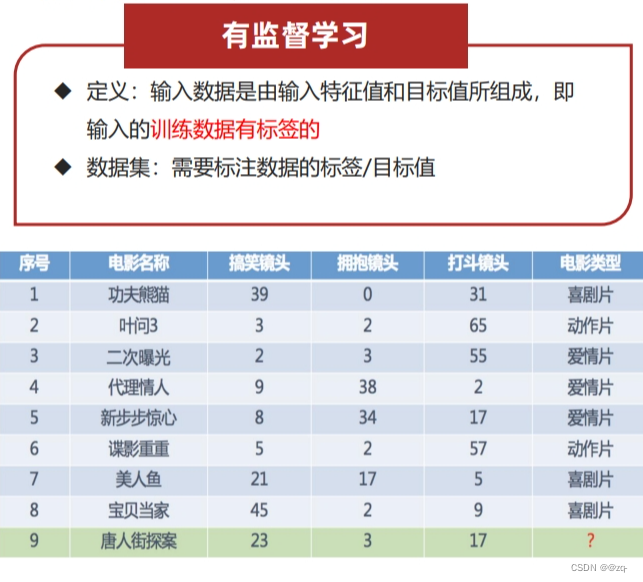
无监督学习
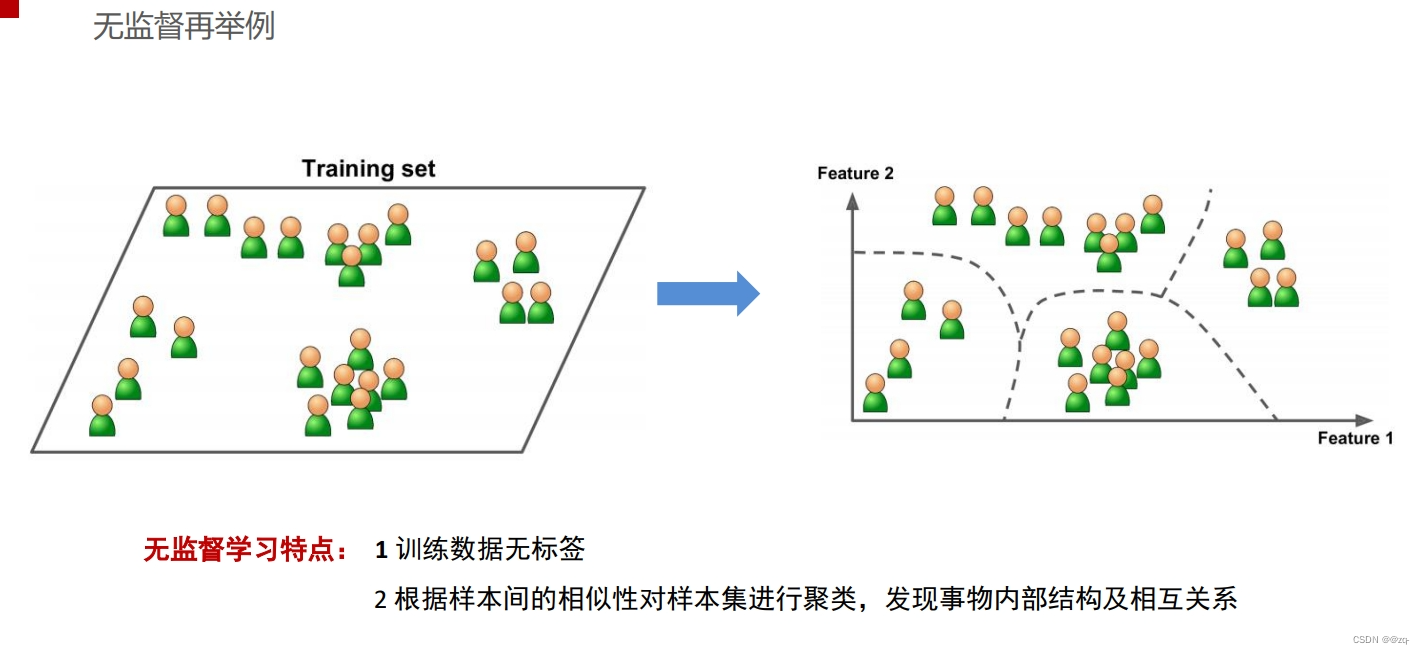
无监督学习是一种机器学习方法,其训练数据没有标签或输出,模型需要自行发现数据中的模式和结构。无监督学习通常用于聚类、降维和异常检测等任务。
半监督学习
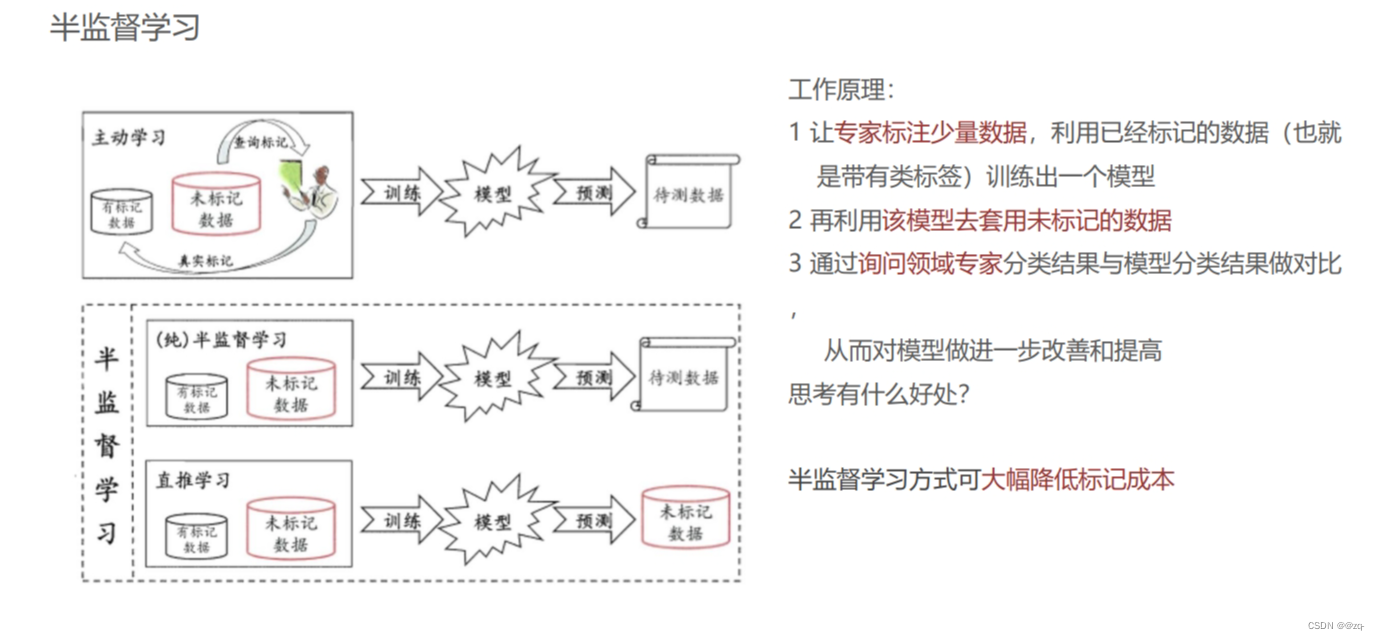
