







针对 hashmap 面试题网上也是一坨坨五花八门的答案,在面试的过程中啊,我们除了要征服面试官,秀出我们的技术功底,其实也是面试者之间的 PK,面十进一,甚至几十进一,那你要如何成为最优秀的那一个拿下 offer。小白误闯,年后想跳槽进大厂的,一定好看完。
如何破解烂大街的HashMap面试题?
怎样的解题思路才能 PK 掉其他竞争者?
网上答案一大堆,怎么突出你的过人之处?
互联网大厂关于HashMap的面试题
互联网大厂必问题 :BATJ / TMD

HashMap是一个数据结构问题,可以从HashMap的底层数据结构进行分析;建议从多个不同jdk版本进行分析;容易被忽略的坑:分析片面,没有深入。
先从 HashMap 的版本入手,分析JDK 1.8之前与之后的区别,重点放在1.8版本的改进上,涉及的问题包括HashMap的数据插入原理,HashMap怎么设定初始容量大小?HashMap的哈希函数设计,1.8对hash函数做了优化,1.8还有别的优化?线程安全及怎么解决,ConcurrentHashMap的分段锁,链表转红黑树的阈值问题,CAS 的实现原理,Hash冲突等等。
面试开始。。。。
面试官:说说对HashMap的理解吧。
这是一个开放性问题啊,面试官绝对是套路满满,一定是对自己的技术非常自信的那种,想通过你所了解的东西入手,看你理解到什么程度。
面试者可以从HashMap的存储结构开始切入,当然,表达的时候是没有图的,需要理解后描述出来。
JDK1.8之前 JDK1.8之后
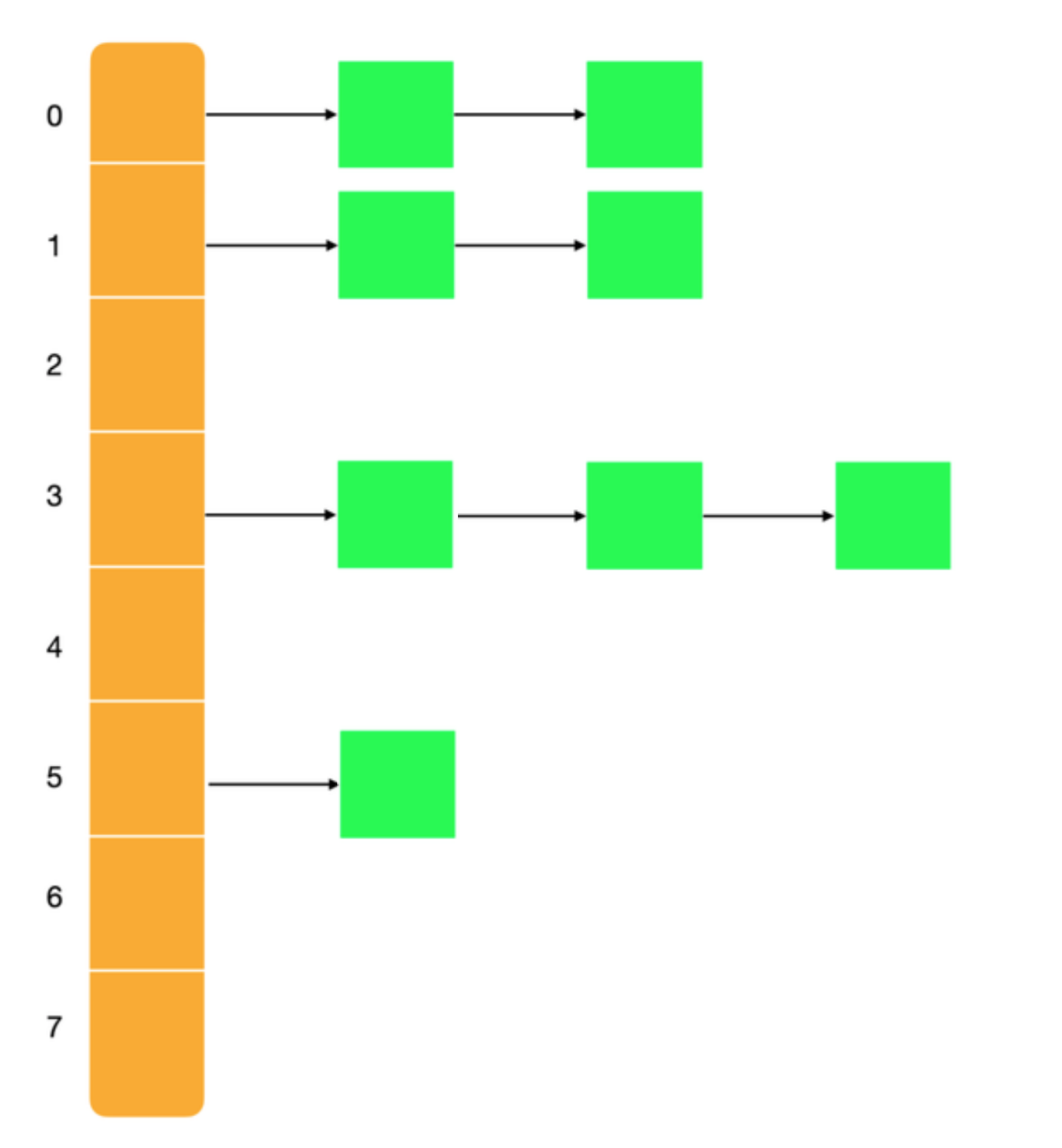
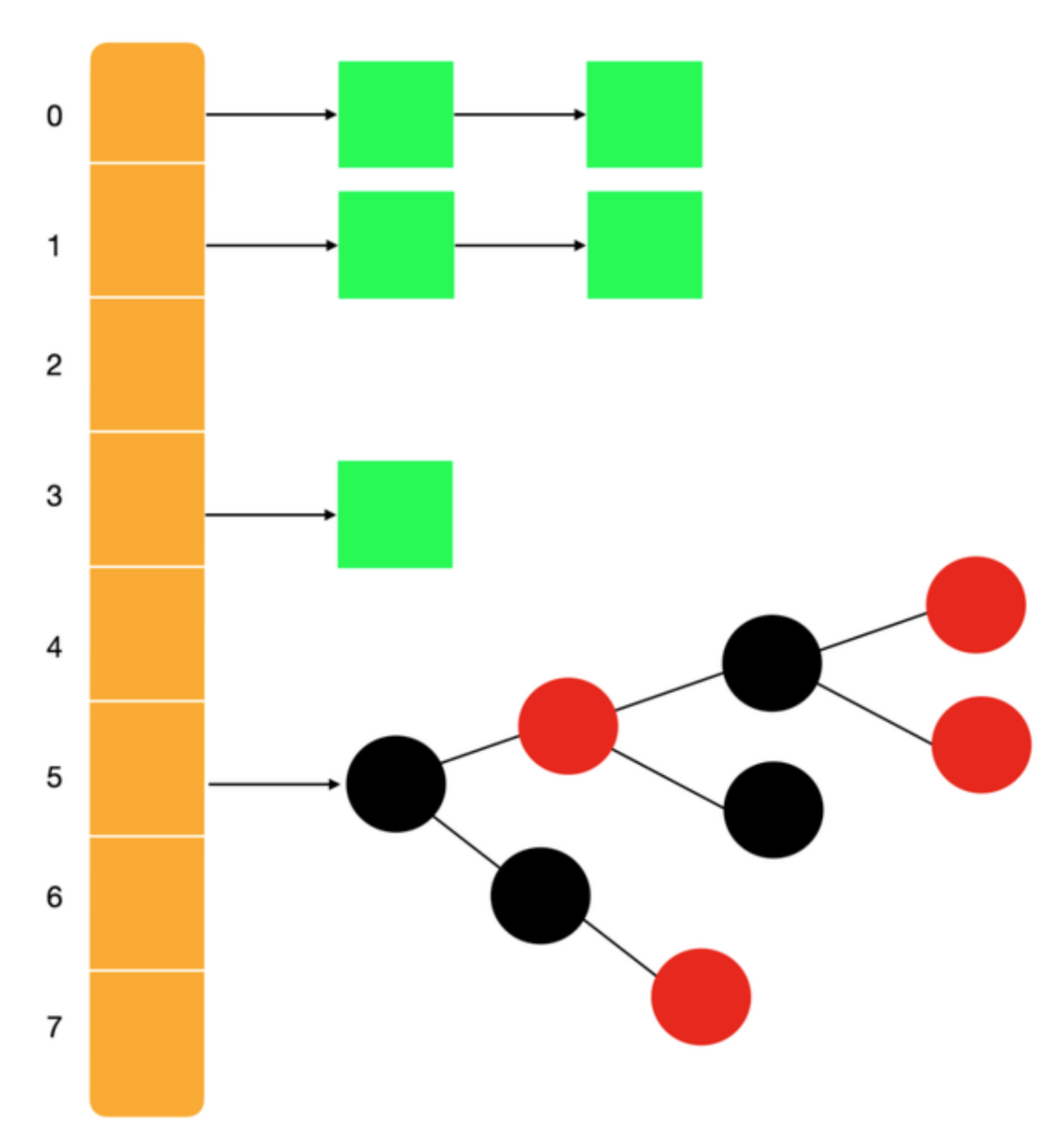
