






Piece it Together(PiT)通过将给定元素无缝集成到连贯的组合中,同时添加完整概念驻留在先验域中所需的必要缺失部分,有效地完成了缺失的信息。
《PiT:用视觉碎片拼出完整创意》

在艺术创作和设计领域,很多时候,一个独特的灵感来源于某个视觉元素的碎片,比如一个特别的翅膀结构、一种独特的发型,它们就像是散落的拼图碎片,等待着创作者将它们拼凑成一个完整而富有创意的概念。然而,传统的生成模型往往依赖于文本描述来生成图像,这在一定程度上限制了视觉灵感的直接表达和拓展。现在,一种名为“Piece it Together(PiT)”的新方法,为这一问题带来了创新的解决方案。
一、PiT:让视觉碎片“拼”出完整概念
PiT 是一种先进的生成框架,它能够将用户提供的部分视觉组件无缝整合到一个连贯的构图中,同时生成缺失的部分,从而创造出一个完整且合理的概念。这种方法的核心在于其独特的 IP-Prior 模型,它基于 IP-Adapter+ 的内部表示空间构建,通过轻量级的流匹配模型,根据特定领域的先验知识合成连贯的构图,实现多样化且具有上下文感知能力的生成效果。



PiT 的强大架构与工作原理
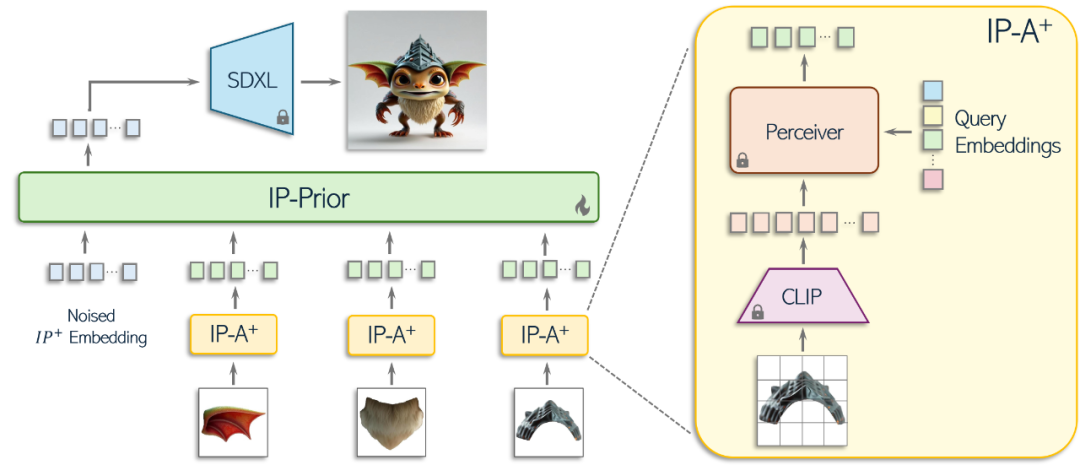
The IP-Prior Architecture 架构概览
PiT 的架构设计巧妙。它首先从输入图像中提取语义组件,然后对这些组件进行采样,并使用冻结的 IP-Adapter+ 将每个图像块编码到 IP+ 空间。接着,这些图像嵌入通过 IP-Prior 模型进行处理,模型输出一个清晰的图像嵌入,捕捉到预期的概念,最后利用 SDXL 生成概念图像。在推理阶段,用户可以提供不同数量的对象部件图像,以生成与所学分布一致的新概念。

生成的样本
IP+ 空间的优势
IP+ 空间是 PiT 的关键所在。与 CLIP 空间相比,IP+ 空间在语义操作方面表现出色,同时又能更好地保留复杂的概念和细节。这是因为 CLIP 空间虽然适合语义操作,但在图像重建方面存在局限性,它在训练时主要关注文本和图像的联合表示空间,而不是图像的细节重建。而 IP+ 空间则在保留语义操作能力的同时,显著提升了图像重建的质量,能够更有效地作为视觉概念的表示空间。

如上图,将输入图像(左)编码到两个不同的嵌入空间中,通过遍历每个空间来修改其潜在表示,并使用SDXL渲染编辑后的图像。如图所示,CLIP在重建概念和遵循所需编辑方面都很困难,而在IP+空间中,渲染的图像在整个范围内都忠实于概念和所需的编辑。
其他示例:

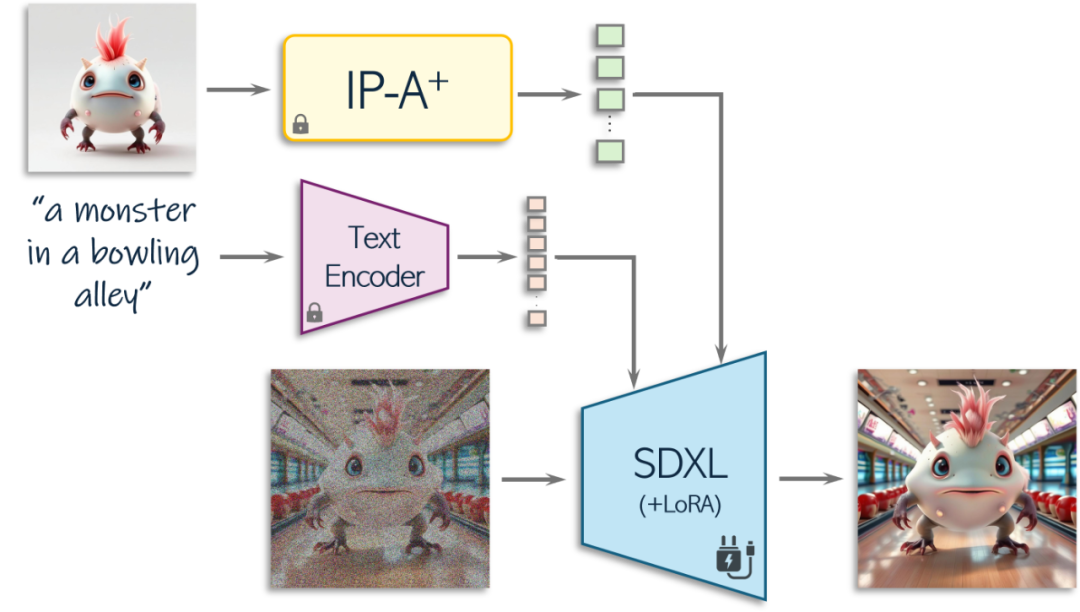
IP-LoRA:提升文本依从性
虽然 IP-Adapter+ 能够通过 SDXL 渲染生成的概念,但在文本依从性方面常常面临挑战。为了解决这一问题,PiT 引入了 IP-LoRA,这是一种基于 LoRA 的微调策略。通过在配对样本上对 LoRA 适配器进行微调,其中条件图像具有干净的背景,目标图像将对象放置在使用文本提示描述的场景中,这种轻量级的训练(仅使用 50 个提示)有效地恢复了文本控制能力,同时保持了视觉保真度。此外,这种调整机制还可以用于在 SDXL 模型的输出上强制执行特定风格,当使用相同的概念嵌入输入进行条件约束时,能够生成符合特定风格的图像。
PiT 的生成成果
PiT 在生成各种概念方面展现出了卓越的能力。无论是奇幻生物、产品设计还是玩具创意,它都能根据用户提供的视觉组件,生成丰富多样的完整概念。这些生成结果不仅在视觉上连贯,而且与用户的输入元素紧密相连,充分体现了 PiT 在创意整合方面的强大实力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









