







本次实验参考了官方文档如下:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html
版本说明:
操作系统:rhel-linux-64
hadoop版本:hadoop-3.0.0-alpha1 下载地址:http://hadoop.apache.org/releases.html
Java版本:jdk 1.8 下载地址:https://www.java.com/en/download/manual.jsp#lin
一:环境配置
1、安装jdk:
[root@test2 setup]# rpm -ivh jre-8u111-linux-x64.rpm
2、安装配置pdsh
[root@test2 setup]# tar -jxf pdsh-2.26.tar.bz2 && cd pdsh-2.26
[root@test2 pdsh-2.26]# ./configure --with-ssh --without-rsh && make && make install
[hadoop@test2 pdsh-2.26] # pdsh -v
3、创建hadoop 用户:
[root@test1 ~]# useradd hadoop
[root@test1 ~]# passwd hadoop
4、Hadoop用户解压缩安装包:
[hadoop@test2 setup]# gunzip hadoop-3.0.0-alpha1.tar.gz
[hadoop@test2 setup]# tar -xvf hadoop-3.0.0-alpha1.tar
5、在hadoop环境变量文件中设置java环境变量
[hadoop@test2 hadoop-3.0.0-alpha1]$ vi etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jre1.8.0_111
6、Hadoop用户设置java环境变量
[hadoop@test2 latest]$ export JAVA_HOME=/usr/java/jre1.8.0_111
7、查看java为1.8版本
[hadoop@test2 latest]$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build25.111-b14, mixed mode)
二:搭建伪分布式hadoop