JDK1.8之前,HashMap的存储结构是数组+链表,JDK1.8之后则采用数组+链表或红黑树,引入红黑树的存储结构的目的就是避免链表过长的情况下,影响查询效率。
面试官:HashMap的数据插入原理是怎样的
面试者:如果你能按以下思路回答,堪称完美!
- 先判断数组是否为空,为空进行初始化;
- 不为空,计算 k 的 hash 值,通过(n - 1) & hash计算应当存放在数组中的下标 index;
- 查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
- 存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
- 如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创建树型节点插入红黑树中;(如果当前节点是树型节点证明当前已经是红黑树了);
- 如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8并且数组长度是不是大于64,大于的话链表转换为红黑树;
- 插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
以上7个步骤,不一定完全死记硬背,咱也背不下来,因此威哥的逻辑还是基于理解本质。
面试官:HashMap怎么设定初始容量大小?
面试者:一般如果new HashMap()不传值,默认大小是16,负载因子是0.75,如果自己传入初始大小k,初始化大小为大于k的 2的整数次方,例如如果传10,大小为16。
HashMap类源码截图:

补充说明:下图是详细过程,算法就是让初始二进制右移1,2,4,8,16位,分别与自己位或,把高位第一个为1的数通过不断右移,把高位为1的后面全变为1,最后再进行+1操作,例如:初始化 new HashMap(50),实际的大小是64,2的6次方=64。

面试官:HashMap的哈希函数设计是怎样的?
面试者:hash函数是先拿到 key 的hashcode,是一个32位的int值,然后让hashcode的高16位和低16位进行异或操作,看看代码如何实现的。

这么设计有二点原因:
- 一定要尽可能降低hash碰撞,越分散越好;
- 算法一定要尽可能高效,因为这是高频操作, 因此采用位运算;
我们知道一个好的 哈希算法能够使得元素分布的更加均匀,从而减少哈希冲突。HashMap 在这块的处理就很巧妙:
首先第一步取得 hashCode,该方法是一个用native修饰的本地方法,返回的是一个 int 类型的值(根据内存地址换算出来的一个值),通常我们都会重写该方法。
第二步将取得的哈希值无符号右移16位,高位补0。并与前面第一步获得的hash码进行按位异或^ 运算。这样做有什么用呢?这其实也是扰动函数,为了降低哈希码的冲突。右位移16位,正好是32bit的一半,高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。也就是保证考虑到高低Bit位都参与到Hash的计算中。
可以看看JDK1.7中,其实是做了4次扰动,在JDK1.8中只做了一次,我猜测是为了在降低冲突的同时保证效率。
与运算: 两位同时为“1”,结果才为“1”,否则为0
异或运算:相同时为0,不同则为1”




面试官:1.8还有别的优化吗?
