







在使用spring的时候,我也经常会使用到bean标签,beans标签,import标签,aop标签等。
下面主要为读者介绍spring的默认的自带标签的解析流程。
验证模式(DTD&XSD)
dtd基本已被淘汰,现在spring的验证模式基本都是采用xsd文件作为xml文档的验证模式,通过xsd文件可以检查该xml是否符合规范,是否有效。在使用xsd文件对xml文档进行校验的时候,除了要名称空间外(xmlns="http://www.springframework.org/schema/beans")还必须指定该名称空间所对应的xsd文档的存贮位置,通过schemaLocation属性来指定名称空间所对应的xsd文档的存储位置,它包含两部分,一部分是名称空间的URI,另一部分是该名称空间所标识的xsd文件位置或URL地址(xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd“)。
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd“)。
名称空间URI
当我们使用spring标签的时候,例如使用aop标签的时候,这个aop标签是在哪里解析的呢,例如看下面的例子:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.1.xsd ">
<aop:aspectj-autoproxy/>
<bean name="purchaseService" class="net.itaem.aop.PurchaseService" />
<bean name="purchaseService2" class="net.itaem.aop.fPurchaseService2" />
<bean class="net.itaem.aop.LogAspect"/>
</beans>
其中schemaLocation有包含http://www.springframework.org/schema/aop这个地址,我们可以在这里找到

我们可以看到,它对应着一个类的路径,是AopNamespaceHandler,着代表着aop的实现是经过这个处理器实现的。
XSD文件位置
我们可以看到在xsi:schemaLocation里面http://www.springframework.org/schema/aop 后面还跟着http://www.springframework.org/schema/aop/spring-aop-3.2.xsd,这个xsd文件代表着aop标签的定义以及解析校验规范都是在这里定义的。那么是不是要去这个网址http://www.springframework.org/schema/aop/spring-aop-3.2.xsd下载呢,让我们先看看下面这个截图:
