







九、流程控制语句
-
if
""" if <条件> : <一个tab键或者4个空格><事件> """ # demo1 age = 18 if age > 10: print("我不是小朋友了") #demo2 age = input('你多大了:') if int(age) > 10: print("我不是小朋友了")- if else
""" if <条件> : <一个tab键或者4个空格><事件> else : <一个tab键或者4个空格><事件> """ #demo1 age = 7 if age > 10: print("我不是小朋友了") else: print("我还是小朋友") #demo2 age = input('你多大了:') if age > 10: print("我不是小朋友了") else: print("我还是小朋友") -
elif
""" if <条件1> : <一个tab键或者4个空格><事件1> elif <条件2> : <一个tab键或者4个空格><事件2> elif <条件3> : <一个tab键或者4个空格><事件3> else : <一个tab键或者4个空格><事件4> """ age = input("你多大了:") if int(age) > 18: print("我成年了") elif int(age) > 12: print("我上中学了") elif int(age) > 6: print("我上小学了") elif int(age) < 6: print("我读幼儿园") else: print("唉") -
for
""" for <临时变量> in <列表或字符串等可迭代对象>: <一个tab键或者4个空格><事件> """ # 输出:h,e,l,l,o _str='hello' for s in _str: print(s) # 输出:a,b,c _list=["a","b","c"] for s in _list: print(s) # 输出:d,e,f _tuple=("d","e","f") for s in _tuple: print(s) # 输出:aa,aaa,bb,bbb,cc,ccc _dic={"aa":"aaa","bb":"bbb","cc":"ccc"} for s in _dic: print(s) print(_dic[s]) -
range
# range(从0开始几位) # 输出0,1,2,3,4 for s in range(4): print(s) # range(起始值,结束值) # 输出1,2 for s in range(1, 3): print(s) # range(起始值,结束值,每次递增值) # 输出5,9 for s in range(1, 10, 4): print(s)
十、字符串高级
- len:获取字符串长度
- find:查找内容是否存在,返回索引,没有返-1
- startswith,endswith:判断字符串是不是以xx开头或结尾
- count:返回字符串在start和end之间出现的次数
- replace:替换
- split:切割
- upper,lower:大小写互换
- strip:去空格
- join:字符串拼接
_s = "a" print(_s.join("你看这个在哪儿")) 输出: 你a看a这a个a在a哪a儿
十一、列表高级
-
添加
- append:在末尾添加元素
- insert:在指定位置插入元素
- extend:合并两个列表
# append a = ["dada", "didi", "dudu"] b = "addend" a.append(b) # 输出:['dada', 'didi', 'dudu', 'addend'] print(a) # insert b = "addinto" a.insert(1, b) # 输出:['dada', 'addinto', 'didi', 'dudu', 'addend'] print(a) # extend b = ["lili", "lala", "lulu"] a.extend(b) # 输出:['dada', 'addinto', 'didi', 'dudu', 'addend', 'lili', 'lala', 'lulu'] print(a) -
修改
a = ["dada", "didi", "dudu"] a[0] = "lili" # 输出:['lili', 'didi', 'dudu'] print(a) -
查询
- in 和 not in
a = ["dada", "didi", "dudu"] b = "didi" # 输出:找到了 if b in a: print("找到了") else: print("没找到") # 输出:没找到? if b not in a: print("找到了?") else: print("没找到?")- index 和 count
-
删除
- del:根据下标进行删除
- pop:删除最后一个元素
- remove:根据元素值进行删除
a = ["dada", "didi", "dudu"] # del del a[2] # 输出:['dada', 'didi'] print(a) # pop a.pop() # 输出:['dada'] print(a) # remove a.remove("dada") # 输出:[] print(a)
