









堆排序是利用最大堆性质和维护最大堆的操作来进行的排序。
时间复杂度分析:
构建初始的大顶堆的过程时间复杂度为O(n),交换及重建大顶堆的过程中,需要交换n-1次,重建大顶堆的过程根据完全二叉树的性质,[log2(n-1), log2(n-2), …,1]逐步递减,近似为nlogn,所以它最好和最坏的情况时间复杂度都是O(nlogn)。
空间复杂度:
本地操作,空间复杂度O(1)
稳定性:
堆排序是不稳定的排序方法。因为在堆的调整过程中,结点值进行比较和交换走的是该结点到其叶子结点的路径,对于相同的结点值就可能出现排在后面的结点被交换到前面来的情况。
应用:
堆所对应的二叉树为完全二叉树。如果想得到一个序列中前k个最小元素的部分排序序列,最好采用堆排序。
===========================================
还记得堆的一些性质:
堆的索引与数组索引具有特定对应的关系
如果堆是以 1 为起始结点索引的话,数组索引从左到右0,1,2…,对应堆中每个节点的索引顺序,就是对二叉堆层序遍历每个结点的顺序。对于二叉堆的某个结点索引
i
i
i来说,
i
i
i的父结点索引为 i/2,
i
i
i的左子结点索引为 i*2 ,那
i
i
i的右子结点索引就是 i*2+1(左子节点索引+1)。
