








点赞👍👍收藏🌟🌟关注💖💖
你的支持是对我最大的鼓励,我们一起努力吧!😃😃
搜索是递归中的一个分支,回溯是搜索中的一个分支,因此我们学习顺序是递归、搜索、回溯。
1.递归
什么是递归
在C语言,和数据结构(二叉树、快速排序、归并排序)我们或多或少已经接触过递归;递归大白话来说就是:函数自己调用的情况
为什么会用到递归
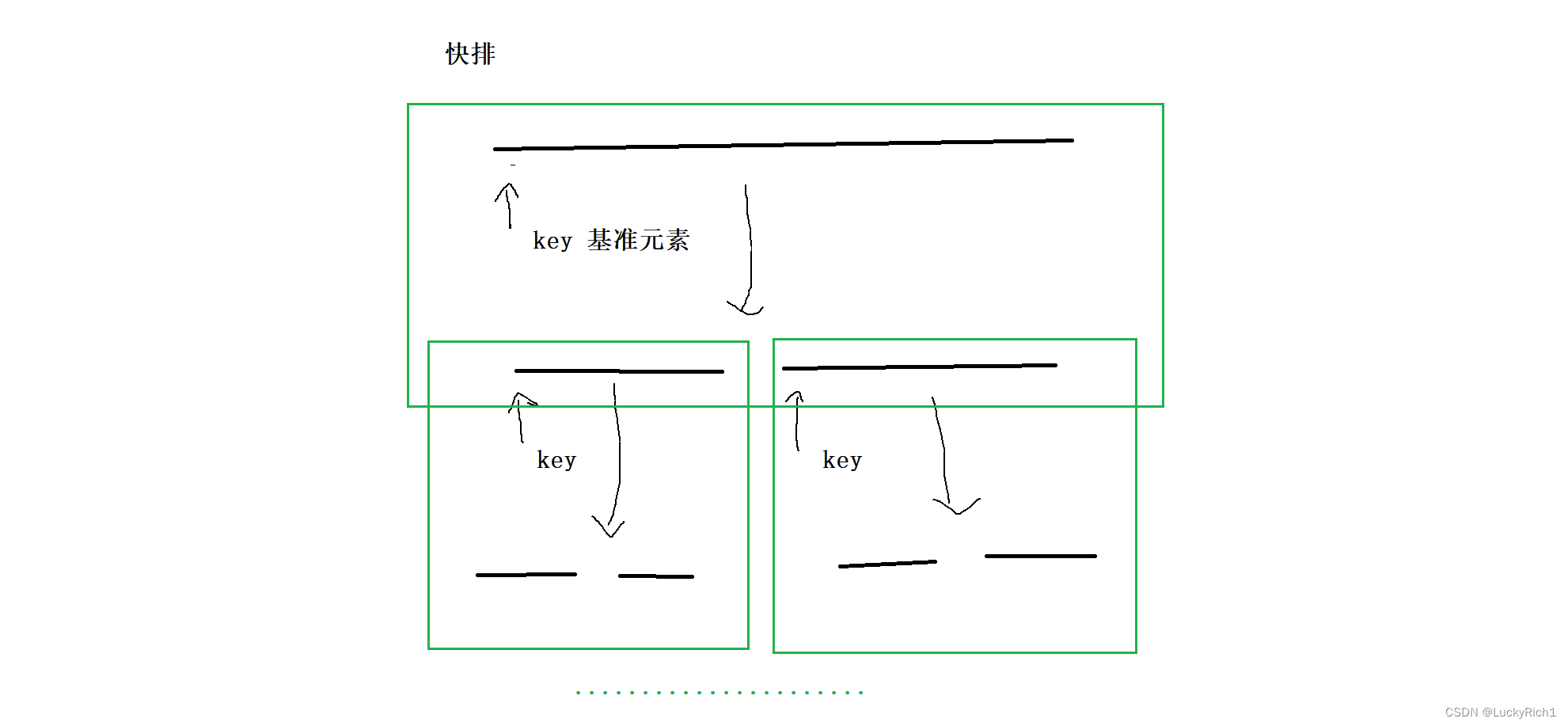
以二叉树、快排、归并为例
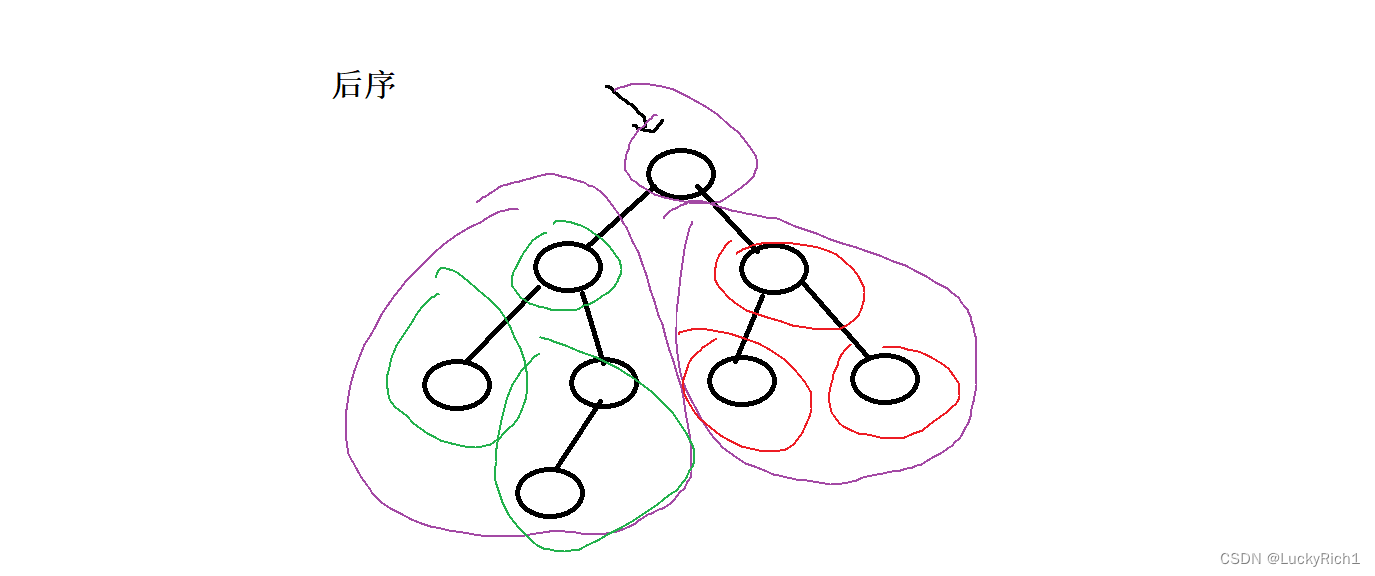
后序:左右根
我们一定是从根节点开始,先找左子树,在找右子树,然后在根节点,
当我们走到下面左子树的时候,也依旧是这样的做法,等到把左子数遍历完了,然后走到右子树依旧是左右根,当右子树走完,才最终回到根节点
快排每次都找一个基准元素,将数组分成两部分,然后再对分开的部分在找基准元素然后在继续分…
归并,选择中间节点将数组分成两部分,然后再合并,然后分解到下面也是一样的操作,
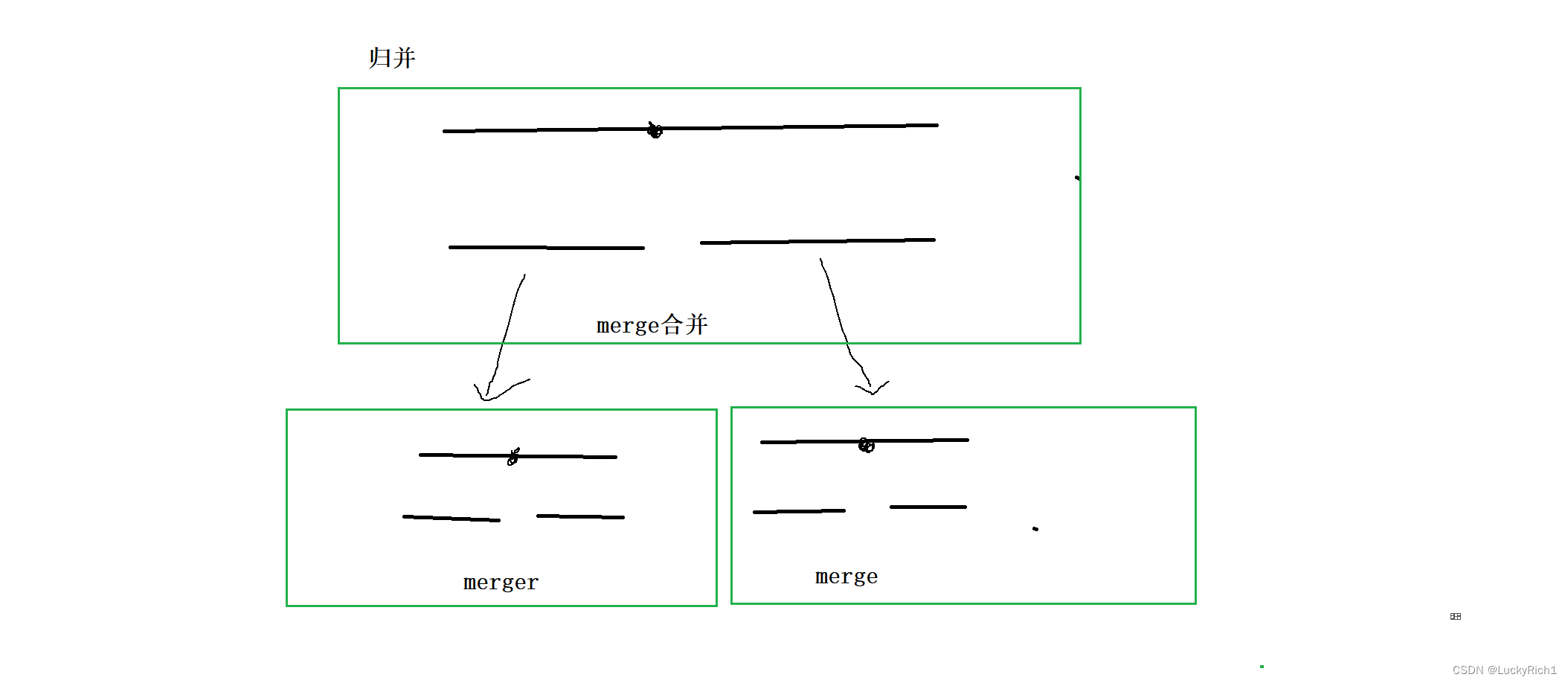
上面都是解决主问题的时候,出现了相同的子问题。
主问题 -----> 相同的子问题
子问题 -----> 相同的子问题
总结:当出现一个问题,你发现解决这个问题的过程中,会出现相同的子问题,并且这些子问题都可以用同一个函数来解决,此时用递归!
