







文章目录
关于batch_size和learning_rate
1)因为NVIDIA底层的并行计算架构,一般的训练batch_size设为32和64是效果最好的~好像也有实验支持。
batch一般选取2^n,主要是为了符合计算机内部的计算;如果是训练GAN的话越大越好,biggan那篇paper有做过实验。
2) Batch_size不宜选的太小,太小了容易不收敛,或者需要经过很大的epoch才能收敛;也没必要选的太大,太大的话首先显存受不了,其次可能会因为迭代次数的减少而造成参数修正变的缓慢;
3)为什么增大batch_size后可以增大学习率而不发散?
当我们增加batch_size为原来的N倍时,要保证经过同样的样本后更新的权重相等,按照线性缩放规则,学习率应该增加为原来的N倍,但是如果要保证权重的方差不变,则学习率应该增加为原来的sqrt(N)倍;
交叉验证
交叉验证是为了防止过拟合
通常我们为了测试模型的性能,会划分训练集和测试集;
sklearn提供了附注函数train_test_split可以很快的将实验数据划分为任何训练集和测试集;可以自己参考文档实践一下from sklearn.model_selection import train_test_split
1、什么是交叉验证?
Cross Validation:简言之,就是进行多次train_test_split划分;每次划分时,在不同的数据集上进行训练、测试评估,从而得出一个评价结果。
2、交叉验证的好处?
充分利用有限的数据集,从中或得更多的有效信息,同时缓解过拟合;
3、交叉验证的方法
1)留一法,leave one out (LOOCV)
如果数据集有N条,留一法将数据集分成 N 份,然后 每次从中选取 一条样本 作为 测试,其他的作为 训练集,循环重复步骤 N 次,这种方法 的优点是能够 训练 n 个 不同的模型,
- 优点:
- 该方法是 循环 N 次选取,每一份数据集都可以作为 测试集 进行测试,所以 该方法 不受 划分方式 的 影响;
- 因为能够 循环 N 次训练,所以所有数据 都可以参与 模型训练;
- 缺点:
- 由于 要 循环 计算 N 次,所以 计算量过高;
2) K折交叉验证 K-fold cross Validation
将数据集划分为互斥的K个集合,用K-1个集合做训练,然后剩下的一个做验证。
脏数据处理------置信学习
实际生产过程中,标注的数据不可能100%正确,那些标注错误,标注歧义,对结果造成坏影响的样本称为脏数据;
1、脏数据如何处理
笨方法:
- 人工清洗? 【眼瞎】
- 重标? 【标注人员和平相处五项原则!!!】
- 自己改? 【外号 “算法工程师” 的 “标注工程师”?】
有没有什么好办法?
有!置信学习!
2、什么是置信学习?
置信学习方法 其实就是 计算 每一个样本的 标签的置信度,以识别标签错误、表征标签噪声并应用于带噪学习(noisy label learning)。【注:模型找出的置信度低的样本,并不一定就是错误样本,而只是一种不确定估计的选择方法】
举例说明:
- 在某些场景下,对训练集通过交叉验证来找出一些可能存在错误标注的样本,然后交给人工去纠正。
注意:置信学习的要求是你的数据集包含脏数据比例不可以太多,否则啥学习也没用了。置信学习发现的“可能错误样本”,这个只是相对的,因为模型找出的置信度低的样本,并不一定就是错误样本,而只是一种不确定估计的选择方法;
置信学习开源工具 cleanlab, 可参考
3、cleanLab使用
1) 置信学习方法 怎么用?有什么开源框架?
- 置信学习开源工具: cleanlab
- 使用文档:cleanlab 操作手册
- 使用
- cleanlab在MINIST数据集中找出的错误样本
from cleanlab.pruning import get_noise_indices
# 输入
# s:噪声标签
# psx: n x m 的预测概率概率,通过交叉验证获得
ordered_label_errors = get_noise_indices(
s=numpy_array_of_noisy_labels,
psx=numpy_array_of_predicted_probabilities,
sorted_index_method='normalized_margin', # Orders label errors
)
- 找出错误样本后,clean 点,重新训练
from cleanlab.classification import LearningWithNoisyLabels
from sklearn.linear_model import LogisticRegression
# 其实可以封装任意一个你自定义的模型.
lnl = LearningWithNoisyLabels(clf=LogisticRegression())
lnl.fit(X=X_train_data, s=train_noisy_labels)
# 对真实世界进行验证.
predicted_test_labels = lnl.predict(X_test)
2)置信学习方法 的工作原理?