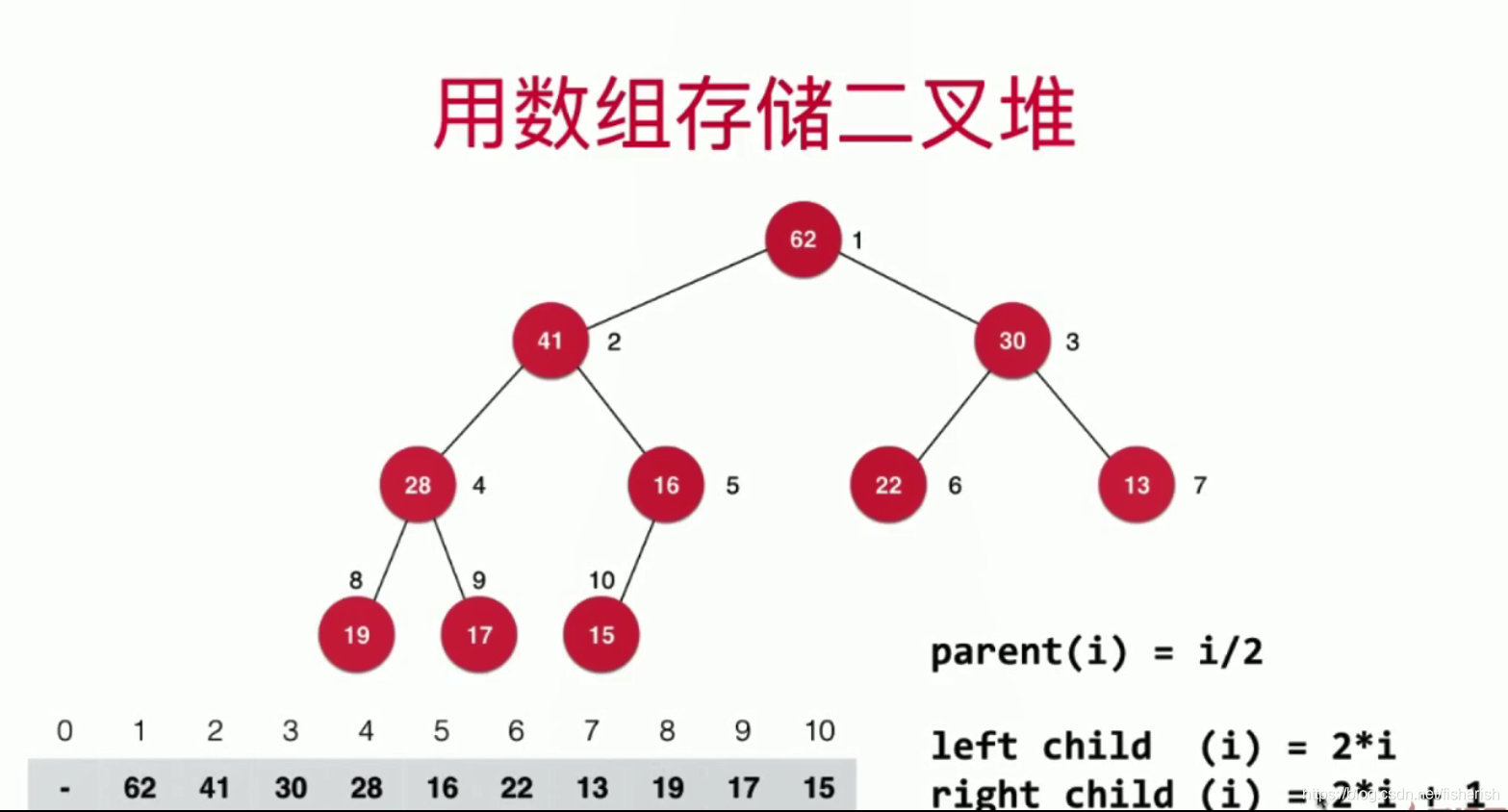
但如果堆是以 0 为起始结点索引的话,数组索引从左到右0,1,2…,对于二叉堆的某个结点索引 i i i来说, i i i的父结点索引为 i/2(左子结点) i/2 - 1(右子结点), i i i的左子结点索引为 i*2 + 1 ,那 i i i的右子结点索引就是 i*2+2(左子节点索引+1)。
这同时也说明为什么习惯上用1作为堆的起始结点索引,因为这样对左右子结点来说,父结点索引的计算就可以统一为 i/2,比较方便计算。
==============================================
代码如下:
public class Main {
public static void main(String[] args) {
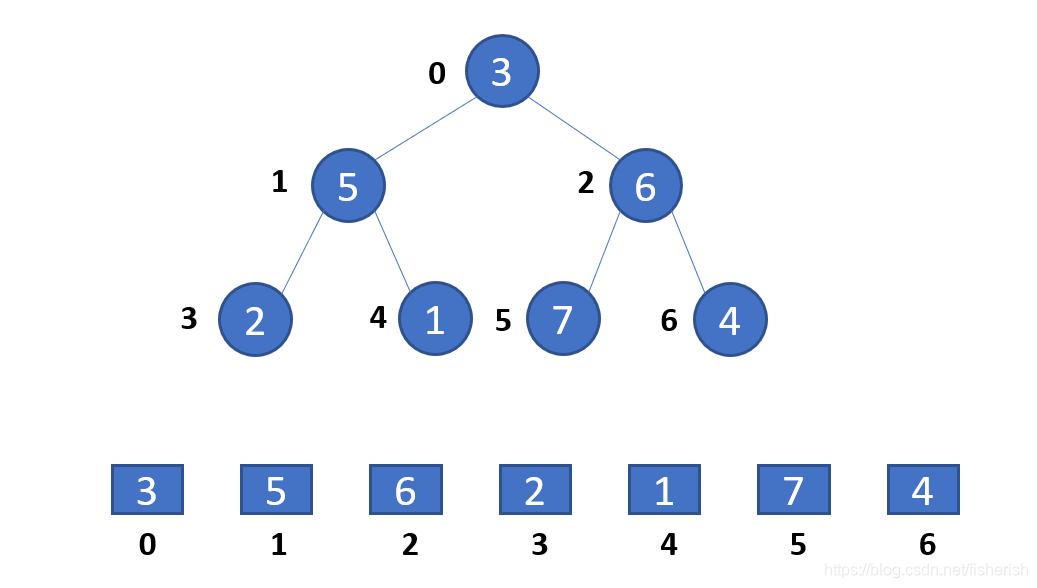
int[] arr = {3, 5, 6, 2, 1, 7, 4};
System.out.print("排序前:");
arrPrint(arr);
HeapSort(arr);
System.out.print("排序后:");
arrPrint(arr);
}
// 堆排序
//
// 第一个for循环,目的是将数组初始化为最大堆数组(在本实例中转为[7, 5, 6, 2, 1, 3, 4])。