如何理解递归
第一层:递归展开图
第二层:二叉树中的题目
第三层:宏观看待递归的过程
- 不要在意递归的细节展开图
- 把递归的函数当成一个黑盒(我给黑盒一些数据,黑盒最终能够返回我想要的结果,具体里面是如何操作我并不关心)
- 相信这个黑盒一定能完成这个任务
dfs函数看成一个黑盒,我给你一个根节点,你把这个根节点后序遍历一下。我们要有一个心理暗示,相信这个dfs一定能够完成。接下来就是如何完成,后序先要遍历左子树,所以给dfs传入左子树根节点,右子树根节点,关于dfs如何完成并不关心。然后左右子数都完成了,就该根节点了。

如果把递归当成一个黑盒,不用关心那些递归展开图,直接看递归函数是如何进行的看某一层是如何操作的,具体是如何展开并不关心,我相信你一定能够完成这个任务。因为我们有之前第一层第二层的铺垫,编译器是会自动帮我们展开完成左子树右子树的遍历。然后再关注细节问题,这个递归代码就出来了。
merge看成一个黑盒,我给你一个数组和左端点和右端点,你把这个区间排下序,并且我相信这个黑盒一定能够完成任务。具体如何排序,就是选一个中间节点把数组平方成两部分,左边排好序,右边排好序,如何排序merge就是排序的具体你里面是如何操作的我不管,而且一定能够完成任务,因为以前我画过递归展开图。排好序之后再合并有序数组。注意处理细节不能出现死递归。

如何写好一个递归
1.先找到相同的子问题(确定每次要传什么)!!! ----> 函数头设计
2.只关心某一个子问题是如何解决的 -----> 函数体的书写
3.注意一下递归函数的出口即可
2.搜索
搜索 vs 深度优先遍历 vs 深度优先搜索 vs 宽度优先遍历 vs 宽度优先搜索 vs 暴搜
这些都是在搜索经常会碰见的名词
深度优先遍历 vs 深度优先搜索
宽度优先遍历 vs 宽度优先搜索
深度优先遍历一条路走到黑直到不能走在返回
宽度优先遍历一层一层走
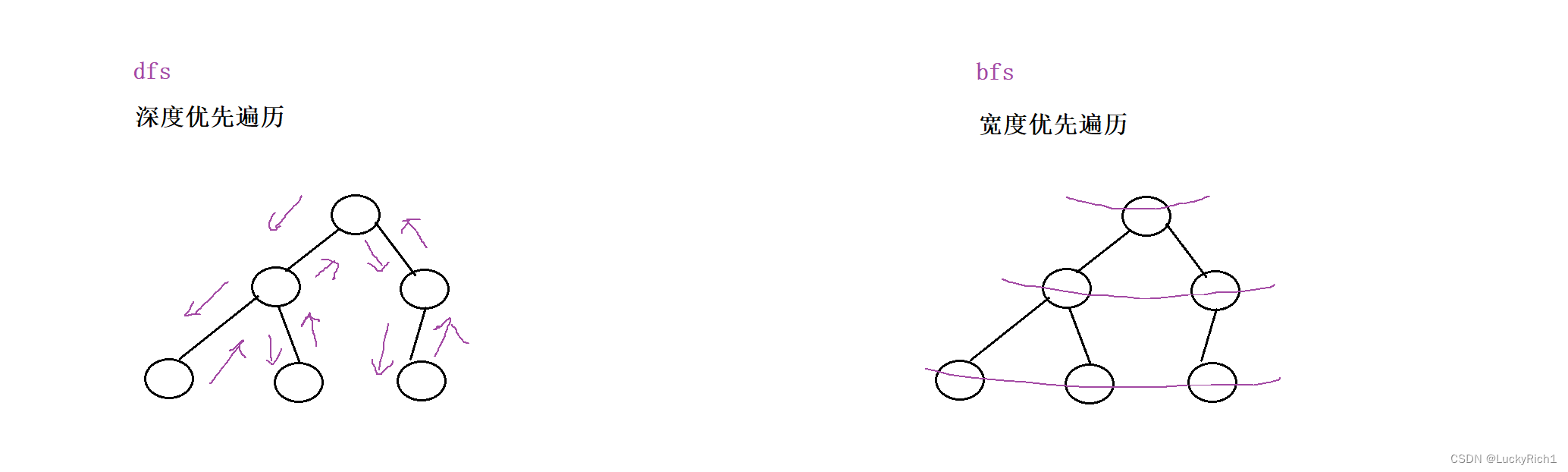
那什么是深度优先搜索和宽度优先搜索呢?
想一个问题,我们遍历的目的是不是为了找到节点里的值啊。所以深度优先遍历和深度优先搜索,宽度优先遍历和宽度优先搜索 其实就是一个东西。
遍历是形式,目的是搜索。 其实就是同一个东西!
搜索就是在这个树或者图,把所有节点都遍历一遍。
关系图
搜索的本质就是:暴力枚举一遍所有的情况。
所以搜索也可以叫做暴搜。
搜索(暴搜),把所有情况都暴力枚举一遍。它分为两种情况:1. dfs ,2. bfs
扩展搜索问题
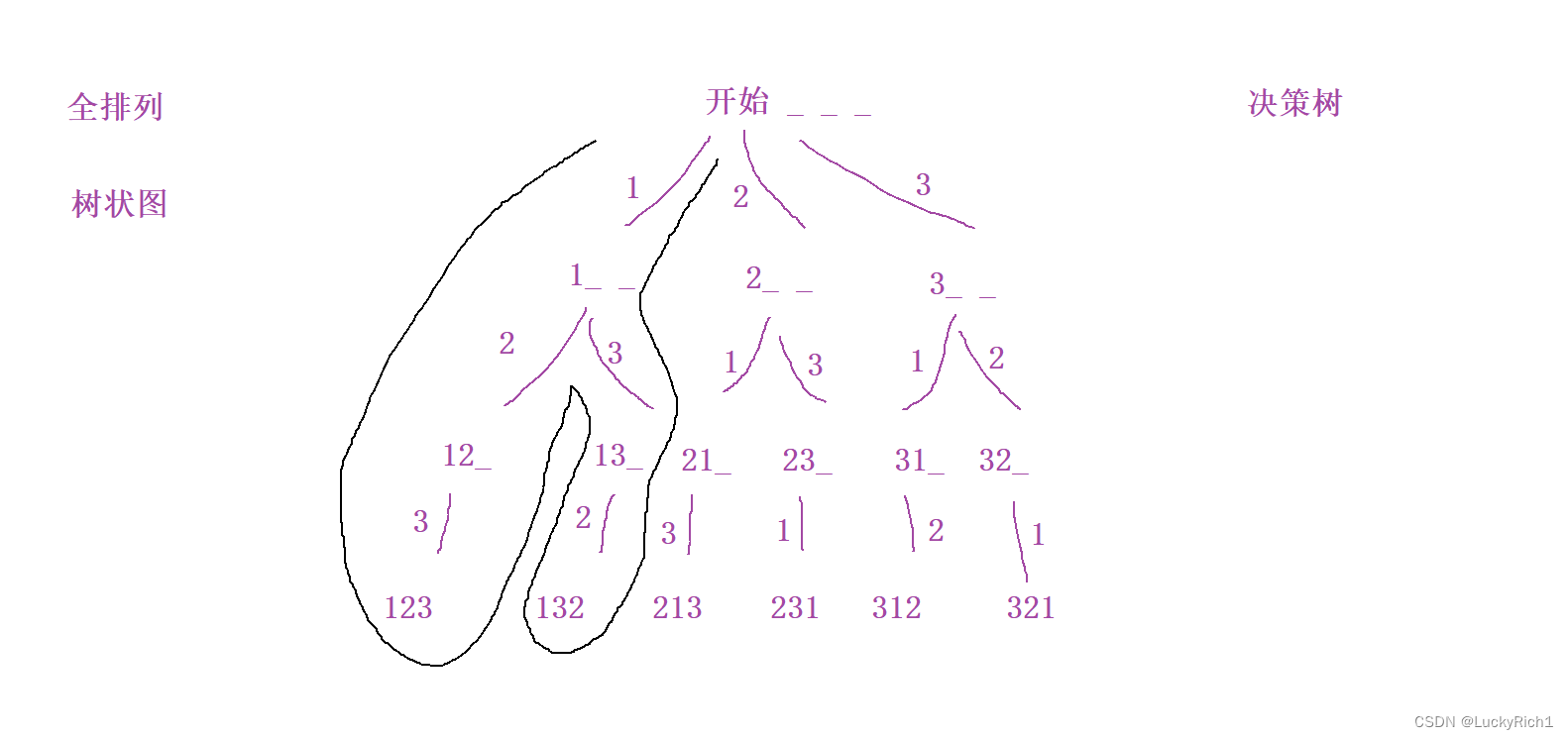
搜索要么是树状结构,要么是图状结构。其实全排列就是树状结构