- 置信学习方法 主要是通过 寻找出 标注数据中的 “脏数据”,然后抛弃掉这些数据后重新训练,也就是直接估计噪声标签和真实标签的联合分布,而不是修复噪声标签或者修改损失权重。
3)参考
- 标注数据存在错误怎么办?MIT&Google提出用置信学习找出错误标注(附开源实现)
- Confident Learning: Estimating Uncertainty in Dataset Labels
数据标注-------主动学习
1、 主动学习是什么?
通过主动找到最有价值的训练样本加入训练集,如果该样本是未标记的,则会自动要求人工标注,然后再用于模型训练;
目标:以更少的训练样本训练出性能尽可能高的模型;
2、为什么需要主动学习?
- 数据标注成本高,尤其是专业知识领域;
- 数据量巨大,难以全量训练 ,或训练机器/时间有限;
3、 主动学习的思路是什么?
该方法首先筛选出条的未标记样本,然后对其手动标记,然后采用该标记过的数据训练实体识别模型,接着,用训练后的模型标记未标记数据;最后,利用主动学习的样本抽取策略计算未标记样本的价值量后排序,挑拣条价值含量最高的未标记数据,手工标记后合并标记样本,并作为新的训练集。循环实行以上步骤,当被检测指标满足预设范围后停止循环。
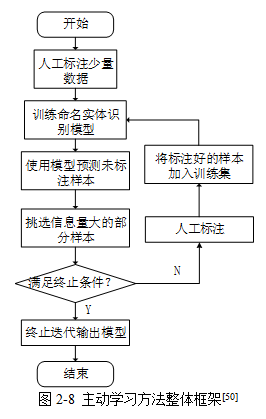
4、主动学习方法 的价值点在哪里?
- 主动学习能减少样本标注量来节约成本,包括标注成本和训练资源成本;并且主动学习能在同等数据量下提升模型性能。
未标注的样本池有1000w个样本,应用主动学习从中挑出200w样本进行标注后训练,便能训练出性能与1000w训练相当的模型。通常认为,主动学习能减少一半以上的样本标注量。有时主动学习挑选数据集子集进行训练,模型性能能超越全量训练。
5、如何选取“信息”量最大的数据标记
- 依赖委员会的样本选取策略(Query by committee, QBC):首先利用当前已标记样本集训练得到多个NER模型组建委员会;然后委员会成员分别根据自己的经验判断未标记样本中每个词可能属于的类型;而后统计样本中每个词的不同类型选项所获得的成员票数;最后,抽取出所获得的选票最不统一的样本进行标记。如果未标记样本带有信息量较高时,容易误导委员会中不同成员对其的判断,使其做出不正确的反应,NER模型通过这些标记好的信息量最多的样本,能够为当前NER模型带来较大的泛化能力提升。
- 依赖不确定度的样本选取策略(Uncertainty Sampling, US):利用信息熵方法评估标记样本的不稳定性。该方法首先通过已标记样本集对实体识别模型进行训练,然后利用该模型计算样本中每个字符隶属于不同实体类型的概率,最后,标记不稳定性高的数据,通过利用这些不稳定性高的数据训练实体识别模型,能够提高模型预能力。
- 依赖代表性大的样本选取策略(Representative Sampling, RS):首先计算未标记样本中不同样本的向量化表示,然后,采用聚类分析使样本聚类成多个簇,最后从聚类所得到的不同簇中挑出离中心点最近的样本进行标记。一般而言,未标记样本集中某些样本具有一些相同的特征,聚类分析方法能够根据这些特征,将其划分到不同的簇中。离该簇中心点越近的样本点,具有能够很好的代表该样本所在簇的其他样本,所以对该样本点进行学习,能提高NER模型对该簇中其他未标记样本的实体识别能力。总结,向量化,然后聚类;
6、参考资料
新词发现
1、什么是 “未登录词”?
