






大家好,今天和大家分享几篇最新的工作
1、Stable-Hair
Stable-Hair 是一个发型迁移算法,甚至在真实的环境效果也能保证较好的效果。具体来说,输入一张 source 图片(希望变换发型的人脸)和一张 reference image(预期发型的人脸),如下图所示,
第一行是目标发型,第一列为source image,按行(从第二行开始)查看生成的效果,除了发型变化外,人脸的特征保留完整

实现思路:
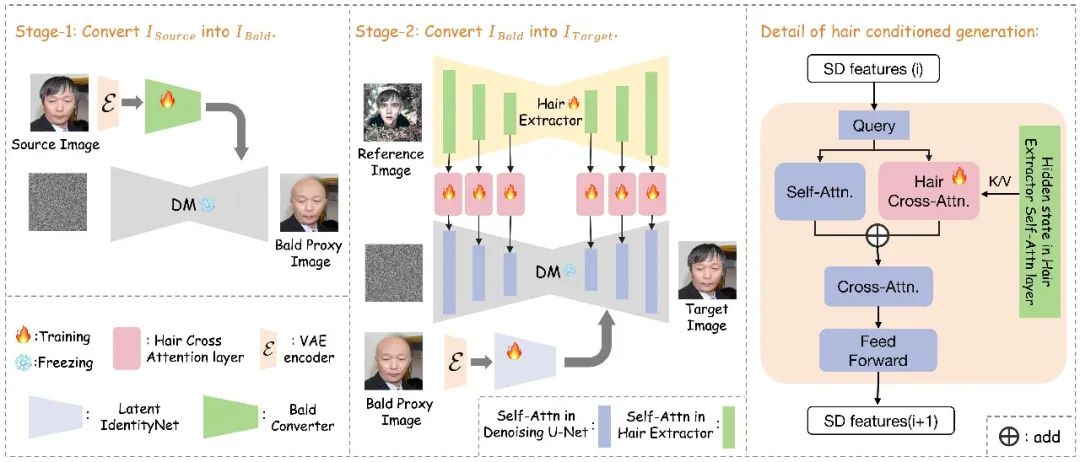
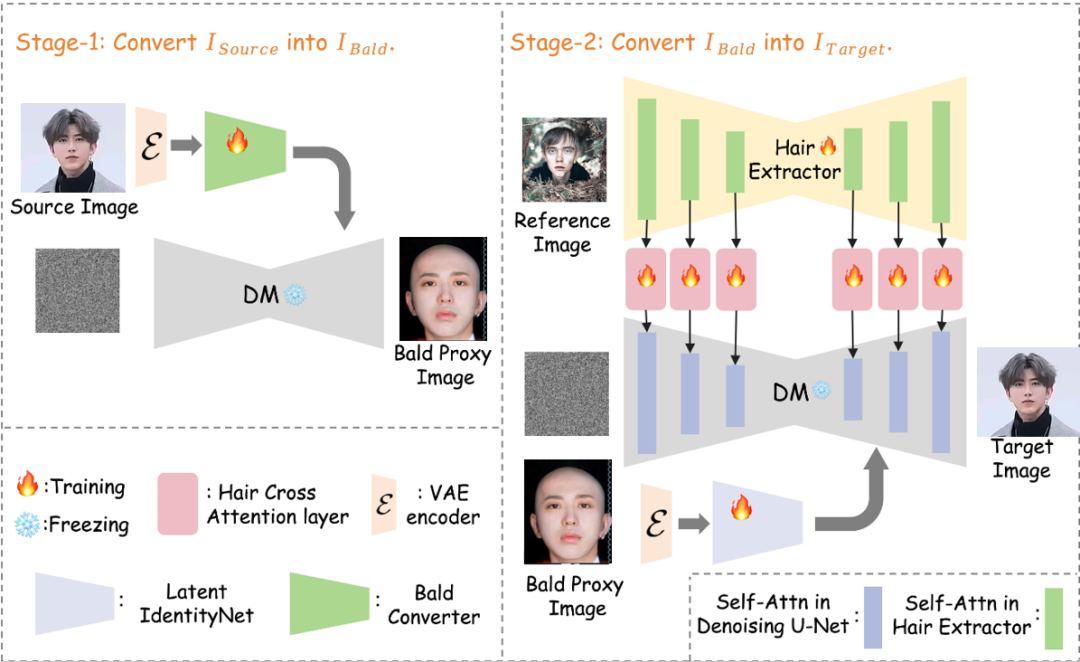
Stable-Hair 由两个阶段组成,来实现高质量的发型迁移。
1)首先,将用户输入的源图像转换为秃头图像。该转换是使用预训练的稳定扩散 (SD) 模型与专门的秃头转换器结合来完成的。- 如左上角所示
2)在第二阶段,采用预训练的 SD 模型和发型提取器将参考发型转移到秃头图像上。发型提取器负责捕获参考发型的复杂细节和特征。然后通过新添加的发型交叉注意层将这些特征注入到 SD 模型中。
通过利用这两个阶段,该方法实现了高度详细和高保真度的发型移植,产生自然且视觉上吸引人的结果。
更多测试效果:
与其他方法相比,stable-hair方法实现了更精细和稳定的发型转移,而不需要精确的面部对齐或明确的掩模进行监督。

该方法的稳健性使得发型能够跨不同领域转移,这是以前的方法无法实现的能力。

更多其他测试效果:

论文和项目地址:
https://xiaojiu-z.github.io/Stable-Hair.github.io/
https://arxiv.org/pdf/2407.14078
https://github.com/Xiaojiu-z/Stable-Hair
2、T2V-CompBench
在这项工作中,对组合文本到视频的生成进行了首次系统研究。提出了 T2V-CompBench,这是第一个专为合成文本到视频生成而定制的基准测试。T2V-CompBench 涵盖组合性的各个方面,包括一致的属性绑定、动态属性绑定、空间关系、运动绑定、动作绑定、对象交互和生成计算能力。
✔️ 对组合文本到视频生成进行首次系统研究,并提出基准 T2V-CompBench。
✔️ 通过精心设计的指标评估组合性的各个方面,涵盖 7 个类别和 700 个文本提示。
✔️ 提出专为组合 T2V 生成而设计的评估指标,并通过人工评估进行验证:基于 MLLM 的评估指标、基于检测的评估指标和基于跟踪的评估指标。
✔️ 对 20 个文本到视频生成模型进行基准测试和分析,强调当前模型的组合文本到视频生成的重大挑战,旨在指导未来的研究。
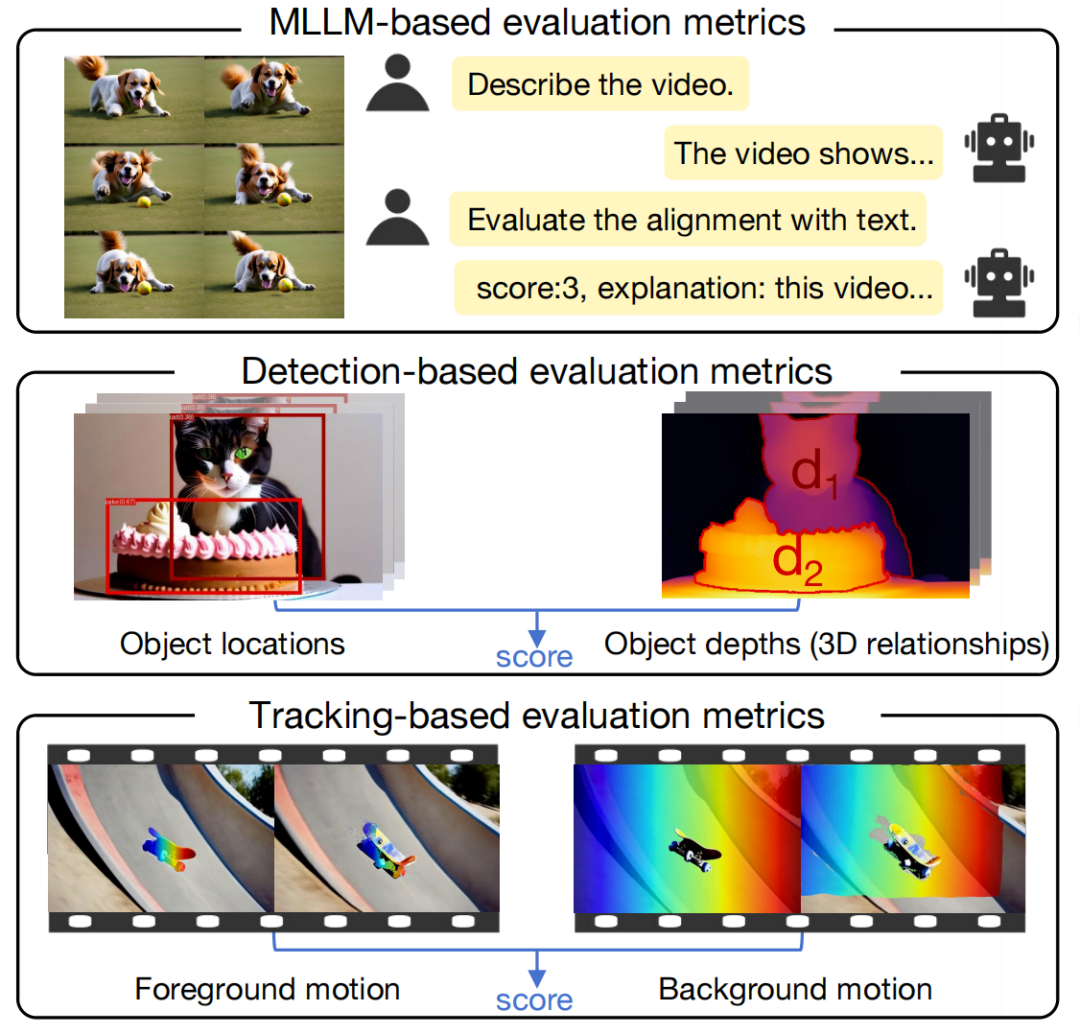
如上图所示,分别为:
1)基于 MLLM 的评估指标,用于一致和动态的属性绑定、操作绑定和对象交互。
2)基于检测的空间关系和对象交互的评估指标。
3)基于跟踪的运动绑定评估指标。
论文和项目地址:
https://t2v-compbench.github.io/
https://arxiv.org/pdf/2407.14505
https://github.com/KaiyueSun98/T2V-CompBench
以上就是今天分享的最新成果,如果对大家有帮助,希望能帮忙点赞转发一波,感谢各位小伙伴!!!
推荐
微信交流群现已有2000+从业人员交流群,欢迎进群交流学习(nvshenj125)
请备注:方向+姓名+学校/公司名称!一定要根据格式申请,拉你进群。

B站最新成果demo分享地址:https://space.bilibili.com/288489574
顶会工作整理Github repo:https://github.com/DWCTOD/CVPR2023-Papers-with-Code-Demo

















 3588
3588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