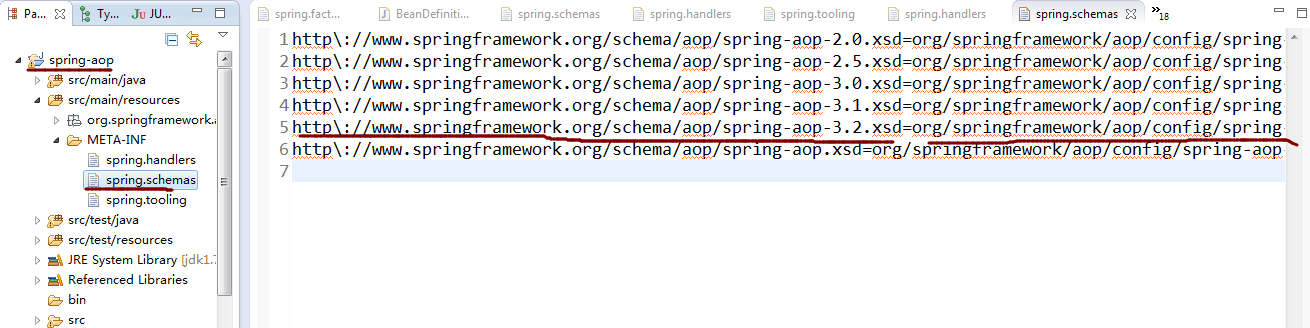
从中可以看到http://www.springframework.org/schema/aop/spring-aop-3.2.xsd对应着一个路径,在这个路径我们可以找到对应的xsd文件,所以,在解析该标签的时候spring会更具schemas文件下面对应的路径去找这个校验文件,如果实在是没有找到的话它才回去网上下载然后再执行校验。
确定XML的解析模式
spring的配置文件已经写好了,spring启动的时候,它究竟是如何确定spring使用的是哪种xml验证模式呢,是DTD还是XSD,下面我们先通过时序图看看spring在判断验证模式的实现
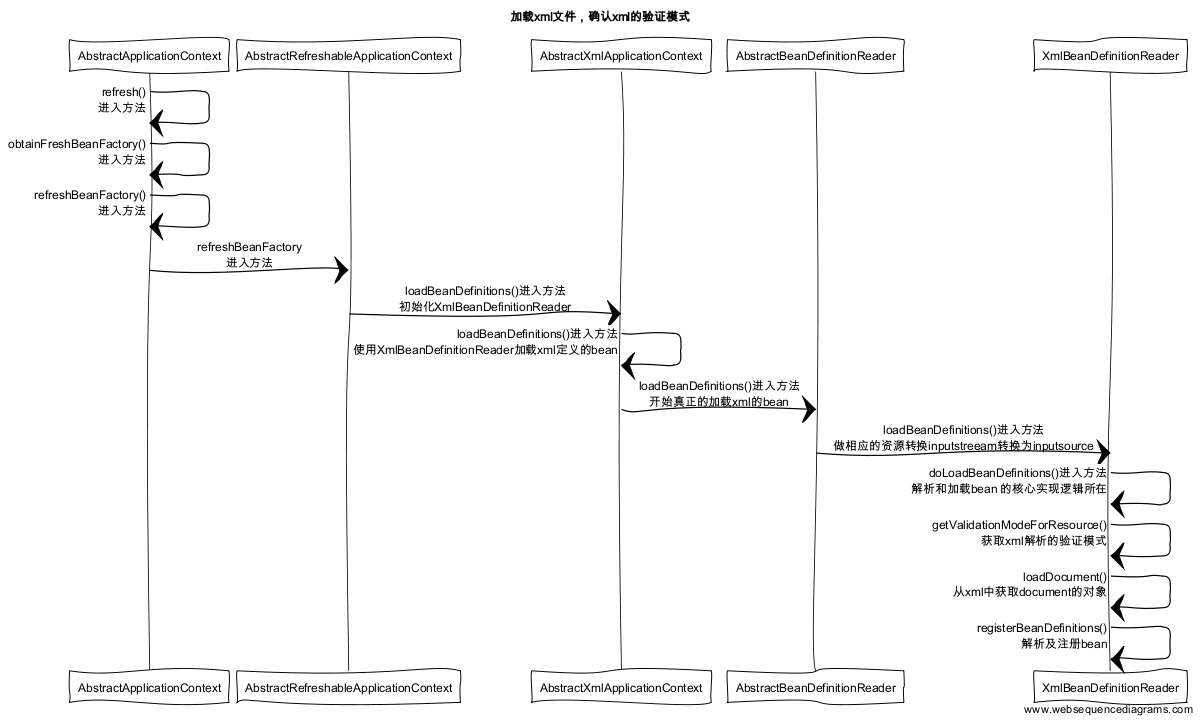
图1
绕了那么多个方法,我们终于看到获取xml验证模式的获取了,是不是觉得很蛋疼,说实话,要不是画了时序图我也不知道这绕了那么远。好了,让我们先看看它的核心实现代码吧
protected int getValidationModeForResource(Resource resource) {
int validationModeToUse = getValidationMode();
//如果是手动指定了验证模式,那么就使用手动指定的验证模式
if (validationModeToUse != VALIDATION_AUTO) {
return validationModeToUse;
}
//如果未指定,那么就自动检测验证模式
int detectedMode = detectValidationMode(resource);
if (detectedMode != VALIDATION_AUTO) {
return detectedMode;
}
// Hmm, we didn't get a clear indication... Let's assume XSD,
// since apparently no DTD declaration has been found up until
// detection stopped (before finding the document's root tag).
return VALIDATION_XSD;
}加载xml文档
确定好,文档的解析模式后,下面的话便调用loadDocument方法对xml文档进行加载。对于xml文档的加载spring采用的还是javax.xml.parsers.DocumentBuilderFactory下面的DocumentBuilder去解析inputsource,返回document对象。
那么解析的时候是怎么获取验证文件的呢。在文章的前面有说过如果本地有验证文件那么就从本地获取验证文件,如果本地没有验证文件才去网上下载验证文件,那么这是怎么实现的呢?