- 未登录词 or 新词:NLP 任务中存在一些 之前之前没见过的词,这些词即为 “未登录词”(新词);
2、 “未登录词”(新词) 对于 NLP 任务的影响?
- 对于“未登录词”(新词)的发现,主流的深度学习框架CNN/LSTM/Attention和BERT/RoBERTa/Albert等都无法解决这个问题;
- 如果无法 发现这些“未登录词”(新词),那么 会 影响 训练模型的性能;
3、常用的解决 “未登录词”(新词) 问题的方法?
- 方法类型:无监督任务
- 常用方法:自信息 and 互信息
4、如何 衡量 当前词 是 “未登录词”(新词) 呢?
- 常用的衡量 字符串 是 新词 的方法:
- 自信息(信息熵):Entropy
- 互信息:MI(Mutual Information)
5、做 分词处理 需要考虑的问题是什么?
- 动机:在做新词发现时,需要解决 特殊字符 做带来的噪声影响。比如在做 新词发现时,需要设置 滑动窗口,当 存在 阿拉伯数字 or 英文字符时,会导致几个数字或者几个英文字母随便组合一下,他们的程度就大于5,造成的问题是 有些数字会被识别为新词,新发现的英文单词最大程度为5。此外,在这两种情况下,它们对前后字符串的分词也会造成不利的影响。
- 解决方法:需要 将 连续的数字或英文字母看成一个字 【采用 Bert 中 的 tokenization.py】
- 代码
class BasicTokenizer(object):
"""Runs basic tokenization (punctuation splitting, lower casing, etc.)."""
def __init__(self, do_lower_case=True):
"""Constructs a BasicTokenizer.
Args:
do_lower_case: Whether to lower case the input.
"""
self.do_lower_case = do_lower_case
def tokenize(self, text):
"""Tokenizes a piece of text."""
text = convert_to_unicode(text)
text = self._clean_text(text)
# This was added on November 1st, 2018 for the multilingual and Chinese
# models. This is also applied to the English models now, but it doesn't
# matter since the English models were not trained on any Chinese data
# and generally don't have any Chinese data in them (there are Chinese
# characters in the vocabulary because Wikipedia does have some Chinese
# words in the English Wikipedia.).
text = self._tokenize_chinese_chars(text)
orig_tokens = whitespace_tokenize(text)
split_tokens = []
for token in orig_tokens:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token)
split_tokens.extend(self._run_split_on_punc(token))
output_tokens = whitespace_tokenize(" ".join(split_tokens))
return output_tokens
def _run_strip_accents(self, text):
"""Strips accents from a piece of text."""
text = unicodedata.normalize("NFD", text)
output = []
for char in text:
cat = unicodedata.category(char)
if cat == "Mn":
continue
output.append(char)
return "".join(output)
def _run_split_on_punc(self, text):
"""Splits punctuation on a piece of text."""
chars = list(text)
i = 0
start_new_word = True
output = []
while i < len(chars):
char = chars[i]
if _is_punctuation(char):
output.append([char])
start_new_word = True
else:
if start_new_word:
output.append([])
start_new_word = False
output[-1].append(char)
i += 1
return ["".join(x) for x in output]
def _tokenize_chinese_chars(self, text):
"""Adds whitespace around any CJK character."""
output = []
for char in text:
cp = ord(char)
if self._is_chinese_char(cp):
output.append(" ")
output.append(char)
output.append(" ")
else:
output.append(char)
return "".join(output)
def _is_chinese_char(self, cp):
"""Checks whether CP is the codepoint of a CJK character."""
