







1、KNN分类算法
KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法。
他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本“距离”最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类。简单的说就是让最相似的K个样本来投票决定。
这里所说的距离,一般最常用的就是多维空间的欧式距离。这里的维度指特征维度,即样本有几个特征就属于几维。
KNN示意图如下所示。(图片来源:百度百科http://baike.baidu.com/view/1485833.htm?from_id=3479559&type=syn&fromtitle=knn&fr=aladdin)
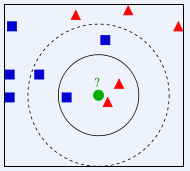
上图中要确定测试样本绿色属于蓝色还是红色。
显然,当K=3时,将以1:2的投票结果分类于红色;而K=5时,将以3:2的投票结果分类于蓝色。
KNN算法简单有效,但没有优化的暴力法效率容易达到瓶颈。如样本个数为N,特征维度为D的时候,该算法时间复杂度呈O(DN)增长。
所以通常KNN的实现会把训练数据构建成K-D Tree(K-dimensional tree),构建过程很快,甚至不用计算D维欧氏距离,而搜索速度高达O(D*log(N))。
不过当D维度过高,会产生所谓的”维度灾难“,最终效率会降低到与暴力法一样。
因此通常D>20以后,最好使用更高效率的Ball-Tree,其时间复杂度为O(D*log(N))。
人们经过长期的实践发现KNN算法虽然简单,但能处理大规模的数据分类,尤其适用于样本分类边界不规则的情况。最重要的是该算法是很多高级机器学习算法的基础。
当然,KNN算法也存在一切问题。比如如果训练数据大部分都属于某一类,投票算法就有很大问题了。这时候就需要考虑设计每个投票者票的权重了。
2、测试数据
测试数据的格式仍然和前面使用的身高体重数据一致。不过数据增加了一些:
3、Python代码
scikit-learn提供了优秀的KNN算法支持。使用Python代码如下:
4、结果分析
其输出结果如下:
[ 0. 0. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 1.]
[ 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 0. 1. 1. 0. 1.]
准确率=0.94, score=0.94
precision recall f1-score support
thin 0.89 1.00 0.94 8
fat 1.00 0.89 0.94 9
avg / total 0.95 0.94 0.94 17
1、KNeighborsClassifier可以设置3种算法:‘brute’,‘kd_tree’,‘ball_tree’。如果不知道用哪个好,设置‘auto’让KNeighborsClassifier自己根据输入去决定。
2、注意统计准确率时,分类器的score返回的是计算正确的比例,而不是R2。R2一般应用于回归问题。
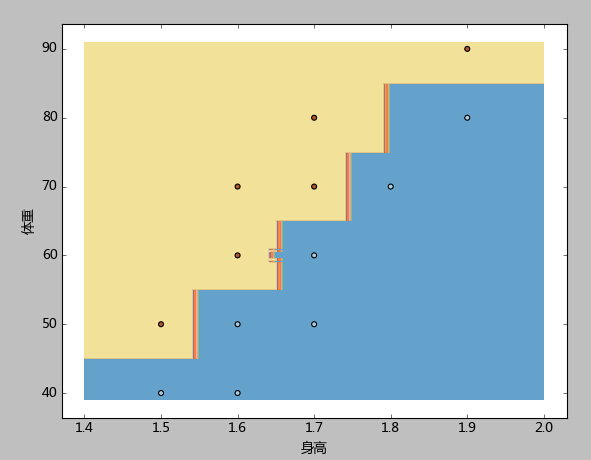
3、本例先根据样本中身高体重的最大最小值,生成了一个密集网格(步长h=0.01),然后将网格中的每一个点都当成测试样本去测试,最后使用contourf函数,使用不同的颜色标注出了胖、廋两类。
容易看到,本例的分类边界,属于相对复杂,但却又与距离呈现明显规则的锯齿形。
这种边界线性函数是难以处理的。而KNN算法处理此类边界问题具有天生的优势。我们在后续的系列中会看到,这个数据集达到准确率=0.94算是很优秀的结果了。















 2135
2135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









