







注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流。
1. 理论部分
1.1 Hadoop是什么?
1.2 Hadoop 生态圈
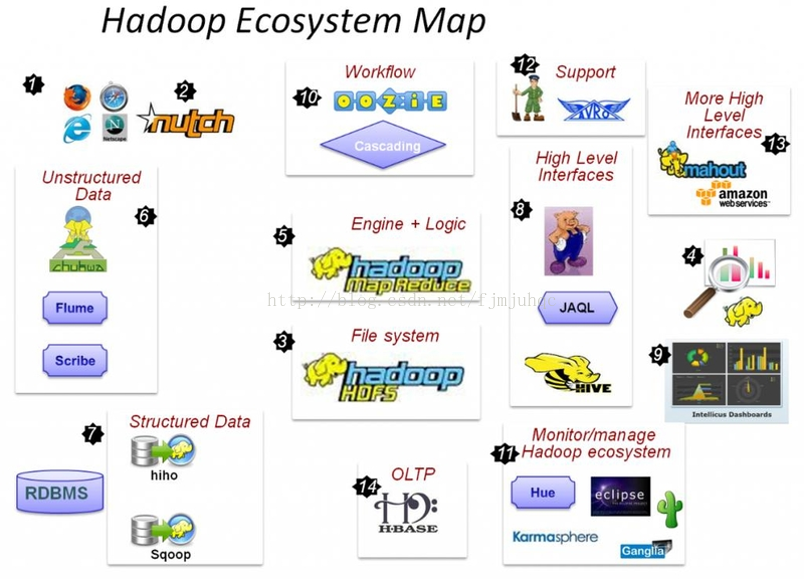
1.3 Hadoop和虚拟化的差异点
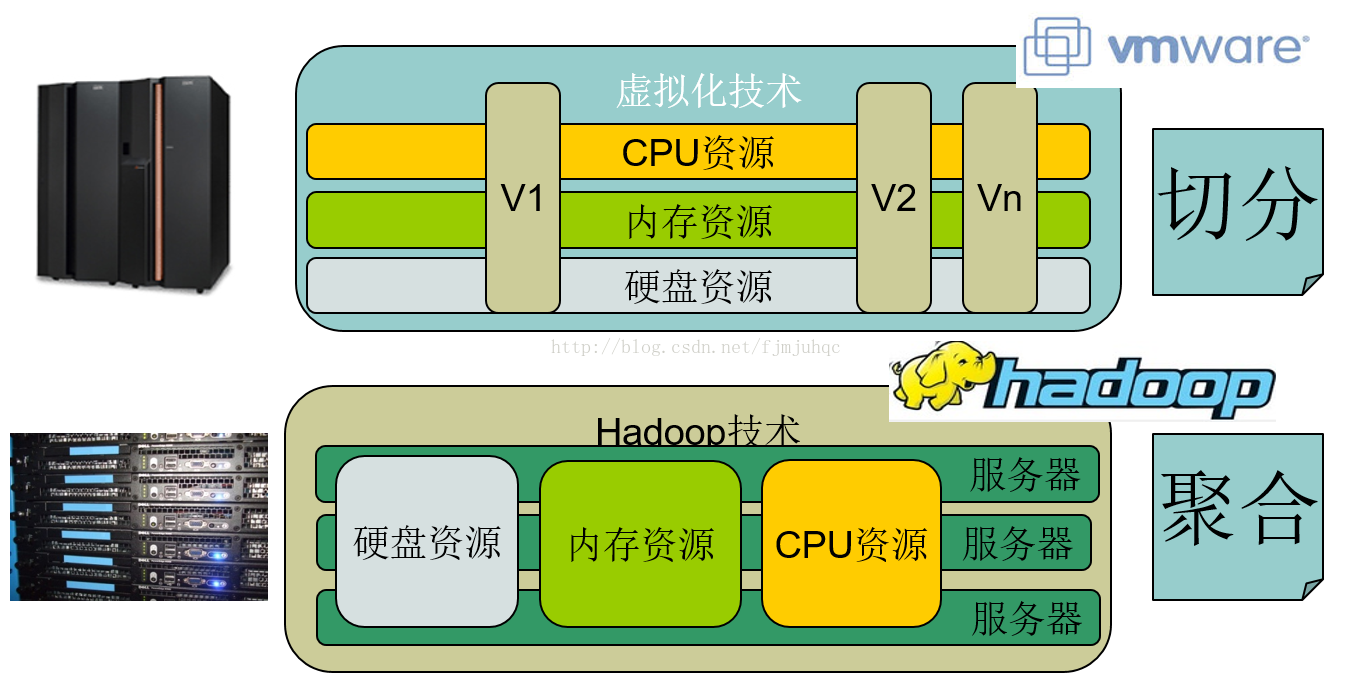
1.4 HDFS的架构