# This defines a "chinese character" as anything in the CJK Unicode block:
# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
#
# Note that the CJK Unicode block is NOT all Japanese and Korean characters,
# despite its name. The modern Korean Hangul alphabet is a different block,
# as is Japanese Hiragana and Katakana. Those alphabets are used to write
# space-separated words, so they are not treated specially and handled
# like the all of the other languages.
if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
(cp >= 0x3400 and cp <= 0x4DBF) or #
(cp >= 0x20000 and cp <= 0x2A6DF) or #
(cp >= 0x2A700 and cp <= 0x2B73F) or #
(cp >= 0x2B740 and cp <= 0x2B81F) or #
(cp >= 0x2B820 and cp <= 0x2CEAF) or
(cp >= 0xF900 and cp <= 0xFAFF) or #
(cp >= 0x2F800 and cp <= 0x2FA1F)): #
return True
return False
def _clean_text(self, text):
"""Performs invalid character removal and whitespace cleanup on text."""
output = []
for char in text:
cp = ord(char)
if cp == 0 or cp == 0xfffd or _is_control(char):
continue
if _is_whitespace(char):
output.append(" ")
else:
output.append(char)
return "".join(output)
对抗训练
1、什么是 对抗训练 ?
对抗训练 从 CV 引入到 NLP 领域,作为一种防御机制,能够在修改部分信息的情况下,提高模型的泛化能力。
2、 为什么 对抗训练 能够 提高模型效果?
对抗样本可以用来攻击和防御,而对抗训练其实是“对抗”家族中防御的一种方式,其基本的原理呢,就是通过添加扰动构造一些对抗样本,放给模型去训练,以攻为守,提高模型在遇到对抗样本时的鲁棒性,同时一定程度也能提高模型的表现和泛化能力。
3、对抗训练 有什么特点?
- 对抗样本一般需要具有两个特点:
- 相对于原始输入,所添加的扰动是微小的;
- 能使模型犯错
4、 对抗训练 的作用?
- 提高模型应对恶意对抗样本时的鲁棒性;
- 作为一种regularization,减少过拟合,提高泛化能力。
5、对抗训练的基本概念?
在原始输入样本 x 上加一个扰动
r
a
d
v
r_{adv}
radv ,得到对抗样本后,用其进行训练。也就是说,问题可以被抽象成这么一个模型:
m
i
n
θ
−
l
o
g
P
(
y
∣
x
+
r
a
d
v
;
θ
)
min{\theta} -logP(y|x + r_{adv}; \theta)
minθ−logP(y∣x+radv;θ)
注: y 为gold label, θ 为模型参数
6、 如何计算扰动?
- 方法:FGSM
r a d v = ϵ ⋅ s g n ( ∇ x L ( θ , x , y ) ) r_{adv} = \epsilon \cdot sgn(\nabla_xL(\theta, x, y)) radv=ϵ⋅sgn(∇xL(θ,x,y))
注: sgn 为符号函数, L 为损失函数。Goodfellow发现,令 ε=0.25 ,用这个扰动能给一个单层分类器造成99.9%的错误率。
7、 如何优化?
- 动机:将问题重新定义成了一个找鞍点的问题
- 方法:Min-Max公式
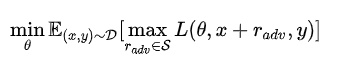
注:公式由两部分构成:一个是内部损失函数的最大化,一个是外部经验风险的最小化
内部max是为了找到worst-case的扰动,也就是攻击,其中, L 为损失函数, S 为扰动的范围空间。
外部min是为了基于该攻击方式,找到最鲁棒的模型参数,也就是防御,其中 D 是输入样本的分布。
8、对抗训练–实战篇
3.1 NLP 中经典对抗训练 之 Fast Gradient Method(FGM)
- 方法:假设输入的文本序列的embedding vectors [v1,v2,…,vT] 为 x ,embedding的扰动为:
r a d v = ϵ ⋅ g / ∣ ∣ g ∣ ∣ 2 g = ∇ x L ( θ , x , y ) r_{adv} = \epsilon\cdot g/||g||_2\\g=\nabla_xL(\theta, x, y) radv=ϵ⋅g/∣∣g∣∣2g=∇xL(θ,x,y)
注:实际上就是取消了符号函数,用二范式做了一个scale,需要注意的是:这里的norm计算的是,每个样本的输入序列中出现过的词组成的矩阵的梯度norm。原作者提供了一个TensorFlow的实现 [10],在他的实现中,公式里的 x 是embedding后的中间结果(batch_size, timesteps, hidden_dim),对其梯度 g 的后面两维计算norm,得到的是一个(batch_size, 1, 1)的向量 ∣ ∣ g ∣ ∣ 2 ||g||_2 ∣∣g∣∣2 。为了实现插件式的调用,笔者将一个batch抽象成一个样本,一个batch统一用一个norm,由于本来norm也只是一个scale的作用,影响不大。
- 代码实现:
- FGM 类实现
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
- FGM 类调用
# 初始化
fgm = FGM(model)
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
注:PyTorch为了节约内存,在backward的时候并不保存中间变量的梯度。因此,如果需要完全照搬原作的实现,需要用register_hook接口[11]将embedding后的中间变量的梯度保存成全局变量,norm后面两维,计算出扰动后,在对抗训练forward时传入扰动,累加到embedding后的中间变量上,得到新的loss,再进行梯度下降。
3.2 NLP 中经典对抗训练 之 Projected Gradient Descent(PGD)
- 动机:内部max的过程,本质上是一个非凹的约束优化问题,FGM解决的思路其实就是梯度上升,那么FGM简单粗暴的“一步到位”,是不是有可能并不能走到约束内的最优点呢?
