






目录
一、DDL
DDL是数据定义语言, 定义了不同的表、列、视图、索引、存储过程、数据段等数据库对象。
1、create
create常用于表、视图、索引、存储过程、函数、触发器的创建
(1)创建表
语法:create table table_name(
str1 类型,
str2 类型,
str3 类型
……
);
create table student_score (
class number(4),
id number(6) ,
name varchar2(10),
subject varchar2(6),
grade number(4),
import_time date
);
表注释: comment on table table_name is '表注释'; --添加表注释
comment on column table_name.表字段 is '字段注释'; --添加表字段注释
--表添加注释
comment on table student_score is '学生成绩表';
--字段添加注释
comment on column student_score.class is '班级';
comment on column student_score.id is '学号';
comment on column student_score.name is '姓名';
comment on column student_score.subject is '学科';
comment on column student_score.grade is '分数';
comment on column student_score.import_time is '导入时间';
字段约束:
- primary key:主键约束,每张表都要有唯一的主键(可由单列组成;也可以由多列组成称为复合主键,多列之间用逗号隔开),主键列值必须唯一且非空
- foreign key:外键约束,可作用在单列或者多列上,是指当前表引用另一张表的某个列或某几个列,另一张表被引用列必须具有主键约束或者唯一约束(外键列值可以重复也可为空;当删除引用表中的数据时,数据不能出现在外键表外键列中)
外键引用行为3种:通过关键字on指定引用行为的类型1、on no action,被引用表中被引用列的数据删除时违反外键约束而禁止操作(外键默认引用类型)2、on set null,被引用表中被引用列的数据被删除时,外键表中外键列被设置为null,使用该应用行为,外键列值必须可以为空值3、on cascade,被引用表中被引用列的数据被删除时,外键表中对应的数据也会被删除,这种删除方式称为级联删除
- unique:唯一约束,不能存在相同的值,但允许空值
- not null:非空约束
- check:检查约束,数据在插入列前根据限制条件检查,满足条件的才可以插入列中
- default:默认约束,约束列未给定数值时使用默认值
删除约束:drop constraint 约束名;
1、创表时添加约束
create table student_score (
class varchar2(6),
class_id number(6),
name varchar2(10),
student_id number(6) constraint st_id_unique unique,--唯一约束,
subject varchar2(6) not null,--非空约束
grade number(4) constraint grade_ck check(grade between 0 and 100),--检查约束
import_time date default sysdate,--默认约束
constraint score_pk primary key (class,class_id) ,--复合主键
constraint score_fk foreign key (name) references student(name)--外键,引用student_score表name列数据(假设student表中每个学生的姓名name唯一)
);
2、对已有表添加约束
alter table student_score add constraint score_pk primary key (student_id,class_id);--复合主键
alter table student_score add constraint score_fk foreign key(name) references student(name);--外键约束
alter table student_score add constraint st_id_unique unique (student_id);--唯一约束
alter table student_score add constraint grade_ck check (grade between 0 and 100);--检查约束
alter table student_score modify subject not null;--非空约束
alter table student_score modify import_time default sysdate;--默认约束
3、外键的3种引用行为
alter table student_score drop constraint score_fk;
--on no action是外键的默认引用行为
--on set null
alter table student_score add constraint score_fk foreign key(name) references student(name) on delete set null;
--on cascade
alter table student_score add constraint score_fk foreign key(name) references student(name) on delete cascade;
禁用和激活约束:
- 约束默认是激活状态,但也可以根据实际需求,临时禁用约束,禁用后约束不在起作用,但是仍存于数据库中
- 禁用主键约束时,oracle会默认删除约束对应的唯一索引,等再次激活约束时重新启用。若想要在删除约束的同时保留唯一索引,可以在禁用约束时在约束名称后加关键字keep index;
- 禁用唯一约束或主键约束时,有外键约束在引用该列;可以先禁用外键约束,然后再禁用唯一约束或主键约束;或者在禁用唯一约束或主键约束时加上cascade关键字
- 定义约束时禁用,直接在约束后加上disable关键字
- 禁用已经存在的约束,语法:alter table table_name disable constraint 约束名;
- 激活约束,语法:alter table table_name enable [novalidate\validate] constraint 约束名;(novalidate:激活约束时不验证表中数据,validate则对表中数据进行验证)
--禁用约束
alter table student_score disable constraint grade_ck;
--激活约束,并对表中已有数据进行验证
alter table student_score enable validate constraint grade_ck;(2)创建视图
说明:
- 视图是一张虚表
- 视图可以进行DML操作
- 视图并不在数据库中存储数据值,他的数据值来自定义视图的查询语句中所引用的表
- 视图可以建立在关系表或其他视图之上
- 修改视图表中的数据就是在修改关系表中的数据;同样关系表中的数据会自动更新到视图表中,不需要配置调度更新数据
语法:create [or replace] view view_name [(column1,column2,column3,……)]
as
select ……from table_name
[with check option] [constraint 约束名]--指定在视图上定义的检查约束,当对视图进行
DML操作时数据必须符合where条件
[with read only]; --定义只读视图
create or replace view score_view
as
select * from student_score t
where t.subject = '数学'
with check option constraint ck;(3)创建索引
索引类型:B树索引、 位图索引、 反向键索引、 基于函数的索引注意点:
B树索引(默认类型)
oracle系统会自动为表的主键列建立索引,这个索引就是B树索引
无论用户搜索哪个分支的叶块(包含索引列的值和记录行 对应的物理地址rowid)
B树索引是通过在索引表中保存排序的索引列的值已经记录的物理地址rowid类实现快速查找
B树索引中的数据是以升序方式排列的
语法:create index 索引名 on table_name(column)