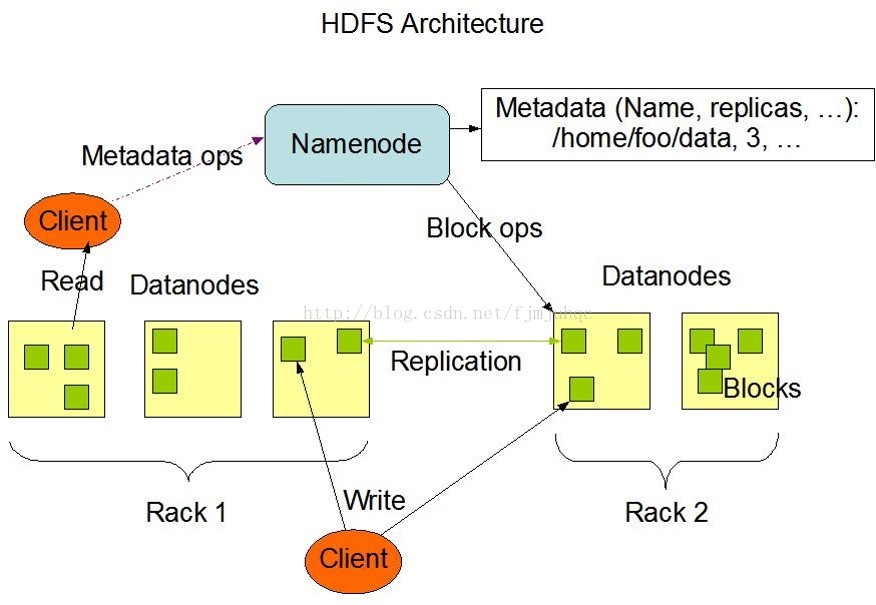
2. 实践部分
2.1 电脑配置
2.2 hadoop安装前的准备工作
2.2.1 安装Vmware WorkStation软件
这是一个VM公司提供的虚拟机工作平台,后面将在这个平台安装所需要的Linxu操作系统,我安装的版本是:VMware® Workstation 12 Pro,版本号:12.5.0 build-4352439,具体安装过程很简单,网上有很多安装教程。
2.2.2 在虚拟机上安装Linux操作系统