面试者:
- 数组+链表改成了数组+链表或红黑树;
- 链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将
新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表,将元素放置到链表的最后; - 扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断
逻辑,位置不变或索引+旧容量大小; - 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
面试官: 你分别跟我讲讲为什么要做这几点优化;
优化目的:
- 防止发生hash冲突,链表长度过长,将时间复杂度由O(n)降为O(logn);
- 因为1.7头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环;A线程在插入节点B,B线程也在插入,遇到容量不够开始扩容,重新hash,放置元素,采用头插法,后遍历到的B节点放入了头部,这样形成了环
- 扩容的时候为什么1.8 不用重新hash就可以直接定位原节点在新数据的位置呢?这是由于扩容是扩大为原数组大小的2倍,用于计算数组位置的掩码仅仅只是高位多了一个1,怎么理解呢?扩容前长度为16,用于计算(n-1) & hash 的二进制n-1为0000 1111,扩容为32后的二进制就高位多了1,为0001 1111。因为是& 运算,1和任何数 & 都是它本身,那就分二种情况,原数据hashcode高位第4位为0和高位为1的情况;第四位高位为0,重新hash数值不变,第四位为1,重新hash数值比原来大16(旧数组的容量)
面试官:扩容的时候为什么1.8 不用重新hash就可以直接定位原节点在新数据的位置呢?
(靠,果然是遇到高手了,问得那么细)
面试者:其中一个重要的优化即在扩容的时候,原有数组里的数据迁移到新数组里不需要重新hash,而是采用一种巧妙的方法。
看源码:
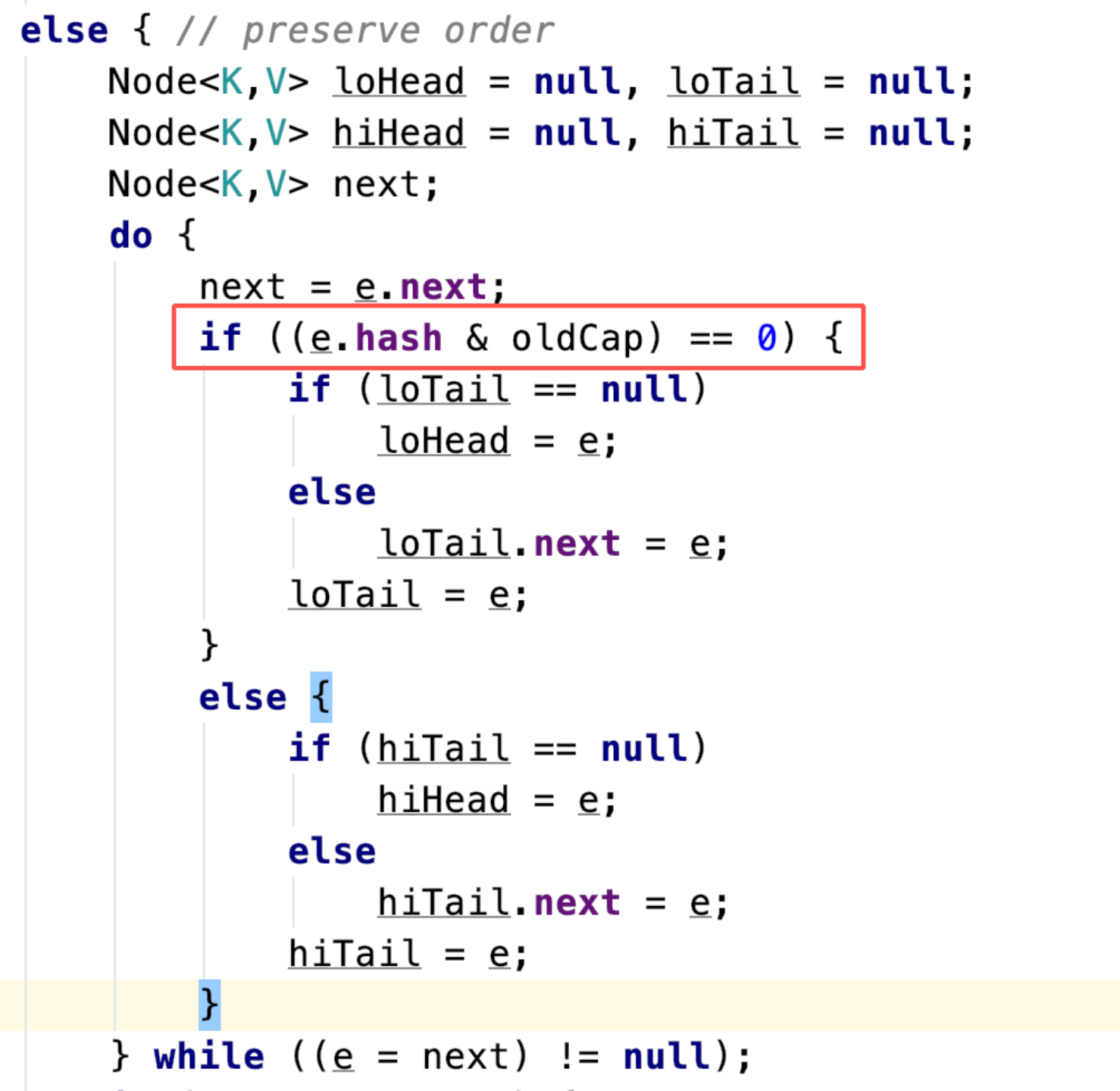
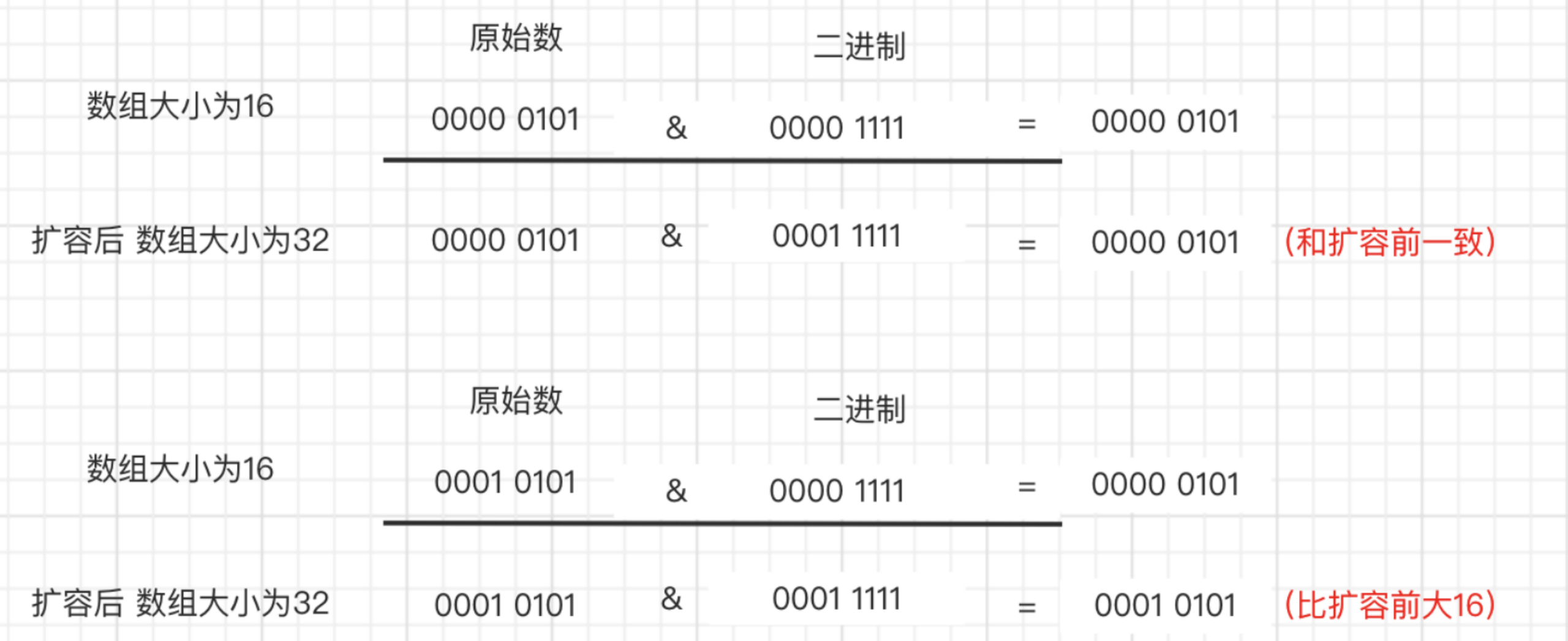
可以看到它是通过将数据的hash与扩容前的长度进行与操作,根据结果为0还是不为0来做对应的处理e.hash & oldCap。举个例子比如数据 A它经过hash之后的值为 0111(二进制),一开始map中数组的长度是 8,根据定位的逻辑 (n-1)&hash,那么数据A的位置是:
(n-1)&hash = (8-1) & 0111 = 111 & 0111 = 0111
扩容之后数组长度是原来的2倍,即16,假设我们重新算一遍A的位置,那么应该是:
(n-1)&hash =(16-1) & 0111 = 1111 & 0111 = 0111
可以看到数据A扩容之后,如果重新计算hash的话,它的位置是没有发生变化的
面试官:那HashMap是线程安全的吗?怎么解决这个线程不安全的问题?
面试者:当然不是,ConcurrentHashMap使用分段锁,降低了锁粒度,让并发度大大提高。
1.7版本中,ConcurrentHashMap使用ReentrantLock+Segment+HashEntry实现,是通过减少锁粒度来削弱多线程和锁竞争的,JDK1.8 之后 ConcurrentHashMap取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。JDK1.8采用CAS+Synchronized保证线程安全。从锁的粒度方面:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
