






您辛苦了很长时间,编写了一套很不错的管理软件,行业使用很不错,代码行10万+,有一天一位外国客户找到您,说想购买使用您的软件,但显示语言需要是英语的,三五天内就要使用,你怎么办?
或者,您获取到一套很不错的含代码的大型开源软件,想全面学习借鉴一下,可惜注释和显示文字都是英文的,甚至可能是德文的.....一点一点翻译吧,太费时间了!
又或者,有好几个软件想翻译出来学习一下,人工一点一点翻译,不知道要花多长时间!
再或者,系统中使用了一个字符串,字符串本身当初表达意义不太明确,我就是想把它表达明确了,要换个字符串名称,一个一个去修改?可能涉及所有文件啊,会不会遗漏了几个没找到呢!
更有甚者,我原来编写代码时考虑不周,都没有考虑到要限制用户的打印权限,一个一个地方去加上?我自己都感觉确实难办呀!
......
上面这些,需要人工打开每个文件,然后点开每个方法,小心翼翼全面搜索替换?人工一个地方一个地方翻译过来?我曾经这样干过,因为不堪过程漫长,然后就是穷则思变、差则思勤,有没有一个比较有效的工具呢?问了一下度娘,还有古哥,都说没有见过,偶尔有那么一个远房亲戚,基本上是能力都比较低下,这也很麻烦呀!
没办法,为了多快好省,为了今后的方便,为了更多地省下自己宝贵的时间,只能自己上手,于是就有了现在这个辅助工具《VFP源程序显示信息及注释文本等批量提取与翻译后写入》,名称而已,可能不能表达其所包含的各种功能。
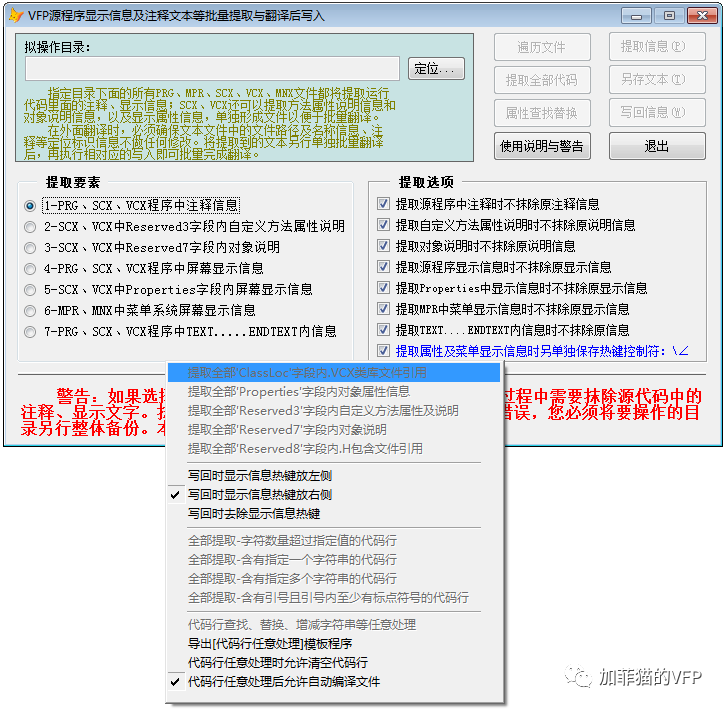
一、辅助工具功能
1、可以一次性提取指定目录下全部(下同)PRG、SCX、VCX文件中的程序行注释信息,包括行前注释与行后注释;
2、可以提取SCX、VCX文件中Reserved3字段内的自定义方法属性的说明信息;
3、可以提取SCX、VCX文件中Reserved7字段内的对象的说明信息;
4、可以提取SCX、VCX文件中Properties字段内的屏幕显示文字信息;
5、可以提取PRG、SCX、VCX文件中程序行里面的屏幕显示文字信息;
6、可以提取MPR、MNX文件中菜单系统的屏幕显示文字信息;
7、可以提取PRG、SCX、VCX文件中TEXT...ENDTEXT区间内的文本输出行信息;
8、上述提取出来的信息可以另存为文本文件;
9、上述保存的文本文件可以另行批量、集中修改或者翻译;
10、上述提取各种信息时可以选择是否抹除原信息;
11、抹除原信息后,可以将上述文本文件再按照对应关系将修改或翻译后的信息一次性自动全部写回程序中。在写回方法或过程中,代码行发生变化时会生成原始代码与修改后的代码的对照日志;
12、在提取和写回过程中,如果发生文件打开或者写入错误,会生成错误日志文件;
13、程序还可以一键提取目录下所有文件的全部代码、全部属性、全部自定义方法属性、全部对象说明,用于从整体上研读系统的功能。
二、辅助工具作用
1、可以对提取出来的信息进行批量修改,达到修改的目的,可以无数倍提高效率;
2、可以对提取出来的信息进行批量翻译,达到翻译的目的,可以无数倍提高效率;
3、可以对提取出来的信息进行批量整理,整理后文件修改为.h包含文件格式,可以作为编译常量使用,主要用于国际化多语言场所。
4、也可以仅仅是提取出来慢慢研习一下……
三、辅助工具基本操作
1、第一步是执行信息提取;
2、第二步是对刚才提取到的信息另存为文本文件;
3、第三步是对保存的文本文件进行修改、翻译;
4、第四步是对修改、翻译后的文本文件执行写回。
四、提取与回写的实现原理
1、以递归方式遍历指定目录下的全部文件,并记录;
Dimension amDIR(1,5),amFILE(1,5),amERR(1) &&定义总数组
amDIR(1,1)=Addbs(cDrvmc) 。
amDIR(1,2)=''
amDIR(1,3)=Date()
amDIR(1,4)=Time()
