






引言
PL/SQL语句在SQL命令语言中增加了过程处理语句(如分支、循环等),使SQL语言具有了过程处理的能力。
通过PL/SQL Developer工具创建一个新的文件时,默认会看到下面这段代码:
declare
--Local variable here
begin
--Test statement here
end;
在这段代码中,declare表示声明部分,比如变量的声明、游标的声明都可以放在这个部分,如果程序中没有使用到变量,这一部分是可以省略的。
begin和end之间可以存放的相当于程序的方法体,在这个部分里面我们可以对表进行操作,对业务进行判断。
当然了,有时候在方法中也会产生异常,所以在方法体中添加一个exception处理异常即可
declare
--Local variable here
begin
--Test statement here
exception
-- exception handlers
end;
和学其他语言一样,在最开始的时候我们试一试打印hello world!
begin
set serveroutput on; -- 设置控制台输出内容可见
DBMS_output.put_line('hello world!');
end;
基本语法
变量
普通变量
声明变量的方式为: 变量名 变量类型,例如:
s_id number;
s_name varchar2(4);
为变量赋值则有两种方法:
- 在DECLARE声明部分中通过
:=符号直接赋值,例如:
s_name varchar2(4) := '黑猫几绛'
- 在方法体内通过**
select 值 into 变量 from 表名称**语句赋值,例如:
declare
s_name varchar2(4);
s_id number
begin
s_id := 1902;
select '黑猫几绛' into s_name from studnt_table;
DBMS_output.put_line('姓名为:' || s_name || ',id为:' || s_id); --这里的||类似于字符串拼接时的 + 号
end;
引用型变量
引用型变量的类型和长度取决于表中字段的类型和长度
通过表名.列名%TYPE可以指定变量的类型和长度,例如:
-- 直接通过表.列的方式拿到目标变量类型
s_name_var student_table.student_name%TYPE;
-- 等价写法
s_name_var varchar2(4);
这样定义变量类型,可以让我们不必再次查表看某个变量的类型,需要哪张表的类型直接引用即可。
现在做一个练习:查询employee_table表中1902号员工的个人信息,打印他的id和name。
首先定义好变量(这里的employee_name是表中字段,e_name是自己定义的变量名,你也可以写为ENAME什么的)
declare
e_name employee_table.employee_name%TYPE;
e_id employee_table.employee_id%TYPE;
begin
DBMS_output.put_line('姓名为:' || e_name || ',id为:' || e_id);
end;
然后思考,在sql语句中我们如何拿到目标信息:
select employee_id, employee_name from employee_table where employee_id = 1902;
现在通过变量赋值的方法完善plsql语句,在选中数据后通过into的方法将值赋给变量:
select employee_id, employee_name into e_name, e_id from employee_table where employee_id = 1902;
最终代码:
declare
e_name employee_table.employee_name%TYPE;
e_id employee_table.employee_id%TYPE;
begin
select employee_id, employee_name into e_name, e_id from employee_table where employee_id = 1902;
DBMS_output.put_line('姓名为:' || e_name || ',id为:' || e_id);
end;
记录型变量
接受表中的一整行记录,相当于Java中的一个对象。其语法为:变量名称 表名%ROWTYPE;
还是上面的那个练习:查询employee_table表中1902号员工的个人信息,打印他的id和name。
declare
e employee_table%rowtype;
begin
select * into e from employee_table where employee_id = 1902;
DBMS_output.put_line('姓名为:' || e.employee_name || ',id为:' || e.employee_id);
end;
如果将赋值的代码改为:
select * into e from employee_table;
此时就是全表查询,* 查出来的就是表中的所有数据,和其他语言一样,我们无法将一个数组类型的数据赋值给一个对象。如果想要获取到数组中的所有数据,我们可以用循环语句来操作,这也是我们接下来要看的内容。
流程控制
条件分支
这里没啥介绍的,看看语法示例就能理解,需要注意的大概有两点:
- else if 在这里写法为
elsif - 在判断的最后要写上
end if表示判断结束
begin
if 条件1
THEN 执行1;
elsif 条件2
THEN 执行2;
else
执行3;