pctfree 预留空间大小
tablespace 表空间;
create bitmap index id_index
on student_score(id)
tablespace users;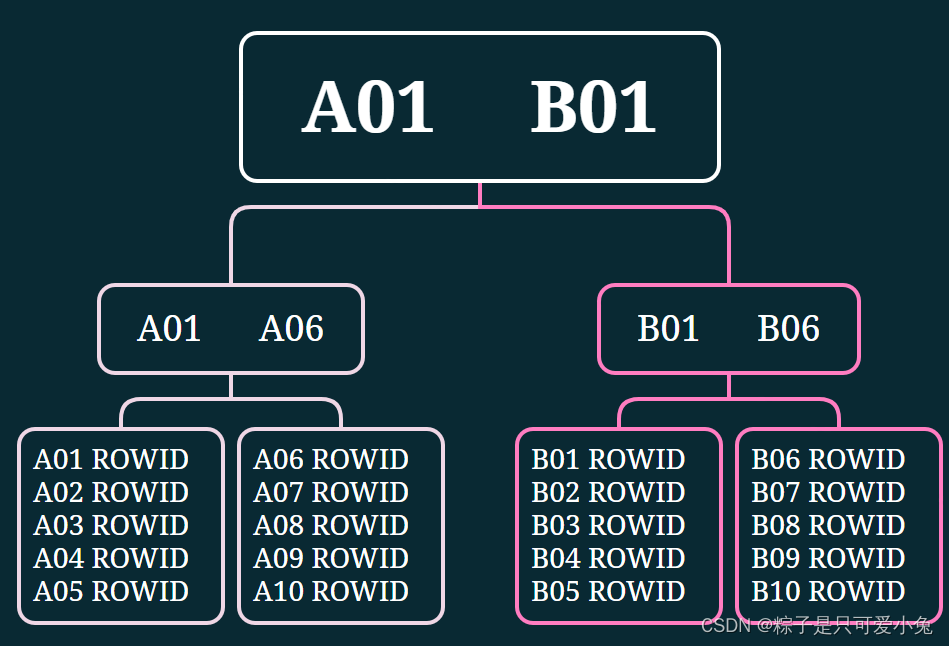
B树索引逻辑图
位图索引
位图索引适用于该列与行数的比例为1%时,当表中低基数的列上建立位图索引时(如在性别列上创建索引,只有两个分支,就不适合用B树索引,用位图索引更合适),系统对表进行一次全面扫描,为遇到的各个取值构建“图表”
语法:
create bitmap index 索引名
on table_name(column)
tablespace 表空间;
create bitmap index name_index
on student_score(name)
tablespace users;
注意:参数create_bitmap_area_size用于指定建立索引时分配的位图区大小,默认是8MB,为加快创建位图索引的速度,可以将参数值改为更大的值(该参数是静态参数,修改后需要重启数据库生效)
语法:alter system set create_bitmap_area_size = 数值;
alter system set create_bitmap_area_size = 8388608;反向键索引(特殊的B树索引)
反向键索引适用于在顺序递增列上建立索引
反向索引可以将添加的数据随机分散到索引中(避免在单调递增的列上建立B树索引,且表数据量庞大的情况下导致索引数据分布不均匀)
反向索引逻辑:它的存储结构和B数索引一样,但是在当用户使用序列在表中输入记录,反向索引会首先指向每个列键值的字节,然后再反方向后的新数据进行索引。(如索引列为1234,反向转换后是4321)
语法:
create index 索引名 on table_name(column) reverse
tablespace 表空间;
create index class_index on student_score(class) reverse
tablespace users;
由B树索引更改为反向索引,语法:alter index 索引名 rebuild reverse;
alter index id_index rebuild reverse;基于函数的索引
适用于查找列值大小写对查找结果有影响的列
基于函数的索引是常规的B树索引,但是它存储的数据是由表中的数据应用函数后得到的,并不是直接存储在表中的数据本身
语法:
create index 索引名 on table_name(lower\upper(column));
create index ename_index on emp(lower(ename));
select * from emp t where lower(t.ename) = 'jones';(4)存储过程
存储过程包括声明部分、执行部分和异常处理3部分
语法:
create [or replace] procedure 存储过程名 [(parameter1 in|out 数据类型,parameter2 in|out 数据
类型,……)]
is|as
begin
程序主体部分;
[exception]
[异常处理语句;]
end [存储过程名];
说明:
-
parameter是存储过程调用/执行时用到的参数,关键字in表示输入参数,out表示输出参数;它并不是存储过程定义的内部变量,内部变量需要在is|as和begin之间进行定义,并使用分号结束
-
创建存储过程时,is|as的效果是相同的
create or replace procedure sp_test(
--存储过程调用/执行时用到的参数,关键字in表示输入参数,out表示输出参数
sp_class in varchar2,
sp_id in number,
sp_name in varchar2,
sp_subject in varchar2,
sp_grade in number,
sp_date in date
)
is
--内部变量定义
begin
--程序主体
insert into student_score values(sp_class,sp_id,sp_name,sp_subject,sp_grade,sp_date);
commit;
end sp_test;(5)函数
函数可以接收0或者多个参数,并且必须有返回值(存储过程没有这个要求)
语法:
create [or replace] function 函数名[(parameter1,parameter2,……)]
return 函数返回值类型
is
[inner_variable]--函数的内部变量,不同与函数的参数
begin
函数主体;
[exception]
[dowith_sentences;]--异常处理
end [函数名];
/*创建函数,用于计算当月最后一天*/
create or replace function get_last_day(
--函数调用时使用参数
p_date in date
)
return date
is
v_month number;
begin
--获取传入日期的月份
select extract(month from p_date) into v_month from dual;
--根据月份计算当月最后一天
if v_month = 2 then
--如果是二月,需要判断闰年情况
if to_char(trunc(p_date,'yy'),'yy')='04' and mod(to_number(to_char(trunc(p_date,'mm'),'ddd'))+1,7)=6 then
return last_day(add_months(p_date,-1));
else
return last_day(p_date);
end if;
elsif v_month=4 or v_month=6 or v_month=9 or v_month=11 then
--四、六、九、十一月每月30天
return last_day(p_date);
else
--其他月份每月31天
return add_months(trunc(p_date, 'mm'), 1)-1;
end if;
end;
/*调用函数*/
select get_last_day(to_date('2024/02/26','yyyy/mm/dd')) from dual;--2024/2/29(6)触发器
触发器用于管理复杂的完整性约束,或控制对表的修改,或通知其他程序,甚至可以实现对数据的审计功能
触发器通过触发事件来执行,而存储过程的调用或者执行是由用户或应用程序进行的
语法:
create [or replace] trigger 触发器名
[before |after |instead of] 触发事件 --instead of表示触发器为替代触发器
on table_name |view_name |user_name |db_name
[for each row [when 触发条件]] --for each row表示行级触发器,若未指定则是语句级触发器
begin
主体部分;
end 触发器名;
触发器5种类型:
-
行级触发器:指DML语句对每一行数据的操作都会引起触发器运行
-
语句级触发器:指无论DML语句影响多少行数据,触发器都只会执行一次
-
替换触发器:指触发器并非定义在表上,而是视图上,当视图逻辑中存在2张及以上源表时,无法对视图做DML操作,使用替换触发器,可以使对视图的操作替换为对基表数据的操作
-
用户事件触发器:指与DDL或用户登录、退出数据库等事件相关的触发器,常见用户事件包括create、alter、drop、comment、grant、revoke、rename、truncate等
-
系统事件触发器:指在oracle系统的实践中进行触发的触发器,如oracle实例启用与关闭
1、行级触发器
-- 创建行级触发器
create or replace trigger trg_employees1
before insert on employees for each row
begin
-- 在这里编写触发器逻辑
if :new.salary < 1000 then
raise_application_error(-20001, 'salary cannot be less than $1000');
end if;
end;
2、语句级触发器
-- 创建日志表
create table dpt_log (
var_tag varchar2(50),
time date
);
-- 创建语句级触发器
create or replace trigger trg_employees2
before insert on employees
declare--声明变量
var_tag varchar2(10);--执行操作类型
begin
--触发器逻辑主体
if inserting then var_tag := '插入';