amDIR(1,5)='....D'
Store 1 To nCountDir
Store 0 To nCountFile,nCountErr
nIarr=1
DO WHILE m.i<=nCountDir &&开始扫描指定磁盘或磁盘目录
nNum=ADIR(aDIRtmp,amDIR(m.i,1)+'*.*','RASHD') &&获取指定目录下所有信息,这时候还没有遍历其下面的子目录
IF nNum < 1
nCountErr = nCountErr + 1
DIMENSION amERR[nCountErr] &&重新定义总数组
amERR[nCountErr] = "Error:" + amDIR(m.i,1)
ELSE
FOR I=IIF(m.i<=1,1,3) TO nNum &&记录全路径并将新获取数据添加到总数组中,除根目录外跳过.和..
IF 'D'$aDIRtmp(I,5) AND !INLIST(aDIRtmp(I,1),".","..")
aDIRtmp(I,1)=amDIR(m.i,1)+aDIRtmp(I,1)+'\'
nCountDir=nCountDir+1 &&目录数组增加一行
DIMENSION amDIR(nCountDir,5)
FOR ai=1 TO 5
amDIR(nCountDir,ai)=aDIRtmp(i,ai)
ENDFOR
ELSE
aDIRtmp(I,1)=amDIR(m.i,1)+aDIRtmp(I,1)
nCountFile=nCountFile+1
DIMENSION amFILE(nCountFile,5)
FOR ai=1 TO 5
amFILE(nCountFile,ai)=aDIRtmp(i,ai) &&找到的文件
ENDFOR
ENDIF
ENDFOR
ENDIF
m.i=m.i+1
ENDDO2、在操作过程中,只对VFP代码文件PRG、SCX、VCX、MPR、MNX进行操作;
SCAN
cFilename=ALLTRIM(wjmc)
cExtname='|'+UPPER(JUSTEXT(cFilename)) &&取文件扩展名
IF AT(cExtname,"|PRG|MPR|SCX|VCX")=0 &&不是要操作的文件类型
LOOP
ELSE
nChange=THISFORM.getAllCode(cFilename) &&提取该文件中的代码行信息
SELECT Mydbf
ENDIF
ENDSCAN3、对上面提取到的代码行,逐行取出,并根据功能需求提取备注信息、显示信息等,并在提取完字符串后,是否在原位置抹除原字符串,如果要抹除原信息,需要在该位置留下定位标识字符串,以便于回写时定位识别用,下面示例是提取备注信息的总控代码;、
DO CASE
CASE cExtname="PRG"
cPrgCode=FILETOSTR("&cFilename") &&prg代码存入字符串中
nAll=ALINES(aTemp_1A, cPrgCode,8) &&将字符串的每一行存入数组中
cNotes=THISFORM.GetNoteLine(cFilename,@aTemp_1A,"") &&提取这个数组里面的注释信息,cNotes是抹除注释信息后的字符串下面是代码行对是否是备注信息的计算:
DO CASE
CASE SUBSTR(cCurLineTrim,1,1)="*" &&以"*"打头的行前注释
nleft=AT("*",cCurLine,1) &&因为要保留星号前面的空格,所以使用cCurLine变量
lCurLineBefore=.T.
CASE SUBSTR(cCurLineTrim,1,2)="&"+"&" &&以"&&"打头的行前注释,两个这个符号不能同时放在一起
nleft=AT("&"+"&",cCurLine,1)+1
lCurLineBefore=.T.
