






在服务器上跑Test-summarize-Chinese的时候,在制作数据集的时候遇到了UnicodeDecodeError的问题,解决办法搜了很久才找到。
现在先罗列一些对我来说没有用的做法:
1. 因为写的是utf-不能解码,所以在
df = pd.read_csv('./PreLCSTS/%s.csv' % file, header=None)中加了
encoding = 'gbk'
以错误告终
2. 尝试了其他的解码方式,encoding='gb18030'
还是以错误告终
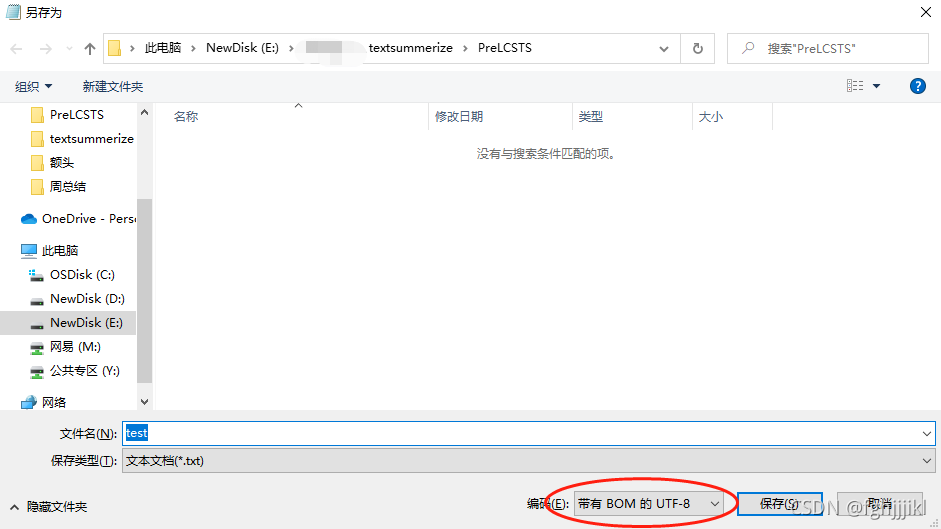
3.最终,查看了excel文件的属性。把csv的文件用记事本打开,然后点击另存为,选择带有BOM的UTF-8,然后再运行程序就成功啦!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