其实这关键就在于EntityResolver这个类。何为EntityResolver,官方是这样解释的:如果SAX应用程序需要实现自定义处理外部尸体,则必须实现此接口并使用setEntityResolver方法向SAX驱动器注册一个实例,也就是说对于解析一个xmlSAX首先读取该XML文档的声明,根据声明去找相应的DTD或者XSD定义,然后根据DTD或者XSD对文档进行一个验证。
在spring里面用DelegatingEntityResolver实现了EntityResolver类,并在解析的时候会根据要获取的解析文件URL先去本地找对应的验证文件,DTD文件是在当前路径下去找,XSD文件统一是从META-INF/Spring.schemas文件中去找对应的本都验证文件。
解析并注册BeanDefinitions
让我们继续doLoadBeanDefinitions方法的执行,先看看解析注册beandefinitions的时序图
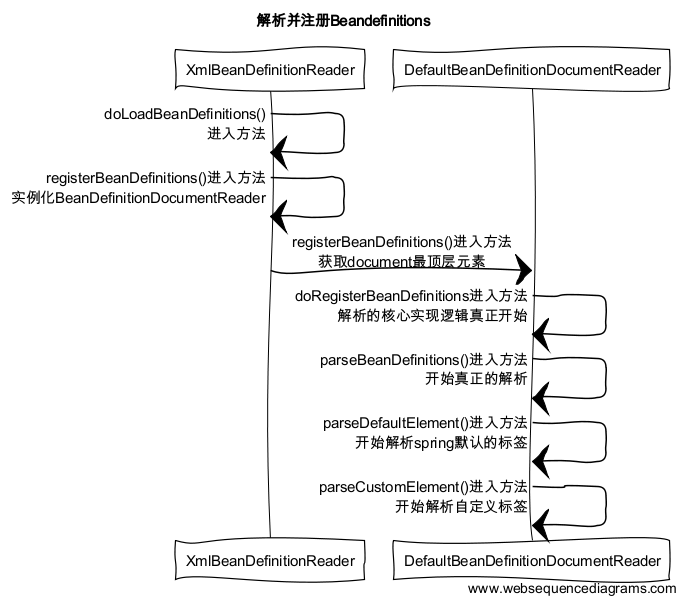
图2
1)spring有4种不同的默认标签,分别是import,alias,bean,beans,这四种标签的解析统一是由parseDefaultElement方法完成。
2)自定义的标签,像aop标签,是由parseCustomElement方法完成的。
默认标签解析
让我们来先看看spring是如何解析默认的标签的,先看parseDefaultElement方法的内容:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
//对import标签的解析
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
//对alias标签的解析
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
//对bean标签的解析
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
//对beans标签的解析
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}
先上DefaultBeanDefinitionDocumentReader类的processBeanDefinition方法:
/**
* Process the given bean element, parsing the bean definition
* and registering it with the registry.
*/
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
2)当返回的bdHolder不为空的情况下,若存在默认标签的子节点下再有自定义属性,还需要再次对自定义标签进行解析,也就是调用decorateBeanDefinitionIfRequired方法
3)解析完成后,需要对解析之后的bdHolder进行注册,同样,注册操作委托给了BeanDefinitionReaderUtils的registerBeanDefinition方法。
4)最后发出响应事件,通知相关的监听器,这个bean已经加载完成了。
下面让我看看parseBeanDefinitionElement方法的实现:
/**
* Parses the supplied {@code <bean>} element. May return {@code null}
* if there were errors during parse. Errors are reported to the
* {@link org.springframework.beans.factory.parsing.ProblemReporter}.
*/
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) {
//获取id属性
id = ele.getAttribute(ID_ATTRIBUTE);
//获取name属性
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
//分割name属性
List<String> aliases = new ArrayList<String>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
//解析bean的属性和元素,并分装成GeneicBeanDefinition中(GeneicBeanDefinition是AbstractBeanDefinition实现类)
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
//如果不存在beanName,则使用默认的规则创建beanName
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}解析的核心逻辑由parseBeanDefinitionElement方法实现,让我们看看parseBeanDefinitionElement方法到底为我们做了哪些操作。
1)提取元素中的id和name属性
2)进一步解析bean中其他所有的属性,这些属性包含scope、singleton、abstract、lazy-init、autowire、dependency-check、depends-on、autowire-candidate、primary、init-method、destroy-method、factory-method、factory-bean。并且解析bean下面所有的元素,其中包含:meta、lookup-method、replace-method、constructor-arg、property、qualifier。解析完成这些属性和元素之后(元素和属性很多,所以这是一个庞大的工作量),统一封装到GeneicBeanDefinition类型的实例中。
3)如果检测到bean没有指定的beanName,那么便使用默认的规则为bean生成一个beanName。
4)将获取到的信息封装到BeanDeinitionHolder里面去。
自定义标签的解析
关于自定义标签的解析流程的话我的博客也有介绍,这里就不重复介绍了,想温习一下的朋友可以去看看,
spring源码剖析(四)自定义标签解析流程。
注册BeanDefinition
让我们回到processBeanDefinition方法,找到beanDefinition的注册的方法BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());让我们来看看里面的详细实现:
/**
* Register the given bean definition with the given bean factory.