CASE UPPER(SUBSTR(cCurLineTrim,1,5))="NOTE "&&以"note "打头的行前注释,必须有一个空格
nleft=AT("NOTE ",UPPER(cCurLine),1)+4
lCurLineBefore=.T.
CASE AT("&"+"&",cCurLineTrim)#0 &&以"&&"引导的行后注释
nleft=AT("&"+"&",cCurLine,1)+1
lCurLineBefore=.F.
OTHERWISE
nleft=99999 &&指定一个不可能的超级大的数
lCurLineBefore=.F.
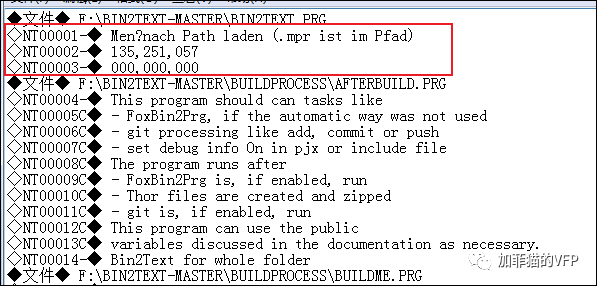
ENDCASE下面是原文件中被提取了3处备注信息,并留下了◇NT00001-◆等3个位置标识:
_SCREEN.CAPTION = ' - SF Bin2Text'
* ◇NT00001-◆
DO lcDrive+'\SE\TOOLS\Start_Project.prg' WITH;
lcProg,
'NONE',;
RGB(000,000,255),; && ◇NT00002-◆
RGB(255,255,255),; && ◇NT00003-◆
'Graphics\Tools.ico'下面是提取到的备注信息形成的单独文本文件,其中前3个就是对应上面示例中的:
4、对提取到的文本文件,可以批量复制到网上自动翻译系统,比如谷歌翻译、百度翻译,只要总字符数不超过其限制就行了。或者有能力直接使用文档翻译,一键全文翻译。如果是注释信息,自动翻译结果是不是就可以直接使用了,但是对于显示信息,由于需要精确表达,自动翻译完成后,最好人工再逐个检查复核一遍,不合适的地方进行修正。
5、将翻译后的文本,分别对照“提取要素”的7个方面,执行右上角的<写回信息>,下面是写回信息的核心代码部分:
ctjwFlags=ALLTRIM(SUBSTR(cCurline,1,AT(" ",cCurline,1)-1)) &&前面的◇NT00001◆标识
ctjwWords=ALLTRIM(SUBSTR(cCurline,AT(" ",cCurline,1)+1)) &&翻译后的文本
nRow=ASCAN(aTemp_9A,UPPER(ctjwFlags)) &&数组中快速查找定位标识
IF nRow<=ALEN(aTemp_9A,1)
aTemp_9A(nRow)=STRTRAN(aTemp_9A(nRow),ctjwFlags,ctjwWords) &&用翻译后文本替换掉定位标识
ELSE
cErrString=cErrString+"文件:"+"&cNewFile"+'内,定位标识:'+ctjwFlags+"未找到"+CHR(13)+CHR(10) &&记录错误日志
ENDIF五、鼠标右键“代码行查找、替换、添加、删除任意处理”实现的高级应用
通过菜单选择这项功能时,可以对程序中的代码行实现查找、替换、添加、删除等任意您想做的各种处理。
实现原理:本辅助工具里面操作目录下的所有文件,从文件内提取代码行,然后逐行传递给辅助工具外部的单独的处理程序(初步命名为“代码行任意处理.PRG”,简称为“Hand.prg”), Hand.prg根据编写的处理条件和处理方法,对代码行进行任意处理,然后返回处理结果, 辅助工具里面将结果进行保存,就达到了任意处理代码行的目的。
目的:任何时候、对任何目录内全部程序文件,可以在本程序内临时编写处理代码行的程序,达到对代码行按条件任意进行查找、替换、删除、添加的目的。
下面是任意处理的核心调用代码:
FOR m.ian=1 TO ALEN(aTemp_1A)
cCurLine=aTemp_1A(ian) &&取出一行
cAfterProc=代码行任意处理(cCurLine) &&到外部文件去处理代码行
IF !EMPTY(cAfterProc) &&当成功处理后,返回处理结果;如果不符合处理条件,返回空
IF UPPER(ALLTRIM(cCurLine))#UPPER(ALLTRIM(cAfterProc)) &&代码有变化
THISFORM.aCodeProcing(ALEN(THISFORM.aCodeProcing,1),1)=cFilename &&第1列是文件名,含全路径
THISFORM.aCodeProcing(ALEN(THISFORM.aCodeProcing,1),2)=cUniqueFld &&第2列标识唯一的字段记录
THISFORM.aCodeProcing(ALEN(THISFORM.aCodeProcing,1),3)=ALLTRIM(cCurLine) &&第3列为原代码行