- 方法:用Projected Gradient Descent(PGD)的方法,简单的说,就是“小步走,多走几步”,如果走出了扰动半径为 ε 的空间,就映射回“球面”上,以保证扰动不要过大:

- 代码实现:
- PGD 类实现
import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]
- FGM 类调用
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
9、对抗训练参考
数据增强
1、 什么是 数据增强?
数据增强 是通过采用一些策略 增加 训练样本的数据量,提高模型的训练效果。
2、为什么需要 数据增强?
在医疗、金融、法律等领域,高质量的标注数据十分稀缺、昂贵,我们通常面临少样本低资源问题。
3、常见的数据增强方法
3.1 词汇替换篇
3.1.1 什么是基于词典的替换方法?
- 介绍:基于同义词替换的方法是从句子中以一定的概率随机选取一个单词,利用一些同义词数据库(注:英文可以用 WordNet 数据库,中文可以用 synonyms python 同义词词典) 将其替换成对应的同义词。
- 举例说明:

注:对 句子 “我 喜欢 NLP ” 随机选取 其中一个词 利用 synonyms 包进行替换,可以替换为 “我 喜爱 NLP ”。
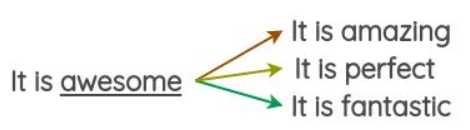
3.1.2 什么是基于词向量的替换方法?
- 介绍:通过利用预先训练好的词向量(eg:Word2Vec、GloVe、FastText等),使用嵌入空间中最近的相邻单词替换句子中的某些单词。
- 思路:
- 预先训练好的词向量(eg:Word2Vec、GloVe、FastText等);
- 使用嵌入空间中最近的相邻单词,如下图,在嵌入空间中,与词 “awesome” 最近的相邻单词为 amazing、perfect等

嵌入空间
- 随机选取三个 与 词 “awesome” 最相近的单词替换 词 “awesome”,如下图:
- 实现:
import synonyms
# 功能:同义词替换,替换一个语句中的n个单词为其同义词
def synonym_replacement(words, alpha, num_words, stop_words):
n = max(1, int(alpha * num_words))
new_words = words.copy()
random_word_list = list(set([word for word in words if word not in stop_words]))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(synonyms)
new_words = [synonym if word == random_word else word for word in new_words]
num_replaced += 1
if num_replaced >= n:
break
sentence = ' '.join(new_words)
new_words = sentence.split(' ')
return new_words
# 功能:获取与 word 最相近的同义词
def get_synonyms(word):
return synonyms.nearby(word)[0]
3.1.3 什么是基于 MLM 的替换方法?