end if;
end;
循环分支
这也没啥介绍的,看看示例就能理解了:
begin
loop
exit when 退出循环的条件;
循环内部语句;
end loop;
end;
举个例子,打印数字 1-10:
declare
i number := 1
begin
loop
exit when i > 10;
DBMS_output.put_line(i);
i := i + 1; --无法使用自增
end loop;
end;
游标
游标用于临时存储一个查询返回的多行数据,像是jdbc技术中的Resultset集合,存储所有查询到的数据集合。面对这样的集合,我们可以通过遍历游标,逐行访问该结果集的数据。
游标的使用方式:
声明->打开->读取->关闭
语法
游标的声明:
cursor 游标名[(参数列表)] is 查询语句;
游标的打开:
open 游标名;
读取:
fetch 游标名 into 变量列表;
关闭:
close 游标名;
属性
- %rowcount,获得fetch语句返回的记录条数
- %found,表示是否返回了数据
- %notfound,表示没有返回数据
- %isopen,判断游标是否已经打开
举个例子:通过游标查询employee表中所有员工的姓名和工资,并将其依次打印出来。
首先,我们要创建游标,接收所有查询数据的集合
declare
cursor c_emp is select ename, esal from emp;
-- 声明变量参数负责接收游标中的数据
e_name emp.ename%TYPE;
e_sal emp.esal%TYPE;
begin
end;
现在我们获取到了数据集合,若想拿到每一条数据,我们可以使用循环的方法来实现:
declare
cursor c_emp is select ename, esal from emp;
-- 声明变量参数负责接收游标中的数据
e_name emp.ename%TYPE;
e_sal emp.esal%TYPE;
begin
-- 首先得开启游标
open c_emp;
-- 然后开启循环
loop
--%notfound默认是false,所以我们需要先fetch取数据然后再进行判断
fetch c_emp into e_name,e_sal;
-- 设置循环退出条件
exit when c_emp%notfound;
-- 如果满足循环条件,即集合中有数据时再打印数据
DBMS_output.put_line(e_name || ' ' || e_sal);
end loop;
close c_emp;
end;
游标也传递参数,还是以上面的例子来说,只不过这里查询的是部门编号为2019的员工信息:
declare
cursor c_emp(id emp.deptid%TYPE) is select ename, esal from emp WHERE deptid = ;
-- 声明变量参数负责接收游标中的数据
e_name emp.ename%TYPE;
e_sal emp.esal%TYPE;
begin
-- 在开启游标的时候传入参数
open c_emp(10);
loop
fetch c_emp into e_name,e_sal;
exit when c_emp%notfound;
DBMS_output.put_line(e_name || ' ' || e_sal);
end loop;
close c_emp;
end;
存储过程
之前我们编写的PLSQL程序可以进行表的操作,判断,循环逻辑处理的工作,但无法重复调用,这就好比是之前的代码全都编写在了main方法中,在每次的代码调用中只能执行一次。
平时我们写代码的时候,会将重复度高的逻辑封装为一个方法来解决复用的问题,这样的封装思想放在PLSQL中被称为存储过程:
语法
-- [] 表示参数列表是可选项
create or replace procedure 存储过程名[(参数列表)] is/as
-- 这里可以直接声明变量,无需在begin前加上declare声明
begin
end 存储过程名;
根据参数类型,可以将存储过程分为:
- 无参存储
- 有输入参数的存储
- 有输入(相当于形参)、输出(相当于返回值)参数的存储
无参存储
举个例子:封装一个可以输出hello world的存储过程。
create or replace procedure my_hello is/as
word varchar(50) := 'hello world';
begin
DBMS_output.put_line(word);
end my_hello;
然后在别的文件中就可以执行任意次该函数:
begin
exec my_hello;
end;
有输入参数的存储
举个例子:以存储过程的方式,打印并查询employee_table表中1902号员工的名称和薪水。
首先想,我们需要根据员工号进行信息查询,既然这是一个封装好的方法,那我们可以将员工号通过参数的方式传入到存储过程中:
-- 参数名 参数类型
print_info(id employee_table.employee_id);
但是我们前面说,在存储过程中有输入参数和输出参数这两种参数,为了更好的区别他们,我们可以在参数名和参数类型中间添加in、out标识符来区分:
create or replace procedure print_info(id in employee_table.employee_id%TYPE) is
e_name employee_table.employee_name%TYPE;
e_salary employee_table.employee_salary%TYPE;
begin
