









对于非正态分布的数据,当样本量不够大(如小于30)时,Wilcoxon 检验的功效较低。如何提高非参数检验的功效,这是个不容易的问题。Wilcoxon是一个特异度很高的检验方法,但小样本时灵敏度较低。如果简单放宽检验水准,将会迅速损失特异度,并不是上上策。小样本的差异分析一直是个头疼的问题,对于两组样本量都少于30的情况,各类非参数检验都很低效。除了尝试对数据log或开根号转化等数据预处理技巧外,是否能直接从非参数检验体系本身对检验功效进行优化?本文可能有点纠结边际优化效果(毕竟特别有价值的特征往往容易被Wilcoxon检验发现的),对于检验灵敏度要求不高的情况,可直接忽略本文的观点。
有论文(见参考资料)指出,某些小样本情况下Kolmogorov–Smirnov检验可能优于Wilcoxon检验。严格来说,Wilcoxon检验和KS检验的功效对比需多次重复模拟进行评估,此处不再赘述(见参考资料的论文),本文仅以一个简单的典型示例呈现。笔者根据Wilcoxon的特点和KS检验的优势(对分布敏感),构造了如下的数据:
A组中12个样本的X分子表达量为:1,6,12,18,19,20,22,23,24,26,27,28
B组中13个样本的X分子表达量为:2,3,4,5,7,8,9,10,11,13,21,25,29
可视化如下:

直观来看,两组应当是有显著差异的。
分别检验两组数据的正态性,发现符合正态分布。因此使用 t 检验,结果 p=0.038,佐证了我们对数据的直观感受。
以分组为结局变量,X的表达量为自变量,建立Logistic回归模型,结果:OR=0.90,p=0.047。值得注意的是,将上述Boxplot 旋转90度后,直观感觉 似乎能较好地拟合出 Logistic的S型曲线。
以整体的中位数13为界值,划分为高表达和低表达,进行Fisher精确检验,结果 p=0.017.
频率学派过渡依赖于p值,我们用贝叶斯学派的观点来看看这一组数据。事先假定这是表达量count计数资料(离散分布),由于数据的方差(70左右)明显大于均值(均值小于30),存在overdispersion,不太符合Poisson分布,可考虑使用负二项分布。为了尽量减少主观影响,我们假定两组参数均值mu的先验都为0~30之间的均匀分布,参数alpha的先验分布都为0~10之间的均匀分布,使用MCMC采样模拟,得到两组参数的后验分布如下:

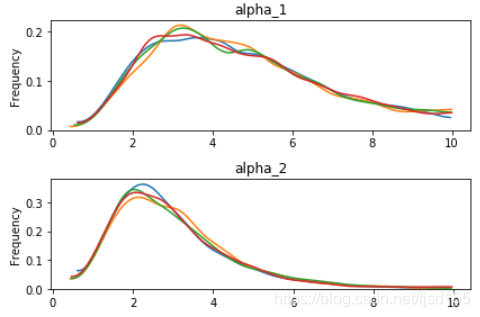
且A组均值mu_1 大于 B组均值 mu_2 的概率为:96.0%。
接下来我们看看非参数检验的表现如何。
使用Wilcoxon检验,得到 p=0.068,保守的Wilcoxon不能以0.05的水准得到显著差异。在进行biomarker筛选的时候很容易被Wilcoxon误导。
我们尝试采用KS检验,结果 p=0.040,诶,可以。个人一直感觉KS检验也比较严格保守,但这种情况确实能为非参数检验挽回一些颜面。
可能有人认为,既然数据服从正态分布,何不直接使用 t 检验呢?我们如果将A组最后两个样本点的值27和28改为26.1和26.2,则A组的数据不再服从正态分布(哈哈,有点夸张,这个演示稍微极端一点,但确实正态检验结果认为不再服从正态分布)。这个时候还使用 t 检验是会被质疑的,因此不得不使用非参数检验方法。再次进行Wilcoxon和KS检验,结果不变(毕竟秩次没发生变化)。
为何不直接转向贝叶斯推断的怀抱,上述例子中笔者假定该计数资料符合负二项分布,但如果为连续分布数据且分布形式多种多样(如代谢组学数据),难以统一判断分布类型时,贝叶斯推断好像有点吃力(主要是笔者水平还不够)。
题外话:对于RNA-Seq的count数据,可以直接使用 edgeR、DESeq2及limma等各种工具包(edgeR和DESeq2基于负二项分布广义线性模型处理count数据,limma基于线性模型、在 t 检验的基础上改进),但其实各个工具之间并没有达到特别好的共识,检验的灵敏度和特异度各有千秋。limma包本来用于处理芯片数据的(芯片数据首选方法),后来有论文证明(limma包的RNA-Seq部分的参考资料),将count数据转成logCPM,也可以使用limma处理。由于CPM、FPKM及TPM等数据本质上是类似的,因此limma包也可以处理TPM类型的数据,但建议使用log预处理。可以参考:RNAseq数据,下载GEO中的FPKM文件后该怎么下游分析
另外,对于将连续变量转成分类变量再进行卡方检验或Fisher精确检验的思路,存在争议的地方在于划分所使用的界值(中位数并不总是有效,而直接优化最佳界值也容易被质疑),并且笔者观点是尽量避免将连续变量压缩成二分类变量(许多大佬都认为粗鲁地压缩容易丢失大量的信息)。同样作为分布检验的方法,KS检验虽然不是最佳选择,但勉强还可以代表大家出战。
但注意,KS检验可能会找到一些奇奇怪怪的分布的特征,最好剔除多峰分布的特征(多峰分布的特征难以解释)。另外,KS检验对相同秩的情况也处理不佳(相同秩估计不准 简直是许多非参数检验的共病)。
本文的示例只是其中一种典型的代表,实际(小样本)数据中这样的情况并不罕见。笔者认为,小样本数据分析时,可在Wilcoxon检验的基础上,辅之以KS检验,从而提高非参数检验的功效,即:Wilcoxon检验与KS检验分别筛选biomarker后,再取并集作为差异分析的结果,可能可以帮助挖掘潜在有用的biomarker(记得确实有一些综述总结到KS检验可以作为筛选biomarker的方法之一)。
上述的例子中,众多检验方法都认为两组很可能存在差异,而Wilcoxon检验则过于保守估计,这大概是Wilcoxon的其中一个缺陷。Wilcoxon的另一个缺陷是:丢失了数值的绝对大小,只保留了相对大小的信息。下面举个小样本中简单而又极端的栗子。
A组的3个病例的X分子表达量为:1, 2, 3
B组的3个病例的X分子表达量为:40, 50, 60
使用Wilcoxon检验 p=0.1,而使用 t 检验则 p=0.01。
因此,提高非参数检验功效的另一个思路是:重新引入绝对数值大小。这可能是优化非参数检验功效极为重要的一方面。
参考资料:
曾艳等. 完全随机设计两样本的Wilcoxon检验与KS检验功效比较. 中国卫生统计学.2011



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