elsif updating then var_tag := '更新';
elsif deleting then var_tag := '删除';
end if;
insert into dpt_log values(var_tag,sysdate);--向日志表插入操作日志
end;
--插入数据
insert into employees values(2,'小张',1000);
commit;
--查看日志表
select * from dpt_log;
3、创建替换触发器
--创建视图
create or replace view emp_dept_view
as
select t1.empno,t1.ename,t2.deptno,t2.dname,t1.job,t1.hiredate from emp t1
join dept t2
on t1.deptno = t2.deptno;
select * from emp_dept_view;
--创建触发器
create or replace trigger tig_emp_dept
instead of insert on emp_dept_view
for each row
declare
result_count number;--自定义变量
begin
select count(*) into result_count from dept where deptno = :new.deptno;--查看dept表中是否存在对应insert的部门
if result_count = 0 then
insert into dept(deptno,dname) values(:new.deptno,:new.dname);--数据插入dept表中
end if;
insert into emp(empno,ename,deptno,job,hiredate) values(:new.empno,:new.ename,:new.deptno,:new.job,:new.hiredate);--数据插入emp表中
end tig_emp_dept;
--通过对视图插入数据,实现数据分别插入基表
insert into emp_dept_view(empno,ename,deptno,dname,job,hiredate) values(6666,'xiaoxu',11,'IT','develop',sysdate);
--查看数据是否分别插入两张基表中
select * from dept t where t.deptno = '11';
select * from emp t where t.ename = 'xiaoxu';
4、用户事件触发器
--创建日志信息表,用于保存数据对象、数据对象类型、操作行为、操作用户、操作日期等日志信息
create table ddl_log(
obj_name varchar2(20),
obj_type varchar2(10),
oper_action varchar2(10),
oper_user varchar2(10),
oper_time date
);
--创建触发器
create or replace trigger tig_ddl
before create or alter or drop
on scott.schema--在scott用户下的create or alter or drop操作都会引起触发器运行
begin
insert into ddl_log values(
ora_dict_obj_name,--操作的数据对象名称(系统函数)
ora_dict_obj_type,--对象名称(系统函数)
ora_sysevent,--系统时间名称(系统函数)
ora_login_user,--登录用户(系统函数)
sysdate
);
end tig_ddl;
--创建一张新表
create table test(
id number(3)
);
--查看日志信息表
select * from ddl_log;2、drop
(1)表
语法:
drop table table_name [cascade constraints];
说明:
-
表存在约束、关联视图、触发器等,则需要使用cascade constraints子句才可以删除
-
表drop之后,并没有彻底删除,而是放到回收站中,依然占有存储空间,可以使用flashback table进行还原,但若在drop时使用purge选项,则删除表的同时立即释放表空间
数据字典可以查看该表是否在回收站,语句:
select object_name,original_name from recyclebin where original_name = 'table_name';
还原删除表,语句:flashback table table_name to before drop;
--删除表
drop table error_log;
--删除存在触发器的表
drop table ddl_log cascade constraints;
--删除表的同时立即释放表空间
drop table dpt_log purge;
--查看该表是否在回收站语句
select object_name,original_name from recyclebin where lower(original_name) = 'ddl_log';
--还原删除表
flashback table ddl_log to before drop;(2)视图
语句:drop view 视图名;
(3)索引
由create index创建的索引直接使用drop index语句删除
定义约束时,由oracle系统自动建立的索引,必须先禁用或删除这个约束本身
语句:drop index 索引名;
(4)存储过程
语句:drop procedure 存储过程名;
(5)函数
语句:drop function 函数名;
(6)触发器
语法:drop tigger 触发器名;
3、truncate
truncate对象是数据表中的所有记录
truncate语句中可以使用reuse storage或者drop storage关键字,前者表示删除记录后仍保存记录所占用的空间,后者表示删除记录后立即回收记录所占用的空间,默认使用drop storage。
语法:truncate table table_name;
--删除记录后仍保存记录所占用的空间
truncate table student_score1 reuse storage;
--删除记录后立即回收记录所占用的空间
truncate table student_score1;4、alter
(1)表
alter对象是表结构
字段
添加字段,语句:alter table table_name add(字段名 字段类型(数值));
删除字段,语句:alter table table_name drop column 字段名;--删除一个字段
alter table table_name drop (字段1,字段2,……);--删除多个字段前面不加关
键字column
修改字段,语句:alter table table_name modify 字段名 属性;--属性包括字段的数据类型和长度
等
注意点:修改已有数据的字段数据类型为兼容数据类型时,数据的长度只能由低向高修改,避免出现数据溢出的情况
--添加字段
alter table student_score add(teacher varchar2(8));
--修改字段
alter table student_score modify grade number(10);
--删除字段
alter table student_score drop column teacher;
约束
添加约束:alter table table_name add constraint 约束名 约束类型(字段名);
删除约束:alter table table_name drop constraint 约束名;
表名
重命名表,语句:alter table table_name rename to 新表名;
表空间
修改表空间,语句:alter table table_name move tablespace 表空间名;
存储参数
修改存储参数:alter table table_name pctfree|pctused 数值;
说明:pctfree指快中预留用于insert、update的空间百分比,pctused指块中的数据使用空间低于一个百分比时,可以重新insert。若改变这两个参数,则无论数据块是否已经使用,都将受到影响
--pctfree
alter table scott_tablespace pctfree 20;--当剩余表空间小于20%时,无法再insert数据
--pctused
alter table scott_tablespace pctused 80;--定义表空间的使用率,当空间使用率低于80%,可以insert数据(2)索引