此时我们仅需从开始的位置开始把这棵决策树遍历一遍,也就是来一次深度优先遍历就可以把所有结构都可以找到。所以不要把深度优先遍历和宽度优先遍历局限于是必须是二叉树的题目和图的题目,如果一个题目能用一个决策树的形式画出来,我们就可以用搜索的形式把所有结果全都暴力枚举处理。
3.回溯与剪枝
回溯本质就是深度优先搜索
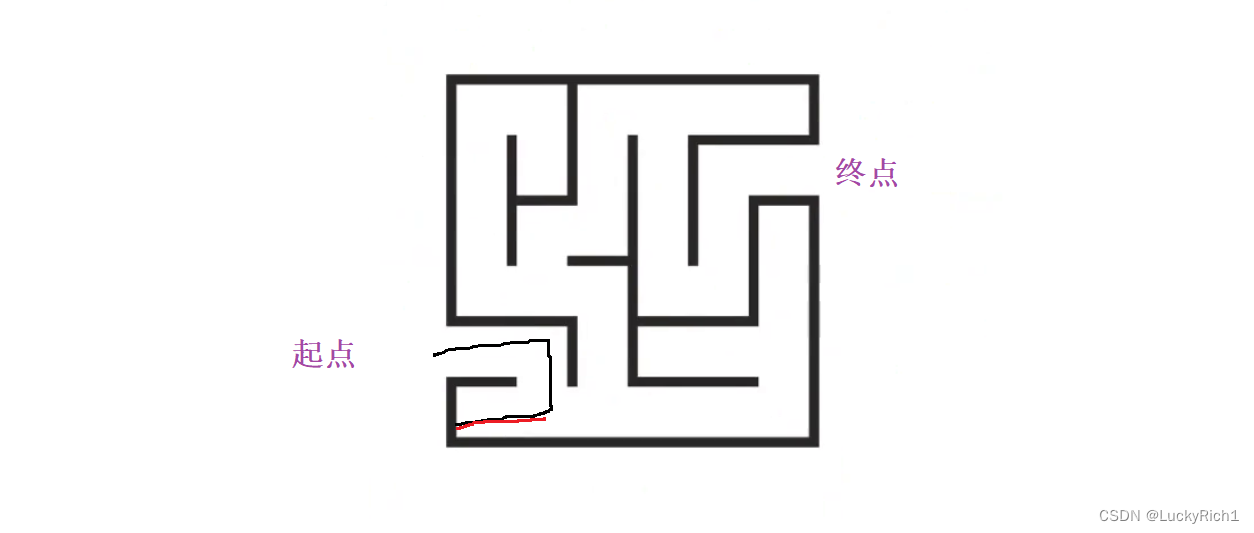
就比如迷宫问题,解决迷宫问题有两种方式,一个是深度优先遍历,一个是宽度优先遍历。下面我们采用深度优先遍历的方式,只要有拐角要么走左边,要么走右边,把所有情况都尝试一遍,一定能找到终点。
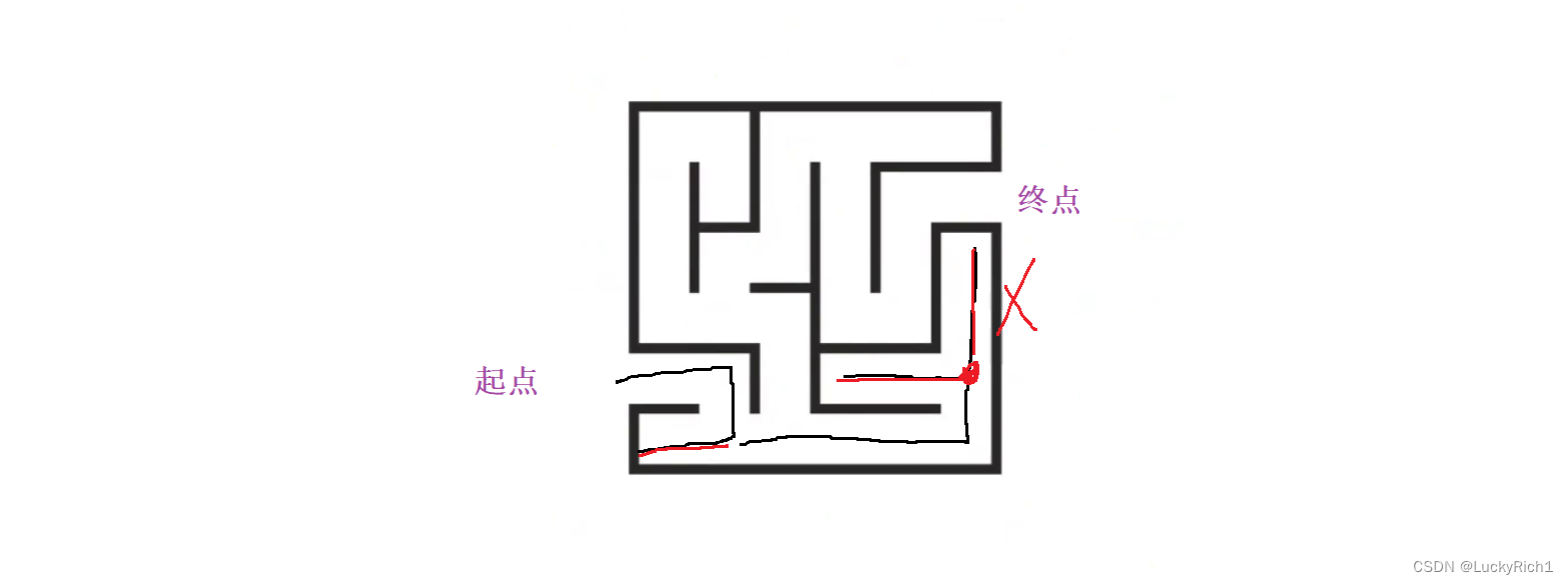
如果发现一条路走不通就返回,其中红色这条线就是回溯。回溯就是在找最终结果时尝试某种情况的时候发现某种情况行不通,此时返回上一级然后从上一级继续开始尝试。 这不是就是深搜的分支吗返回上一层的操作。回退上一级就是回溯,所以不要把回溯和深搜分开。
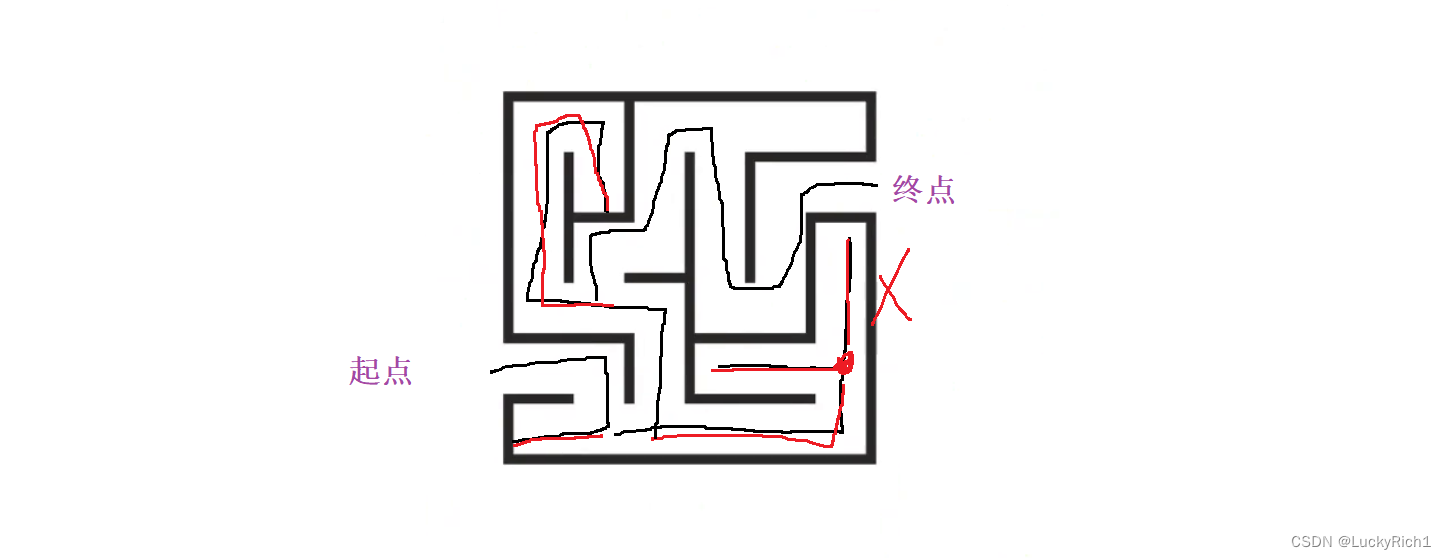
当再次回溯到同一点的时候,但是上面的已经走过了不用再走了,这种情况就是剪枝。剪枝就是这条分叉路口有两种选择,但是我们已经明确知道其中一个选择不是我们最终想要的结果,我们就可以把这个分支剪掉。
所以不要把回溯和剪枝想的有多难,回溯就是深搜的一个小分支而已。
4.汉诺塔问题
题目链接:面试题 08.06. 汉诺塔问题
题目分析:

有三根柱子和一些盘子,将第一根柱子上面所有盘子借助其他柱子移动到最后一根盘子上。
算法原理:
不要看到汉诺塔就马上使用递归,一定知道为什么可以用递归,这比如何用递归解决这个问题更加重要。
1.如何解决汉诺塔问题
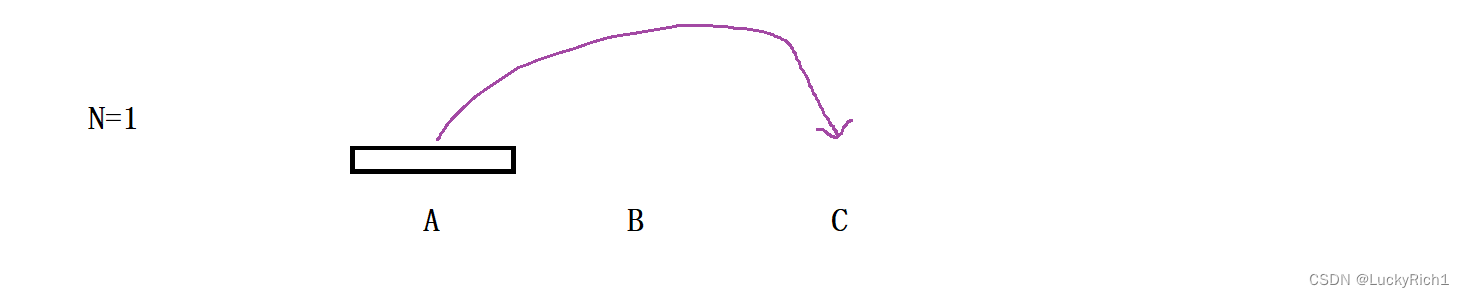
当只有一个盘子的时候,可以直接移动到最后一个柱子上
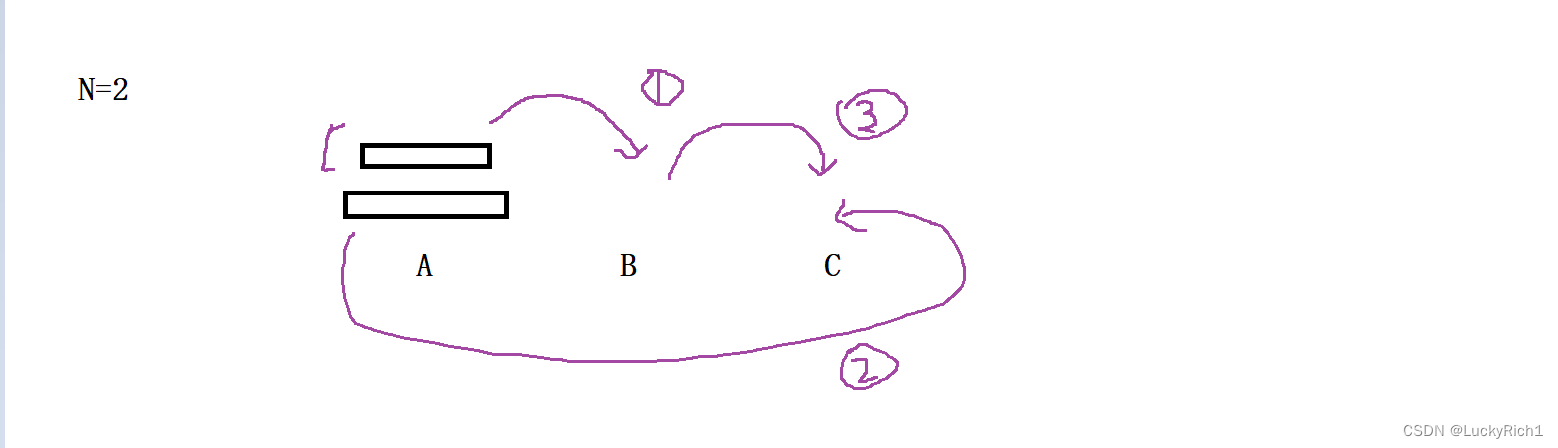
当有两个盘子的时候,1. 将A柱最下面盘子上面的盘子先放到B柱,2. 将A柱最下面的一个放到C柱,3. 然后将B柱上面的盘子在放到C柱
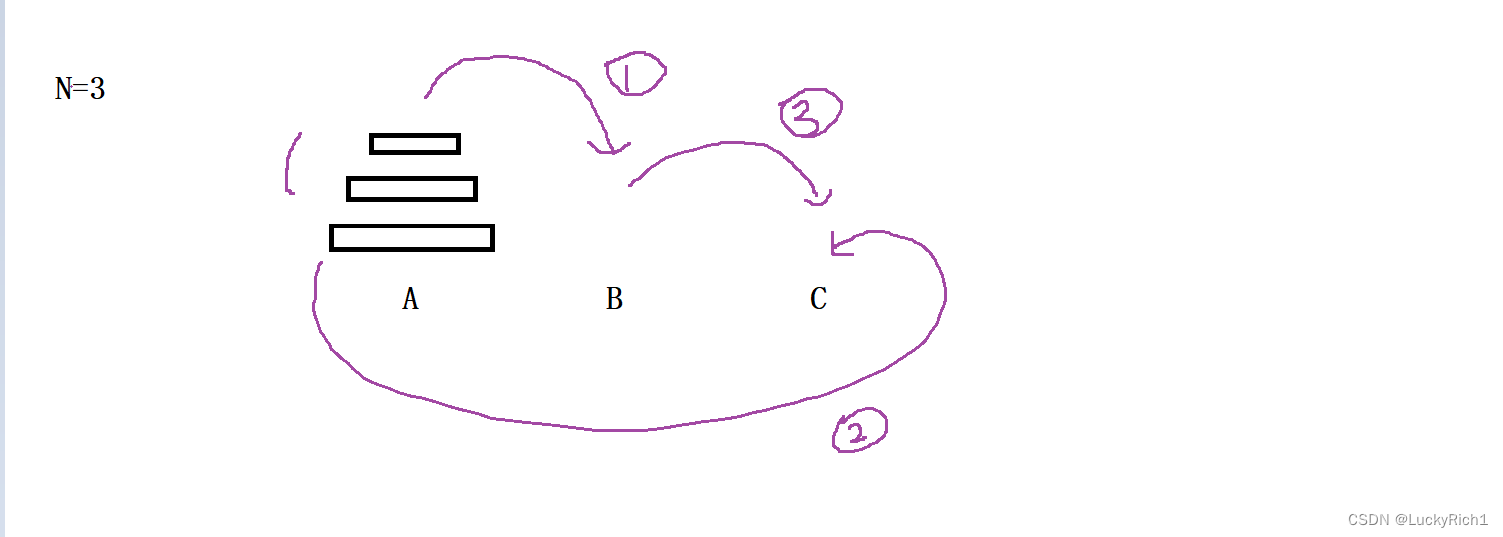
当有三个盘子的时候,1. 将A柱最下面盘子上面的盘子先放到B柱,2. 将A柱最下面的一个放到C柱,3. 然后将B柱上面的盘子在放到C柱
当有四个盘子的时候,1. 将A柱最下面盘子上面的盘子先放到B柱,2. 将A柱最下面的一个放到C柱,3. 然后将B柱上面的盘子在放到C柱
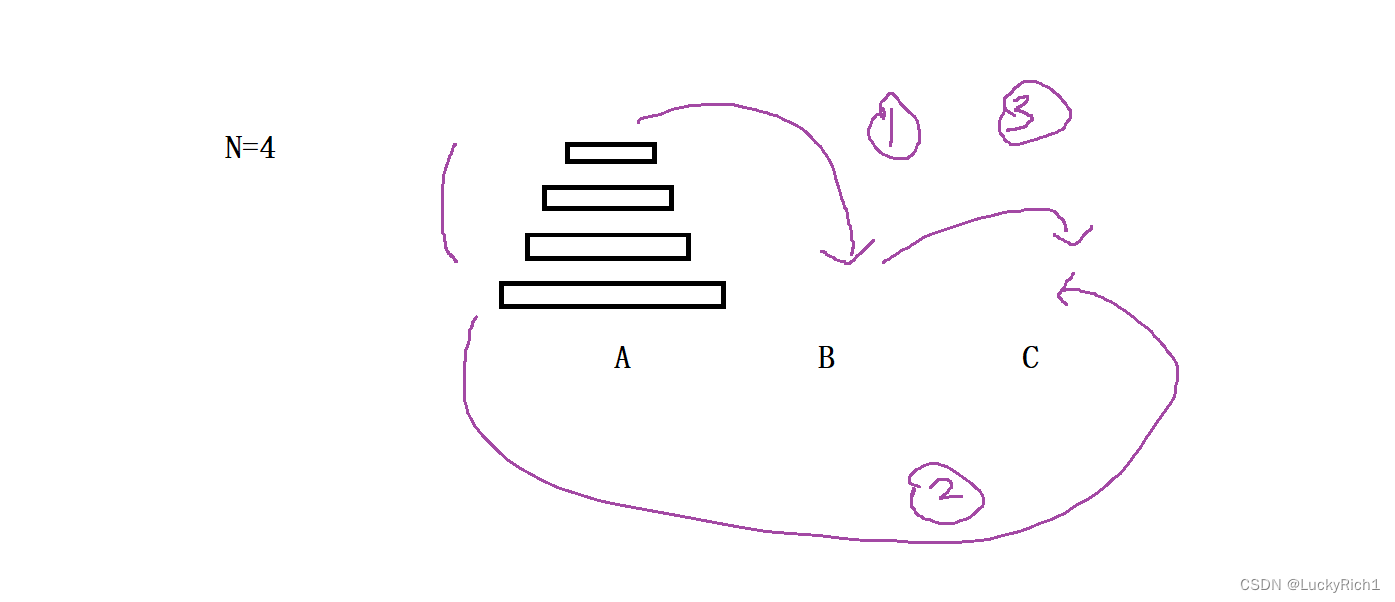
2.为什么可以用递归?