THISFORM.aCodeProcing(ALEN(THISFORM.aCodeProcing,1),4)=ALLTRIM(cAfterProc) &&第4列为处理后的代码行
DIMENSION THISFORM.aCodeProcing(ALEN(THISFORM.aCodeProcing,1)+1,4) &&代码行数组增加一行
ENDIF
aTemp_1A(ian)=cAfterProc &&将处理后的代码行写回数组
ELSE
aTemp_1A(ian)=cCurLine &&如果得到空,此处不做任何改变
ENDIF
ENDFOR下面是外部程序“代码行任意处理.PRG”的实现过程:
FUNCTION 代码行任意处理
LPARAMETERS cOldCode
cCurLineTrim=ALLTRIM(cOldCode) &&去掉空格是为了计算方便
IF EMPTY(cCurLineTrim)
RETURN ""
ENDIF
cNewCode=""
cTailString="" &&代码行尾部的分号以及注释字符串
*1、=====要进行处理需满足的基本处理条件, 可以根据需要设定 ==================
IF "tors"$LOWER(cOldCode ) &&处理条件,只有满足条件的才能进行相关分析处理,$ 区分大小写[这里的条件很关键,需要设定很严格的条件]
*2、=====对原代码行预处理 ======================================
DO CASE &&对行后注释及分号进行预处理
CASE AT("&"+"&",cCurLineTrim,1)=1 &&行前注释
RETURN "" &&对行前注释不进行任何处理,除非您需要
CASE SUBSTR(cCurLineTrim,1,1)="*" &&以"*"打头的行前注释
RETURN ""
CASE SUBSTR(cCurLineTrim,1,2)="&"+"&" &&以"&&"打头的行前注释
RETURN ""
CASE UPPER(SUBSTR(cCurLineTrim,1,5))="NOTE "&&以"note "打头的行前注释,必须有一个空格
RETURN ""
CASE AT("&"+"&",cCurLineTrim,1)>1 &&以"&&"引导的行后注释
nNotePos=AT("&"+"&",cOldCode,1)
cTailString =SUBSTR(cOldCode,nNotePos) &&行后的注释部分
cFrontString=LEFT(cOldCode,nNotePos-1) &&注释前面的部分
IF RIGHT(RTRIM(cFrontString),1)=";" &&尾部还有分号
nSpace=LEN(cFrontString)-RAT(";",cFrontString,1)-1 &&分号与&&之间的空格数量
cTailString =";"+REPLICATE(" ",nSpace)+cTailString
cNewCode=RTRIM(LEFT(cFrontString,RAT(";",cFrontString,1)-1))
ELSE
cNewCode=RTRIM(cFrontString) &&对原代码行仅可以去掉右面的空格
cTailString =REPLICATE(' ',LEN(cFrontString)-LEN(cNewCode))+cTailString
ENDIF
CASE RIGHT(cCurLineTrim,1)=";" &&尾部是分号
cTailString =" ;"
cNewCode=RTRIM(LEFT(cOldCode,RAT(";",cOldCode,1)-1))
OTHERWISE
cNewCode=RTRIM(cOldCode)
ENDCASE
*3、======这里具体编写对该代码行要进行的处理, 可以根据需要编写=============
* 下面示例只是替换字符串,实际上可以作很多你想做的工作
cNewCode=STRTRAN(cNewCode,"tors","EQtoRS",-1,-1,1) &&不区分大小写
*4、=====将处理后的代码行信息还原 =======================
cNewCode=cNewCode+cTailString &&将行后注释等信息还附加回去
RETURN cNewCode
ENDIF此PRG文件放在外面的原因,是因为每一次要使用的条件,要进行的增删查改工作任务都不一样,需要根据实际需要进行修改,不能固化,您想做什么工作,在第3步骤里面详细些就行,这样就可以实现你想做的各种各样的工作。