一个已建索引的表,随着数据不断insert、update、delete,索引中会产生很多的存储碎片(即空闲空间),进而影响索引工作效率;可以采用重建索引和合并索引2种方式来清除碎片,合并索引是将B树种叶子节点的存储碎片合并在一起,并不改变索引物理组织结构。而重建索引不仅可以清除碎片,还可以改变索引的全部存储参数设置,以及改变索引的存储表空间
合并索引语句:alter index 索引名 coalesce deallocate unused;
重建索引语句:alter index 索引名 rebuild
[reverse]--将反向建索引更改为普通索引
[tablespace 表空间名];
5、rename
rename对象包括表、列、约束、视图、索引、触发器、存储过程、函数、用户、包 。
表,语句:alter table table_name rename to 新表名;
列,语句:alter table table_name rename column 列名 to 新列名;
约束,语句:alter table table_name rename constraint 约束名 to 新约束名;
视图,语句:alter view 视图名 rename to 新视图名;
索引,语句:alter index 索引名 rename to 新索引名;
触发器,语句:alter tigger 触发器名 rename to 新触发器名;
存储过程,语句:alter procedure 存储过程名 rename to 新存储过程名;
函数,语句:alter function 函数名 rename to 新函数名;
用户,语句:alter user 用户名 rename to 新用户名;
包,语句:alter package 包名 rename to 新包名;
二、DML
数据操作语言,包括添加、删除、更新等数据操作
1、insert
insert对象是数据表
,将数据记录添加到已存在的数据表中
数据insert之后并不会立马插入表中,而是进入缓存表中,commit提交后新增数据会进入表中
注意点:insert时需要考虑字段列类型、列的个数和顺序、表字段约束这3点
1、字段类型为数值类型时,可以直接提供字段数值或用加上单引号
字段类型为字符、日期类型时,必须加上单引号
2、添加的数据行必须与字段列的个数和顺序保持一致
3、添加的数据必须要满足约束规则
(1)插入单条记录
格式:insert into table_name [(column1,column2,column3……)] values(value1,value2,value3……);
常用几种形式:
(1)给定列,只需要按对应列提供数据(非空约束字段必须指定,且提供数据也需为非空值)
(2) 不给定列,需要按照表列顺序提供所有数据
(3)使用特定格式插入日期值:添加日期数据,默认日期值必须匹配日期格式和日期语言;若希
望按照给定的格式插入数据,可以使用to_date进行转换
(4)使用default提供数据:
添加数据时可以使用default提供数值,若该列存在默认值会使用默认
值,若不存在则自动用null
(5)使用替代变量插入数据:将insert语句放入sql脚本中,使用变量为表插入数据;运行脚本,
数据插入
--建表
create table student_score (
id number(6) ,
name varchar2(10),
subject varchar2(6),
grade number(4),
import_time date
);
comment on table student_score is '学生成绩表';
comment on column student_score.id is '学号';
comment on column student_score.name is '姓名';
comment on column student_score.subject is '学科';
comment on column student_score.grade is '成绩';
comment on column student_score.import_time is '导入日期';
--指定列
insert into student_score (name,id,subject,grade,import_time) values('小张',01,'数学',98,to_date('2018-07-01','yyyy-mm-dd'));
--不指定列、使用特定格式插入日期值(to_date)
insert into student_score values(02,'小汪','语文',88,to_date('2018-07-01','yyyy-mm-dd'));
--使用default提供数据
insert into student_score values(02,'小汪','数学',87,default);
commit;
--查看表数据
select * from student_score;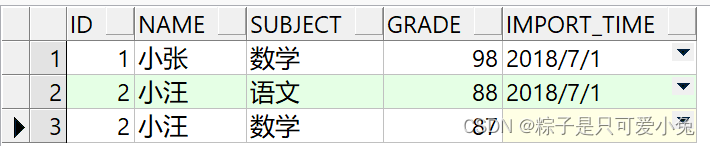
--使用替代变量插入数据
--sql脚本
accept s_id prompt '输入学号:'
accept s_name prompt '输入姓名:'
accept s_subject prompt '输入学科:'
accept s_grade prompt '输入成绩:'
accept s_import_time prompt '输入导入日期:'
insert into student_score(id,name,subject,grade,import_time) values(&s_id,'&s_name','&s_subject',&s_grade,sysdate);
commit;
--sql plus运行
@E:\localdate(2)查询结果插入
使用select替换语法中的values部分,由select语句提供插入的数据
格式:insert into table1 [(column1, column2, column3, ...)]
select column1, column2, column3, ...
from table2
where 条件;
1、向已建好表中插入多条数据
--插入多条记录
insert into student_score2
select * from student_score t
where t.id = 1;
commit;
--查看表数据
select * from student_score2;
2、创表的同时插入多条记录(不需要commit)
create table student_score3
as
select * from student_score t
where t.id = 2;
--查看表数据
select * from student_score2;(3)有条件插入多条记录
insert all when、insert first when
insert all when ...else :数据插入不考虑先后关系,只要满足条件,数据就会插入对应的表中,也就是说会导致重复记录的出现。
语法:
insert all
when 条件1 then into table1 [(column1, column2, column3, ...)]
when 条件2 then into table2 [(column1, column2, column3, ...)]
……
else into table3 [(column1, column2, column3, ...)]
select * from table;
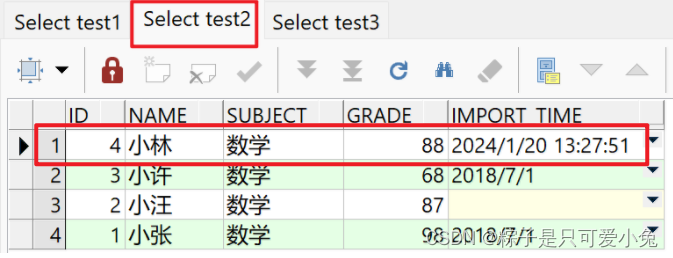
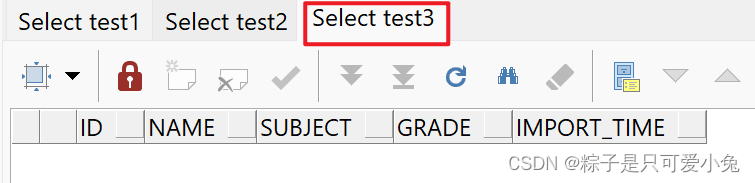
insert all
when id > 3 then into test1
when id < 5 then into test2
else into test3
select * from student_score where subject = '数学';
commit;
select * from test1 order by id desc;
select * from test2 order by id desc;
select * from test3 order by id desc;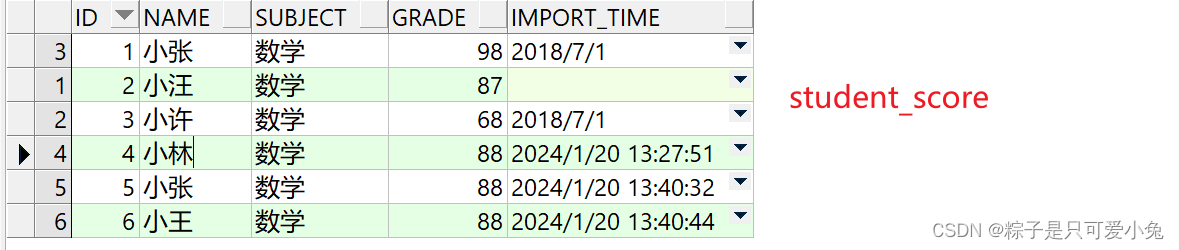
insert first when ...else :数据插入考虑先后关系,满足前一个条件的记录不会出现在后面when条件判断的对象记录中,因此不会存在重复记录
语法:
insert first
when 条件1 then into table1 [(column1, column2, column3, ...)]
when 条件2 then into table2 [(column1, column2, column3, ...)]