- 介绍:像BERT、ROBERTA和ALBERT这样的Transformer模型已经接受了大量的文本训练,使用一种称为“Masked Language Modeling”的预训练,即模型必须根据上下文来预测遮盖的词汇。这可以用来扩充一些文本。例如,我们可以使用一个预训练的BERT模型并屏蔽文本的某些部分。然后,我们使用BERT模型来预测遮蔽掉的token。
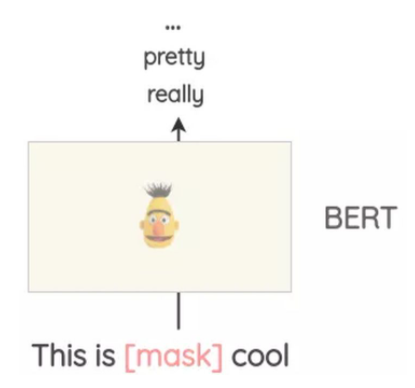
使用mask预测来生成文本的变体。与之前的方法相比,生成的文本在语法上更加连贯,因为模型在进行预测时考虑了上下文。
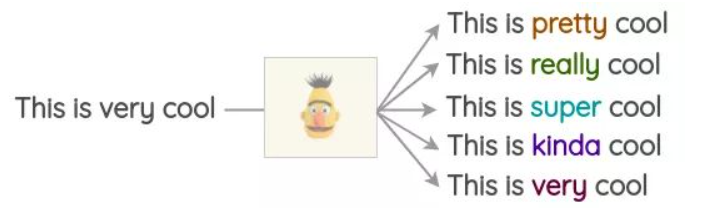
- 实现:
注:使用开源库这很容易实现,如Hugging Face的transformers。你可以将你想要替换的token设置为并生成预测。
from transformers import pipeline
nlp = pipeline('fill-mask')
nlp('This is <mask> cool')
[{'score': 0.515411913394928,
'sequence': '<s> This is pretty cool</s>',
'token': 1256},
{'score': 0.1166248694062233,
'sequence': '<s> This is really cool</s>',
'token': 269},
{'score': 0.07387523353099823,
'sequence': '<s> This is super cool</s>',
'token': 2422},
{'score': 0.04272908344864845,
'sequence': '<s> This is kinda cool</s>',
'token': 24282},
{'score': 0.034715913236141205,
'sequence': '<s> This is very cool</s>',
'token': 182}]
注:这种方法的一个问题是,决定要屏蔽文本的哪一部分并不是一件小事。你必须使用启发式的方法来决定掩码,否则生成的文本将不保留原句的含义。
3.1.4 什么是基于 TF-IDF 的词替换?
- 动机:对于 query 里面 TF-IDF 值较小的词语,一般对 query 的贡献度较少
- 基本思想:针对 TF-IDF值较低的词语贡献度低问题,所以在不影响句子所属类别的情况下替换,可以达到数据增强的作用。

3.2 词汇插入篇
3.2.1 什么是随机插入法?
- 方法:通过在 query 里面随机插入一个或多个新词汇、相应的拼写错误、符号等噪声的方式提高 训练模型的健壮性。
- 代码实现:
import random
import synonyms
# 功能:随机插入,随机在语句中插入n个词
def random_insertion(words, alpha, num_words, stop_words):
n = max(1, int(alpha * num_words))
new_words = words.copy()
for _ in range(n):
self.add_word(new_words)
return new_words
# 功能:插入新词
def add_word(new_words):
synonyms = []
counter = 0
while len(synonyms) < 1:
random_word = new_words[random.randint(0, len(new_words)-1)]
synonyms = get_synonyms(random_word)
counter += 1
if counter >= 10:
return
random_synonym = random.choice(synonyms)
random_idx = random.randint(0, len(new_words)-1)
new_words.insert(random_idx, random_synonym)
# 功能:获取同义词
def get_synonyms(word):
return synonyms.nearby(word)[0]
3.3 词汇交换篇
3.3.1 什么是随机交换法?
- 方法:通过在 query 里面随机交换一个或多个词汇的方式提高 训练模型的健壮性。
- 代码实现:
import random
# 功能:随机交换:随机交换句子中的两个词
def random_swap(words, alpha, num_words, stop_words):
n = max(1, int(alpha * num_words))
new_words = words.copy()
for _ in range(n):
new_words = swap_word(new_words)
return new_words
# 功能:随机交换两个词
def swap_word(new_words):
random_idx_1 = random.randint(0, len(new_words)-1)
random_idx_2 = random_idx_1
counter = 0
while random_idx_2 == random_idx_1:
random_idx_2 = random.randint(0, len(new_words)-1)
counter += 1
if counter > 3:
return new_words
new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
return new_words
3.4 词汇删除篇
3.4.1 什么是随机删除法?
