






 本文介绍了如何使用Python库openpyxl处理Excel文件,包括新建工作薄、设置单元格值、打开已有工作薄,以及访问大量单元格的操作步骤和示例代码。
本文介绍了如何使用Python库openpyxl处理Excel文件,包括新建工作薄、设置单元格值、打开已有工作薄,以及访问大量单元格的操作步骤和示例代码。
前言:
1、python中感觉用xlwings处理EXCEL文件更好,但整了好长时间就是用不了,个人怀疑与所使用的WPS有关,因为感觉xlwings主要针对office的。
2、除了xlwings,应该就属openpyxl了,但注意好像xls文件用不了。在网上也看了一些文章,看的云里雾里,所以把自己学习openpyxl的过程记录在此,一起学习,有错误的地方请指正,有问题可留言讨论。
3、前两部分的代码可直接拷贝运行,里面有说明,上手应该比较容易。
4、详细内容可看:Tutorial — openpyxl 3.1.2 documentation
一、新建及保存工作薄
from openpyxl import Workbook, load_workbook
# 在py文件夹下新建一个工作薄
wb = Workbook() # 创建工作薄,并默认建立一个表名为Sheet的工作表,但是还没有保存,需要保存后才能看到
ws = wb.active # 获取活动表,新建的工作薄中只有一个工作表,ws就是Sheet表
# 在工作薄中创建新的工作表
ws1 = wb.create_sheet('ws11') # 默认在末尾插入
ws2 = wb.create_sheet('ws22', 0) # 在第一个位置插入,表名ws22
ws3 = wb.create_sheet('ws33', -1) # 在倒数第二个位置插入
# 修改工作表的表名
ws1.title = 'New Title' # 将工作表ws1的表名“ws11”改为“New Title”
# 修改表名“ws”的背景颜色
ws.sheet_properties.tabColor = '1072BA'
# 在工作薄中复制并创建工作表
ws4 = wb.copy_worksheet(ws2) # 新生成的工作表ws4是ws2的拷贝,表名为“ws22 Copy”
ws4.title = 'Title' # 修改工作表ws4表名为Title
# 保存工作薄
wb.save('test.xlsx') # 保存在py同文件夹下,也可指定详细路径,会覆盖重名文件
# 查看工作簿中所有工作表的表名
print(wb.sheetnames)
# 遍历工作表
for sheet in wb:
print(sheet.title)
上述代码结果如下:
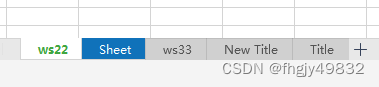
二、打开已有工作薄及设置单个单元格值
from openpyxl import Workbook, load_workbook
# 打开已存在的工作薄
wb = load_workbook('test.xlsx') # 也可指定路径
# 设置工作表(工作表是工作薄的键),下面两行取其一即可
ws2 = wb.active # 获取活动表,是指工作薄最后一次'人为'保存时所在的工作表,否则就是默认的第一个工作表
ws2 = wb['ws22'] # 是指定表名为ws22的工作表
# 设置一个单元格的值,会覆盖原有值,下面两行取其一即可
ws2['B2'] = 'Hello' # 在单元格B2写入值“Hello”
ws2.cell(row=2, column=4, value=20) # row为行,column为列,cell为单元格,在单元格D2写入值20
wb.save('test.xlsx') # 注意保存时,未打开工作薄,否则显示运行错误
# 读取并打印单元格的值(单元格是工作表的键)
print(ws2['B2'].value) # 读取单元格B2的值并打印
print(ws2.cell(row=2, column=4).value) # 读取单元格D2的值并打印
# 也可以下面这样,能print出来但表中不显示,因未wb.save()
a = ws2['B3'] # 将单元格B3设为a,a是单元格
b = ws2.cell(row=3, column=4) # 将单元格D3设为b,b是单元格
a.value = 24 # 在单元格B3写入值24
b.value = 'World' # 在单元格D3写入值“World”
print(a.value) # 读取并打印单元格B3的值
print(b.value) # 读取并打印单元格D3的值
#获取单元格的行、列、坐标
print(b.value, b.row, b.column, b.coordinate) #coordinate为单元格具体坐标
三、访问大量单元格
经过上述两部分内容,应该能够理解如何用openpyxl对xlsx文件进行新建、打开、修改(读写)、保存文档。上述两部分的代码可直接拷贝运行,而接下来的这部分因比较繁琐,就列出部分代码说明,每段代码都可放在下述三行代码后运行,使用print语句查看结果就明白怎么回事了,有的别忘了wb.save('test.xlsx')保存
