







安装
从hadoop官网下载hadoop安装包,解压到安装目录,安装目录最好在用户目录下,因为在用户目录下当前用户拥有直接读写权限,不用sudo也不会报权限错误,而后配置环境变量
下载地址:http://hadoop.apache.org/releases.html
官方安装文档:
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/ClusterSetup.html
非安全模式配置
1.配置文件说明
hadoop配置文件在etc/hadoop/目录下,包含两种类型
默认配置文件:
core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml
自定义配置文件:
core-site.xml, hdfs-site.xml,yarn-site.xml and mapred-site.xml
自定义配置文件优先级高于默认配置文件,直接配置自定义文件就可以
2.守护进程说明

上图对应守护进程配置环境变量,根据需要配置,环境变量配置文件(etc/hadoop目录下):hadoop-env.sh mapred-env.sh yarn-env.sh
JAVA_HOME:jdk安装位置(必要最简化配置)
HADOOP_PID_DIR:Hadoop进程id存放文件目录,可自定义
HADOOP_LOG_DIR:Hadoop日志存放目录,可自定义
export JAVA_HOME=/home/user/hadoop/jdk1.8.0_121
# Where log files are stored. $HADOOP_HOME/logs by default.
export HADOOP_PID_DIR=/home/user/hadoop/hadoop-2.7.3/logs
export HADOOP_LOG_DIR=/home/user/hadoop/hadoop-2.7.3/logs此外在log4j.properties中也有日志存储目录,不知道两者是否关联,如果上述日志存储目录配置不可用,可在log4j中尝试配置
配置site文件
1.core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/user/hadoop/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>2.hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/user/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/user/hadoop-2.7.3/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>3.yarn-site.xml
master为主机名,需要在/etc/hostname和/etc/hosts中配置
<configuration>
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>4.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>Yarn</value>
</property>
</configuration>启动服务
1.初次启动前初始化
hdfs namenode -format <cluster_name>2.启动服务
start-all.sh3.测试安装是否成功
访问http://localhost:50070 http://localhost:8088
若出现管理界面则成功
分布式集群配置
1.在hosts文件中添加集群机器hostname和ip对应关系及配置slaves文件
192.168.241.20 master
192.168.241.30 node在hadoop配置文件目录(${HADOOP_HOME}/etc/hadoop)下配置slaves文件,添加两者hostname
master
node2.复制虚拟机系统,并修改网络配置和hostname
将虚拟机系统文件夹复制一份到文件夹下并用WMware WorkStation打开,并配置网络,ip设置为192.168.241.30
参考:http://blog.csdn.net/flushest/article/details/58702349中网络配置这一块内容
网络配置之后需要测试一下网络是否畅通
sudo gedit /etc/hostname将hostname修改为node
3.在master主机上启动hadoop服务
start-all.sh #已经过时,不过还可以用
或者
start-hdfs.sh & start-yarn.sh4.测试集群是否部署成功
在master主机上,会启动如下进程:
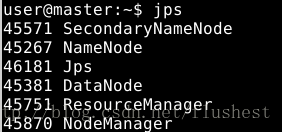
在node主机上,只会启动NameNode、JPS、DataNode三个进程















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