当我们发现解决大问题的时候,出现相同类型的子问题。并且解决方法都是一样的。此时就可以用递归了。
大问题 —> 相同类型的子问题
子问题 —> 相同类型的子问题
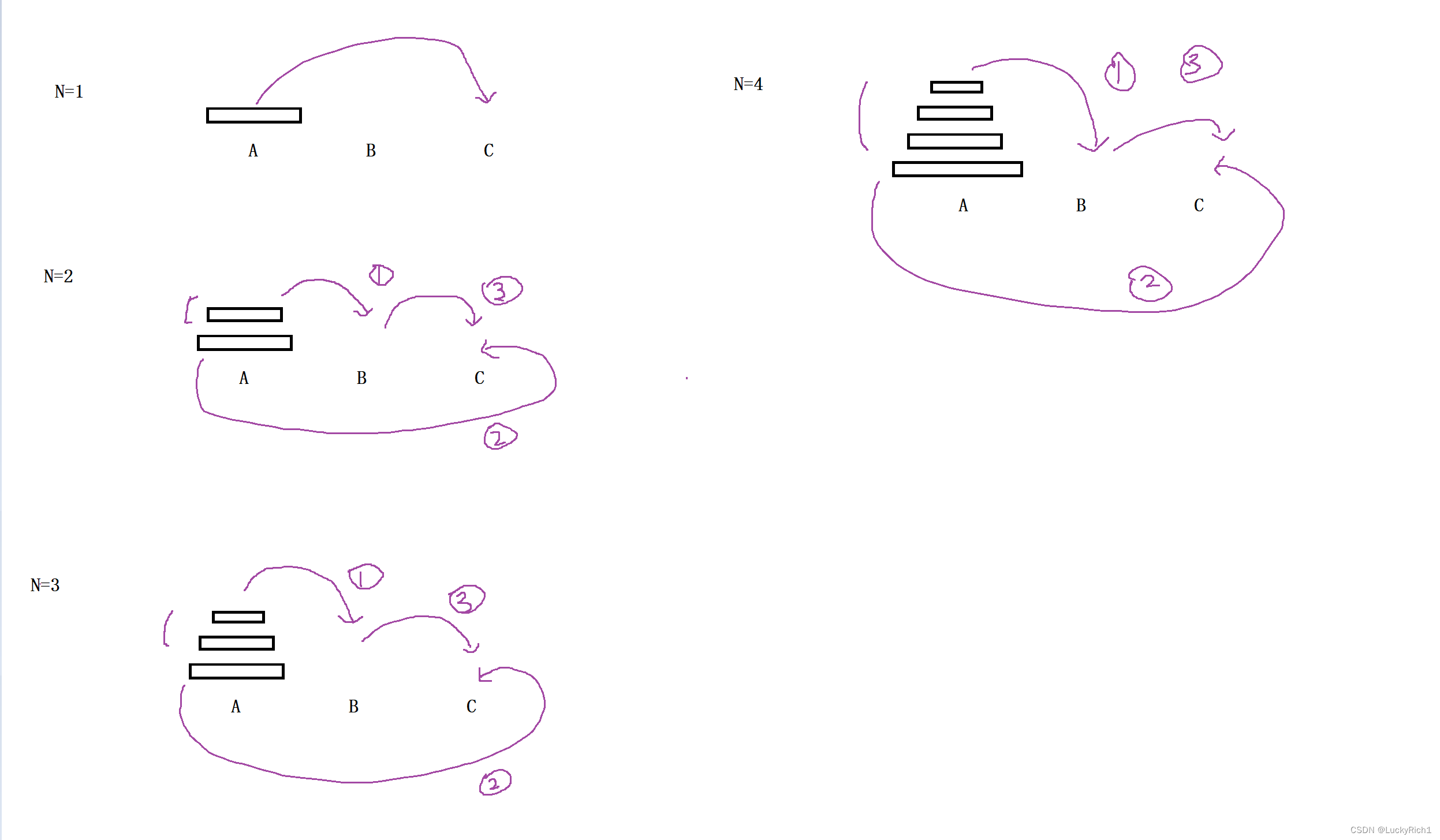
3.如何编写递归?
- 重复的子问题 ----> 函数头
我们发现都是一根柱子上的盘子借助另一个柱子将盘子转移到其他柱子上面的,因此我们可以总结出来。
将 x 柱子上的一堆盘子,借助 y 柱子,转移到 z 柱子上面 ----> void dfs(x,y,z,int n)
- 只关心某一个子问题在做什么 ----> 函数体
dfs(x,z, y,n-1) 将x柱上n-1个盘子借助z柱,转移到y柱子 第
x.back() -> z 将x柱最后一个盘子,转移到z柱
dfs(y,x,z,n-1) 将y柱上n-1个盘子借助x柱,转移到z柱
我们要以宏观角度理解递归函数,只要给它数据它一定能够帮我们完成任务。不用管具体的递归过程。
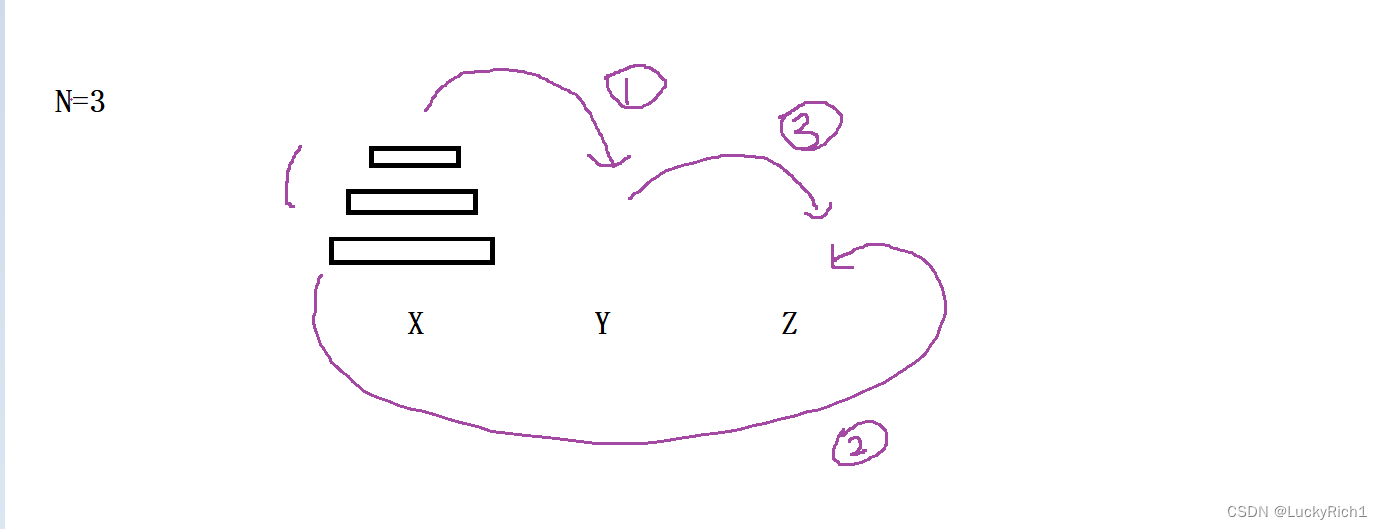
- 递归的出口
n==1的时候,不用借助其他柱子,直接放就可以了。 x.back() --> z
根据上面我们就可以写代码了
class Solution {
public:
void hanota(vector<int>& a, vector<int>& b, vector<int>& c)
{
dfs(a,b,c,a.size());
}
void dfs(vector<int>& a, vector<int>& b, vector<int>& c,int n)
{
if(n == 1)
{
c.push_back(a.back());
a.pop_back();
return;
}
dfs(a,c,b,n-1);
c.push_back(a.back());
a.pop_back();
dfs(b,a,c,n-1);
}
};
有兴趣可以自己画一下递归展开图。
5.合并两个有序链表
题目链接:21. 合并两个有序链表
题目分析:
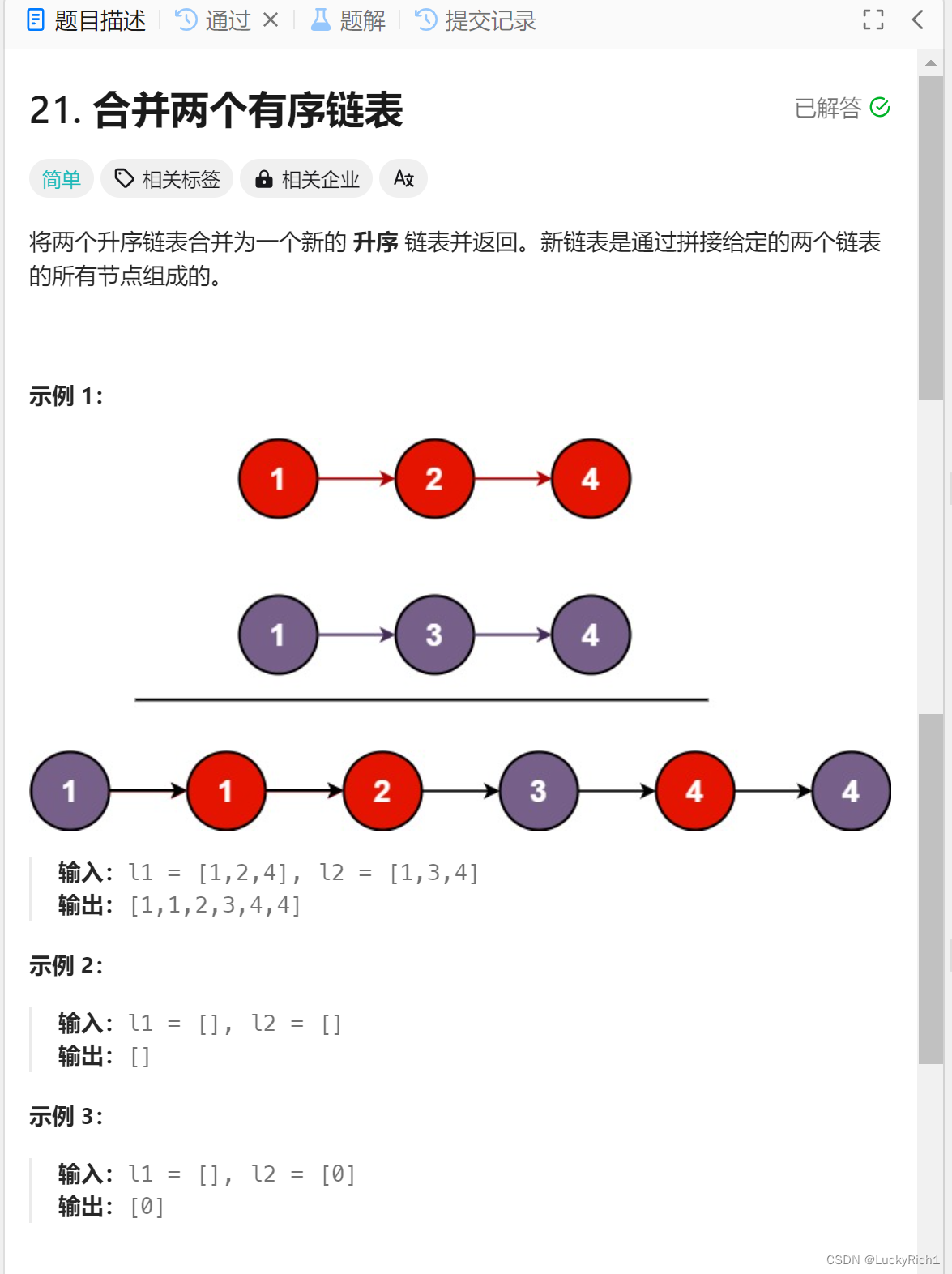
算法原理:
将两个有序链表合并然后返回合并后的头指针,我们可以先找到l1,l2指向的最小节点当作合并后的头指针,然后让剩下的节点合并,这时就出现了重复的子问题,我们的大问题是将全部的节点合并,此时我们选择了合并后的返回的头指针,那仅让剩下的节点合并。
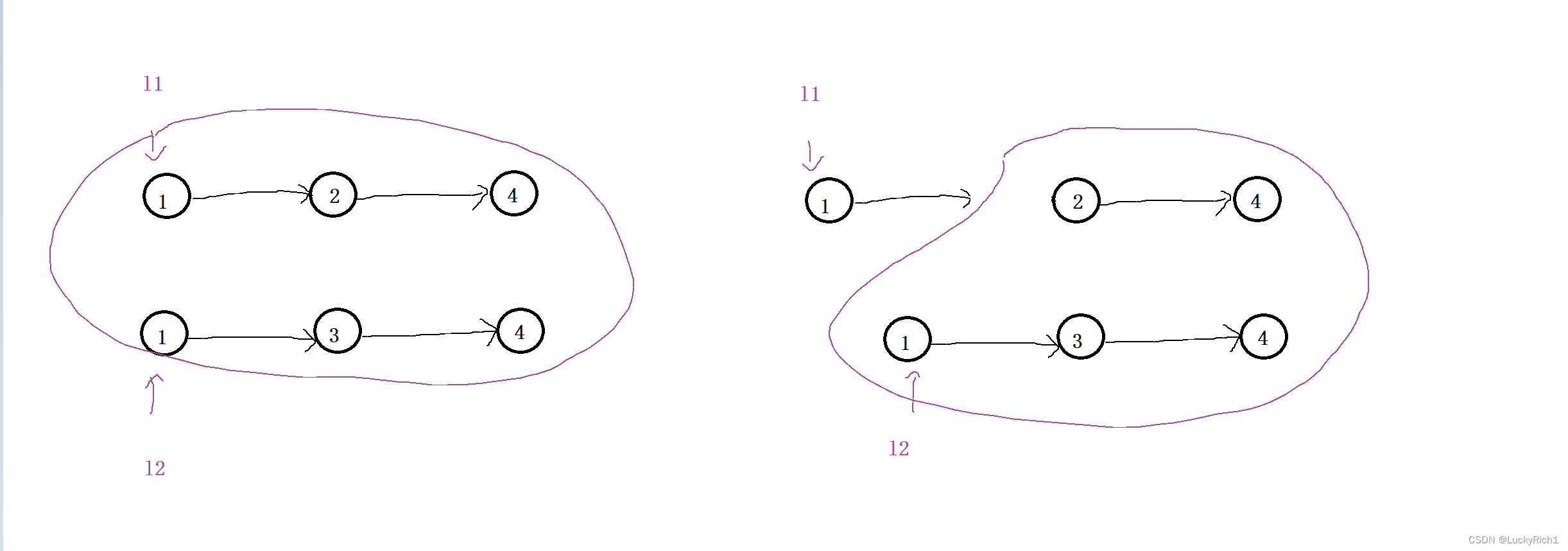
解法:递归
1.重复的子问题 —> 函数头的设计
合并两个有序链表 --> Node* dfs(l1 ,l2) ,仅需传两个链表的头指针,然后把合并后的头指针给我返回来就好了。具体这个dfs怎么去完成这个任务我不管,我相信它 一定能够完成任务。给它两个链表头指针就能给我返回合并之后的头指针。
2.只关心某一个子问题在做什么事情 —> 函数体的设计
- 比大小
- l1->next=dfs(l1->next,l2) l1当头指针让它连接剩下节点合并后的结果,相信dfs一定能把剩下节点合并,此时仅需让l1连着剩下节点合并后的结果就好了。剩下节点如何合并我不关心,我相信dfs一定将合并后的结果给我。
- return l1
这里假设l1较小,如果l2较小上面l1改成l2就行了
3.递归的出口
当l1为空,返回l2 ,l2为空 返回l1 ,l1 l2 都为空返回任意一个
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if(l1 == nullptr) return l2;
if(l2 == nullptr) return l1;
if(l1->val <= l2->val)
{
l1->next=mergeTwoLists(l1->next,l2);
return l1;
}
else
{
l2->next=mergeTwoLists(l1,l2->next);
return l2;
}
}
};
小总结:
循环(迭代) vs 递归
循环(迭代) vs 递归 都是解决重复的子问题 这件事情,所以 它们两者之间可以相互转化。循环改递归,递归改循环。
什么时候用循环,什么时候用递归?
我们先解决递归和深搜的关系,我们在回头看这个东西
就比如汉诺塔那个问题 递归展开图。真正展开就是下面这个样子。 它展开的顺序和树的深度优先遍历是一模一样的。递归的展开图,其实就是对一棵树做一次深度优先遍历(dfs)
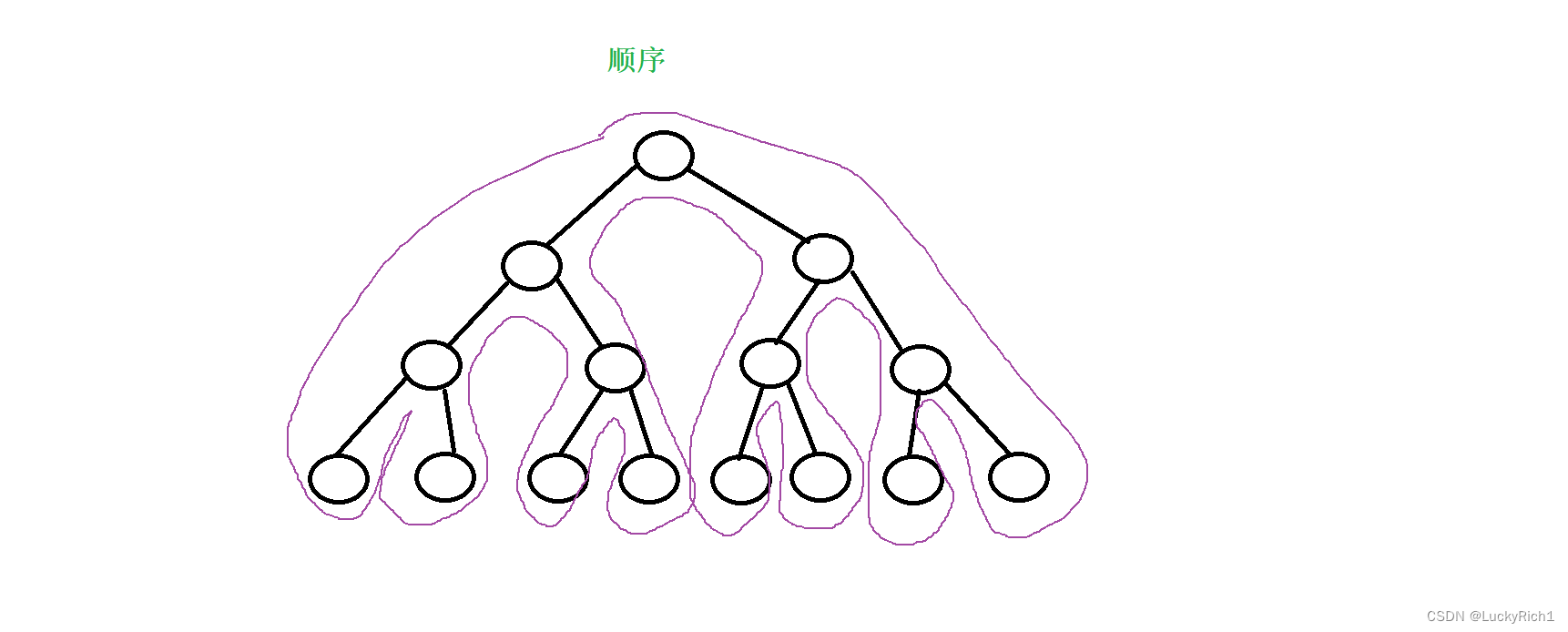
