







HashMap的源码关键解读
一:整体结构
hashMap的源码有太多文章解读了,这里只是记录关键点。对很多不重要的东西略过了。
java8以后对于hashMap的整体做了优化,是基于一个数组+链表+红黑树的实现。结构图如下:
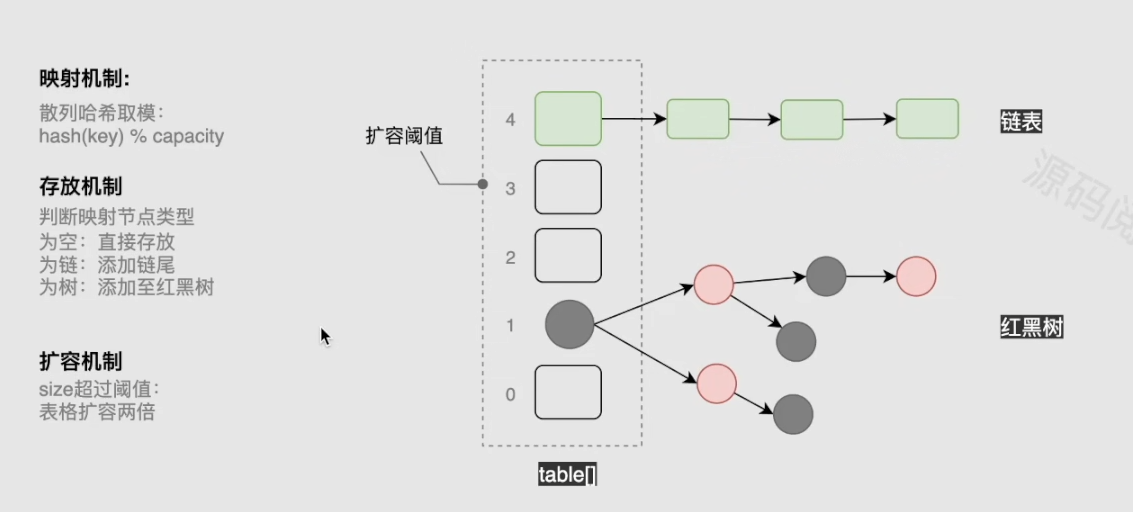
二:key索引映射
- 当我们往hashMap里面put数据的时候,会先获key在数组中的位置。但是hashMap为了让我们的数据在数组中更加分散,在取模前进行了散列hash。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
源码如上,
关键代码简化如下:
int h = key.hashCode();
h ^ (h >>> 16);
将key的hashcode 和 key的hashcode 右移16位值进行异或操作。这里有两个优化点
1:散列算法
直接用key的hashcode取模的话,只有hashcode的后面几位可以影响取模的结果,可能会导致数据分布不均,hash冲突严重。
所以采用将hashcode 的int值的32位分成16位的高位和16位的低位,然后将值右移16位。最终效果就是将高位和低位进行异或操作,让高位值参与到后面计算中。尽可能的将key再数组中打散,同时添加性能也好。正如源码注释说最具性价比的打散方式。
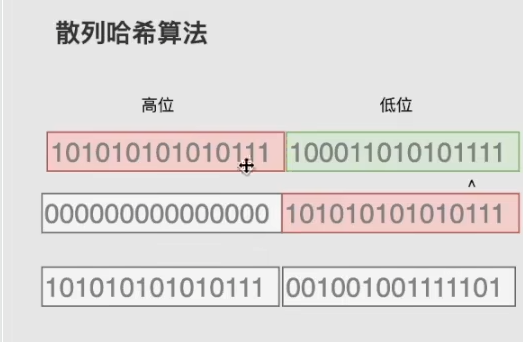
ps:如果key的hashcode小于2的16次方(65536)那么这个散列算法没有作用的。
2:取模优化
将hashcode 散列后得到散列值,还需要确认我们key存储到table[]数组的什么位置,如果对散列值进行直接取模table[]数组的size 也是可以得到key存放到数组的什么位置的。但是源码采用的&的方法,可以达到和取模一样的效果,源码如下:
(n - 1) & hash
这里的n = tab.length,这种方法必须数组的大小必须是2的倍数。
下面就是hashMap扩容时候获取数组大小的源码
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
cap是扩容的容量值,然后减一得到n。后面五次移位然后再和原值或得操作,者五部主要得到扩容容量是2得倍数。
为什么一定是2得倍数呢?首先n是int值是32位得,然后第一位一定是1;
加入现在n=17 二进制就是10001 然后右移动一位,就是1000 然后和10001或之后得到11001,然后第二次操作得到11111。按照上面五部,移动就是32位。所有得值都是1了。然后加1 就一定是2得倍数了。
为啥要n = cap - 1 这里主要是扩容得cap本来就是2得倍数得时候,计算后的值会比原来大一倍。减去以后处理cap为2得倍数得时候,计算后值还是原值。
继续看这段代码: (n - 1) & hash。这段代码是hash&n一样得。
n-1 一定全部都是1,这个前面已经说了。假如n=16 那n-1 =15,二进制就是1111,假如hash=0111110110和1111执行与操作就是0110,也就是取了n-1映射得后面几位和取模一样得。但是比取模性能要搞。
这也就是为什么数组扩容一定是要2得倍数。
三:HashMap的扩容
1:获取扩容得大小
关于数组得扩容为啥是2得倍数,前面已经说明过了,这里就不再重复说明了。
2:将数组,链表,红黑树拷贝到新得位置。
数据拷贝,在源码里面就是resize 方法。数据拷贝需要重新对数据进行位置安排了。
-
空数据
-
数组数据
重新映射拷贝到新表格
-
链表数据
低链基于当前索引放到存放新表格,也就是原来索引是4,新得索引位置还是4;
高链放置当前索引+旧容量位置,原来索引是4,原来得容量是16,那么新得索引位置就是16+4=20;
如何理解高链和低链呢?
前面说过我们得计算索引得方法是,容量减一,然后与hash值。假如现在A得hash是111010,b得hash是101010,数组得容量是16,减一后的二级制就是1111。那么A,B原来得索引位置就是1010 =10 得位置。
然后现在扩容一倍,就是32了,减去一二进制就是11111 如下图:

分别与计算后结果是:11010,1010,换成二级制就是26,10。从结果知道B得记过没有变,我们定义为低链,A定义为高链。
这个26 也可以用另外方法计算出来就是原来容量16,加上原来得索引10。
上面讲得原理,下面看看源码是如何计算高链和低链得。
(e.hash & oldCap) == 0node得hash值,原来数组得容量,等于0就是高链,否则就是低链。
-
红黑树数据
拆分树重新映射,扩容后冲突少了,可能重变成链表结构。
四:put的流程
略,
补充一点就是,链表树化得时候有两个条件1:链表长度超过8,2:就是数组大小大于等于64,小于得话先扩容。















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