……
else into table3 [(column1, column2, column3, ...)]
select * from table;
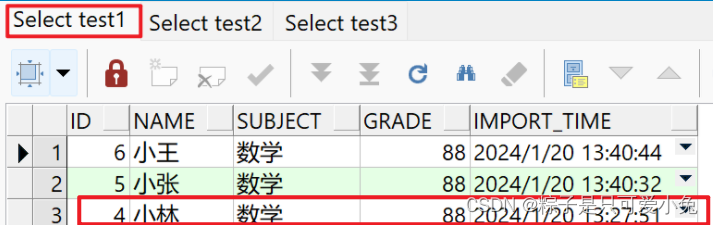
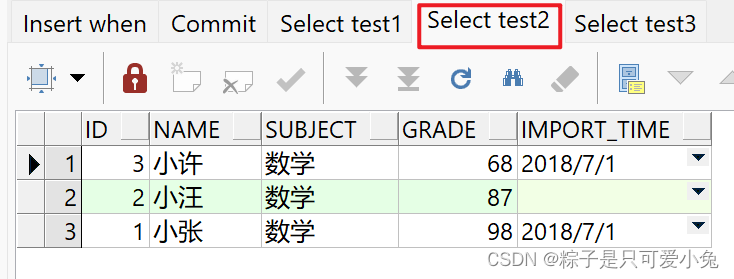
insert first
when id > 3 then into test1
when id < 5 then into test2
else into test3
select * from student_score where subject = '数学';
commit;
select * from test1 order by id desc;
select * from test2 order by id desc;
select * from test3 order by id desc;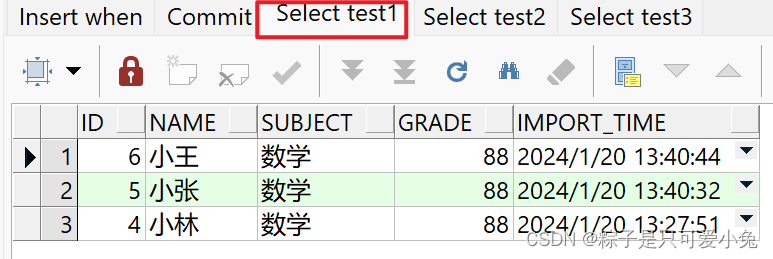
2、update
update的对象是表中数据
数据update之后并不会立马插入表中,而是进入缓存表中,commit提交后新增数据会进入表中
注意点:update时需要考虑列类型、和约束
1、更新数值列时,可以直接提供数值或者用单引号引住;更新字符列或日期列时,必须用单引号引住
2、更新的数据必须要满足列约束规则
语法:update table_name
set column1=express1,column2=express2,column3=express3……/(column3=select语
句)
where 条件;
--更新一条数据
update student_score
set grade = 92
where id = 2 and name = '小汪';
commit;
--更新多条数据
update student_score
set grade = 100
where subject = '数学';
commit;
--使用default更新数据
update student_score
set grade = default
where subject = '语文';
commit;
--子查询更新数据
update student_score
set grade = (select 100 from dual where 1 = 1)
where subject = '语文';
commit;3、delete
delete
对象是数据表,对表中的所有记录或者指定范围的记录(delete语句删除数据时,oracle系统会产生回滚记录,所以可以用rollback来撤销操作)
注意点:对删除存在主外键约束的记录需要特殊处理,如果删除主表(被参考的表)中被引用的记录,若默认外键处理方式,则强制不让删;若是on delete cascade,则一起删除;若是on delete set null,自动设为null
语法:delete from table_name where 条件;
--全表记录删除
delete from student_score;
commit;--事务提交后无法用rollback回滚
--删除给定范围记录
delete from student_score where id = 1;三、DQL
DQL:数据查询语言,select
语法:
select [distinct] columns|* --指定查询字段,distinct指对查询的结果去重
from tables|views|other select --指定数据源
where 条件 --指定数据查询限制条件
group by columns --对查询出的数据按给定columns进行分组
having 条件 --查询分组数据经过条件筛选后的数据
order by columns --按照columns对查询数据进行排序
说明:rowid是标识行中唯一性的行标识符也称为伪列,是数据库中的隐藏列,并不是定义在表中的,长度为18为字符,包含这行数据在oracle数据库中的物理地址
1、筛选查询
(1)比较筛选:=、!或<>、>、<、>=、<=
(2)in关键字
(3)between……and……和not between ……and
(4)is null:需要注意空值和空字符串不同,空值是不存在的值,而空字符串是长度为0的字符串
(5)逻辑筛选:and、or、not
2、模糊查询
模糊查询时,like关键字需要和通配符结合使用。
有2种通配符:%,代表0或者多个字符;_,代表一个字符
escape转义:查询记录包含通配符时,需要使用escape进行转义,将他变为一个普通字符
--%
select * from dept t where t.loc like '%A%';
--_
select * from dept t where t.loc like '_A%';
--escape
select * from dept t where t.loc like '%T\_%' escape '\';3、分组查询
group by分组查询时,后面加上rollup、cube,可以生成分组后数据的横向小计、纵向小计、总计
