这是一篇学习UFLDL反向传导算法 的笔记,按自己的思路捋了一遍,有不对的地方请大家指点。
首先说明一下神经网络的符号:
n l 表示神经网络的层数。
s l 表示第
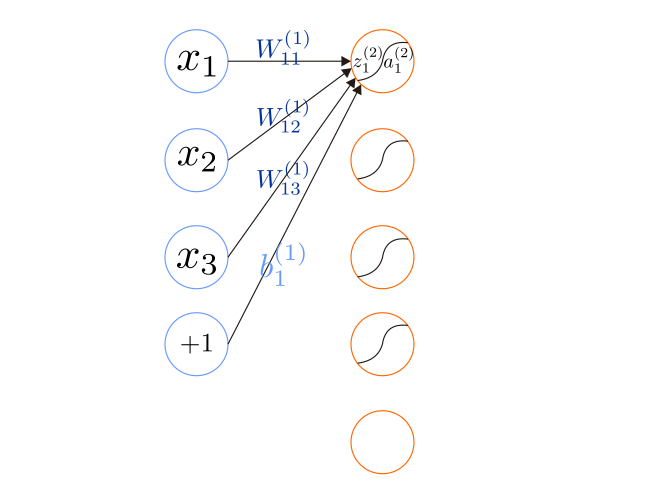
l 层神经元个数,不包含偏置单元。 z ( l ) i
l 层第 i
a ( l ) i 表示第
l 层第 i
W ( l ) i j 表示第
l 层第 j
l + 1 层第
i 个神经元的权重,因此权值矩阵 W
s l + 1 x
s l
a ( 2 ) 1 a ( 2 ) 2 a ( 2 ) 3 a ( 2 ) 4 = f ( W ( 1 ) 11 x 1 + W ( 1 ) 12 x 2 + W ( 1 ) 13 x 3 + b ( 1 ) 1 ) = f ( W ( 1 ) 21 x 1 + W ( 1 ) 22 x 2 + W ( 1 ) 23 x 3 + b ( 1 ) 2 ) = f ( W ( 1 ) 31 x 1 + W ( 1 ) 32 x 2 + W ( 1 ) 33 x 3 + b ( 1 ) 3 ) = f ( W ( 1 ) 41 x 1 + W ( 1 ) 42 x 2 + W ( 1 ) 43 x 3 + b ( 1 ) 4 )
我们可以将其向量化表示:
z ( 2 ) a ( 2 ) = W ( 1 ) x + b ( 1 ) = f ( z ( 2 ) )
这里的矩阵
W 的具体形式为:
W 4 × 3 = ⎡ ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ W ( 1 ) 11 W ( 1 ) 21 W ( 1 ) 31 W ( 1 ) 41 W ( 1 ) 12 W ( 1 ) 22 W ( 1 ) 32 W ( 1 ) 42 W ( 1 ) 13 W ( 1 ) 23 W ( 1 ) 33 W ( 1 ) 43 ⎤ ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥
第
2 层的神经元个数为
4 ,第
1 层神经元的个数为
3 ,因此为
4 × 3 维的矩阵。
代价函数
对于单个样本我们将神经网络的代价函数定义为:
J ( W , b ; x , y ) = 1 2 ∥ ∥ h W , b ( x ) − y ∥ ∥ 2
对所有
K 个样本,神经网络的总的代价函数(这也是批量的由来)为:
J ( W , b ) = [ 1 K ∑ k = 1 K J ( W , b ; x ( k ) , y ( k ) ) ] + λ 2 ∑ l = 1 n l − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( W ( l ) j i ) 2 = [ 1 K ∑ k = 1 K ( 1 2 ∥ ∥ h W , b ( x ( k ) ) − y ( k ) ∥ ∥ 2 ) ] + λ 2 ∑ l = 1 n l − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( W ( l ) j i ) 2
使用批量梯度下降算法寻求神经网络的最优参数
我们使用批量梯度下降算法寻求神经网络的最优参数
W ( l ) , b l 。
l + 1 层第
i 个神经元来说,第 l
j 个神经元的权值可按如下方式迭代更新:
W ( l ) i j = W ( l ) i j − α ∂ ∂ W ( l ) i j J ( W , b ) = W ( l ) i j − α ⎡ ⎣ ⎛ ⎝ 1 K ∑ k = 1 K ∂ ∂ W ( l ) i j J ( W , b ; x ( k ) , y ( k ) ) ⎞ ⎠ + λ W ( l ) i j ⎤ ⎦
类似的,对于 第
l + 1 层第
i 个神经元来说,第
l 层的偏置单元的权值可按如下方式迭代更新:
b ( l ) i = b ( l ) i − α ∂ ∂ b ( l ) i J ( W , b ) = b ( l ) i − α ⎡ ⎣ 1 K ∑ k = 1 K ∂ ∂ b ( l ) i J ( W , b ; x ( k ) , y ( k ) ) ⎤ ⎦
我们现在的目的是求出以下两个式子就可以对参数进行迭代了:
∂ ∂ W ( l ) i j J ( W , b ; x ( k ) , y ( k ) ) ∂ ∂ b ( l ) i J ( W , b ; x ( k ) , y ( k ) )