// 从最后一个非叶结点索引i=len/2 - 1开始遍历,倒叙遍历,直到堆顶结点0。
// heapify函数是一种不完全的堆化,可以将遍历结点i及其部分子二叉堆转化为最大二叉堆,
// 我们用for循环从最后的非叶结点开始倒序遍历,可以覆盖到整个二叉堆。
// (不知道为什么是len/2-1,可以假想最后一个结点len-1的后面还有一个虚拟结点len,
// 当结点len是左子结点时,len的父结点len/2的上一个结点len/2 - 1 一定是最后一个非叶结点。
// 当结点len是右子结点时,len的父结点len/2-1同样一定是最后一个非叶结点。
// 严格证明可以看看 https://blog.csdn.net/qq_34629352/article/details/105591415 )
//
// 第二个for循环,从尾到头倒序遍历二叉堆所有结点,遍历索引为j,
// 循环中,交换0和j元素,即把最大值交换到堆(数组)末端的j位置,
// 之后调用heapify(以0为函数遍历结点,长度边界为j),可将0到j-1的子二叉堆进行堆维护,
// 即0到j-1中的最大值上升到堆顶0的位置处。如此循环,j在倒序遍历的过程中,子二叉堆堆顶
// 的最大值会不断地交换到j遍历位置,交换完,子二叉堆进行维护,新的最大值重新上升到堆顶,
// 待循环结束,排序就完成了。