(1)rollup
rollup:保留原有统计结果的基础上,可以生成横向小计、总计
语法:…… group by rollup (column1,column2,……);
…… group by rollup ((column1,column2,……));--使用复合列,可以略过rollup的某些
统计结果
两者区别:
……group by rollup (a,b,c):统计结果等同于group by(a,b,c)、group by(a,b)、group by a、
group by ()的并集,
……group by rollup (a,(b,c))的统计结果等同于group by(a,b,c)、group by a、group by ()的并集
--查看源表数据
select t.* from student_score t;
--group by
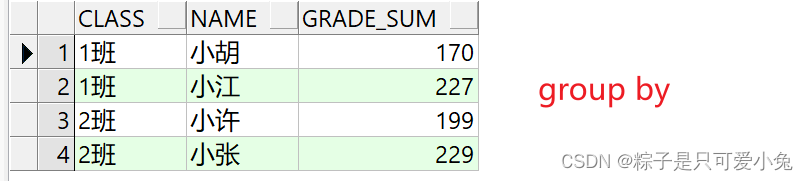
select t.class,t.name,sum(t.grade) grade_sum
from student_score t
where t.import_time = to_date('2023/1/1','yyyy-mm-dd')
group by t.class,t.name
order by t.class;
--group by rollup (column1,column2,……)
select t.class,t.name,sum(t.grade) grade_sum
from student_score t
where t.import_time = to_date('2023/1/1','yyyy-mm-dd')
group by rollup(t.class,t.name)
order by t.class;
--group by rollup ((column1,column2,……))
select t.class,t.name,sum(t.grade) grade_sum
from student_score t
where t.import_time = to_date('2023/1/1','yyyy-mm-dd')
group by rollup((t.class,t.name))
order by t.class;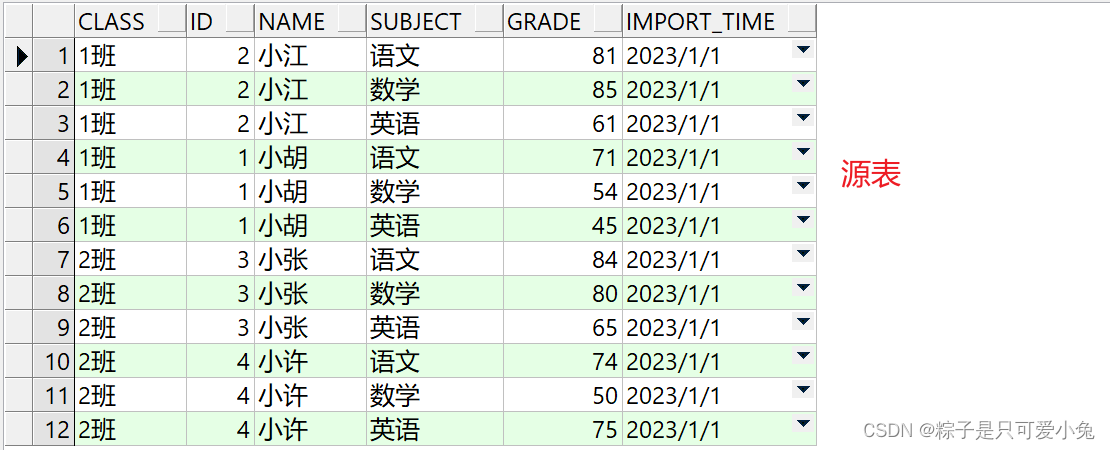


(2)cube
cube:保留原有统计结果的基础上,可以生成横向小计、纵向小计、总计
语法:…… group by cube(column1,column2,……);
…… group by cube((column1,column2,……));--使用复合列,可以略过cube的某些统
计结果
两者区别:
- ……group by cube(a,b,c)的统计结果等同于group by(a,b,c)、group by(a,b)、group by(a,c)、group by(b,c)、group by a、group by b、group by c、group by ()的并集
- ……group by cube(a,(b,c))的统计结果等同于group by(a,b,c)、group by(b,c)、group by a、group by ()的并集
--group by cube(column1,column2,……)
select t.class,t.name,sum(t.grade) grade_sum
from student_score t
where t.import_time = to_date('2023/1/1','yyyy-mm-dd')
group by cube(t.class,t.name)
order by t.class;
--group by cube ((column1,column2,……))
select t.class,t.name,sum(t.grade) grade_sum
from student_score t
where t.import_time = to_date('2023/1/1','yyyy-mm-dd')
group by cube((t.class,t.name))
order by t.class;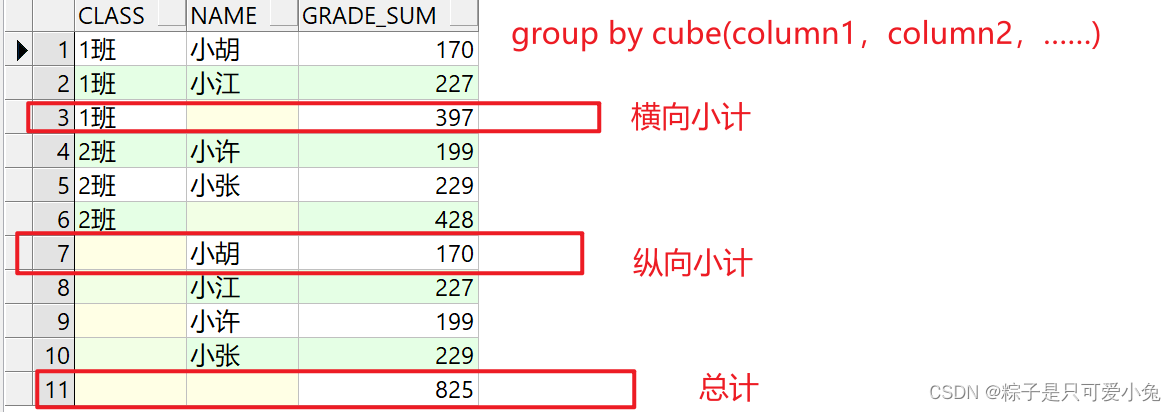

(3)grouping sets
grouping sets:可以实现合并多个分组的统计结果
语法:…… group by grouping sets(column1,column2,……)
--group by grouping sets(column1,column2,……)
select t.class,t.name,sum(t.grade) grade_sum
from student_score t
where t.import_time = to_date('2023/1/1','yyyy-mm-dd')
group by grouping sets(t.class,t.name)
order by t.class;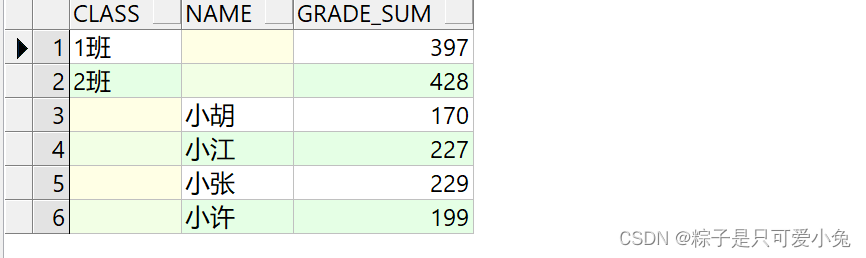