2.2.3 规划节点
按照hadoop集群的基本要求,其中一个是master结点,主要是用于运行hadoop程序中的NameNode、SecondaryNameNode和ResourceManager。另外两个结点均为slave结点,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了,所以模拟hadoop集群至少要有3个结点,如果电脑配置非常高,可以考虑增加一些其它的结点。slave结点主要将运行hadoop程序中的DataNode和NodeManager。
所以,在准备好这3个结点之后,需要分别将linux系统的主机名重命名,重命名主机名的步骤:

以下是我对三个结点的CentOS系统主机分别命名为:centos01, centos02, centos03,其中centos01规划为主节点,其他为从节点。
以下是我个人参考网上教程的配置图
虚拟机网关设置为192.168.3.1
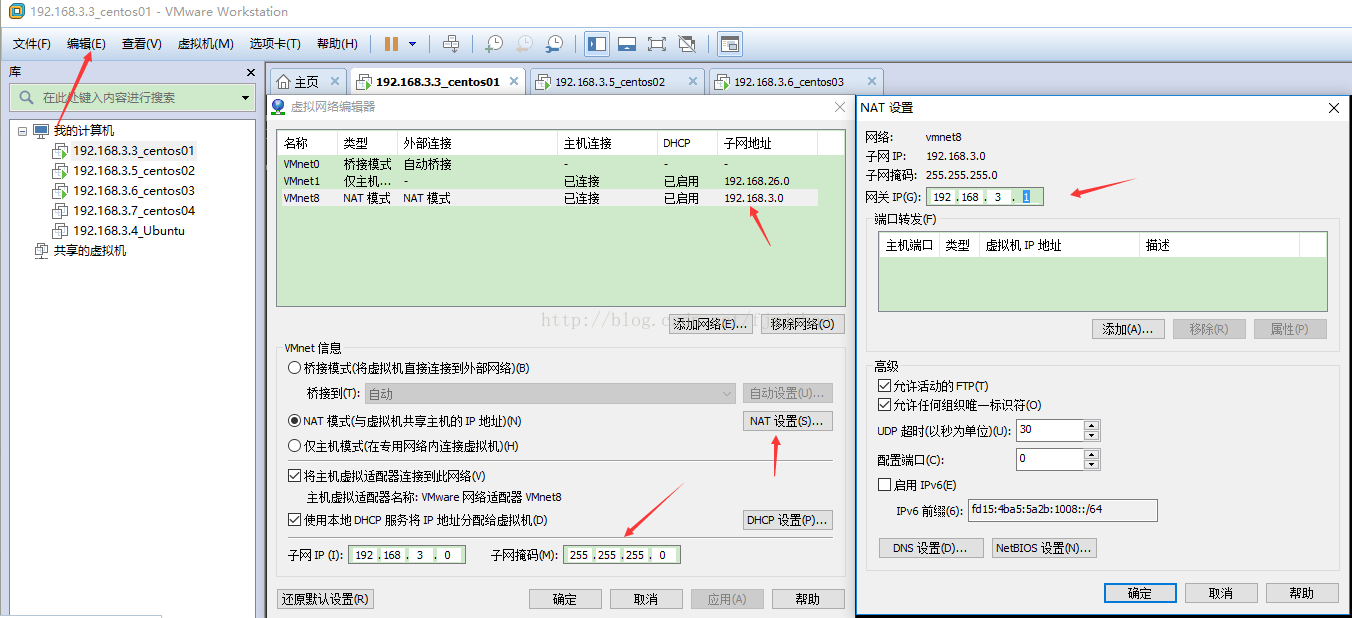
设置物理机上的虚拟机网卡IP为192.168.3.2,并指定网关192.1683.1

设置三个节点的IP地址分别为192.168.3.3、 192.168.3.5、192.168.3.6

2.3 hadoop集群搭建
一、配置hosts文件,查看2.2.3 规划节点
二、建立hadoop 运行账号
即为hadoop集群专门设置一个用户组及用户,这部分比较简单,参考示例如下:
sudo groupadd hadoop //设置hadoop用户组
sudo useradd –s /bin/bash –d /home/yellow –m yellow–g hadoop –G admin //添加一个yellow用户,此用户属于hadoop用户组,且具有admin权限。
sudo passwd 1234 //设置用户yellow登录密码
su yellow//切换到yellow用户中
上述3个虚机结点均需要进行以上步骤来完成hadoop运行帐号的建立。
三、配置SSH无密登录原理:A要无密登录B,则将A的公钥加入到B的授权列表,这样A就能免密登录B
SSH主要通过RSA算法来产生公钥与私钥,在数据传输过程中对数据进行加密来保障数据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均可以访问,私钥主要用于对数据进行加密,以防他人盗取数据。总而言之,这是一种非对称算法,想要破解还是非常有难度的。Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证,hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果hadoop对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
步骤:
四、下载并解压JDK安装包