select employee_name, employee_salary into e_name, e_salary from employee_table where employee_id = id;
DBMS_output.put_line('姓名为:' || e_name || ',薪水为:' || e_salary);
end print_info;
然后在别的文件中就可以执行任意次该函数:
begin
exec print_info(1902);
end;
有输入、输出参数的存储
举个例子:以存储过程的方式,查询employee_table表中1902号员工的信息,并将他的薪水作为返回值输出,给调用的程序使用。
和上一节的差别不大,通过out标识符表示返回即可。
create or replace procedure ret_salary(
id in employee_table.employee_id%TYPE,
salary out employee_table.employee_salary%TYPE
) is
begin
select employee_salary into salary from employee_table where employee_id = id;
end ret_salary;
然后在别的文件中就可以执行任意次该函数:
declare
my_salary employee_table.employee_salary%TYPE
begin
exec ret_salary(1902,my_salary);
DBMS_output.put_line('薪水为:' || my_salary);
end;
自定义函数
其实自定义函数和存储过程大致上差不多,最大的区别在于自定义函数可以设置返回值。
语法
create or replace function function_name (参数列表)
return 参数类型
is / as
定义变量; -- 和存储过程一样,不需要使用declare
begin
执行过程;
return 定义变量;
end;
举个例子:模拟实现abs()函数:
create or replace my_abs(my_num number) return number
is
vnum number := my_number;
begin
if vnum >=0
then vnum := vnum;
else
vnum := -vnum;
end if;
end;
触发器
数据库触发器是一个与表相关联的、存储的PL/SQL程序。每当一个特定的数据操作语句(Insert,update,delete)在指定的表上发出时,Oracle自动地执行触发器中定义的语句序列。
根据触发器的触发时机可以分为前置触发器(before)和后置触发器(after)
语法
create or replace trigger my_trigger
before | after --表示是在修改表操作前还是后
[insert] [or update [of 列名(可以有很多个)]] [or delete]
ON 表名称
-- 表明是对表的每一行触发器执行一次,如果没有这一项则是对整个表执行一次
-- 比如delete from student_table,如果加了这句话,就是在删除表的时候对每一行进行触发器操作,否则是对整张表执行触发器
for each row
when inserting | updating | deleting
-- 下面和写plsql相同
declare
begin
end;
在触发器中触发语句还有一个特殊的属性伪记录变量:
:old表示触发语句前,某个变量的值:new表示触发语句后的新值
| 触发语句 | :old | :new |
|---|---|---|
| insert | 表示为空值NULL | 将要插入的新数据 |
| update | 更新以前的值 | 更新后的值 |
| delete | 删除以前的值 | 没有数据,表示为空值NULL |
举个前置触发器的例子:当用户每次输入一个数字之后,自动算出两次数字之间的差值
create or replace trigger num_trigger
before
update of num
on num_table
for each row
declare
begin
:new.change_num := :new.num - :old.num;
end;
再举个后置触发器的例子:当用户修改信息表的姓名数据后,自动记录修改前后的姓名信息
create or replace trigger name_trigger
after
update of name
on name_table
for each row
declare
begin
insert into name_table values(:new.id,:new.name,:old.name);
end;
举例一
基于人力资源管理系统数据库设计一个员工表、和一个部门表:
employees (emp_id, emp_name, sex, birthday, salary, department_id ),
departments(department_id,dep_name,manager_name)
函数
一
创建一个函数,以员工号为参数,返回该员工所在部门的平均工资
create or replace function avg_func(id employees.emp_id%TYPE)
return employees.salary%TYPE
is
-- 函数和触发器不用写declare
v_deptno employees.department_id%type;
v_avgsal employees.salary%type;
begin
-- 首先使用sql语句根据id获取部门号