十二、元组高级
元组的元素不能修改,删除
元组的元素如果只有一个,需要在最后面加一个逗号
- a = (11,)
十三、切片
-
字符串,列表,元组 都支持切片操作
-
切片语法:[起始:结束:步长] ,[起始:结束]
-
切片是通过下标去某一元素
a = "hello word!" # o 字符串里的第4个元素 print(a[4]) # lo W 包含下标 3,不含下标 7 print(a[3:7]) # llo word! 从下标为2开始,取出 后面所有的元素 (没有结束位) print(a[2:]) # hello 从起始位置开始,取到 下标为5的前一个元素 (不包括结束位本身) print(a[:5]) # l o 从下标为3开始,取到下标为8的一个元素,步长为2(不包括结束位本身) print(a[3:8:2])
十四、字典高级
-
查询
a = {"t1": "hello word!", "t2": "Wang Xiao Ming", "t3": "Zhang Xiao Na"} # hello word! print(a["t1"]) # Wang Xiao Ming print(a.get("t2")) # None print(a.get("t4")) # Wang Xiao Ming print(a.get("t2", "大学生")) # 小学生 print(a.get("t4", "小学生")) -
修改
a = {"t1": "hello word!", "t2": "Wang Xiao Ming", "t3": "Zhang Xiao Na"} # hello word!!! a["t1"] = "hello word!!!" print(a["t1"]) -
添加
a = {"t1": "hello word!", "t2": "Wang Xiao Ming", "t3": "Zhang Xiao Na"} # {'t1': 'hello word!', 't2': 'Wang Xiao Ming', 't3': 'Zhang Xiao Na', 't4': '小学生'} a["t4"] = "小学生" print(a) -
删除
- del:删除指定元素,删除整个字典
- clear():清空
#del a = {"t1": "hello word!", "t2": "Wang Xiao Ming", "t3": "Zhang Xiao Na"} # {'t1': 'hello word!', 't3': 'Zhang Xiao Na'} del a["t2"] print(a) # 然后a就不存在了 del a # clear a = {"t1": "hello word!", "t2": "Wang Xiao Ming", "t3": "Zhang Xiao Na"} # {} a.clear() print(a) -
遍历
- 遍历字典的key
- 遍历字典的value
- 遍历字典的key和value
- 遍历字典的项/元素
a = {"t1": "hello word!", "t2": "Wang Xiao Ming", "t3": "Zhang Xiao Na"} # dict_keys(['t1', 't2', 't3']) print(a.keys()) #dict_values(['hello word!', 'Wang Xiao Ming', 'Zhang Xiao Na']) print(a.values()) #dict_items([('t1', 'hello word!'), ('t2', 'Wang Xiao Ming'), ('t3', 'Zhang Xiao Na')]) print(a.items()) # t1 t2 t3 for key in a.keys(): print(key) # hello word! Wang Xiao Ming Zhang Xiao Na for value in a.values(): print(value) # t1 hello word! # t2 Wang Xiao Ming # t3 Zhang Xiao Na for key,value in a.items(): print(key,value) # ('t1', 'hello word!') # ('t2', 'Wang Xiao Ming') # ('t3', 'Zhang Xiao Na') for key in a.items(): print(key) for value in a.items(): print(value)
十五、函数
-
函数的定义和调用
''' 定义格式 def <函数名称>(): <一个tab键或者4个空格><事件> 调用格式 <函数名称>() ''' def f1(): print('调用f1') # 输出:调用f1 f1() -
函数的参数
def addnum(a, b): c = a + b print(c) addnum(1, 10) -
函数的返回值
def addnum(a, b): c = a + b return c d = addnum(1, 10) print(d) -