伪分布式搭建(Hadoop的伪分布式就是可以运行在一个节点上但hadoop守护进程运行在每个独立的java进程中)
1、修改core-site.xml文件 hadoop-3.0.0-alpha1/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2、修改hdfs-site.xml文件 hadoop-3.0.0-alpha1/etc/hadoop/ hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3、设置ssh信任
[hadoop@test2 ~]$ ssh-keygen -t rsa
[hadoop@test2 ~]$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys
[hadoop@test2 ~]$ cd .ssh
[hadoop@test2 .ssh]$ chmod 0600 authorized_keys
无需密码既能返回日期即表示成功
[hadoop@test2 .ssh]$ ssh localhost date
Fri Nov 18 10:17:14 CST 2016
4、格式化文件系统
[hadoop@test2 hadoop-3.0.0-alpha1]$ ./bin/hdfs namenode -format
5、启动NameNode和DataNode
[hadoop@test2 hadoop-3.0.0-alpha1]$./sbin/start-dfs.sh
注:hadoop的日志写入到 $HADOOP_LOG_DIR 目录 (默认是 $HADOOP_LOG_DIR /logs)6、NameNode 的默认地址:http://localhost:9870/
(本次测试服务器的IP是192.168.56.59)
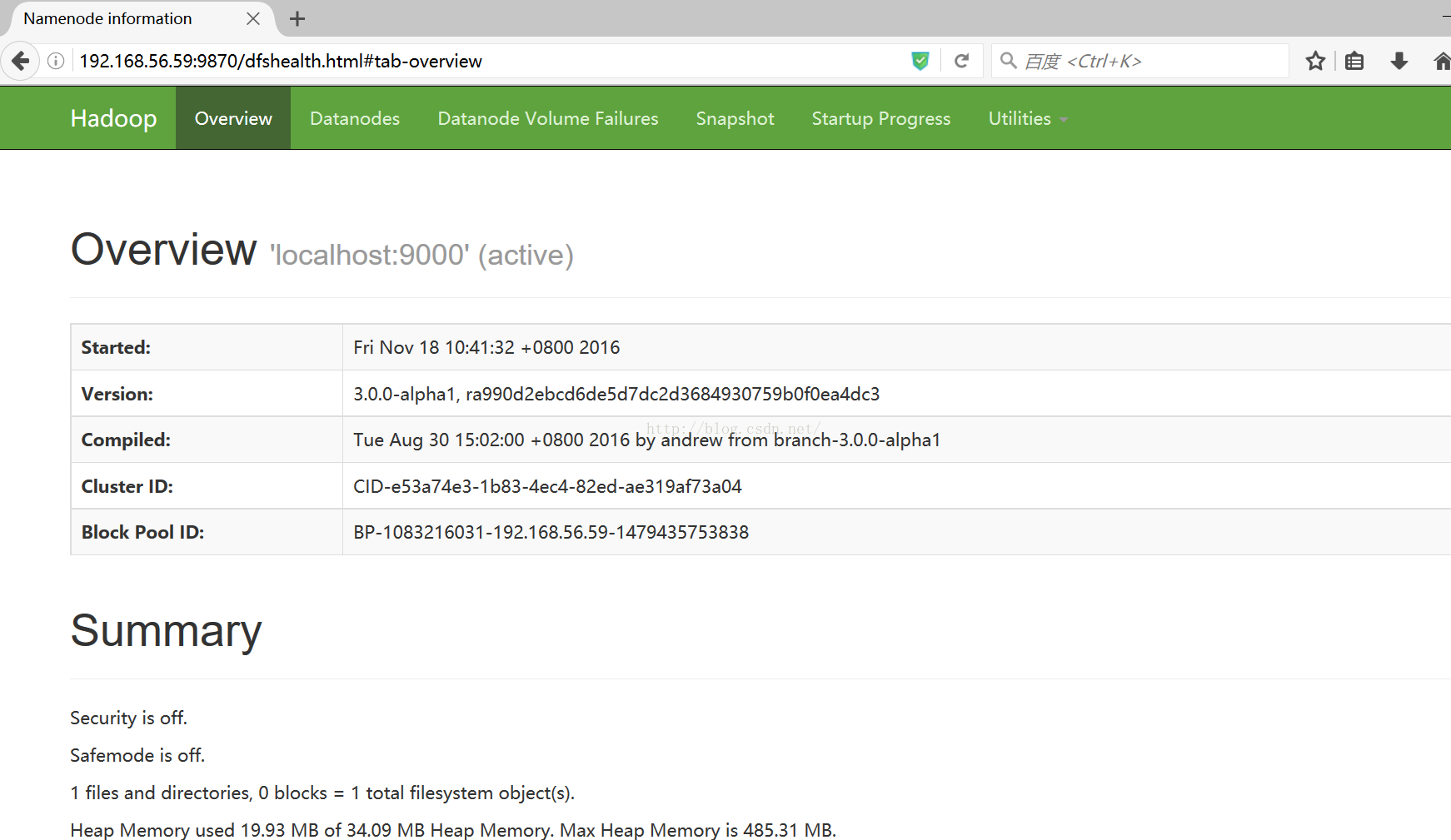
7、生成HDFS的目录以便执行MapReduce任务
[hadoop@test2 hadoop-3.0.0-alpha1]$./bin/hdfs dfs -mkdir /user
[hadoop@test2 hadoop-3.0.0-alpha1]$./bin/hdfs dfs -mkdir /user/hadoopuser
8、把输入文件拷贝一份到分布式文件系统中
[hadoop@test2 hadoop-3.0.0-alpha1]$./bin/hdfs dfs -mkdir /user/hadoopuser/input