from openpyxl import Workbook, load_workbook
wb = load_workbook('test.xlsx') #也可指定路径
ws = wb["ws22"] #ws是指定表名为ws22的工作表
1、可以使用切片来访问一系列单元格(是单元格,不是单元格的值)
cell_range = ws['A1':'C2']
一系列的行和列也可以通过类似的方法获取单元格
>>> colC = ws['C'] >>> col_range = ws['C:D'] >>> row10 = ws[10] >>> row_range = ws[5:10]
也可使用 Worksheet.iter_rows 方法(按“行”获取单元格)
>>> for row in ws.iter_rows(min_row=1, max_col=3, max_row=2): ... for cell in row: ... print(cell) <Cell Sheet1.A1> <Cell Sheet1.B1> <Cell Sheet1.C1> <Cell Sheet1.A2> <Cell Sheet1.B2> <Cell Sheet1.C2>
同样 Worksheet.iter_cols 方法(按“列”获取单元格)
>>> for col in ws.iter_cols(min_row=1, max_col=3, max_row=2): ... for cell in col: ... print(cell) <Cell Sheet1.A1> <Cell Sheet1.A2> <Cell Sheet1.B1> <Cell Sheet1.B2> <Cell Sheet1.C1> <Cell Sheet1.C2>
注意:由于性能原因 Worksheet.iter_cols() 方法在只读模式下不可用。
2、如果需要遍历文件中的所有行和列的单元格(是单元格,不是单元格的值)
可以使用 Worksheet.rows 属性(按“行”获取单元格)
>>> ws['C9'] = 'hello world' >>> tuple(ws.rows) ((<Cell Sheet.A1>, <Cell Sheet.B1>, <Cell Sheet.C1>), (<Cell Sheet.A2>, <Cell Sheet.B2>, <Cell Sheet.C2>), (<Cell Sheet.A3>, <Cell Sheet.B3>, <Cell Sheet.C3>), (<Cell Sheet.A4>, <Cell Sheet.B4>, <Cell Sheet.C4>), (<Cell Sheet.A5>, <Cell Sheet.B5>, <Cell Sheet.C5>), (<Cell Sheet.A6>, <Cell Sheet.B6>, <Cell Sheet.C6>), (<Cell Sheet.A7>, <Cell Sheet.B7>, <Cell Sheet.C7>), (<Cell Sheet.A8>, <Cell Sheet.B8>, <Cell Sheet.C8>), (<Cell Sheet.A9>, <Cell Sheet.B9>, <Cell Sheet.C9>))
或者 Worksheet.columns 属性(按“列”获取单元格)
>>> tuple(ws.columns) ((<Cell Sheet.A1>, <Cell Sheet.A2>, <Cell Sheet.A3>, <Cell Sheet.A4>, <Cell Sheet.A5>, <Cell Sheet.A6>, ... <Cell Sheet.B7>, <Cell Sheet.B8>, <Cell Sheet.B9>), (<Cell Sheet.C1>, <Cell Sheet.C2>, <Cell Sheet.C3>, <Cell Sheet.C4>, <Cell Sheet.C5>, <Cell Sheet.C6>, <Cell Sheet.C7>, <Cell Sheet.C8>, <Cell Sheet.C9>))
注意:由于性能原因 Worksheet.columns 方法在只读模式下不可用。
3、如果只想要工作薄中单元格中的值(不是单元格),可以使用 Worksheet.values 属性, 这会按“行”获取单元格中所有的值
for row in ws.values:
for value in row:
print(value)
Worksheet.iter_rows 和 Worksheet.iter_cols 可以用 values_only 参数来返回单元格中的值
>>> for row in ws.iter_rows(min_row=1, max_col=3, max_row=2, values_only=True): ... print(row) (None, None, None) (None, None, None)















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