如果此时你想把这个递归转化成循环的话,需要借助一个栈,因为你递归展开左边的图的时候还需要展开右边的图,因此首先要保存一下这个信息等左边递归回来的时候在从这里出发去右边递归。但是这样成本就来了,本来汉诺塔递归代码就三四行,你要借助栈把它改成循环那代码量就上来了。
所以当递归展开图有点麻烦的时候,我们用递归解决这个问题比较好。
如果递归展开图是如下面的形状,这棵树只有一个分支,像这样的递归改成循环是比较容易的。
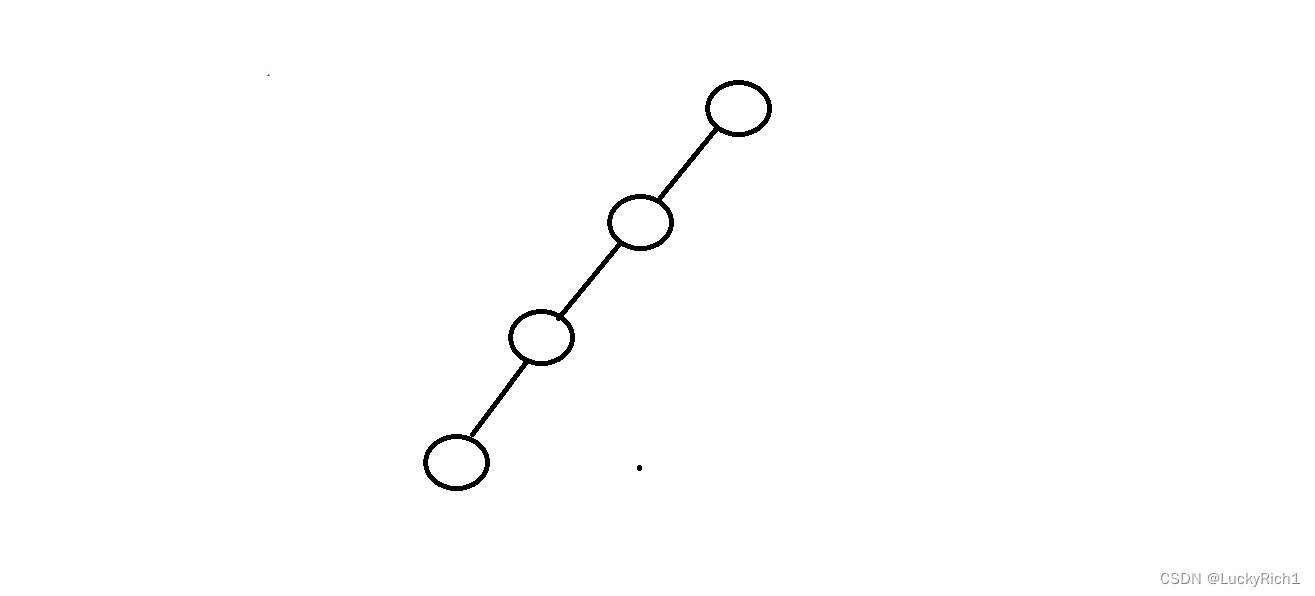
先序遍历和后序遍历对于上面的图来说虽然都是遍历,但是处理时机不一样结果就不意义。先序遍历是从上到下历,后序遍历是从下到上。那什么时候搞先序什么时候搞后序呢?那个方式简单就用那个,后面的题我们会体会到。中序遍历仅适用于二叉树。
6.反转链表
题目链接:206. 反转链表
题目描述:
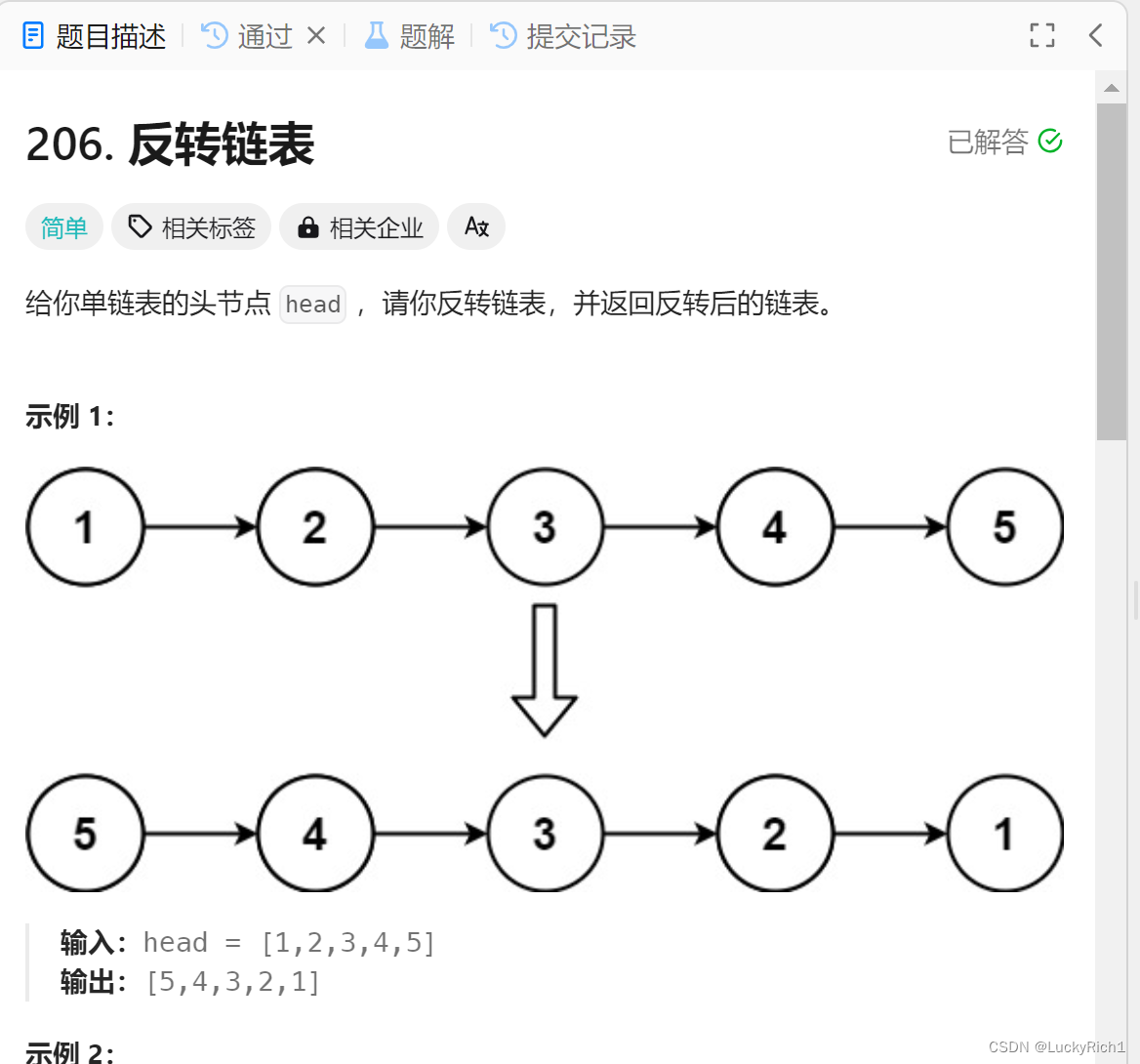
算法原理:
这题循环也能做,不过这里我们不考虑用循环,直接用递归,不过我们以两种视角来做这道题。
解法:递归
第一种视角:从宏观角度看待问题
要求逆序整个链表,我可以先把前两个节点逆序一下,可以让
head->next->next=head;head->next=nullptr
虽然完成了前两个节点的逆置,但是此时有一个问题,你发现后面的节点丢弃了!
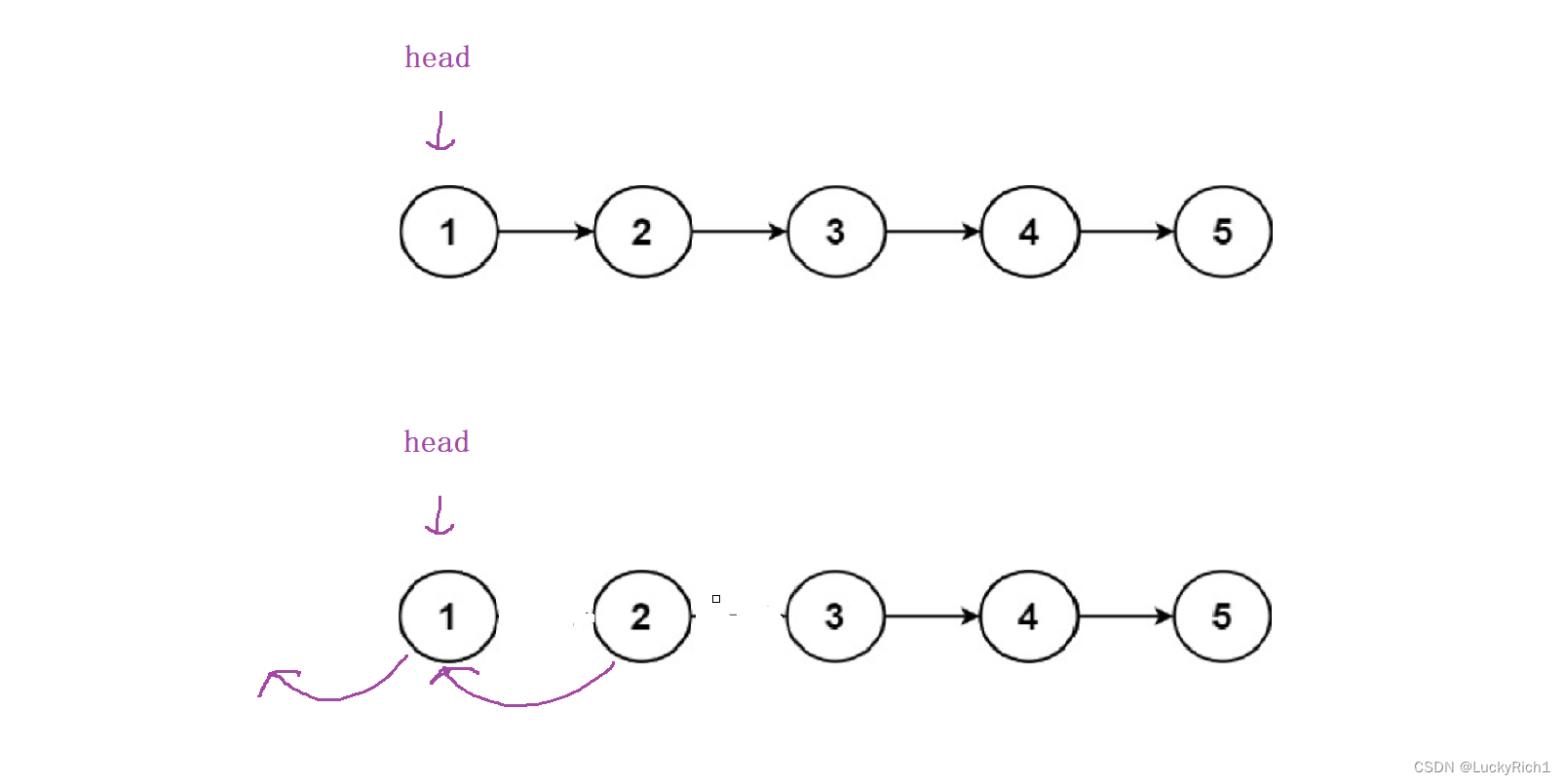
所以先逆置前面两个节点是不行的,因此先把后面一堆节点逆置,具体怎么逆置并不关心,我相信dfs一定可以把head->next后面节点全部逆置,逆序完之后,我仅需在把head连接到逆序链表的后面。如何连接和刚才做法一下,head->next->next=head;head->next=null;此时就完成了整个链表逆序。
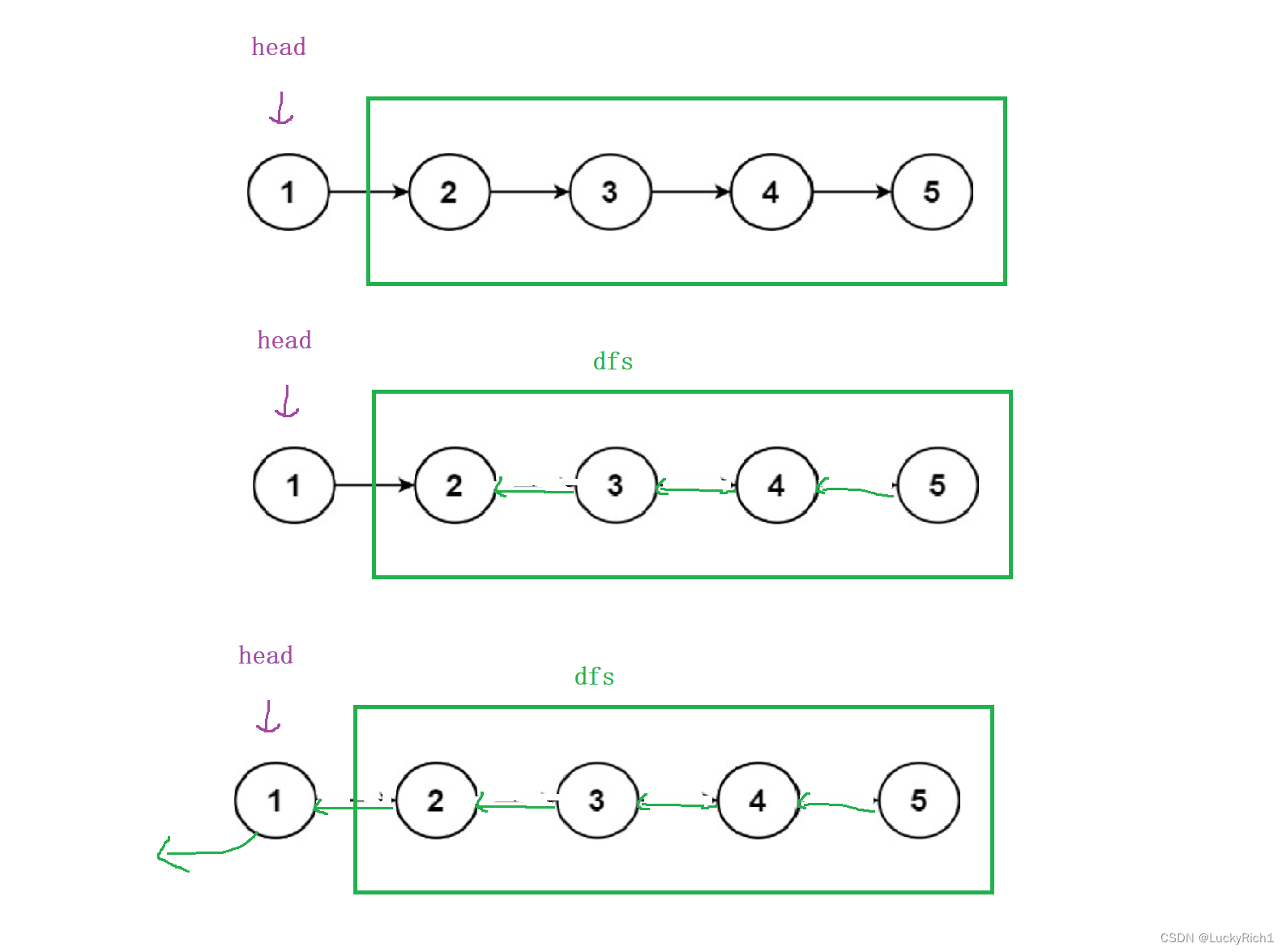
- 让当前节点后面的链表先逆置,并且把头结点返回
- 让当前节点添加到逆置后的链表即可
如果上面不太理解,那我们换一种角度
第二种角度:将链表看成一棵树
无论是二叉树,还是多叉树都是树形结构,但是链表其实也是一个树形结构,无非就是一个节点只有一个分支!