-- select department_id from employees where employee_id=id;
-- 转为plsql形式进行赋值
select department_id into v_deptno from employees where employee_id=id;
select avg(salary) into v_avgsal from employees where department_id=id;
return v_avgsal;
-- 异常处理
exception
when no_data_found then
dbms_output.put_line('there is not such an employees');
end;
存储过程
一
创建一个存储过程,以员工号为参数,修改该员工的工资。若该员工属于 10 号部门, 则工资增加 140 元;若属于 20 号部门,则工资增加 200 元;若属于 30 号部门,则工资增加250 元;若属于其他部门,则工资增长 300 元
create or replace procedure emp_procedure(empid in employees.emp_id%TYPE)
is
v_deptno employees.department_id%type;
v_inc number;
begin
select department_id into v_deptno from employees where employee_id = empid;
if v_deptno = 10 -- 注意一个等号就可以了
then v_inc := 140;
elsif v_deptno = 20
then v_inc := 200;
elsif v_deptno = 30
then v_inc := 250;
else
then v_inc := 300;
endif;
-- 更改操作
update employees set salary = salary + v_inc where employee_id = empid;
exception
when no_data_found then
dbms_output.put_line('there is not such an employees');
end;
触发器
一
在 employees 表上创建一个触发器,保证每天 8:00~17:00 之外的时间禁止对该表进行 DML 操作。
create or replace emp_trigger
before insert or update or delete
on employees
for each row
declare
begin
if to_char(sysdate,'HH24:MI')not between '08:00' and '17:00' then
raise_application_error(-20000,'此时间内,不允许修改 EMPLOYEES 表');
end;
二
在 employees 表上创建一个触发器,当插入新员工时显示新员工的员工号、员工名和部门名。当删除员工时显示被删除员工的员工号、员工名
create or replace emp_trigger
before insert or delete
on employees
for each row
declare
v_name departments.department_name%type;
begin
-- 根据新插入数据员工的部门id去获取部门名称
select department_name to v_name from departments where department_id = :new.department_id
if inserting then
dbms_output.put_line(:new.employee_id||' '|| :new.first_name||' '||:new.last_name||v_name);
elsif deleting then
dbms_output.put_line(:old.employee_id||' '||:old.first_name||' '||:old.last_name);
end if;
end;
多用户管理
这一方面的内容看看例子就可以理解了:
-- 创建一个表空间
create tablespace zzz
datafile 'C:\zzz.dbf'
size 100m
autoextent on
next 10m;
-- 创建一个用户
create user hei_mao_ji_jiang
identified by 1902 --这一句话表示密码
default tablespace zzz --用户是基于表空间存在的
-- 为用户赋权限
grant dba to hei_mao_ji_jiang;
举例二
首先创建六张表,并向表内填充数据:
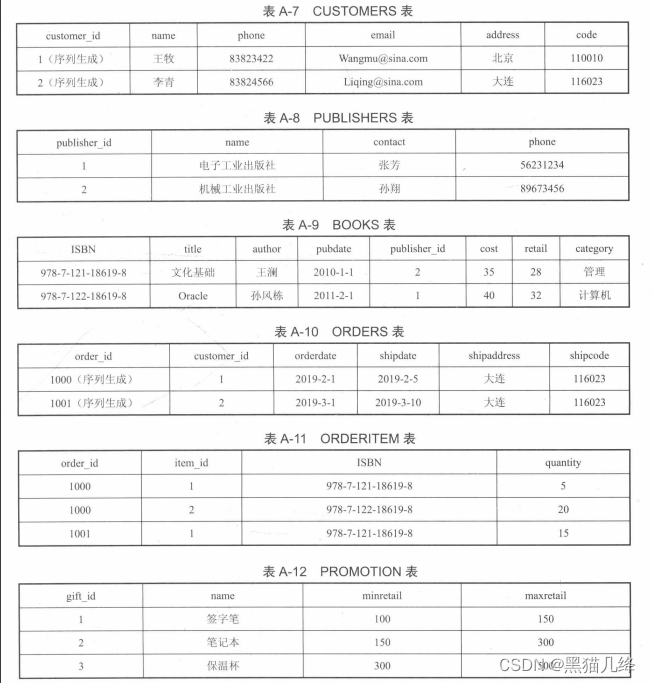
函数
一
创建一个函数,以出版社名为参数,返回该出版社出版的图书的平均价格
create or replace function avg_func( v_pub_name PUBLISHERS.name%TYPE)
return number
is
-- 函数不用写declare,直接声明变量即可
--根据出版社名找到id,然后通过与books表的多表查询拿到书的信息
v_pub_id PUBLISHERS.PUBLISHER_ID%TYPE;
--根据所有书的总金额,除以书的种类数,计算平均价格
v_sumretail NUMBER := 0;
v_avgretail NUMBER := 0;