* @param definitionHolder the bean definition including name and aliases
* @param registry the bean factory to register with
* @throws BeanDefinitionStoreException if registration failed
*/
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String aliase : aliases) {
registry.registerAlias(beanName, aliase);
}
}
}通过上面可以看出,解完之后的beandefinition都会被注册到BeanDefinitionRegistry里面去,其中BeanDefinition的注册分两部分,一种是通过beanName注册,一种是通过别名aliase注册。
通过beanName注册BeanDefinition
通过beanName注册BeanDefinition Spring究竟做了哪些事情呢,让我们来看看:
//---------------------------------------------------------------------
// Implementation of BeanDefinitionRegistry interface
//---------------------------------------------------------------------
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition oldBeanDefinition;
synchronized (this.beanDefinitionMap) {
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!this.allowBeanDefinitionOverriding) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
else {
if (this.logger.isInfoEnabled()) {
this.logger.info("Overriding bean definition for bean '" + beanName +
"': replacing [" + oldBeanDefinition + "] with [" + beanDefinition + "]");
}
}
}
else {
this.beanDefinitionNames.add(beanName);
this.frozenBeanDefinitionNames = null;
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
if (oldBeanDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
}
1)对AbstractBeanDefinition进行校验。在解析XML文件的时候我们进行过校验,之前是对XML格式的校验,现在做的校验是对AbstractBeanDefinition的MethodOverrides的校验
2)对beanName已经注册的情况做处理,如果设置了不允许覆盖bean,那么会直接抛出异常,否则是直接覆盖
3)加入map缓存
4)清楚解析之前留下的beanName的缓存。
通过别名alias注册BeanDefinition
首先我们看具体的代码实现:
public void registerAlias(String name, String alias) {
Assert.hasText(name, "'name' must not be empty");
Assert.hasText(alias, "'alias' must not be empty");
if (alias.equals(name)) {
this.aliasMap.remove(alias);
}
else {
if (!allowAliasOverriding()) {
String registeredName = this.aliasMap.get(alias);
if (registeredName != null && !registeredName.equals(name)) {
throw new IllegalStateException("Cannot register alias '" + alias + "' for name '" +
name + "': It is already registered for name '" + registeredName + "'.");
}
}
checkForAliasCircle(name, alias);
this.aliasMap.put(alias, name);
}
}1)alias和beanName名字一样的情况处理,如果是名字一样,那么直接删除别名。
2)alias覆盖处理。若aliasName已经指向了另一beanName则需要用户的设置进行处理。
3)alias循环检查。当A->B存在时候,如果出现了A->C->B那么直接抛出异常。
4)注册alias
通知监听器解析注册已完成
让我们回顾下processBeanDefinition方法,里面有说到,当bean注册完成之后便会调用getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));这里便提供了途径给开发人员对bean完成注册之后进行相应的拓展,目前Spring里面是空实现。
总结
上面只对spring的bean标签的解析做了说明,其他的默认标签,像import,alias,beans标签,其实解析的方式大同小异,如果想探个究竟的朋友也可以跟着程序源代码走上几遍。
spring默认的标签的解析及注册的大体逻辑就这样,其实认真阅读过源码的同学,很容易理解里面的逻辑,看起来复杂,其实也不是很难,不过有一点可以认同的是,spring的源代码写的的确很严谨,值得我们去学习。















 2109
2109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