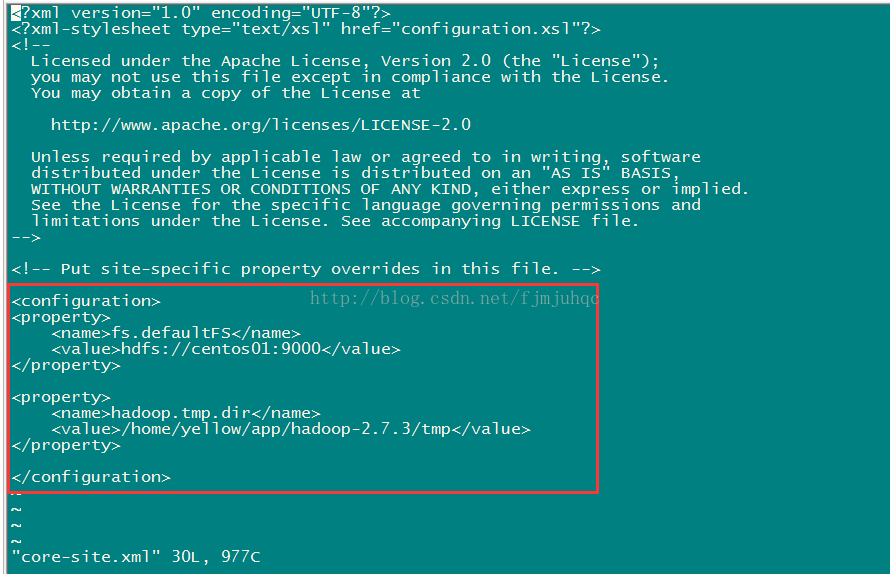
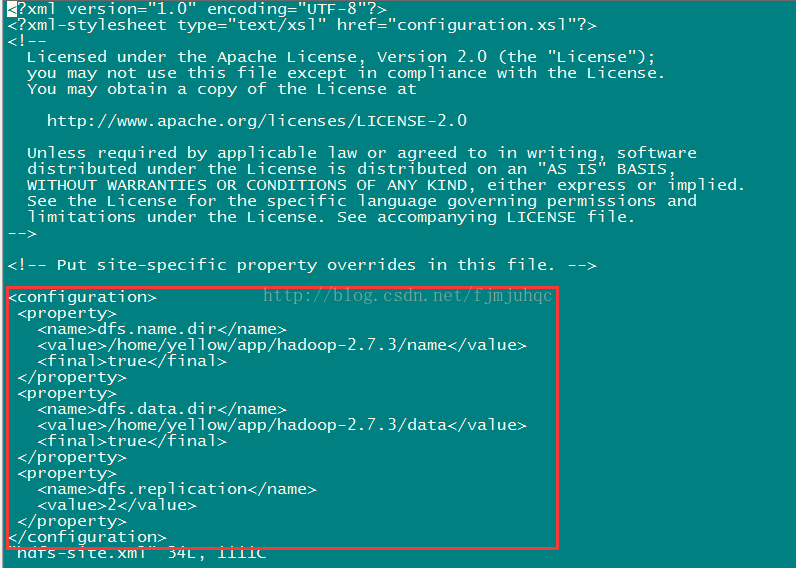
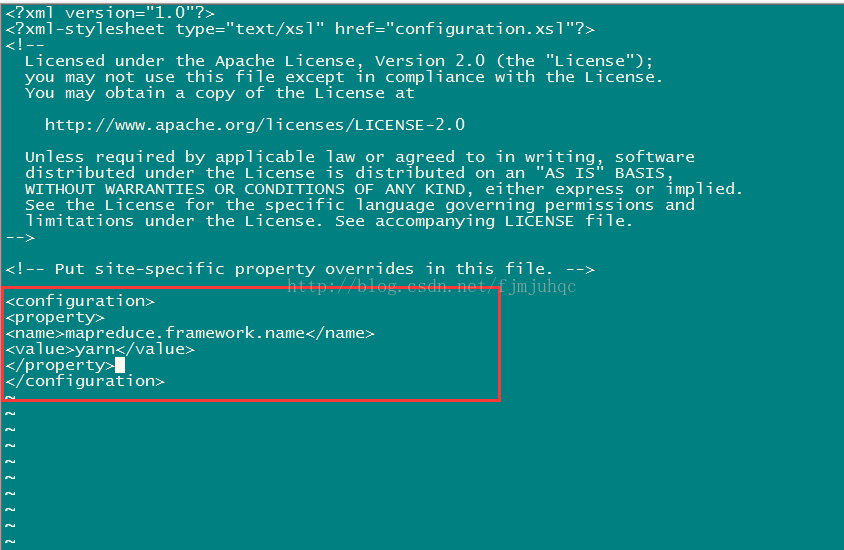



scp -r ./hadoop-2.7.3/ centos02:/home/yellow/app/
scp -r ./hadoop-2.7.3/ centos03:/home/yellow/app/

七、格式化namenode
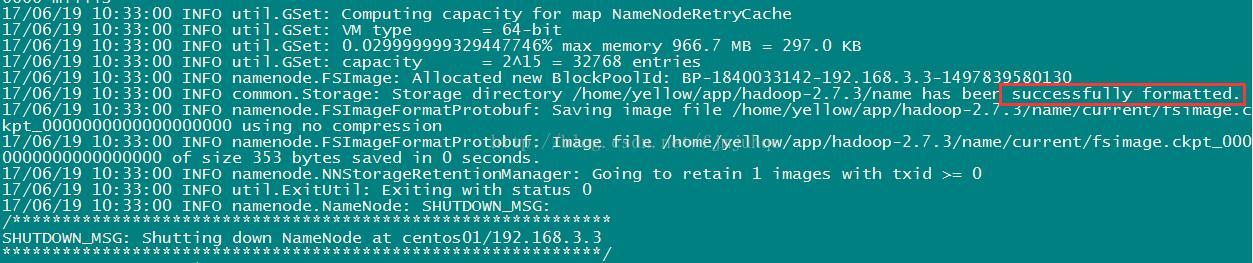
这一步在主节点centos01上进行操作,
注意:上面只要出现“successfully formatted”就表示成功了。