v_count NUMBER := 0;
--还需要一个游标作为Resultset来存储所有查询到的信息,这会在循环中用到
cursor v_books IS select retail from BOOKS where publisher_id = v_pub_id;
begin
select PUBLISHER_ID INTO v_pub_id from PUBLISHERS where name=v_pub_name;
-- 循环遍历结果集
for t_books in v_books LOOP
v_count := v_count+1;
v_sumretail := v_sumretail+t_books.retail;
END LOOP;
--计算平均金额
v_avgretail:=v_sumretail/v_count;
return v_avgretail;
end avg_func;
使用该函数:
declare
v_avgretail BOOKS.retail%TYPE;
v_pub_name PUBLISHERS.name%TYPE;
begin
v_pub_name := &x; -- 表示等待用户输入
v_avgretail := avg_func(v_pub_name);
DBMS_OUTPUT.PUT_LINE( v_pub_name||'的出版的图书的平均价格'||v_avgretail);
end;
二
创建一个函数,以客户号为参数,返回该客户订购图书的价格总额
create or replace function sumcost(v_cusotmer_id CUSTOMERS.CUSTOMER_ID%TYPE)
return books.cost%TYPE
is
--通过oreder_id找到订单编号,然后通过订单编号找到书的isbn,以及订购图书的数目
sumcost BOOKS.COST%TYPE;
begin
SELECT SUM(QUANTITY*COST) INTO sumcost FROM CUSTOMERS,BOOKS,ORDERS,ORDERITEM
WHERE CUSTOMERS.customer_id = ORDERS.customer_id AND ORDERS.order_id =
ORDERITEM.order_id AND ORDERITEM.ISBN = BOOKS.ISBN AND CUSTOMERS.customer_id = v_cusotmer_id;
RETURN sumcost;
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('The id is invaild');
END SUMCOST;
使用该函数:
DECLARE
cost BOOKS.cost%TYPE;
BEGIN
cost:=sumcost(1);
DBMS_OUTPUT.PUT_LINE('该客户订购图书的价格总额'||cost);
EXCEPTION
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('NOT FOUND');
END;
存储过程
一
创建一个存储过程,输出每个客户订购的图书的数量、价格总额
create or replace procedure num_cost_procedure
is
books_count ORDERITEM.quantity%TYPE; --订购图书数量
sumcost NUMBER; --总价格
begin
FOR v_customer_id IN (SELECT DISTINCT customer_id FROM CUSTOMERS) LOOP
-- 总价格
SELECT SUM(QUANTITY*COST) INTO sumcost FROM CUSTOMERS,BOOKS,ORDERS,ORDERITEM
WHERE CUSTOMERS.customer_id = ORDERS.customer_id AND ORDERS.order_id =
ORDERITEM.order_id AND ORDERITEM.ISBN = BOOKS.ISBN AND CUSTOMERS.customer_id = v_customer_id.customer_id;
--订购图书数量
SELECT SUM(QUANTITY) INTO books_count FROM CUSTOMERS,BOOKS,ORDERS,ORDERITEM
WHERE CUSTOMERS.customer_id = ORDERS.customer_id AND ORDERS.order_id =
ORDERITEM.order_id AND ORDERITEM.ISBN = BOOKS.ISBN AND CUSTOMERS.customer_id = v_customer_id.customer_id;
DBMS_OUTPUT.PUT_LINE('ID为'||v_customer_id.customer_id||'的客户订购图书的数量:'||
books_count||' 总价格:'||sumcost);
END LOOP;
end num_cost_procedure;
使用该存储过程:
exec proc_customer_bookmsg;
触发器
一
创建一个触发器,当客户下完订单后,自动统计该订单所有图书价格总额
create or replace sumcost_trigger
after insert
on orders
for each row
declare
sumcost NUMBER;
v_order_id ORDERS.order_id%TYPE;
begin
if inserting then