- 方法:通过在 query 里面随机删除一个或多个词汇的方式提高 训练模型的健壮性。
- 代码实现:
import random
# 功能:随机删除,以概率p删除语句中的词
def random_deletion( words, alpha, num_words, stop_words):
if len(words) == 1:
return words
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > alpha:
new_words.append(word)
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return new_words
3.5 回译篇
3.5.1 什么是回译法?
- 方法:利用百度翻译、谷歌翻译等在线翻译器来解释文本,并重新训练文本;
- 思路:
- 将待数据增强的句子(如中文句子)翻译成另外一种语言,如英语、日语等;
- 然后将翻译后的句子回译回中文句子;
- 检查新句子是否与原来的句子不同。如果是,那么我们使用这个新句子作为原始文本的数据增强。

3.6 交叉增强篇
3.6.1 什么是 交叉增强篇
- 方法:借鉴遗传学中染色体交叉操作的方式进行数据增强。
- 思路:将 tweets 切分未为两部分,两个具有相同极性的随机推文(即正面/负面)进行交换。这个方法的假设是,即使结果是不符合语法和语义的,新文本仍将保留情感的极性。
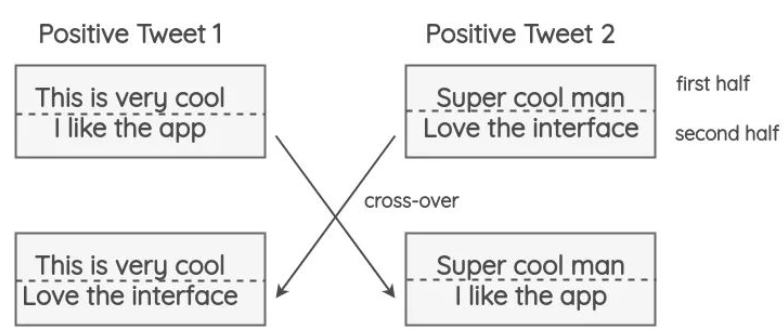
- 实验结果分析:这一技术对准确性没有影响,但有助于论文中极少数类的F1分数,如tweets较少的中性类。

3.7 语法树篇
3.7.1 什么是语法树操作?
- 思路:这项技术已经在Coulombe的论文中使用。其思想是解析和生成原始句子的依赖关系树,使用规则对其进行转换,并生成改写后的句子。
- 举例说明:在不改变句子的含义的情况下将句子从主动转化为被动语态的方式,也是一种数据增强方式。
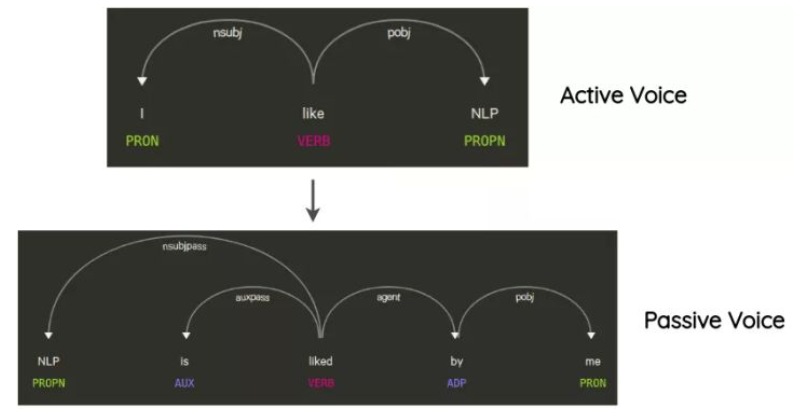
- 实现方式:要使用上述所有方法,可以使用名为nlpaug的python库:https://github.com/makcedward/nlpaug。它提供了一个简单且一致的API来应用这些技术。
3.8 对抗增强篇
3.8.1 什么是对抗增强?
- 方法:NLP中通常在词向量上添加扰动并进行对抗训练,文献[10]NLP中的对抗训练方法FGM, PGD, FreeAT, YOPO, FreeLB等进行了总结。

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