prg文件内的处理代码,对于条件的判断应精确,处理方法要科学,否则全目录内那么多文件和代码,可能会出现不可预期的结果;
处理过程有详细的处理日志,认真研读本程序处理过程的日志文件,对比看看哪些代码行不符合预期要求,想办法找到那个文件及其代码行位置,人工修正一下:
FOR m.ui=1 TO ALEN(THISFORM.aCodeProcing,1)
cstring=cstring+CHR(13)+CHR(10)
cstring=cstring+"文件名:"+THISFORM.aCodeProcing(ui,1)+CHR(13)+CHR(10)
cstring=cstring+"记录名:"+THISFORM.aCodeProcing(ui,2)+CHR(13)+CHR(10)
cstring=cstring+"原代码:"+THISFORM.aCodeProcing(ui,3)+CHR(13)+CHR(10)
cstring=cstring+"新代码:"+THISFORM.aCodeProcing(ui,4)+CHR(13)+CHR(10)
ENDFOR六、经过全局处理的代码的安全性
1、代码修改前后是可验证的
使用本辅助工具对一个目录的全部文件进行提取与写入,到底是否会出现错误,是否真正达到了目的,主要有以下方法来验证:
(1)使用右上角的“提取全部代码”来完成提取,提取一次另存为一个单独的文件,按第一阶段做好标识,这个提取是提取系统下的全部代码;
(2)分别选择下面的“提取要素”,和取消“提取选项”的勾选,使用右上角的“提取信息”,和另存文本;
(3)七项提取要素均完成后,提取出来的文本不要做任何修改,再逐项将刚才提取的信息再写入回去;
(4)再次点击“提取全部代码”,存为一个单独的文件,按第二阶段做好标识;
(5)使用Compare it等类似软件对比阶段1和阶段2的文本文件,应该显示“文件是相同的”,最多也仅仅是个别空格不一致,验证了代码提取并抹除部分以后,如果原样写回去,整个系统中的代码是完全相同的,证明系统的代码是安全的。
(6)如果对提取出来的文本进行了翻译等修改,上述第(5)步骤进行对比时,会发现所有修改过的地方的详细对比情况。
2、代码修改是有对照日志的
对代码行的修改,凡是对比发现有改动的,都作为修改对照日志记录下来并保存为日志文本,在对照日志里面可以发现哪些地方进行了改动。
3、在注释信息写入、程序中显示信息写入、MPR菜单写入时,会即时进行编译,如果出现错误,会第一时间发现。
4、总体写入完毕后,可以对项目进行一次整体编译、试运行,看看有没有错误发生。
5、理论上,是不会出现任何错误的。如果发生了错误情况,一般是由于文件的打开出现了异常(有些文件名称含特殊符号时会出现打开异常),对程序的读、写理论上是不会出现问题的。
6、每个人的编程方式千差万别,对于代码行的信息改动,本工具不能保证100%完整适合所有人编写的各种各样的VFP软件代码,但是经过本人对于几个大型VFP软件的测试,没有发现不满足要求的地方。
猫猫的心里话
加菲猫的VFP|狐友会社群接收投稿啦
加菲猫的VFP,用VFP不局限VFP,用VFP混合一切。无论是VFP,还是JS,还是C,只要能混合起来,都可以发表。
商业模式,销售技巧、需求规划、产品设计的知识通通可以发表。
暂定千字50元红包,,优秀的文章红包更大,一经发表,红包到手。
如何帮助使用VFP的人?
用VFP的人,有专业的,有非专业了,很多人其实是小白,问出的问题是小白,如果问题不对,我们引导他们问正确的问题。无论如何请不要嘲笑他们说帮助都不看,这么简单的问题都不会,嘲笑别人不行,而无法提出建设性答案,是很low的。
我们无论工作需要,还是有自己的软件,都是是需要真正的知识,如何让更多人学习真正的VFP知识呢,只需要点赞,在看,能转发朋友圈就更好了。
加菲猫的vfp倡导用"VFP极简混合开发,少写代码、快速出活,用VFP,但不局限于VFP,各种语言混合开发"。
我已经带领一百多名会员成功掌到VFP的黑科技,进入了移动互联网时代,接下来我们要进入物联网领域。
2023年狐友会社群会员继续招募中
社群会员获取的权益有:
祺佑三层开发框架商业版(猫框),终身免费升级,终身技术支持。
开放的录播课程有:
微信小程序,微信公众号开发,H5 APP开发,Extjs BS开发,VFP面向对象进阶,VFP中间层开发。
源码类资源有:
支付组件源码,短信源码,权限组件源码,一些完整系统的源码。这个可以单独出售的,需要的可以联系我。
会员也可以实现群内资源对接,可以接分包,合作等各项商业或技术业务



















 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











