







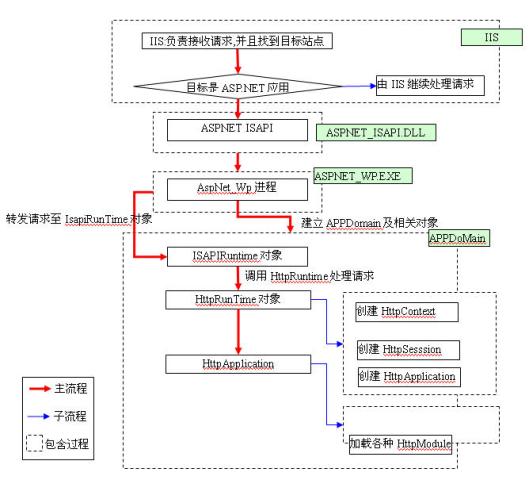
上一篇随笔<深入剖析ASP.NET组件设计>一书中第三章关于ASP.NET运行原理的补白总览了大体的结构及流程,看完后,相信,可以对整体的流程有所了解.但是,许多细节的问题,例如像HttpRuntime如何建立HttpApplication对象等问题,仍然没有解说清楚
当然,了解这些细节并不是必需的,就算你不知道HttpApplication对象是如何被创建的,你仍能够创建出好的组件.但是,如果你仔佃研究这些细节,相信你会吸收不少技术养分.例如,通过本文讲述的HttpApplication对象的创建过程,你就可以深切的体会到ASP.NET设计的精妙之处,并且,你可以学到Factory设计模式的运用,这也是黄先生这本书的另一个特点,就是,他不光讲述了ASP.NET的一些东西,同时教你一些编程的方法和技巧,对于一些学习设计模式,而又觉得难以理解设计模式的初学者来说,通过阅读黄先生的这本书,能够让你看到不少设计模式实地运用的讲解.
实际上HttpApplication并不是HttpRuntime所创建的.HttpRuntime只是向HttpApplicationFactory提出请求,要求返回一个HttpApplication对象.HttpApplicationFactory在接收到请求后,会先检查是否有已经存在并空闲(可以这样讲吗?比较形象一点)的HttpApplication对象,如果有,则从池中取出一个HttpApplication对象返回给HttpRuntime,如果没有的话,则要创建一个HttpApplication对象给HttpRunTime(英文叫Pooling,好比你养鱼一样,每个鱼是一个HttpApplication,而你就是HttpApplicationFactory,别人问你要鱼,你就会检查池中有没有现成的,并且是合适的鱼,有的话,捞一个给别人,没有的话,创造一条鱼,放入池中,再给别人,听起来不错,你好像威力无比哟)
实际上,我们再将HttpApplication的创建过程放大来看的话,还有不少细节.上面讲述的是HttpApplication是如何被请求以及如何被返回给HttpRunTime的,概括的来说,就是HttpRunTime不直接建立HttpApplication,而是把创建的权利交给HttpApplicationFactory,这里实际上运用的正是Factory模式,而且不是一般的Factory模式,而是带有Pool能力的Factory模式.HttpFactory对象负责建立并缓存HttpApplication对象同时返回合适的对象给HttpRuntime.这里就有一个问题了,也就是说,同一时刻,HttpApplicationFactory的"养鱼池"里可能有很多个HttpApplication对象.那最多他能够同时缓存多少个HttpApplication对象呢?默认情况下,HttpApplication对象的最大缓存数目为100,并且HttpApplicationFactory会循环释放超过此数量的HttpApplication对象(那是不是意味着超出100个人同时访问的系统,无论设计的再好,也会因此而遭遇到性能瓶颈呢?)
