






目录
RCU 的基本概念
RCU,read-copy-update,也就是读-拷贝-更新,其基本思想在于,当我们需要对一个共享数据进行操作的时候,我们可以先复制一份原有的数据 B,将需要更新的部分在 B 上实现,然后再使用 B 替换掉 A,这也是 RCU 最典型的使用场景。
很显然,这种无锁方案所针对的是 "共享" 这个特性,毕竟并不直接对目标数据进行操作。
从这个理念出发,其实我们可以非常直观地感受到 RCU 的第一个特点:RCU 是针对多读少写的使用场景的,毕竟这种形式的实现明显加大了写端的开销。
RCU 的设计理念简单到任何人在第一次听到时就能够理解它,但是当我们尝试像 spinlock 那样通过它的 lock/unlock 接口来阅读它的代码实现时,居然惊奇地发现它的 lock/unlock 实现仅仅只是开关一下抢占,在多次确认内核配置没有问题之后,发现事实确实是如此,从而产生一种很荒谬的感觉:仅仅通过开关抢占是怎么实现读-拷贝-更新的?
RCU 实现的核心问题是什么?
很多对 RCU 感兴趣的朋友其实在网上也看过不少 RCU 相关的文章,知道了 RCU 的操作形式:读-拷贝-更新,并自然而然地觉得这是个很好的想法,而且它好像确实不需要锁来实现,因为更新操作和原本读者读到的是不同的数据,不满足共享的条件,随后再执行替换就好了。而且,这三个操作步骤完全就可以由使用者自己完成,实在是想不到有什么地方需要操作系统来插手的。
如果一个问题想不明白,那么我们就代入到真实的场景下来考虑这个问题:假设现在有 3 个读者和 1 个更新者需要对共享数据进行访问,读者不间断地对数据发起读操作,而更新者需要更新时,拷贝出一份新的数据,操作完之后然后再替换旧的数据,这样就完成了数据的更新,而读者就可以读到新的数据。
看起来非常合理,效率也很高,但是这里有一个最大的问题在于,我们默认了一个并不存在的前提条件:新数据的替换立马就对所有的读者生效,替换之后就可以立刻删除旧数据,而读者也可以立刻读到新的数据。
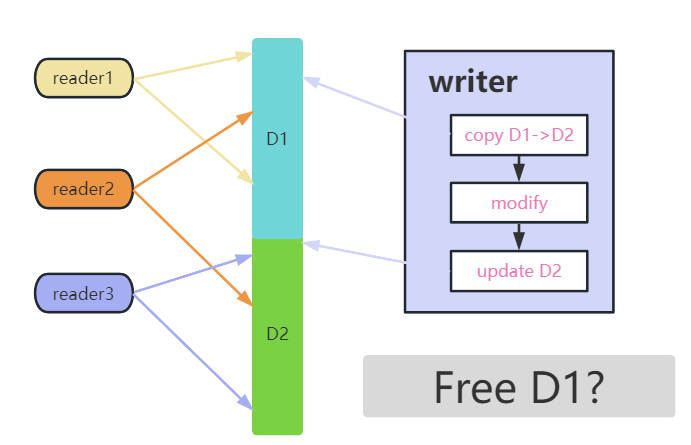
我们可以通过上图来了解这个流程,其中存在三个读者,读者的两个箭头标定读操作的开始点和结束点,中间的表示共享数据。
从图中可以看到,writer 先是从 D1 copy 出一份 D2,接着对D2 执行修改,紧接着将 D2 更新为新的共享数据,这个过程就可以理解为一次 Read-Copy-Update 操作。
而在整个过程中,reader1 始终读到 D1 数据,而reader3 始终读到 D2 的新数据,但是 reader2 就比较麻烦了,它的读操作跨越了 D1 到 D2 的更新过程,那么它读到的是 D1 还是 D2,又或者说读到一半 D1 的数据和另一半 D2 的数据?