[hadoop@test2 hadoop-3.0.0-alpha1]$./bin/hdfs dfs -put etc/hadoop/*.xml /user/hadoopuser/input
9、运行一些示例程序
[hadoop@test2 hadoop-3.0.0-alpha1]$./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-alpha1.jar grep
/user/hadoopuser/input output 'dfs[a-z.]+'
10、查看输出文件,将输出文件从分布式文件系统拷贝到本地然后查看
[hadoop@test2 hadoop-3.0.0-alpha1]$./bin/hdfs dfs -get output output
[hadoop@test2 hadoop-3.0.0-alpha1]$ cat output/*
或者在分布式文件系统上查看输出文件
[hadoop@test2 hadoop-3.0.0-alpha1]$./bin/hdfs dfs -cat output/*
11、停止服务进程
[hadoop@test2 hadoop-3.0.0-alpha1]$ ./sbin/stop-dfs.sh
三:YARN的配置
1、修改mapred-site.xml文件 hadoop-3.0.0-alpha1/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
</configuration>
2、修改yarn-site.xml文件 hadoop-3.0.0-alpha1/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3、开启资源管理和节点管理
[hadoop@test2 hadoop-3.0.0-alpha1]$./sbin/start-yarn.sh4、资源管理的默认地址:http://localhost:8088/
(本次测试服务器的IP是192.168.56.59)
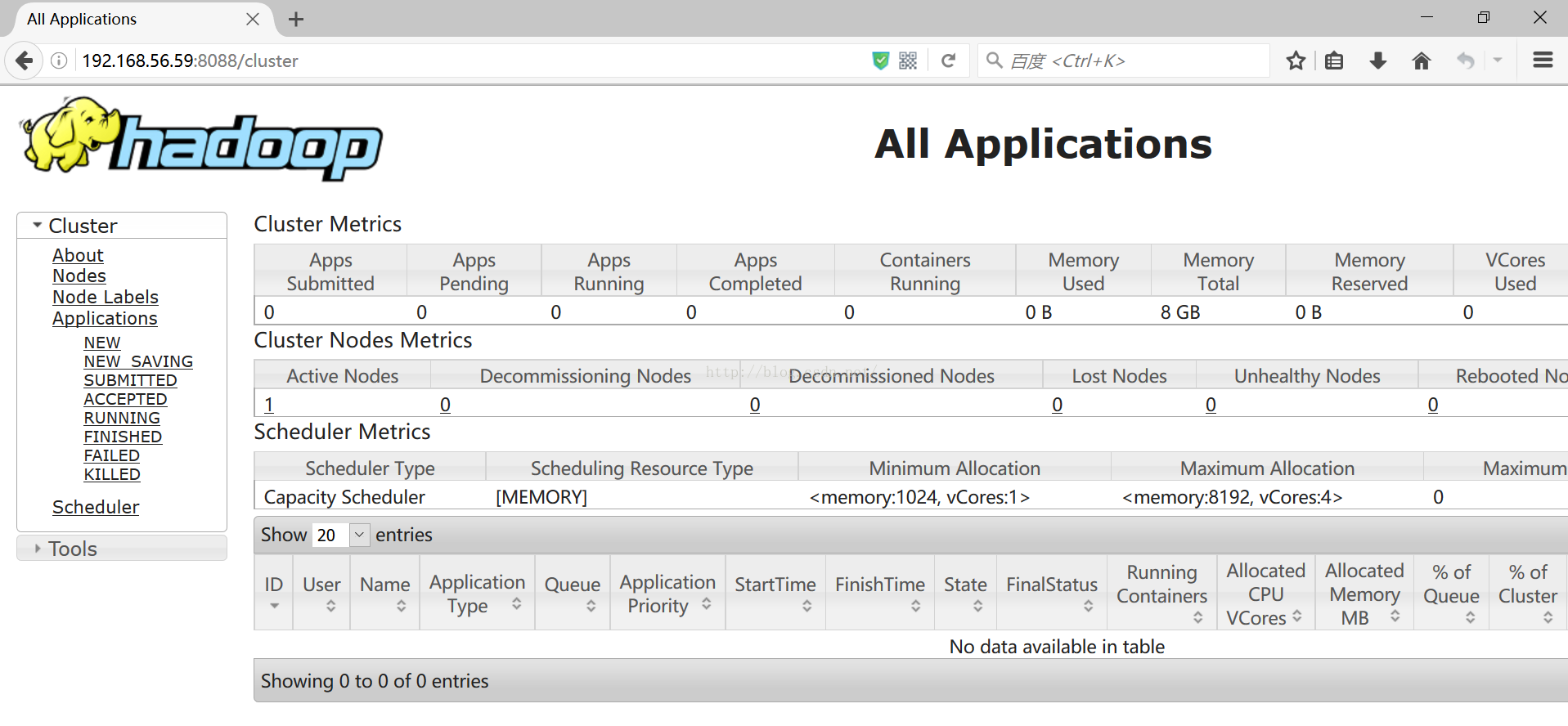
5、关闭资源管理和节点管理
[hadoop@test2 hadoop-3.0.0-alpha1]$./sbin/stop-yarn.sh














 3834
3834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