面试官:讲讲 CAS 是怎么保正线程安全的?
面试者:CAS(比较与交换,Compare and swap) 是一种无锁算法。
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
CAS是不是就是是完美的解决方案呢,当然不是,假设有一个变量 A ,修改为B,然后又修改为了 A,实际已经修改过了,但 CAS 可能无法感知,造成了不合理的值修改操作。这个称为A-->B-->A 问题。
如何解决呢,JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
完美!针对 HashMap 的连环 Call 到此告一段落了。
我们小结一下
面试官是如何层层展开提问的,面试者应该从哪里关联问题入手去充分备战面试:首先关于 HashMap,面试官从:数据结构、多线程安全、倒插法、位运算/二进制操作、扰动函数、hash碰撞等问题依次展开追问。面试者应该从哈希表数据结构1.8之前和之后的不同实现开启话题,从插入数据原理,怎么设定初始容量大小,哈希函数的设计,位运算,扩容机制,倒插法优化,线程安全问题等深入分析来回答面试官的问题。HashMap 是数据结构问题的典型代表,也是在项目应用中高频使用的数据结构,很多框架底层实现都采用 HashMap 来实现数据存储方案,充分理解 HashMap 不仅在面试中帮助很大,在实际开发中更能发挥作用。
















 2615
2615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