HttpApplicationFactory创建HttpRuntime的过程是一个Parse与Compile的过程.原书中黄先生说,HttpApplicationFactory会运用Parser对象来解析Global.asax,同时,加载Global.dll文件,同时,创建一个继承自此类的源代码,最后运用Compiler对象来编译源代码,再创建一个HttpApplication对象.这一点,也可以从黄先生书中配图可以看到.但是,估计许多人看到这里已经晕了.你可以这样理解这个过程:
首先,黄先生所言的Parser与Compiler对象其实是指Codeparser与CodeCompiler类的两个实例,它们是.net类库的一部分,Codeparser对象的作用是将一段文本转换为一段C#或VB源代码
(
看不懂吗?有没有想过,你在ASPX页面中用<ASP:Label runat=server></ASP:Label>中定义的ASP.NET控件在运行时究竟变成什么东东呢?Parser对象可以负责将<asp:Label>以及类似的控件以及<script runat="server">中的代码解析成对应的C#源码片断,也就是 Label label2=new Label();的形式,它返回一个CodeCompileUnit对象.
如果你仍然不理解ASP.NET的这种Parser行为的话,你就不了解ASP.NET控件的运作形式.你必须深刻的记住一点,那就是,处理对应的ASP.NET页面请求的不是ASP.NET也不是IIS,更不是ASP.NET页面本身.而是ASP.NET运用PARSER对象将控件标记转换成C#源码并且派生于PAGE类,被编译并实例外的一个对象.这一点非常重要,跟ASP不同,我们知道ASP的代码是被加载到内存并且被ASP运行时解析然后返回HTML的,但是,ASP.NET不是,ASP.NET处理页面请求的是一个类的实例,它是一个可以输出HTML的对象.同样的,在HttpApplication对象的创建过程中,也是运用了Parser,因为HttpApplication实际上要依赖于Global.ASAX文件,而这个文件,我们知道,如果不用CodeBehind来写的话,它就是一个<Script Runat="Server">,换句话来说,它也是一段标记,这段标记必须被转换成C#源代码,然后编译成一个类,再产生这个类的实例,这个类就是HttpApplication.实际上,像CodeParser,CodeCompiler以及Reflection等构成的CodeDom技术是.NET核心部分之一,.NET的运行非常依赖于这些部分)
至于parser为什么要解析Global.ASAX同地又要加载Assembly,这一点上,许多人会想不通.因为如果使用CODEBehind技术的话,所有代码已经包含在Assembly中了呀,为什么还要解析Global.ASAX呢?如果你这样想,你就错了,首先,也可能Global.ASAX中定义了一部分函数,而Assembly中定义了另一部分,其次,没有人说Gloabal.ASAX中只允许包含代码呀,也有人喜欢在其中利用OBJECT标记来定义APPLICATION范围或者Session范围的对象呀,因此,parser有必要解析Global.ASAX文件,将其转换为C#代码片断,然后,加载Assembly,利用Reflection技术创建一个继承自类Global(默认情况下的类名)的新类的源代码,然后将两部分的源代码合并(Ghost Application Class Source),运用Compiler创建出一个新类(Ghost Application Class Assembly),并且生成新类的一个实例来返回给HttpRuntime.
原书中,黄先生说Parser会加载Global.dll文件,我想,这可能是笔误,很多人不明白Global.dll究竟是什么.写过ASP.NET的人更知道,根本没有这个文件.我想,Global.dll就是包含global.asax文件的工程编译产生的Assembly,由于此Assembly包含了CodeBehind方式下的Global类的信息.因此,Parser才需要加载它
至此,HttpApplication对象创建完毕了.另外,就AppDomain,HttpRuntime,HttpContext,HttpSession,HttpApplication,HttpModule这些对象的数量以及与用户数量的对应关系做以下描述
每一个ASP.NET只有一个AppDomain,每一个AppDomain对应一个httpRunTime,它们都与用户数量无关
每一个用户对应一个HttpApplication,一个HttpSession,一个HttpContext和一组HttpModule
如果对于HttpApplication对象生成过程中的Parser与Compiler不清楚的话(这部分很重要,包括AspX页面的处理方法也是类似的),下面的图或许有助理解:















 2335
2335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