按照传统的同步锁做法,这时候需要写者等所有旧读者退出,然后读者等待写者更新完,才继续进读临界区,对应上图就是 writer 必须等 reader2 先读完再执行更新。你有没有意识到,写者等读者退出,读者再等写者更新完,这个操作实际上就是 rwlock 的实现,难道 RCU 操作要基于 rwlock 来实现?那为什么我不直接使用 rwlock 呢?显然让替换立刻生效来实现 RCU 的方式,只能说你创造了一个新的同步机制,但它永远也不会有人用。
那么为了能超过 rwlock 的性能,一方面不能做读者与写者之间的锁同步,从而让 RCU 能在特定场景下有性能优势,另一方面,如果不做锁同步,那就意味着读者不知道写者什么时候更新,写者也不知道更新时是否存在读者,唯一的方案是:即使 writer 在更新完之后,reader2 读取的依旧是 D1 的旧数据(因为 reader2 不知道数据有更新),而更新完之后新来的读者读到的自然是新数据。
在这种情况下,也就意味着 RCU 不能像普通锁一样保护复合结构的实例,而只能是针对指向动态资源的数据指针,稍微深入地想一想,就能发现,如果D1 和 D2是同一个结构实例,D2 会覆盖掉 D1 的数据,就会产生reader2 读到一半D1,更新后读到另一半D2的错误结果。而如果在更新完之后reader2依旧需要能够读取到 D1,那D1和D2必须是独立的两片内存。
之前的问题是如何处理跨越更新点的读者,在确定这类读者依旧读取旧数据之后,现在剩下的问题变成了:判断什么时候这些读者读完了旧数据,从而可以回收旧数据的资源?
这就是内核中 RCU 实现所需要解决的问题:如何低成本地实现等待依旧正在访问旧数据的读者退出?而读-拷贝-更新操作,完全可以留给用户自己做,所以,RCU 在内核中的实现实际上并不是 Read-Copy-Update 操作,而是实现一种等待读者退出临界区的机制。
同时,由于通常情况下,RCU 等待所有旧读者退出之后,主要的操作就是释放旧数据,所以它的实现也很像一种垃圾回收机制。
结合上面的两点问题,也就引出 RCU 的另外几个特点:
-
即使是在写者更新完之后,依旧允许读者读到旧数据。而内核的 RCU 实现需要保证所有能读到旧数据的 RCU 退出,才删除旧数据。
-
RCU 同步机制所保护的对象不能直接是复合结构,只能保护动态分配数据对应的指针
-
追求读端的极限性能,这是 RCU 在内核中的立足之本。
如果我上一小节已经将 RCU 在内核中实现的逻辑表达清楚,且你也已经看明白,那下一步需要讨论的就是:如何低成本地实现等待旧的读者退出临界区。也就是从现在开始,我们才真正进入到 RCU 的实现中。
等待一件事情结束,最常用的也是容易想到的解决方案就是在开始的时候做一个标记,凭票入场,出场退票,这样只需要通过判断出入的记录是否成对就能判断是否还存在没有退出者,当然,这个想法在上面已经被证实效率过低,记录读端的起始意味着需要执行全局的写操作,而读端临界区一旦需要执行全局的写操作,在多核上并发时就会产生同步问题,这并不好解决,而且开销并不小,当然这个全局写操作可以换成 percpu 类型的,从而减少一些性能的损失,不过这种方式总归是治标不治本,而我们的理想状态是读端没有同步开销,也就是不记录读临界区的进入。
另一个思路是,我们是否可以借用其它的事件来完成这个等待操作?也就是说是否能通过一些既有事件来判断我们需要等待的条件已经满足,而不需要进行针对该事件直接的记录行为。