private static void HeapSort(int[] arr) {
int len = arr.length;
for (int i = len / 2 - 1; i >= 0; i--) {
heapify(arr, i, len);
}
for (int j = len - 1; j > 0; j--) {
swap(arr, 0, j);
heapify(arr, 0, j);
}
}
// 堆化函数/堆维护函数
// 输入为:最大堆数组arr,遍历的结点索引i,长度边界len,堆维护的操作范围是i到len-1
// heapify实际是将遍历结点i,及遍历结点i的左右子结点,及左右子结点中较大结点的左右子结点
// (以此顺延下去),这些结点构成的子二叉堆进行堆化操作。
//
// 将当前遍历结点值arr[i]记为temp。
// for循环:起始为遍历结点i的左子节点k=i*2+1,在k超过len-1时终止,
// 变化条件为k继续取k的左子节点,即k=k*2+1。
// 第一个if:保证i的右子结点k+1不越界,如果i的右子结点大于左子结点值,
// 则k指向右结点。
// 第二个if,如果k的结点值arr[k]比父结点i的结点值arr[i]=temp要大,
// 此时不满足堆的性质,则将子结点k赋给父结点i,arr[i]值赋为arr[k]
// i修改为k。if不满足,循环直接结束。
// 最后将temp给i所在的结点(此时i是原来的k),完成i和k结点的交换。
private static void heapify(int[] arr, int i, int len) {
int temp = arr[i];
for (int k = i*2 + 1; k < len; k = k*2 + 1) {
if (k + 1 < len && arr[k] < arr[k + 1]) {
k++;
}
if (arr[k] > temp) {
arr[i] = arr[k];
i = k;
}
else {
break;
}
}
arr[i] = temp;
}
// 交换位置函数
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 辅助函数:将int[] 打印出来
private static void arrPrint(int[] arr) {
StringBuilder str = new StringBuilder();
str.append("[");
for (int v : arr) {
str.append(v + ", ");
}
str.delete(str.length() - 2, str.length());