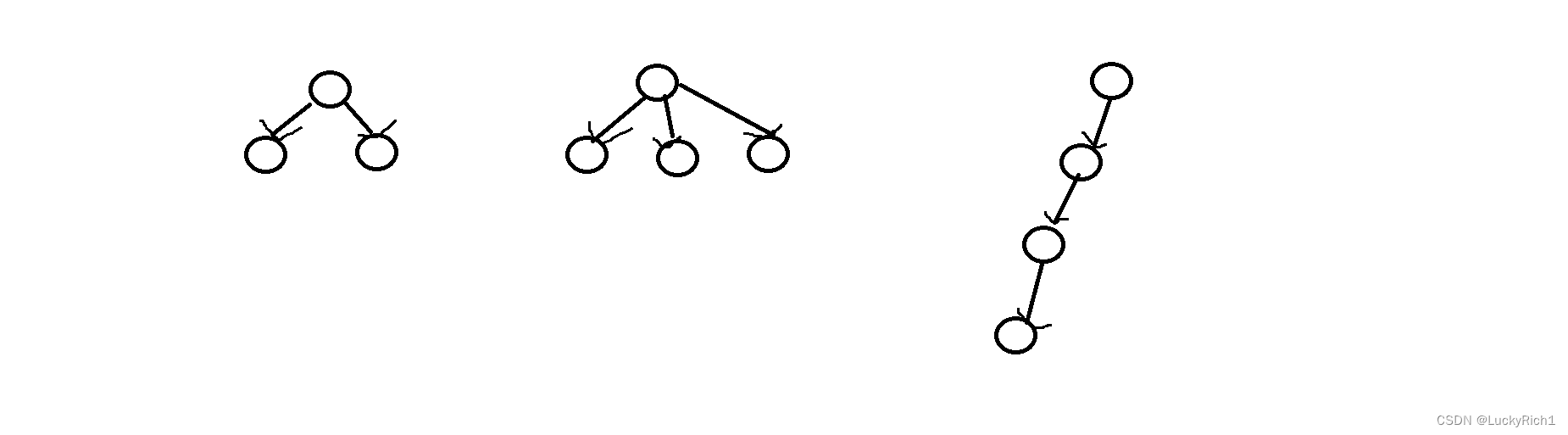
然后对这个链表做一次逆置,仅需做一次后序遍历即可!
从上往下走,当发现此时有个节点为null或者是叶子节点的时候,这就是我们要找的逆置之后的头,这个头要一层层的返回去,每个递归函数内部都做同样的事情,把头返回去,然后逆置。
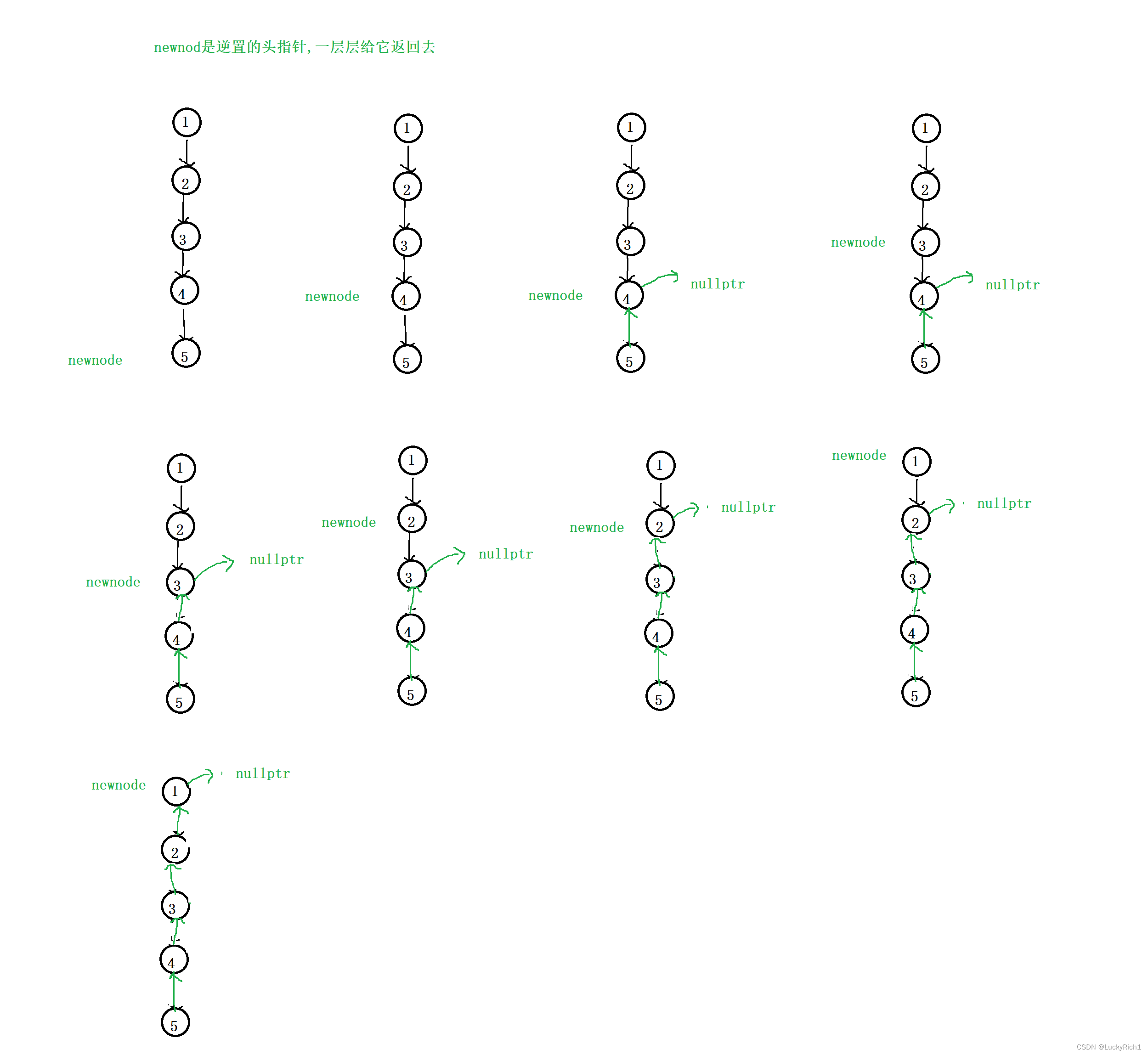
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if(head == nullptr || head->next == nullptr)
return head;
ListNode* newhead=reverseList(head->next);
head->next->next=head;
head->next=nullptr;
return newhead;
}
};
7.两两交换链表中的节点
题目连接:24. 两两交换链表中的节点
题目描述:
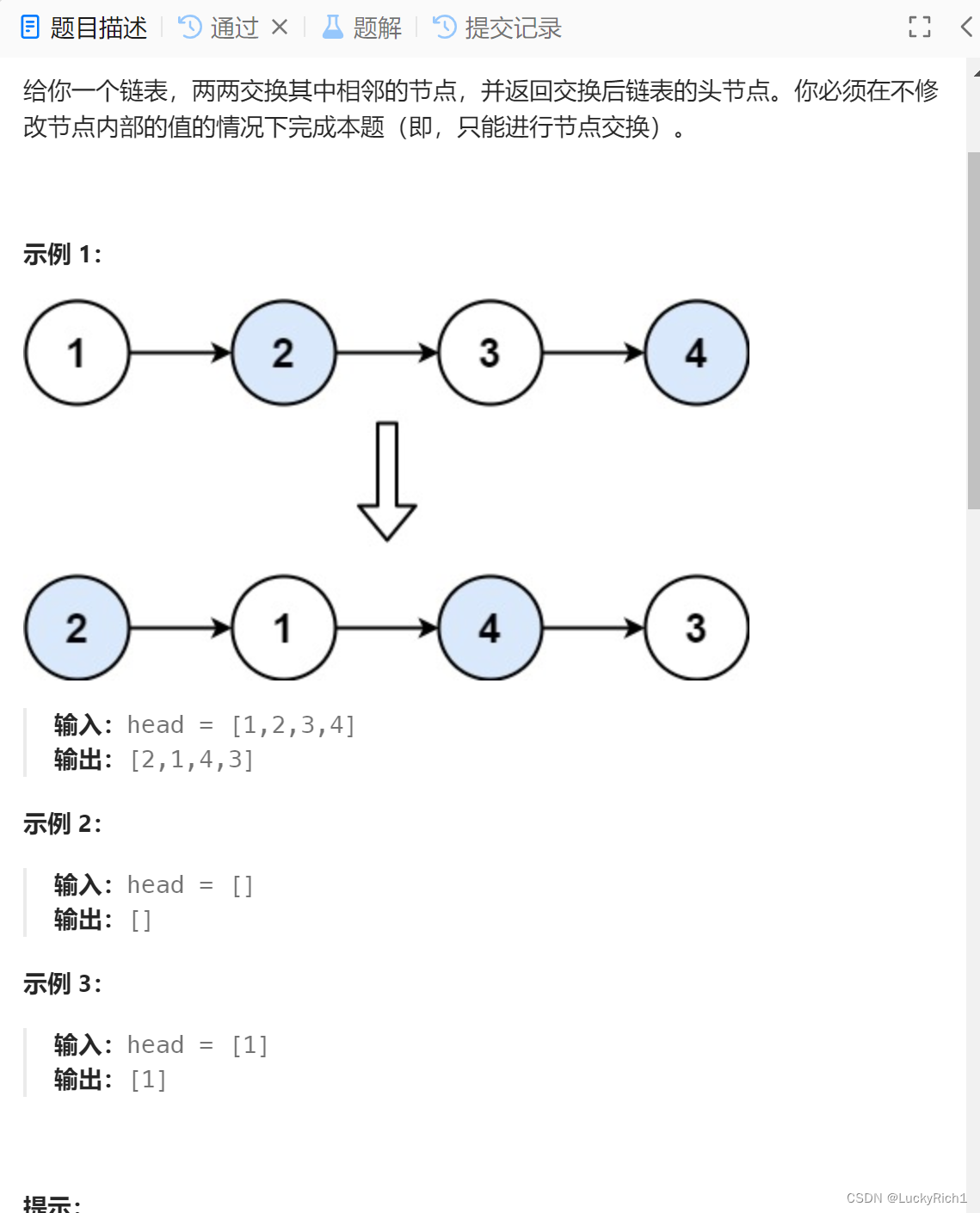
注意不能改变节点内的值,而是要改变指针指向
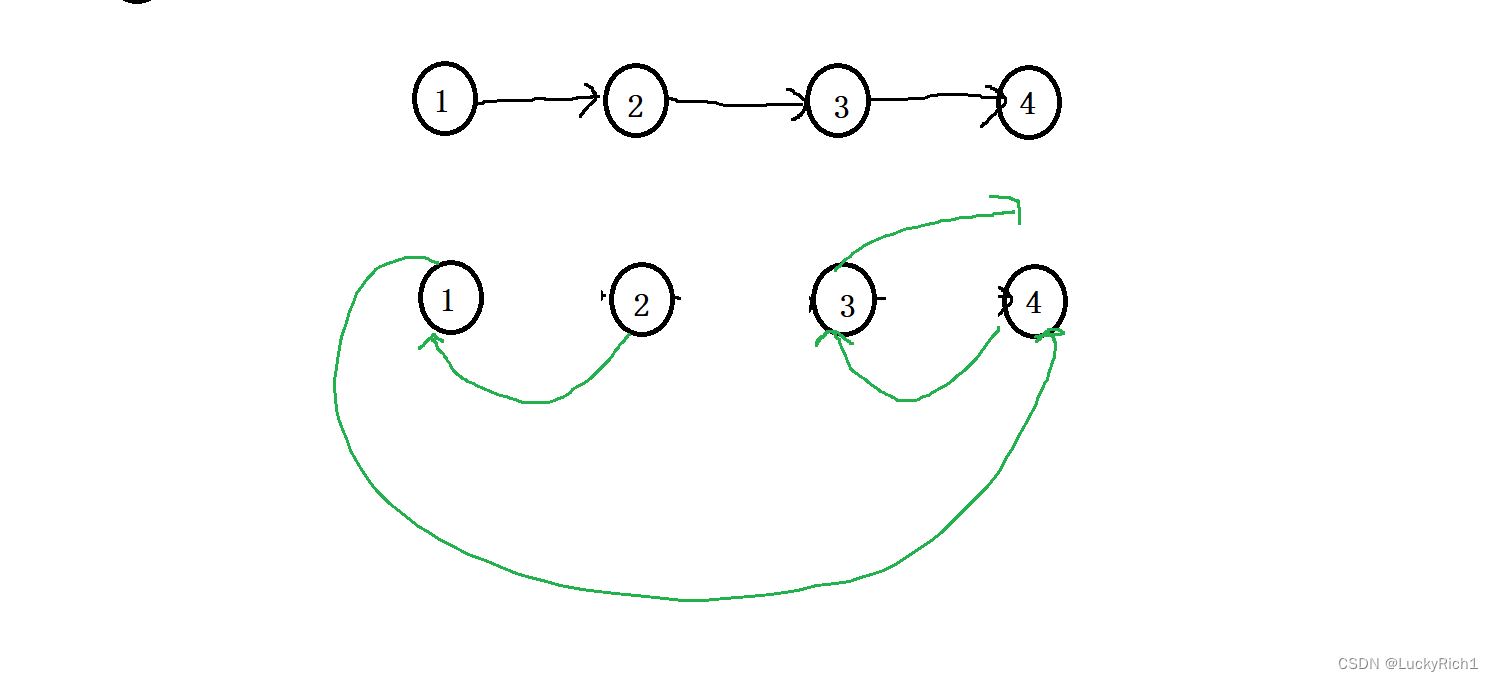
算法原理:
从上面的题我们就知道了,可以以两种视角看待链表递归了。不过我们还是用常用的宏观角度解决问题。把递归函数看成一个黑盒并且相信它一定能够完成任务,这样非常简单。
解法:递归
当有上面链表逆置的基础,你发现这两道题是一模一样的。这道题让把链表两两交换然后把交换后的链表头指针返回。那就给dfs赋予一个使命,给它传一个链表的头指针然后把链表两类交换并且交换后的链表头指针返回。
此时让后面的节点先两两交换然后把头指针返回来,然后仅需将前面两个节点交换一下,将交换后的结果和后面的链表连起来就可以了。
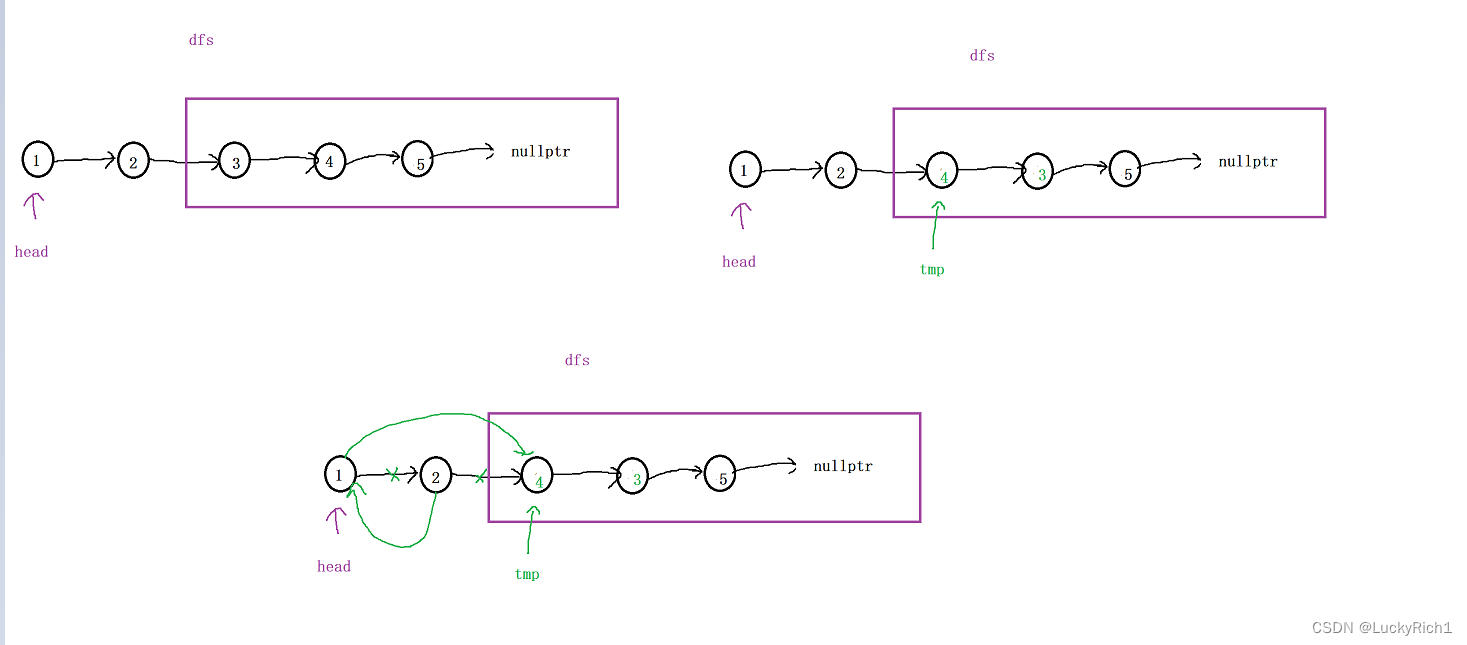
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if(head == nullptr || head->next == nullptr)
return head;
auto tmp=swapPairs(head->next->next);
auto ret=head->next;