半监督学习是介于有监督学习和无监督学习之间的一种学习方法,其训练数据中同时包含有标签和无标签的数据。半监督学习的目标是利用有标签数据和无标签数据来提高模型的性能和泛化能力。在半监督学习中,通常会利用无标签数据的分布信息来帮助模型更好地学习数据的特征和结构。
强化学习
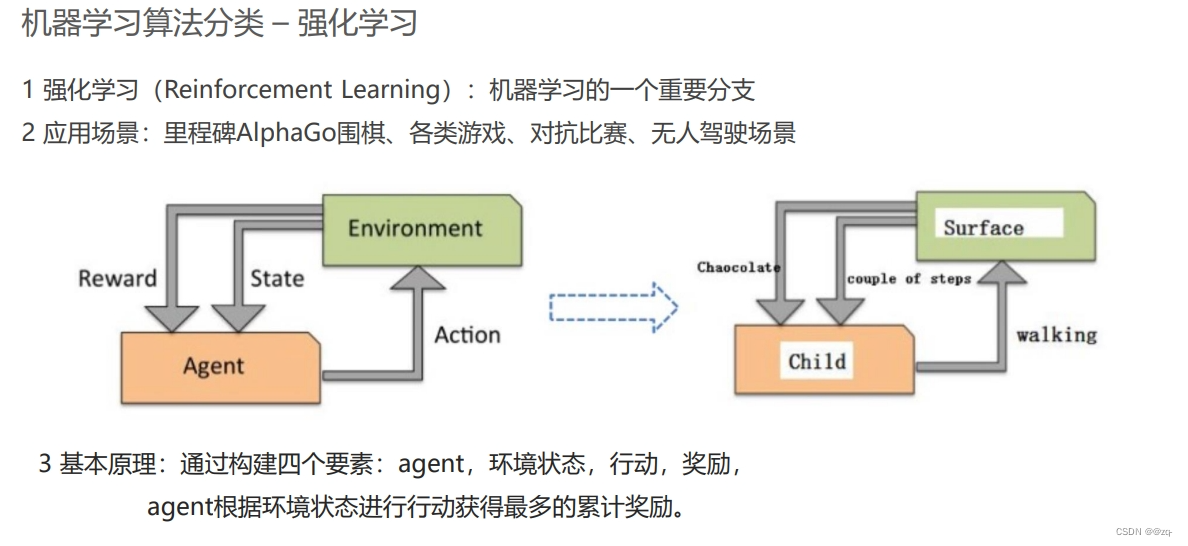
总结















 1377
1377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