v_order_id := :new.order_id;
SELECT SUM(QUANTITY*COST) INTO sumcost FROM BOOKS,ORDERS,ORDERITEM
WHERE ORDERS.order_id = ORDERITEM.order_id AND ORDERITEM.ISBN = BOOKS.ISBN
AND ORDERS.order_id = v_order_id;
DBMS_OUTPUT.PUT_LINE('总价格:'||sumcost);
end if;
end sumcost_trigger;
表空间的设置与管理
表空间是Oracle数据库中的最大逻辑容器,一个表空间包含一个或多个数据文件。
数据库容量有两种决定方式:
- 在物理上由数据文件的大小与数量决定
- 在逻辑上由表空间的大小与数量决定
表空间主要有以下树形:
- 表空间类型有:
- 临时表空间 temp tablespace
- 永久表空间 permanent tablespace
- 撤销表空间 undo tablespace
- 表空间的管理方式有:
- 字典管理方式 dictionary
- 本地管理方式 local (默认采用本地管理方式)
- 区分配方式:
- 自动分配 autoallocate(默认采用区自动分配方式)
- 定制分配 uniform
- 段管理方式:
- 自动管理 auto(默认采用段自动管理方式)
- 手动管理 manual
举例
为数据库创建一个永久性的表空间HRTBS1,区自动扩展,段采用自动管理方式
create tablespace HRTBS1 datafile
'D:\hei_mao_ji_jiang.dbf' size 50M;
为数据库创建一个永久性的表空间HRTBS2,区定制分配,段采用自动管理方式
create tablespace HRTBS2 datafile
'D:\hei_mao_ji_jiang.dbf' size 50M
extend management local
uniform size 512k;
为数据库创建一个永久性的表空间HRTBS3,区定制分配,段采用手动管理方式
create tablespace HRTBS2 datafile
'D:\hei_mao_ji_jiang.dbf' size 50M
extent management local
uniform size 512k
segment space management manual;
数据文件的设置与管理
创建
创建数据文件就是向表空间添加文件的过程,在创建数据文件的时候,根据数据量的大小确定文件的大小和文件的增长方式。
添加数据文件语句为alter tablespace … add datafile
添加临时数据文件语句为alter tablespace … add tempfile
例题:
>向uses表空间中添加一个大小为10MB的数据文件
ALTER TABLESPACE USERS ADD DATAFILE
‘D:\app\LRZYTBS1.DBF’SIZE 50M;
修改数据文件
数据文件建立之后,改变它们的名称或者位置也可以用sql语句完成
如果要改变的数据文件属于同一表空间,使用alter tablespace … rename datafile … to
如果要改变的数据文件属于多个表空间,使用alter database rename file … to
设计分区表
随着表的不断增大,对于新纪录的增加、查找、删除等DML的维护也更加困难。对于数据库中的超大型表,可通过把它的数据分成若干个小表,从而简化数据库的管理活动。对于每一个简化后的小表,我们称为一个单个的分区。
oracle分区表的分区有四种类型:范围分区、散列分区、列表分区和复合分区。
1、范围分区
就是根据数据库表中某一字段的值的范围来划分分区。
数据中有空值,Oracle机制会自动将其规划到maxvalue的分区中。
2、散列分区
根据字段的hash值进行均匀分布,尽可能地实现各分区所散列的数据相等。
散列分区即为哈希分区,Oracle采用哈希码技术分区,具体分区如何由Oracle说的算,也可能我下一次搜索就不是这个数据了。
3、列表分区
列表分区明确指定了根据某字段的某个具体值进行分区,而不是像范围分区那样根据字段的值范围来划分的。
4、复合分区
根据范围分区后,每个分区内的数据再散列地分布在几个表空间中,这样我们就要使用复合分区。复合分区是先使用范围分区,然后在每个分区同再使用散列分区的一种分区方法。
比如将part_date的记录按时间分区,然后每个分区中的数据分三个子分区,将数据散列地存储在三个指定的表空间中。
创建范围分区表
创建一个分区表student_range,将学生信息根据其出生日期进行分区,将1980-1-1前出生的学生信息保存在ORCLTB1表空间中,将1980-1-1至1990-1-1间出生的学生信息保存在ORCLTB2表空间中,其他的学生信息保存在USERS表空间
create table student_range(
sno number(6),
sname varchar2(20),
birthday DATE
)
partition by range(birthday)(
partition p1 values less than(to_date('1980-1-1','YYYY-MM-DD')) tablespace ORACLTB1,
partition p2 values less than(to_date('1990-1-1','YYYY-MM-DD')) tablespace ORACLTB2,
partition p3 values less than(MAXVALYE) tablespace ORACLTB3;
)
创建列表分区表