又我们知道第
l + 1 层第
i 个神经元的输入 z ( l + 1 ) i
z ( l + 1 ) i = ∑ j = 1 s l W ( l ) i j a ( l ) j + b ( l ) i
再进一步的对上面的式子进行变形:
∂ ∂ W ( l ) i j J ( W , b ; x ( k ) , y ( k ) ) = ∂ J ( W , b ; x ( k ) , y ( k ) ) ∂ z ( l + 1 ) i ⋅ ∂ z ( l + 1 ) i ∂ W ( l ) i j = ∂ J ( W , b ; x ( k ) , y ( k ) ) ∂ z ( l + 1 ) i ⋅ a ( l ) j
同样的,对于
b ( l ) i 的偏导数:
∂ ∂ b ( l ) i J ( W , b ; x ( k ) , y ( k ) ) = ∂ J ( W , b ; x ( k ) , y ( k ) ) ∂ z ( l + 1 ) i ⋅ ∂ z ( l + 1 ) i ∂ b ( l ) i = ∂ J ( W , b ; x ( k ) , y ( k ) ) ∂ z ( l + 1 ) i
残差的定义
接下来我们定义:
δ ( l ) i = ∂ ∂ z ( l ) i J ( W , b ; x ( k ) , y ( k ) )
为第
k 个样本在第
l 层第
i 个神经元上产生的残差。再次回顾我们的参数更新公式:
对于
W ( l ) i j 我们有:
W ( l ) i j = W ( l ) i j − α ∂ ∂ W ( l ) i j J ( W , b ) = W ( l ) i j − α ⎡ ⎣ ⎛ ⎝ 1 K ∑ k = 1 K ∂ ∂ W ( l ) i j J ( W , b ; x ( k ) , y ( k ) ) ⎞ ⎠ + λ W ( l ) i j ⎤ ⎦ = W ( l ) i j − α ⎡ ⎣ ⎛ ⎝ 1 K ∑ k = 1 K ∂ J ( W , b ; x ( k ) , y ( k ) ) ∂ z ( l + 1 ) i ⋅ a ( l ) j ⎞ ⎠ + λ W ( l ) i j ⎤ ⎦ = W ( l ) i j − α [ ( 1 K ∑ k = 1 K δ ( l + 1 ) i ⋅ a ( l ) j ) + λ W ( l ) i j ]
类似的,对于
b ( l ) i 我们有:
b ( l ) i = b ( l ) i − α ∂ ∂ b ( l ) i J ( W , b ) = b ( l ) i − α 1 K ∑ k = 1 K ∂ ∂ b ( l ) i J ( W , b ; x ( k ) , y ( k ) ) = b ( l ) i − α 1 K ∑ k = 1 K ∂ J ( W , b ; x ( k ) , y ( k ) ) ∂ z ( l + 1 ) i = b ( l ) i − α 1 K ∑ k = 1 K δ ( l + 1 ) i
现在的核心问题只剩下一个了,这个残差该如何求?
i 个神经元上的残差,这里为了简单起见,不再指定为第 k
δ ( n l ) i = ∂ ∂ z ( n l ) i J ( W , b ; x , y ) = ∂ ∂ z ( n l ) i 1 2 ∥ ∥ h W , b ( x ) − y ∥ ∥ 2 = ∂ ∂ z ( n l ) i 1 2 ∑ j = 1 s n l ( y j − a ( n l ) j ) 2 = ∂ ∂ z ( n l ) i 1 2 ∑ j = 1 s n l ( y j − f ( z ( n l ) j ) ) 2 = − ( y i − f ( z ( n l ) i ) ) f ′ ( z ( n l ) i )
然后计算倒数第二层即第
n l − 1 层第
i 个神经元的残差:
δ ( n l − 1 ) i = ∂ ∂ z ( n l − 1 ) i J ( W , b ; x , y ) = ∂ ∂ z ( n l − 1 ) i 1 2 ∑ j = 1 s n l ( y j − a ( n l ) j ) 2 = 1 2 ∑ j = 1 s n l ∂ ∂ z ( n l − 1 ) i ( y j − f ( z ( n l ) j ) ) 2 = ∑ j = 1 s n l − ( y j − f ( z ( n l ) j ) ) ∂ ∂ z ( n l − 1 ) i f ( z ( n l ) j ) = ∑ j = 1 s n l − ( y j − f ( z ( n l ) j ) ) f ′ ( z ( n l ) j ) ∂ z ( n l ) j ∂ z ( n l − 1 ) i = ∑ j = 1 s n l δ ( n l ) j ∂ ∂ z ( n l − 1 ) i ∑ q = 1 s n l W ( n l − 1 ) j q f ( z ( n l − 1 ) q ) = ∑ j = 1 s n l W ( n l − 1 ) j i δ ( n l ) j f ′ ( z ( n l − 1 ) i )
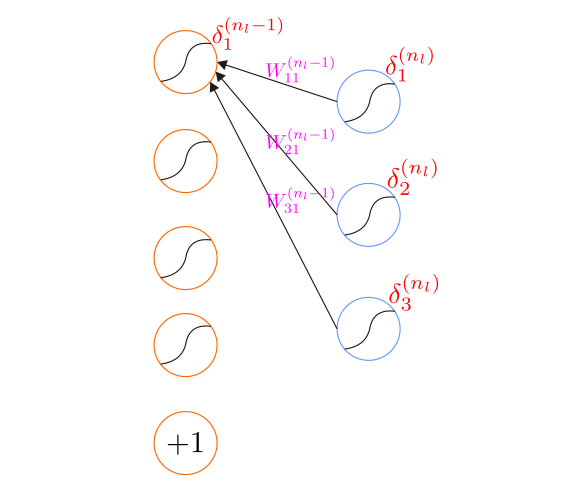
下面是残差传播的示意图:
δ ( l ) i = ∑ j = 1 s l + 1 W ( l ) j i δ ( l + 1 ) j f ′ ( z ( l ) i )
再再次回顾我们的参数更新公式:
W ( l ) i j b ( l ) i = W ( l ) i j − α [ ( 1 K ∑ k = 1 K δ ( l + 1 ) i ⋅ a ( l ) j ) + λ W ( l ) i j ] = b ( l ) i − α 1 K ∑ k = 1 K δ ( l + 1 ) i
我们需要先计算输出层神经元的残差,然后一级一级的计算前一层的神经元的残差,利用这些残差就可以更新神经网络参数了。
向量化表示
这里我们尝试将上述结果表示成向量或矩阵的形式,比如我们希望能一次性更新某一层神经元的权值和偏置,而不是一个一个的更新。
δ ( l + 1 ) i 表示的是第
l + 1 层第
i 个神经元的残差,那么整个第 l + 1
δ ( l + 1 ) i = ∑ j = 1 s l + 2 W ( l + 1 ) j i δ ( l + 2 ) j f ′ ( z ( l + 1 ) i )
从而得到:
δ ( l + 1 ) = ( W ( l + 1 ) ) T δ ( l + 2 ) ∙ f ′ ( z ( l + 1 ) )
注:这里的
∙ 是指点乘,即对应元素相乘,
δ ( l + 1 ) 是一个
s l + 1 × 1 维的列向量。
a ( l ) j 表示第
l 层第 j
l 层的神经元的输出可用 a ( l )
s l × 1 维的列向量。
因此对于矩阵
W ( l ) 来说,我们记:
∇ W ( l ) J ( W , b ; x , y ) = δ ( l + 1 ) ( a ( l ) ) T
我们将
Δ W ( l ) 初始化为
0 ,然后对所有
K 个样本将它们的
∇ W ( l ) J ( W , b ; x , y ) 累加到
Δ W ( l ) 中去:
Δ W ( l ) := Δ W ( l ) + ∇ W ( l ) J ( W , b ; x , y )
然后更新一次
W ( l ) :
W ( l ) = W ( l ) − α [ ( 1 K Δ W ( l ) ) + λ W ( l ) ]
这里再强调一下:上式中的
Δ W ( l ) 是所有
K 个样本的
δ ( l + 1 ) ( a ( l ) ) T 累加 和,如果希望做随机梯度下降了或者是mini-batch,这里就不用把所有样本的残差加起来了。
类似的,令:
∇ b ( l ) J ( W , b ; x , y ) = δ ( l + 1 )
我们将
Δ b ( l ) 初始化为
0 , 然后对所有
K 个样本将它们的
∇ b ( l ) J ( W , b ; x , y ) 累加到
Δ b ( l ) 中去
Δ b ( l ) := Δ b ( l ) + ∇ b ( l ) J ( W , b ; x , y )
于是有:
b ( l ) = b ( l ) − α [ 1 K Δ b ( l ) ]
同样的,上式中的
Δ b ( l ) 是所有
K 个样本的
δ ( l + 1 ) 累加 和。
小结
上面的推导过程尝试把所有的步骤都写出来了,个人感觉比UFLDL上的教程更为详尽,只要你耐心看总能看得懂的。当然这篇文章有些细节并未作说明,比如惩罚因子的作用,为什么没有对偏置进行规则化,激活函数的选择等,这些都可以在UFLDL中找到答案,对应的链接在下面的参考中给出。
参考
[1] 神经网络 反向传导算法























 9302
9302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