4、多表关联查询
(1)内连接
查询出左右两表中满足连接条件的数据行
语句:
select ……
from table1
[inner] join table2
on table1.column1=table2.column2;
select t1.id,t1.name,t1.class,t2.subject,t2.grade,t1.teacher
from st_info t1
join st_score t2
on t1.id = t2.id
order by t1.id;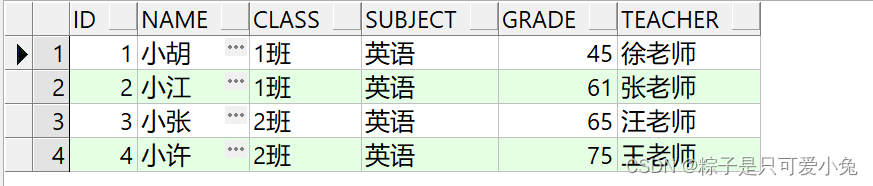
(2)外连接
左外连接、右外连接、全外连接
左外连接
不仅查询出两表中满足连接条件的数据行,也查询出左表中不满足连接条件的数据行
语句:
select ……
from table1
left [outer] join table2
on table1.column1=table2.column2;
select t1.id,t1.name,t1.class,t2.subject,t2.grade,t1.teacher
from st_info t1
left join st_score t2
on t1.id = t2.id
order by t1.id;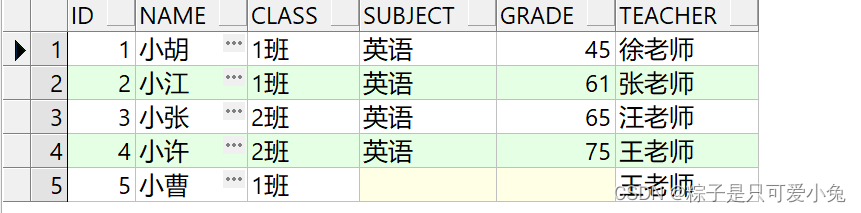
右外连接
不仅查询出两表中满足连接条件的数据行,也查询出右表中不满足连接条件的数据行
语句:
select ……
from table1
right [outer] join table2
on table1.column1=table2.column2;
select t1.id,t1.name,t1.class,t2.subject,t2.grade,t1.teacher
from st_info t1
right join st_score t2
on t1.id = t2.id
order by t1.id;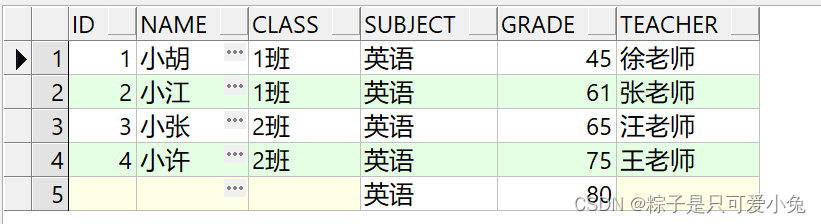
全外连接
首先执行一个完整的左外连接和右外连接,然后再将查询结果合并,消除重复的记录行
语句:
select ……
from table1
full [outer] join table2
on table1.column1=table2.column2;
select t1.id,t1.name,t1.class,t2.subject,t2.grade,t1.teacher
from st_info t1
full join st_score t2
on t1.id = t2.id
order by t1.id;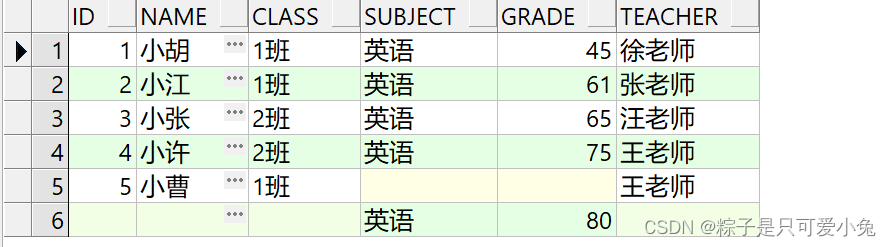
(3)自然连接
自然连接指在检索多张表时,oracle会将第一张表中的列和第二章表中具有相同名称的列进行自动连接。自然连接中不需要明确指定连接列,oracle系统会自动完成
语句:
select ……
from table1
natural join table2
[where 条件]; --相同名称列的限制条件
注意:使用自然连接,两表必须有相同名称的列;且不能为列指定限制词(即表名或者表别名)
select id,name,class,subject,grade,teacher
from st_info
natural join st_score
order by id;
(4)自连接
自连接是在同一张表之间的连接查询,主要用在自参照表上,显示上下级关系或者层级关系,必须要指定表别名
语句:
select ……
from table a
inner | left | right |full join table b
on a.column1 = b.column2;
select t2.ename 领导,t1.ename 员工
from emp t1 left join emp t2
on t1.mgr = t2.empno
order by t1.mgr;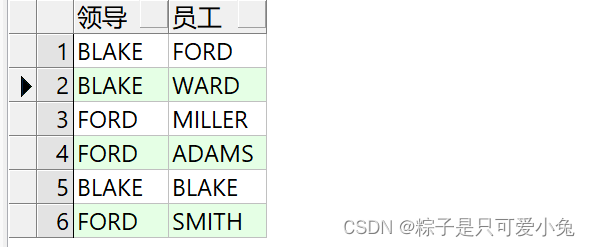
(5)交叉连接
交叉连接不需要任何连接条件,交叉连接的结果会产生笛卡尔积,但是可以通过where子句过滤出需要的数据
语法:
select ……
from table a
cross join table b;
select t1.id,t1.name,t1.class,t2.subject,t2.grade,t1.teacher
from st_info t1
cross join st_score t2
order by t1.id;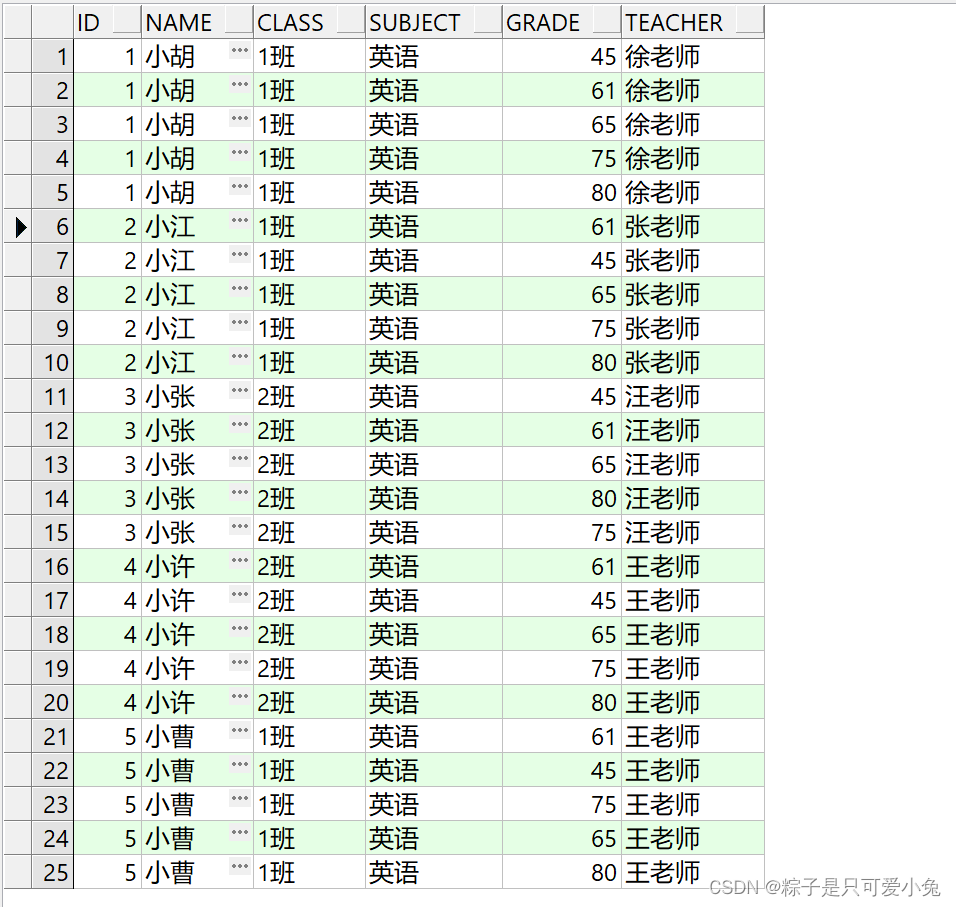
注意点:多表关联查询,on后面限制条件使用and和where关键字的区别
-
数据库在通过连接两张或者多张表来返回记录时,会生成一张中间的临时表,然后再将这张临时表的数据返回给用户,where和and的区别就是这两者筛选的表范围不一样。
-
where是先连接后筛选,也就是对中间生成的临时表数据进行过滤。
-
and是先过滤再连接,and对主表不起过滤作用,对从表有过滤作用
-