创建一个分区表student_list,将学生信息根据性别进行分区,将男生信息保存在ORCLTB1表空间中,女生信息保存在ORCLTB2表空间中。
create table student_list(
sno number(6) PRIMARY KEY,
sname varchar2(20),
sex char(2),
birth date
)
partition by list(sex)(
partition man values('M') tablesoace ORCLTB1,
partition woman values('W') tablesoace ORCLTB2;
)
创建散列分区表
创建一个分区表student_hash,将学生信息均衡保存在ORCLTB1和ORCLTB2表空间中
create table student_hash(
sno number(6) PRIMARY KEY,
sname varchar2(20),
sex char(2),
birth date
)
partition by hash(sno)(
partition p1 tablespace ORCLTB1,
partition p2 tablespace ORCLTB2;
)
TOP-N查询
select * from *
where ... --按照什么方式筛查
order by .. -- 按照特定列排序
offset n rows --删除前n个元素
fetch first m rows with ties -- 从结果中体现前m名
在ORACLE12C中,增加了一些新的特性。可以指定返回结果集的指定数量的行、或按照百分比返回行。
举例
查询50号部门中工资排序在3~6名之间的员工信息
select * from employees
where dept_id = 50
order by salary desc
offset 2 rows
fetch first 4 rows with ties;
层次查询
层次查询又称树形查询,能够将一个表中的数据按照记录之间的联系以树状结构的形式显示出来。
select * from
start with .. --层次查询的起始记录
connect by prior 子树列 = 父列 --指定父记录与子记录之间的关系及分支选择条件
举例
利用分级查询显示emp表中员工与领导之间的关系(从高到低)
select * from emp
start with empno = 1
connect by prior empno = mgr;
查询显示工资大于2000元且最高领导为JONES的员工信息
select * from emp
where salary > 2000
start with emp.ename = 'JONES'
connect by prior empno = mgr;
查询员工信息,不包括以7698号员工为最高领导的员工
select * from emp
start with 7698
connect by prior empno = mgr and empno != 7698;
一些概念
数据库设计的步骤和方法
-
需求分析
-
概念结构设计
-
逻辑结构设计
-
表结构设计
-
序列设计
-
索引设计
-
视图设计
-
存储过程设计
-
函数设计
-
触发器设计
-
-
数据库的创建
Oracle数据库体系结构的构成
Oracle 数据库体系结构由物理存储结构、逻辑存储结构和实例组成
Oracle中的数据库相当于存储结构,数据库管理系统DBMS相当于软件结构
对于逻辑结构又分为:
- 物理存储结构:操作系统中的一系列文件
- 逻辑存储结构:对物理存储结构的逻辑组织与管理,由表空间、段、区、块组成
对于软件结构(即实例INSTANCE),包括:
- 内存结构
- 后台进程
用户操作都是通过实例完成的,首先在内存结构中进行,在一定条件下由数据库后台进程写入数据库的物理存储结构作永久保存
- 一个数据库划分为一个或多个逻辑单位,该逻辑单位就是表空间
- 每一个表空间可能包含一个或多个段
- 段指在表空间中为特定逻辑存储结构分配的空间。包括数据段、索引段、回滚段和临时段
- 每一个段是由一个或多个区组成
- 区是由一系列连续的数据块组成
- ORACLE通过区来给段分配空间
- 数据块是Oracle数据库最小的I/O存储单位,一个数据块对应一个或多个分配给数据文件的操作系统块
关系型数据库和非关系型数据库的异同点及优势所在
非关系型数据库
特点:
- 非结构化的存储
- 基于多维关系模型
- 具有特有的使用场景
优点:
- 高并发,大数据下读写能力较强
- 基本支持分布式,易于扩展,可伸缩
- 简单,弱结构化存储
缺点:
- join等复杂操作能力较弱
- 事务支持较弱
- 通用性差
- 无完整约束复杂业务场景支持较差。
使用情境:
单表数据量超千万,而且并发还挺高;数据分析需求较弱,或者不需要那么灵活或者实时
关系型数据库
特点:
- 数据关系模型基于关系模型,结构化存储,完整性约束
- 基于二维表及其之间的联系,需要连接、并、交、差、除等数据操作
- 采用结构化的查询语言(SQL)做数据读写
- 操作需要数据的一致性,需要事务甚至是强一致性
优点:
- 保持数据的一致性(事务处理)
- 可以进行join等复杂查询
- 通用化,技术成熟
缺点:
- 数据读写必须经过sql解析,大量数据、高并发下读写性能不足
- 对数据做读写,或修改数据结构时需要加锁,影响并发操作
- 无法适应非结构化存储
- 扩展困难
- 昂贵、复杂
使用情境:
主要需求是数据分析,比如做报表;单表数据量不超过千万

















 4101
4101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