在内核中,RCU 的实现就使用了一种非常巧妙的方式:简单地通过关-开抢占来实现一个读临界区,读者进入临界区将会关抢占,而退出临界区时再将抢占打开,而进程的调度只会在抢占开的时候发生,因此,写者等待之前所有的读者退出,只需要等待所有 cpu 上都执行完一次调度就行了。
这里有必要进一步解释一下,上一段文字中非常重要的几个字是:之前所有的读者。
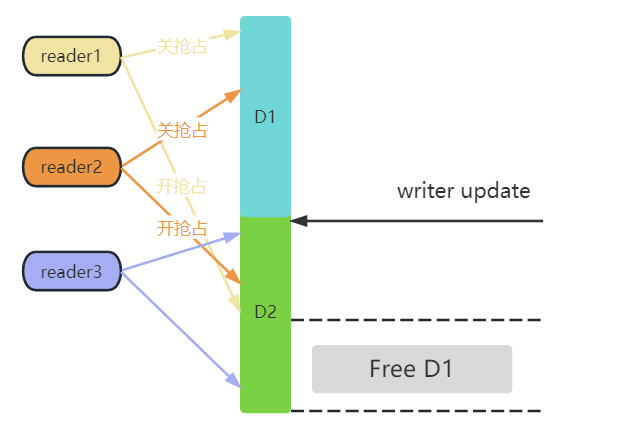
参考上图,在writer更新之前,reader1 和 reader2 依旧引用的是 D1 数据,而 reader3 已经读取到新的数据了,所以只需要等待 reader1 和 reader2 完成读操作,就可以释放 D1 了。
而在 reader1 整个读的过程中,是处于关抢占的状态,如果 reader1 运行在 cpu0 上,那 writer 更新完之后,只需要判断 cpu0 上一旦发生了调度,就能判断 reader1 已经退出临界区,毕竟发生调度的前提是 cpu0 上开了抢占,也就意味着 reader1 已经读完了。
而更新者更新完数据之后,等待所有读者退出临界区这个过程,被命名为宽限期(grance period),也就是宽限期一过,也就意味着数据的更新以及所有读者退出这个过程已经完成,这时候就可以释放旧数据了,如果是单纯的 add 操作,那自然就不需要删除旧数据,只需要确认更新已经完成就好。
当然,等待所有之前的读者退出临界区这个过程可能会比较长,甚至到几十毫秒。因此,在决定是否使用 RCU 作为同步之前需要考虑到这一点。
这也就引出 RCU 的另外两个特点:
-
Linux 实现下的RCU 读端临界区就是通过关-开抢占来实现的,性能以及多核扩展性非常好,但是很明显读端临界区不支持抢占和睡眠。
-
写端具有一定的延迟。读端在一定的时间周期内会获取到新或者旧数据。
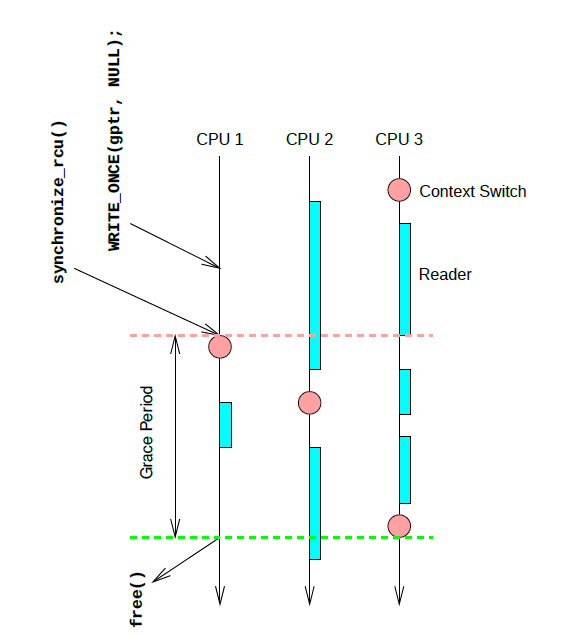
上图是一个简单的示例,更新端在 CPU1 上对 gptr 执行了置 NULL 操作,然后调用 synchronize_rcu 阻塞等待所有之前的读者退出临界区,synchronize_rcu 会立刻触发一次调度,接着 CPU2 上在执行完浅蓝长条对应的读端临界区之后,执行了一次调度,同时也意味着 CPU2 已经渡过了临界区,而在 CPU3 上,实际上经历了三次进入-退出读临界区的阶段,但是因为没有触发进程切换,RCU core 是无法判断 CPU3 渡过了临界区的,直到最后 CPU3 执行了一次调度,整个系统也就渡过了一个完整的宽限期,CPU1 上阻塞的 task 得以继续运行,free 对应的内存。
RCU 的特点
同时,再整体总结一下 RCU 的特点:
-
RCU 是针对多读少写的使用场景
-
写端具有一定的延迟。读端在一定的时间周期内会获取到新或者旧数据
-
即使是在写者更新完之后,依旧允许读者读到旧数据。而内核的 RCU 实现需要保证所有能读到旧数据的读者退出,才删除旧数据
-
RCU 同步机制所保护的对象不能直接是复合结构,只能是指针
-
RCU 追求读端的极限性能,这是 RCU 在内核中的立足之本
-
Linux 实现下的经典RCU 读端临界区就是通过关-开抢占来实现的,性能以及多核扩展性非常好,但是很明显读端临界区不支持抢占和睡眠















 3180
3180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









