









背景:业务需要全国省市区的划分以及3级级联,正好想起2018年曾经抓取过国家统计局网站的去全国统计用区划代码和城乡划分代码,原资源的地址:2018年全国统计用区划代码和城乡划分代码.sql-MySQL文档类资源-CSDN下载
看到2021年已经更新,正好拿原来的代码看看是否还能跑。
代码测试:1、网站由原来的gbk转换为utf-8
2、抓取过程中会经常连接失败导致
3、失败后无法从失败处继续
那为了能顺利完成任务,需要对原有代码进行改造优化。
步骤如下:
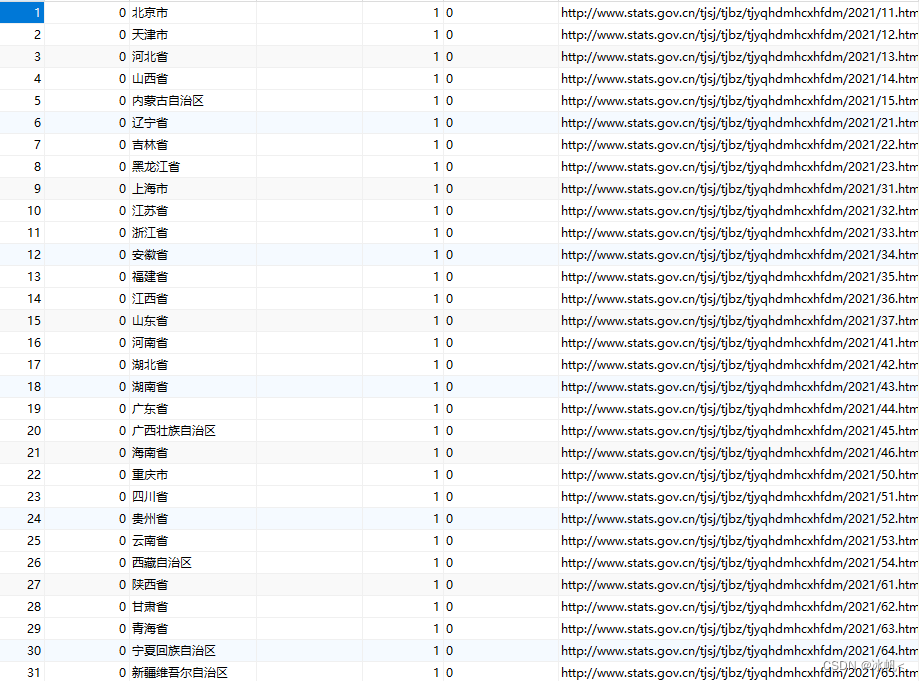
1、目标url:2021年统计用区划代码和城乡划分代码
据粉丝反馈最新的url:2022年统计用区划代码和城乡划分代码
2、mysql 表结构
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for tab_citys
-- ----------------------------
DROP TABLE IF EXISTS `tab_citys`;
CREATE TABLE `tab_citys` (
`id` int(11) NOT NULL AUTO_INCREMENT comment '自动id',
`parent_id` int(11) DEFAULT NULL comment '父id',
`city_name_zh` varchar(20) NOT NULL comment '名称',
`vcode` varchar(20) DEFAULT NULL comment '城乡划分代码',
`city_level` int(11) NOT NULL comment '级别,共五级,1省2城市3区4街道5居委会',
`city_code` char(12) NOT NULL comment '区划代码',
`next_url` char(200) NOT NULL comment '下一级的url',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;3、原则:
1)从第一级开始,依次抓取直到第五级,依次往复迭代,直接完成。
2)如果中途失败,从mysql中读取上次写入最后一条记录处,继续开始
3)防止多次连接导致,服务器判断为爬虫,ip禁用。
4、python 核心代码
import importlib
import sys
import time
import random
import MySQLdb
importlib.reload(sys)
import requests
import lxml.etree as etree
import os
UA_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
class chinese_city():
# 初始化函数
def __init__(self):
self.baseUrl = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2021/index.html'
self.base = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2021/'
self.conn = MySQLdb.connect(host="127.0.0.1", port=3306, user="root", passwd="***", db="test", charset='utf8')
self.cur = self.conn.cursor()
self.trdic = {
1: '//tr[@class="provincetr"]',
2: '//tr[@class="citytr"]',
3: '//tr[@class="countytr"]',
4: '//tr[@class="towntr"]',
5: '//tr[@class="villagetr"]'
}
def __del__(self):
if self.cur:
self.cur.close()
if self.conn:
self.conn.close()
@staticmethod
def log(log_str):
t = time.strftime(r"%Y-%m-%d %H:%M:%S", time.localtime())
print("[%s]%s" % (t, log_str))
def get_now_time(self):
"""
获取当前日期时间
:return:当前日期时间
"""
now = time.localtime()
now_time = time.strftime("%Y-%m-%d %H:%M:%S", now)
return now_time
def crawl_page(self,url):
''' 爬行政区划代码公布页 '''
self.log(f"crawling...{url}")
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'}
flag = True
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 这里添加一行
text = response.text
time.sleep(2)
return text
#解析省页,返回list
def parseProvince(self):
html = self.crawl_page(self.baseUrl)
tree = etree.HTML(html, parser=etree.HTMLParser(encoding='utf-8'))
nodes = tree.xpath('//tr[@class="provincetr"]')
id = 1
values = []
for node in nodes:
items = node.xpath('./td')
for item in items:
value = {}
nexturl = item.xpath('./a/@href')
province = item.xpath('./a/text()')
self.log(province)
value['url'] = self.base + "".join(nexturl)
value['name'] = "".join(province)
value['vcode'] = ""
value['code'] = 0