str.append("]");
System.out.println(str.toString());
}
}
我们对堆排序的实例的动画演示如下:
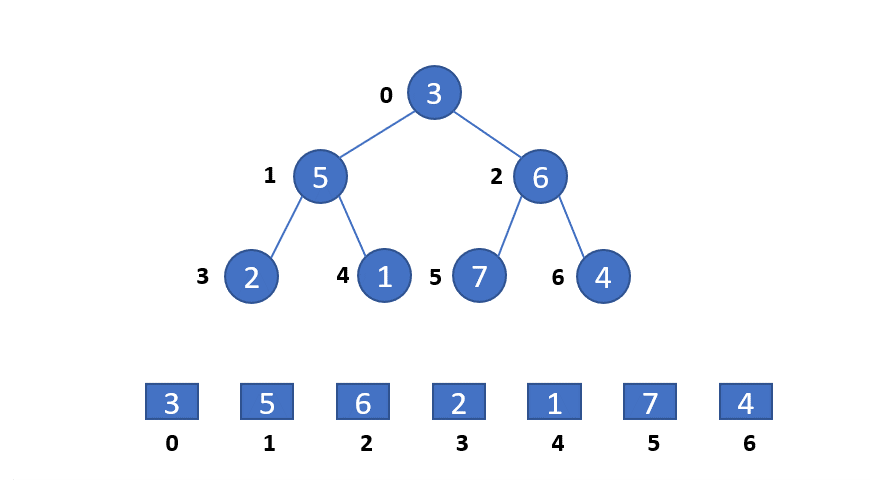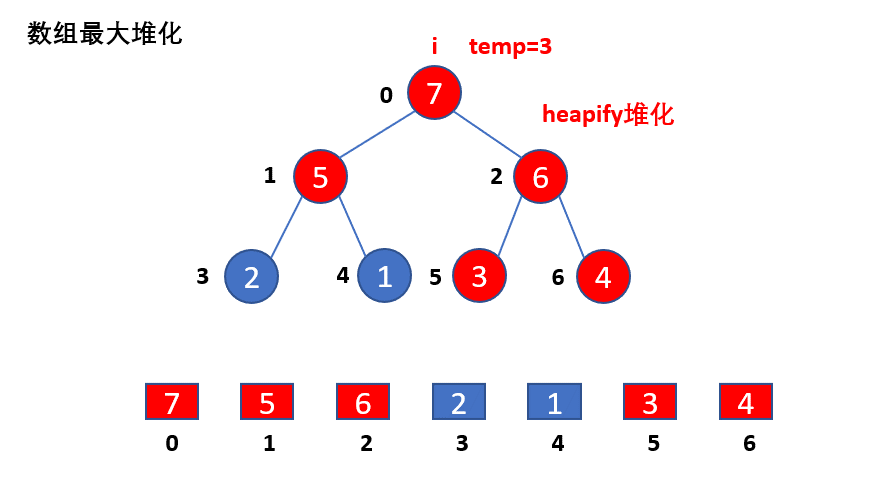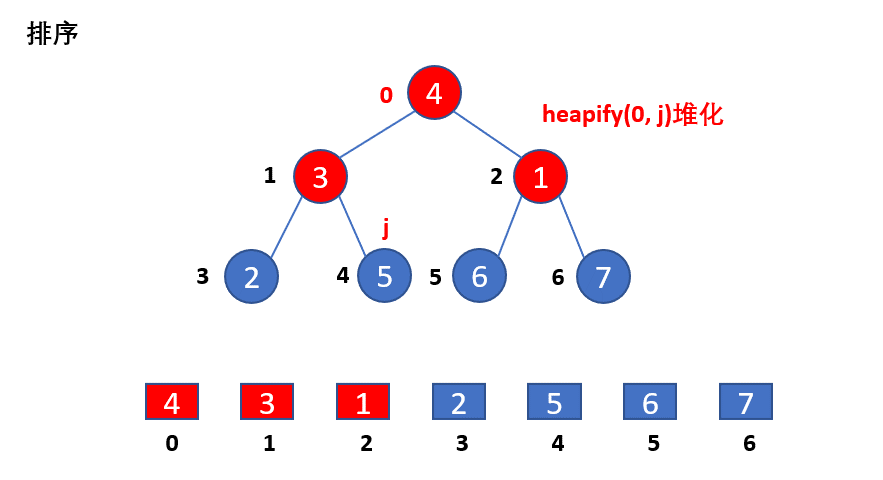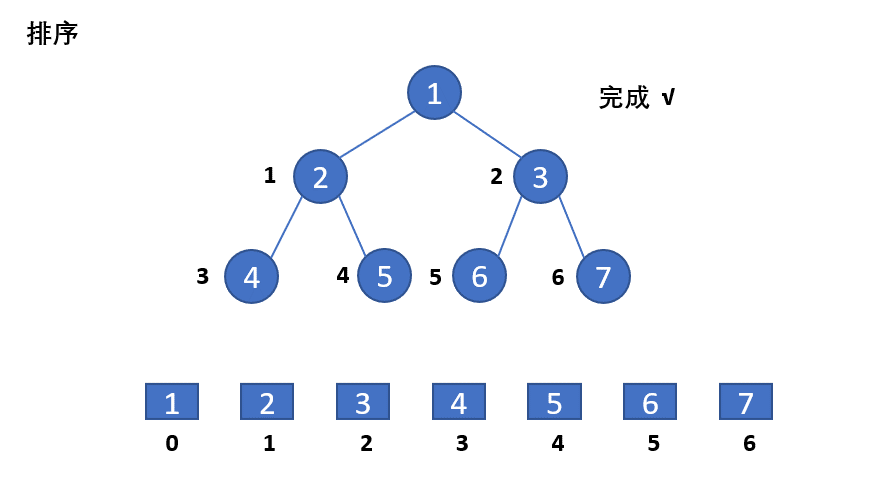
heapify函数的演示如下:
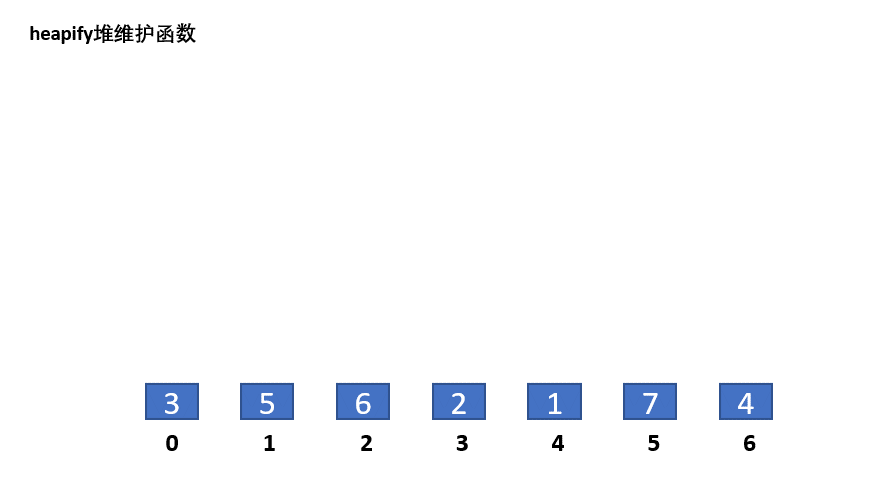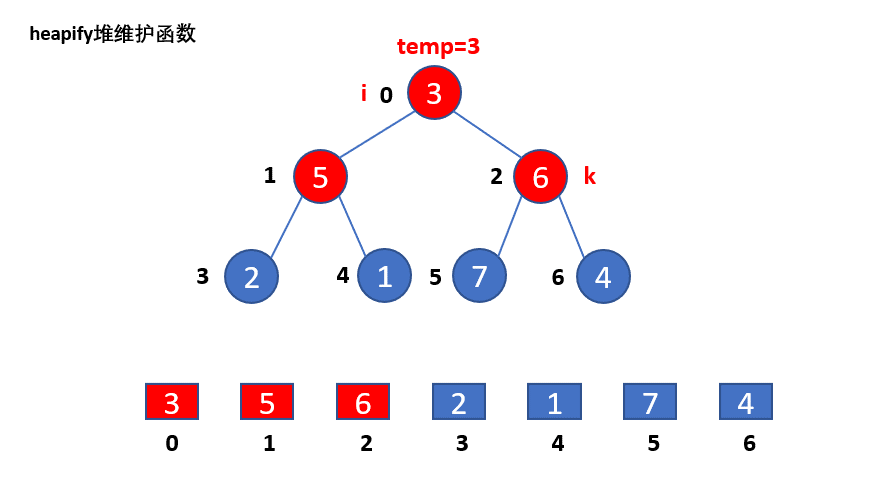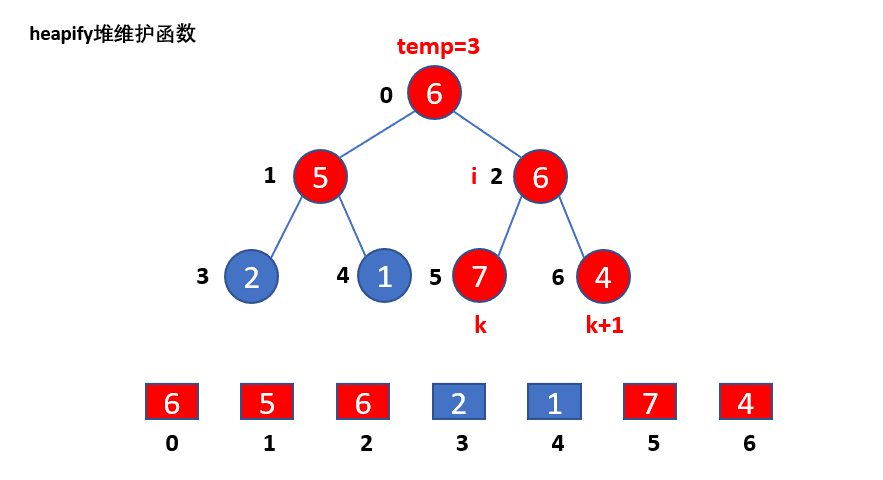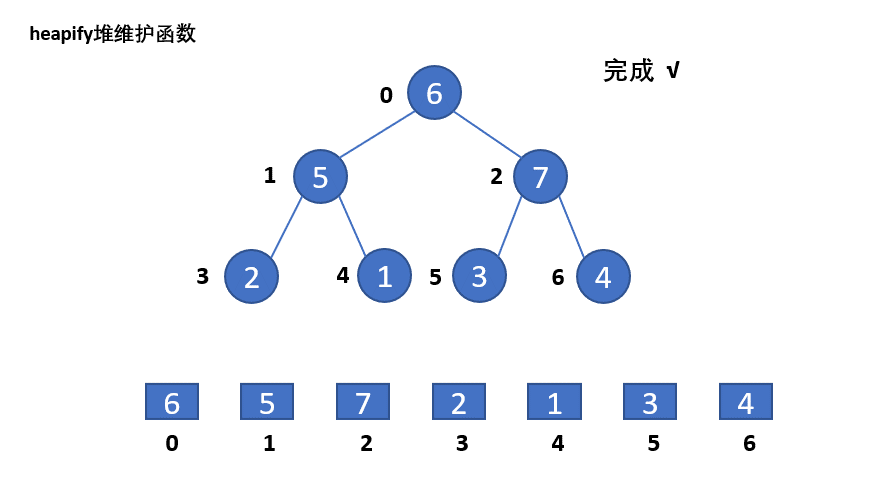
可以看到,只使用一次heapify函数无法对堆化整个数组。
参考:
https://blog.csdn.net/qq_28063811/article/details/93034625

















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











