






如有错误地方 还请各位老师多多指正。。。。
其实我对多线程挺感兴趣的,当时兴趣的产生就是因为听说”难” 。 所以平时有事没事也会扩展一些多线程知识,或者是温习一下学过都知识。
在很早以前,就发现多线程已经嵌入到了我们tomcat容器中,当有用户访问的时候就会产生一条线程去执行该用户的操作。而不需要我们手动编写代码,觉得有些无趣。
而在最近做TailorX项目代码优化的时候,发现一个对我们初级来说很重要的问题 : 因为缺少需求文档的文字说明,本来就对项目逻辑不太熟,只能够从看前人的代码入手,而我们常常跟着前人代码逻辑流程走,从而忽视了逻辑上可优化的地方。
只能改一些代码中比较明显的代码点。 而在网上,对于java代码的优化无非就是说一些规范,或者说是良好的编码习惯,对于逻辑只能自己梳理了。其实有时候我宁愿自己根据自己的逻辑重新写,也不愿意看着前人的代码进行修改。
而对于mysql的优化却都是一些语句优化和表结构的修改。表结构就别想了,这肯定不能随便动。
在周末的时候,突然就想到,我在DAO层进行查询分页列表和数据记录总数的时候,我能不能使用多线程去解决呢?
反正这两者可以说是完全独立分开的,互不影响。 打定了主意 今天一上班就开始一边思考 一边测试了 。
首先是想到了使用线程池,为什么要用线程池呢? 因为如果单独的就是建立线程, 线程销毁。 这样的方式执行。 那么毫无疑问,提高的一点性能或许还没有创建和销毁线程耗费的资源多。
在使用线程池,我可以将线程池使用java类进行配置 并注入到spring容器中, 对项目中任何需要使用到线程的地方,使用@Autowide 进行注入获取。而在此 我就开始进行代码的编写和测试了 。。。 使用的是可缓存线程池,线程任务使用的是Callable(可返回任务结果的线程任务)。
private ExecutorService executors = Executors.newCachedThreadPool(); //首先是手动创建了一个可缓存线程池,这里并没有使用创建批量执行任务的线程池,因为我当前这个地方 只需要线程执行一个任务,主线程执行一个就够了。
new ExecutorCompletionService<String>(ExecutorService) //这里多提一个 这里是在创建支持批量执行可返回值任务的线程,这个构造函数是使用了装饰者模式,将需要装饰的实例传入为它增加一些本没有的代码,就是加强功能啦。
我没看这个类的源码,但是看到他在获取返回值的时候有一个take()方法,就能够猜到它底层应该是将每个任务的返回值存入了队列中,按照先进先出的原则进行获取。
//该任务执行的返回值类型就是Future对象,主线程可以调用该对象的get方法进行获取,但是如果线程任务没有结束,那该线程也会一直阻塞。注意一点就是不要刚刚执行了这个代码就离开get()方法,因为会阻塞线程,这时候主线程可以执行另外的任务,当任务结束了再get().
Future<Integer> future= executors.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
// TODO Auto-generated method stub
return jdbcTemplate.queryForObject("SELECT count(1) FROM t_order_category " + whereSql.toString(),
param1, Integer.class);
}
});
对了 使用的时候注意一下线程安全问题,1.使用线程安全的实例 2.或者为每个线程创建单独的副本 。 我在优化测试的时候就犯了一个错误 ,没有注意到param这个List参数集合。 当我第一个线程在使用的时候,主线程竟然在对其做修改。 最后报了SQL异常,参数角标越界。
当时因为没注意到 , 还以为使用的jdbcTemplate类中的角标计数器不是线程安全的呢?后来略微思考,我们所有的DAO都使用的一个单例的jdbcTemplate啊。 所以后来问题也是顺理找到了 也解决了 。
在这个使用线程去分开执行sql代码,效率的确会提高,但是也会有些弊端。 它会占用额外的连接池资源,和增加一个线程池。这对我们的硬件设施也就增加了要求。 当然 , 任何事其实都有两面性,想要效率 必然对硬件要求提高,要代码易读 那么性能也会降低,要单纯的效率,那么易读性就差。 就好像一个语句全是方法嵌套方法的返回值,而不定义一个变量来接收,只是变量名可以大概告诉我们这tm返回的到底是个什么东西。
我在此也就是提供了一个思路,只要环境支撑,用线程不出问题,能增加性能,那么在任何时候其实都可以做适当的考虑。
为了代码完整 这个简单的 获取也附上吧
try {
totalCount = future.get();
} catch (InterruptedException | ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
这两张图片,只是单单对一个DAO方法的sql语句查询做了分离执行 。 效率的提升也是显而易见的。 为了准确,我这里都是查询了八次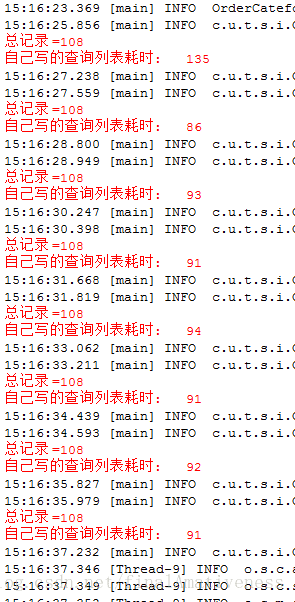














 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









