






爬虫学习第三天,目前可运用 bs4+正则 爬取一些网页源码信息并进行提取
抱着练手的态度,想去学校官网爬数据找点乐子,从而引出了乱码问题

这些内容在网页中 Elements 查看,显示也是正常的文字 ,然而 request.get()请求后得到的却是火星文字
源代码如下

错误解析:pycharm内的编码方式与网页中的编码方式不同
解决方案:
一:查看原网页编码方式:以Edge为例
首先,确保你的浏览器中 Internet Explorer 模式是开启的 如图所示

进入你想要爬取数据的网站,在Edge中 点击 右上角 的 三个点 点击:在 Internet Explorer 模式下重新加载

开启后,在页面中右键-->编码 这时候你就可以看到该页面的编码模式 此网页为 ' utf-8 '
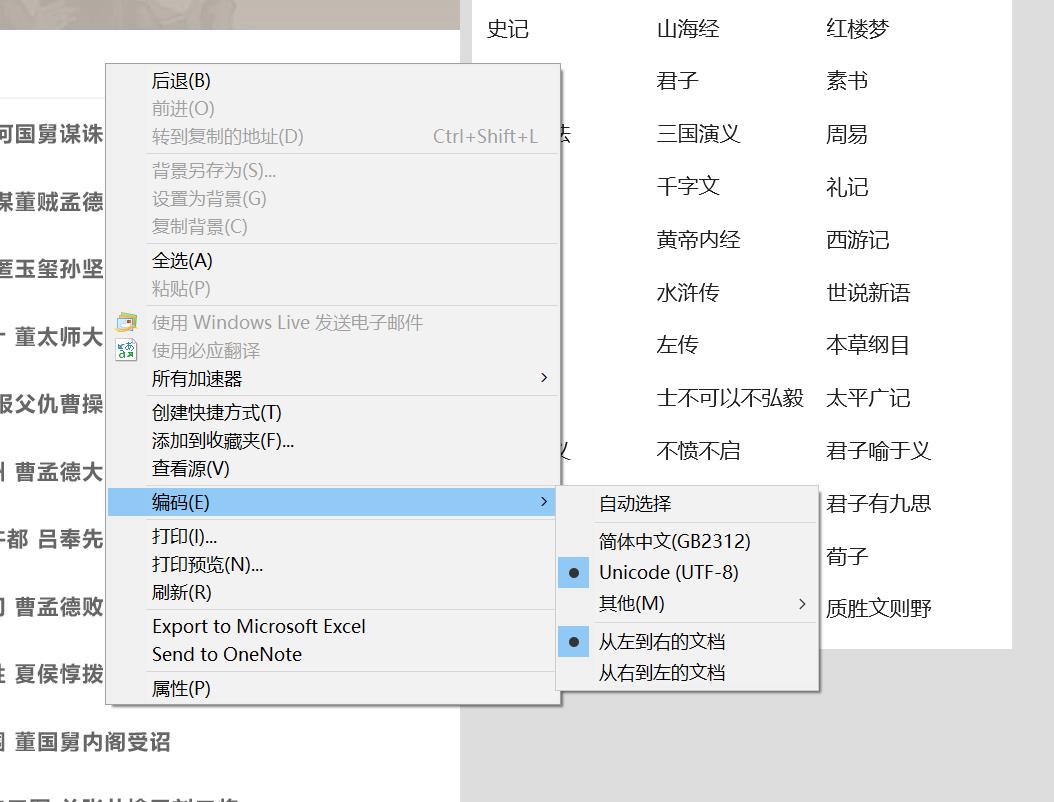
二:进入编译器 修改编码方式
修改前源代码如下

修改代码编码方式为 utf-8 ( 改为你刚查看的网页编码模式 )

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