value['pid'] = 0
value['id'] = id
value['level'] = 1
self.log(repr(value['name']))
id = id + 1
last_id = self.insert_to_db(value)
value['id'] = last_id
values.append(value)
self.log(value)
return values
#根据trid 解析子页
def parse(self,trid, pid, url):
if url.strip() == '':
return None
# url_prefix+url
html = self.crawl_page(url)
tree = etree.HTML(html, parser=etree.HTMLParser(encoding='utf-8'))
nodes = tree.xpath(self.trdic.get(trid))
path = os.path.basename(url)
base_url = url.replace(path, '')
id = 1
values = []
# 多个城市
for node in nodes:
value = {}
nexturl = node.xpath('./td[1]/a/@href')
if len(nexturl) == 0:
nexturl = ''
code = node.xpath('./td[1]/a/text()')
if len(code) == 0:
code = node.xpath('./td[1]/text()')
name = node.xpath('./td[2]/a/text()')
if len(name) == 0:
name = node.xpath('./td[2]/text()')
value['code'] = "".join(code)
urltemp = "".join(nexturl)
if len(urltemp) != 0:
value['url'] = base_url + "".join(nexturl)
else:
value['url'] = ''
value['name'] = "".join(name)
value['vcode'] = ""
self.log(repr(value['name']))
self.log(value['url'])
value['id'] = id
value['pid'] = pid
value['level'] = trid
id = id + 1
last_id = self.insert_to_db(value)
value['id'] = last_id
values.append(value)
self.log(value)
return values
#解析社区页
def parseVillager(self,trid, pid, url):
html = self.crawl_page(url)
tree = etree.HTML(html, parser=etree.HTMLParser(encoding='utf-8'))
nodes = tree.xpath(self.trdic.get(trid))
id = 1
values = []
# 多个城市
for node in nodes:
value = {}
nexturl = node.xpath('./td[1]/a/@href')
code = node.xpath('./td[1]/text()')
vcode = node.xpath('./td[2]/text()')
name = node.xpath('./td[3]/text()')
value['code'] = "".join(code)
value['url'] = "".join(nexturl)
value['name'] = "".join(name)
value['vcode'] = "".join(vcode)
self.log(repr(value['name']))
value['id'] = id
value['pid'] = pid
value['level'] = trid
values.append(value)
id = id + 1
last_id = self.insert_to_db(value)
value['id'] = last_id
values.append(value)
self.log(value)
return values
#插入数据库
def insert_to_db(self,taobao):
# return 0
param = []
lastid = 0
try:
sql = 'INSERT INTO tab_china_citys values(%s,%s,%s,%s,%s, %s,%s)'
param = (0, taobao.get("pid"), taobao.get("name"), taobao.get("vcode"), taobao.get("level"), taobao.get("code"), taobao.get("url"))
self.cur.execute(sql, param)
lastid = self.cur.lastrowid
self.conn.commit()
except Exception as e:
self.log(e)
self.conn.rollback()
return lastid
#从头执行解析
def parseChineseCity(self):
flag = 1
city_flag = 0;
count_flag = 0
town_flag = 0
#先从数据库中获取省份数据
values = self.parseProvince()
略
if __name__ == '__main__':
chinese_city = chinese_city()
chinese_city.parseChineseCity()
若有需要完整代码或者mysql 导入脚本,请私我。
附上mysql 下载地址:
链接:https://pan.baidu.com/s/1JX0sd6Gq2bivp2wXNYeJSA?pwd=YYDS
提取码:YYDS
朋友们可以自由下载

















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