head->next->next=head;
head->next=tmp;
return ret;
}
};
8.Pow(x, n)-快速幂(medium)
题目链接:50. Pow(x, n)
题目描述:

这里是一个快速幂算法。给一个数快速求出它的幂。
算法原理:
解法一:暴力循环
但可能会有越界风险
解法二:快速幂
快速幂有两种实现方式:1. 递归,2. 迭代
这里我们主要是递归。上面暴力循环,假设x^n 需要 x乘n次。想办法优化一下
当求x的n次幂,我可以先求出x的n/2次幂,这样就知道一半的幂了,此时在乘一次一半的幂。不就得到答案了吗,注意这里n是要分偶次和奇次的。
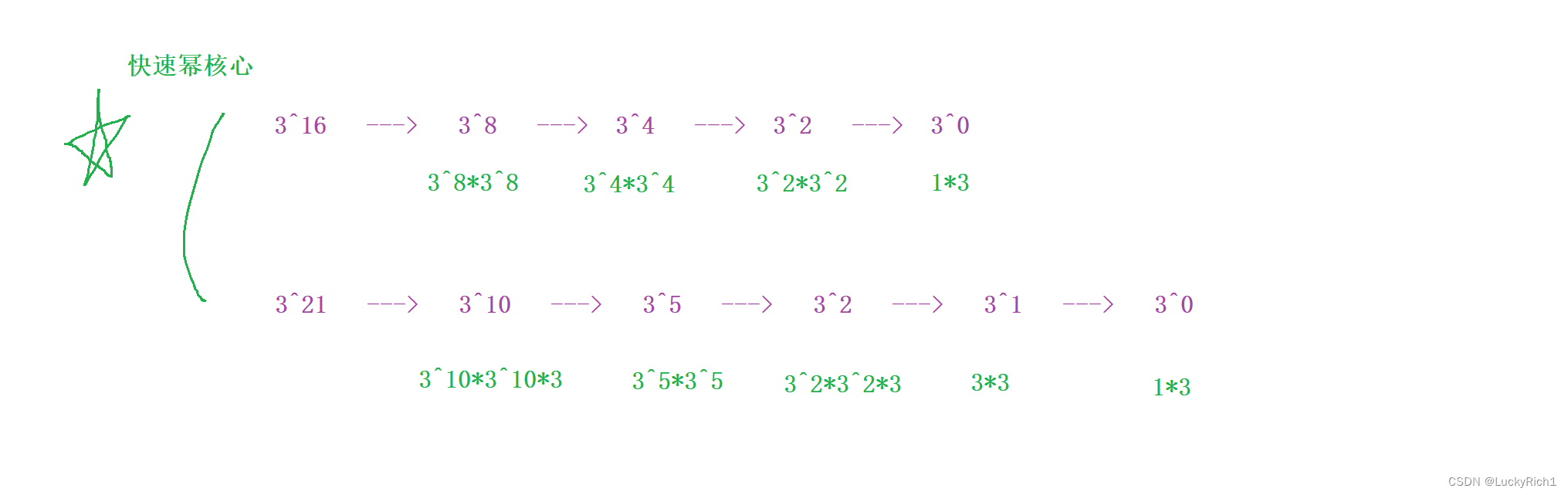
当我们在解决一个大问题的时候又出现了相同的子问题,此时我们就可以用递归了!
- 相同的子问题 —> 函数头
int pow(x,n),我只要给pow一个数x,一个幂n,让它把x的幂给我返回来。我不关心它是如何实现的。 - 只关心每一个子问题都做了什么 —> 函数体
首先我要知道一半的幂是多少 tmp=pow(x,n/2)
然后分情况f返回 return n%2 == 0 ? tmp * tmp : tmp * tmp * x - 递归出口
n==0,就不用在递归了
注意有细节问题:
-
n有可能是负数
负数转成正数,结果用1除一下
2^-3 —> 1/2^3 -
n有可能是-2^31
-2 ^ 31转成正数是2 ^ 31,这比int最大还要大,因此强制转化为long long
class Solution {
public:
double myPow(double x, int n) {
return n<0 ? 1.0/pow(x,-(long long)n) : pow(x,n);
}
double pow(double x,long long n)
{
if(n == 0) return 1.0;
double tmp=pow(x,n/2);
return n%2 == 0 ? tmp*tmp : tmp*tmp*x;
}
};















 466
466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