函数的局部变量和全局变量
十六、文件
-
文件的打开和关闭
open方法默认情况下使用的是gbk编码 如果我们想写入汉字 那么需要在open方法中指定编码格式为utf-8
encodeing='utf-8
open(‘douban_page1.txt’,‘w’,encoding=‘utf-8’)
’
open(文件路径,访问模式):打开一个已存在的- 绝对路径:从盘符开始的路径,如C:/a.txt
- 相对路径
- a.txt 当前文件夹同级下的文件
- ./a.txt 当前文件夹同级下的文件
- …/a.txt 当前文件夹上一级文件夹下的文件
- demo/a.txt 当前文件夹下中demo文件夹下的文件
- 访问模式
- r:只读,默认是r
- w:只写,不存在则创建
- a:追加内容,从文件最后开始
- r+:读写,从文件开头开始
- w+:读写,不存在创建,存在则覆盖创建
- a+:读写,从文件最后开始
- rb:和r的区别是二进制打开
- wb:和w的区别是二进制打开
- ab:和a的区别是二进制打开
- rb+:和r+的区别是二进制打开
- wb+:和w+的区别是二进制打开
- ab+:和a+的区别是二进制打开
# 创建一个文件 open("test.txt", "w") # 打开文件 fp = open("test.txt", "w") # 向文件中写入 fp.write('first') # 关闭文件 fp.close() -
文件的读写
# 打开文件 fp = open("test.txt", "w") # 向文件中写入 5个one 不跨行 fp.write("one" * 5) # 向文件中写入 5个two 跨行\n fp.write("two\n" * 5) # 关闭文件 fp.close() # 读取 # 打开文件 fp = open("test.txt", "r") # 一字节一字节的读 content = fp.read() # oneoneoneoneonetwo # two # two # two # two print(content) # 一行一行的读,只能读取一行 content = fp.readline() # 读取失败了 print(content) # content = fp.readable() # True print(content) # 一行一行的读,多行读取 content = fp.readlines() # [] print(content) # 关闭文件 fp.close()写入文件方式2
with open('douban_page1.txt','w',encoding='utf-8') as fp: fp.write(content) -
文件的序列化和反序列化 [json]
- 序列化
# 引入json import json # 打开文件 file = open("test.txt", "w") # 定义写入内容 names = ["xiaozhang", "xiaoming", "xiaowang"] ## dumps # json 序列化,得到一个字符串 result = json.dumps(names) # 写入文件 file.write(result) ## dump names = ["xiaozhang1", "xiaoming1", "xiaowang1"] json.dump(names, file) # 关闭文件 file.close()- 反序列化
# 引入json import json # 打开文件 file = open("test.txt", "r") # 读取文件 content = file.read() # 字符串类型 ["xiaozhang", "xiaoming", "xiaowang"] print(content) ## loads # json 反序列化,得到一个对象 result = json.loads(content) # 对象类型 ["xiaozhang", "xiaoming", "xiaowang"] print(result) ## load result = json.load(file) # 对象类型 ["xiaozhang", "xiaoming", "xiaowang"] print(result) # 关闭文件 file.close()
十七、异常
- except 的取值位置
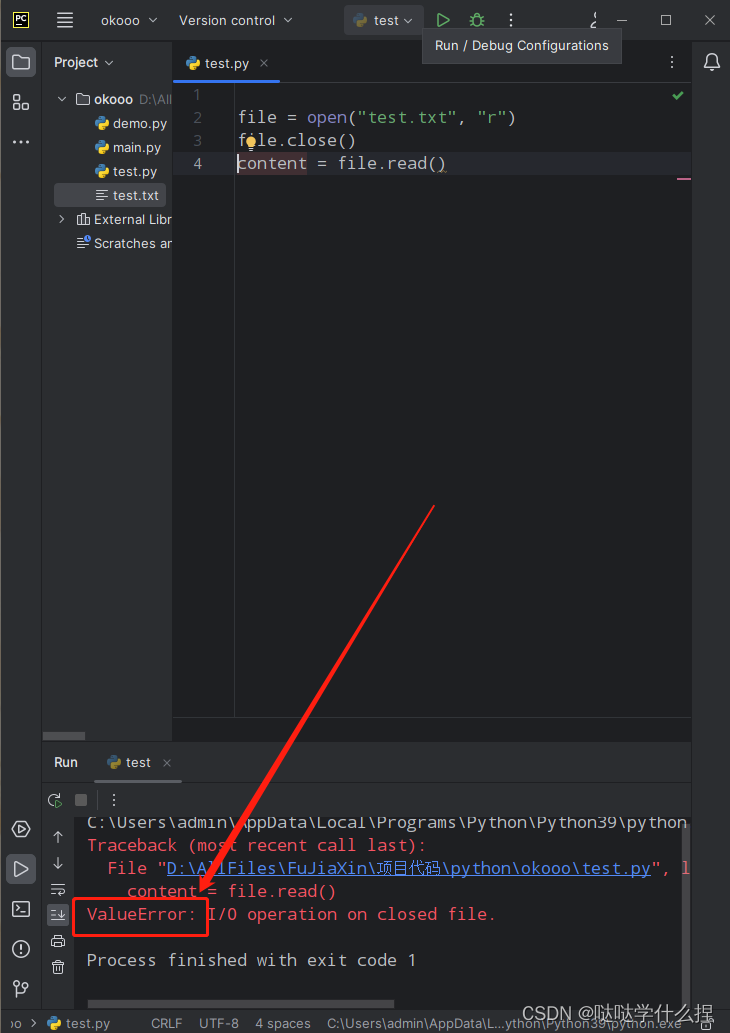
'''
try:
<可能出现异常的代码>
except <异常的类型>
<友好提示>
'''
try:
file = open("test.txt", "r")
file.close()
content = file.read()
except ValueError:
print('I/O operation on closed file.')
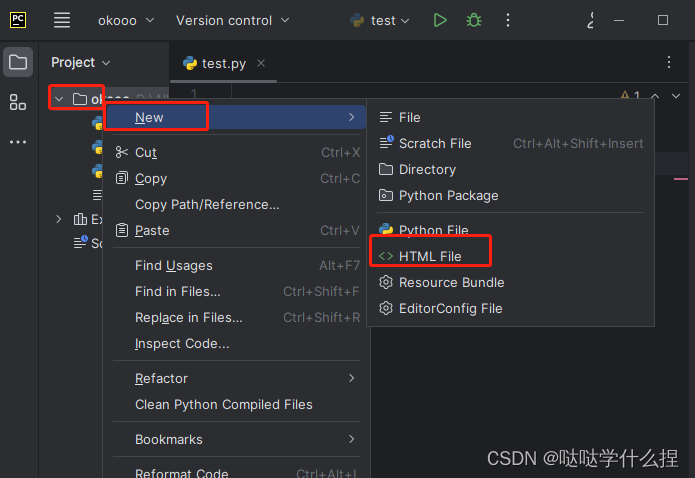
十八、页面结构介绍【HTML】
- 选择项目右键现在如图















 5277
5277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