and和where的使用对内连接而言没有影响,对外连接有影响
--and
select t1.id,t1.name,t1.class,t2.subject,t2.grade,t1.teacher from st_info t1
left join st_score t2
on t1.id = t2.id
and t1.id = 1
order by t1.id;
--where
select t1.id,t1.name,t1.class,t2.subject,t2.grade,t1.teacher from st_info t1
left join st_score t2
on t1.id = t2.id
where t1.id = 1
order by t1.id;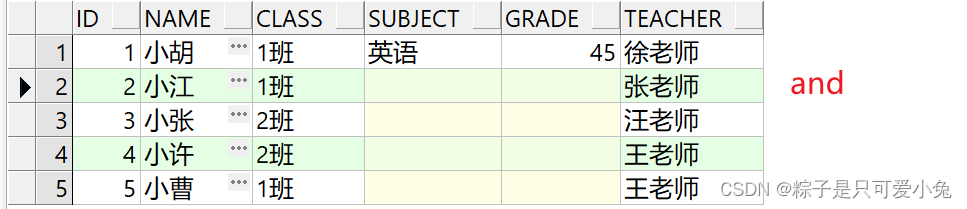
5、子查询
子查询是在sql语句中执行另一条select语句,子查询中不能包含order by子句
(1)单行子查询
单行子查询指返回一行数据的子查询
当在where子句中使用时,可以使用单行比较运算符(=、>、<、>=、<=、<>)
select * from emp t
where t.sal = (select min(t.sal) from emp t);(2)多行子查询
多行子查询指返回多行数据
当在where子句中使用时,必须使用多行比较符(in、any、all)
any运算符必须与单行比较符结合使用,并且返回行只匹配子查询的任意一个结果即可
all运算符必须与单行比较符结合使用,并且返回行必须匹配子查询的所有结果
select * from emp t
where t.sal > any(select t.sal from emp t where t.deptno = 10)--查找工资高于10部分任意一个员工的其他部门的员工信息
and t.deptno <> 10;(3)关联子查询
内查询和外查询时相互关联的,这种子查询称为关联子查询。而前面单行子查询和多行子查询中内查询和外查询时分开执行的,内查询的执行与外查询的执行无关,外查询仅仅使用内查询的最终结果
select * from st_score t1
where t1.class = (select t2.class from st_info t2 where t2.id = t1.id)
order by t1.id ;四、DCL
DCL:数据控制语言,定义数据库、表、用户的访问权限和安全级别
oracle权限分为系统权限、对象权限,系统权限是在系统级对数据库进行存取和使用机制,如用户是否能够连接到数据库系统以及是否可以执行DDL语句;对象权限是指一个用户对其他用户的表、视图、存储过程、函数等进行操作权限
1、grant (授权)
系统授权,语句:grant sys_privi|role to user|role|public [with admin option];
说明:sys_privi指系统权限;role指角色;user指用户;public指oracle系统的所有用户;with admin option指被授权者可以再授权给其他用户
对象授权,语句:grant obj_privi|all column on schema.object to user|role|public [with admin option] [with hierarchy option];
说明:obj_privi指对象的权限(alter、select、update、insert、execute等);with hierarchy option指在对象的子对象上授权给用
户(如在视图上再建视图)
2、revoke(回收权限)
撤销系统权限,语句:revoke sys_privi|role from user|rple|public;
撤销对象权限,语句:revoke obj_privi|all on schema.object from user|role|public cascade constraints;
说明:cascade constraints表示有关联关系的权限也被撤销
3、commit(提交事务)
提交事务指对数据库进行的全部操作持久的保存在数据库中,如DML(insert、update、delete)操作执行后都需要commit,数据才会更新进表中,否则修改后数据只会存在于缓存表中
事务提交的3种方式:
-
显示提交:使用commit命令使当前事务生效
-
自动提交:在SQL*Plus中执行set autocommit on 命令
-
隐式提交:除显示提交之外的提交,如DDL命令、程序中止或关闭数据库等
4、rollback(回滚事务)
回滚事务指撤销对数据库进行的全部操作,oracle利用回退段磊存储修改前的数据,通过重做日志来记录对数据所做的修改
退回整个事务,oracle系统内部执行操作如下:
-
首先使用回退段中的数据撤销对数据库所做的修改
-
oracle后台服务进行释放掉事务所使用的系统资源
-
显示通知,告诉用户事务回退成功
















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