八、启动hadoop并用jps检验各后台进程是否成功启动
在主节点centos01上进行操作[yellow@centos01 ~]$ start-all.sh

可以看出进程都启动了,可以通过网站查看集群情况,在浏览器中输入:http://192.168.3.3:50070,网址为centos01结点所对应的IP.,也可以通过主机名访问,但是必须先配置下Windows 的hosts文件
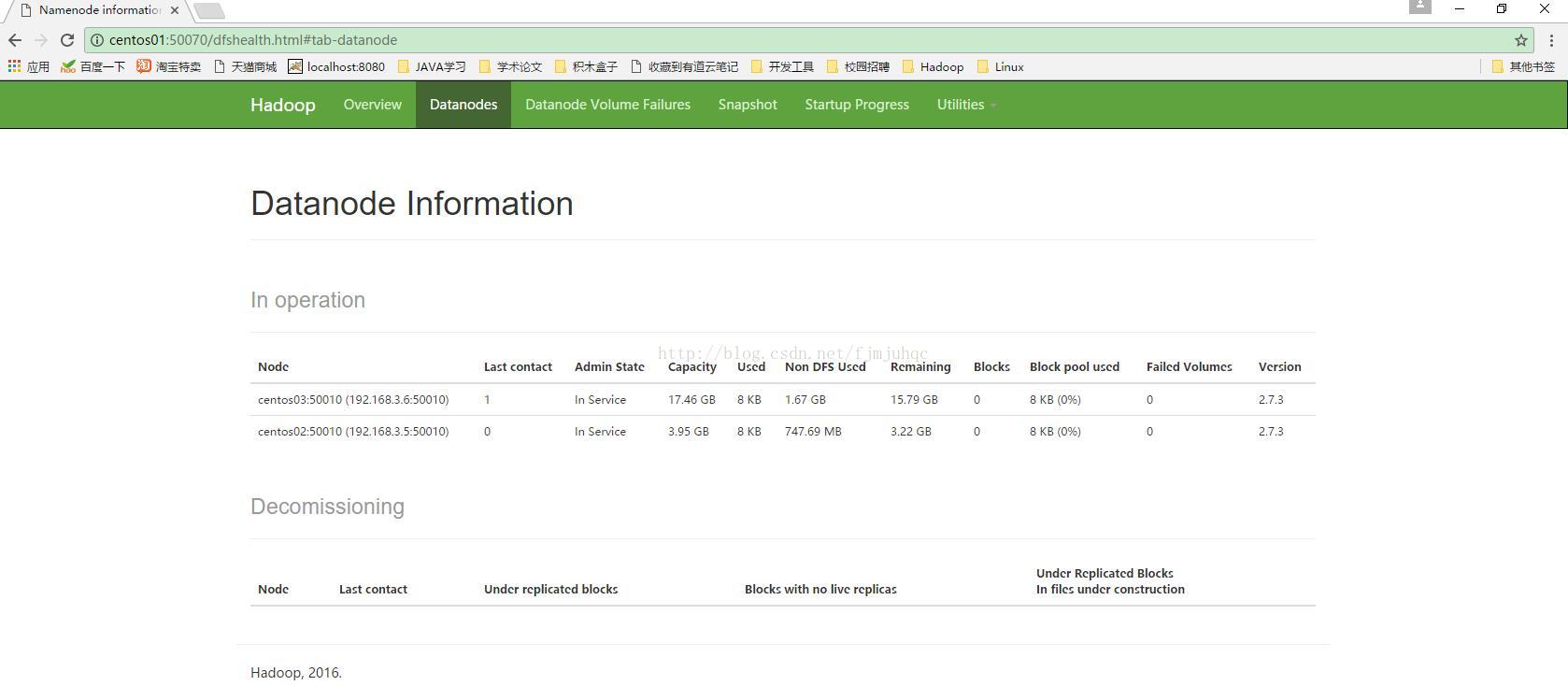
至此,hadoop的分布式集群搭建已经全部完成















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









