









1、时序图
IOC容器的依赖注入是建立在数据BeanDefinition准备好的前提之下的。依赖注入的发生有两种情况:系统第一次向容器索要bean的时候;bean在配置的时候设置了Lazy-init属性,该属性会让容器完成预实例化,预实例化就是一个依赖注入的过程。Bean的依赖注入看下DefaultListableBeanFactory的基类AbstractBeanFactory的getBean里面的实现来看下bean依赖注入的全流程。IOC依赖注入的时序图如下所示:
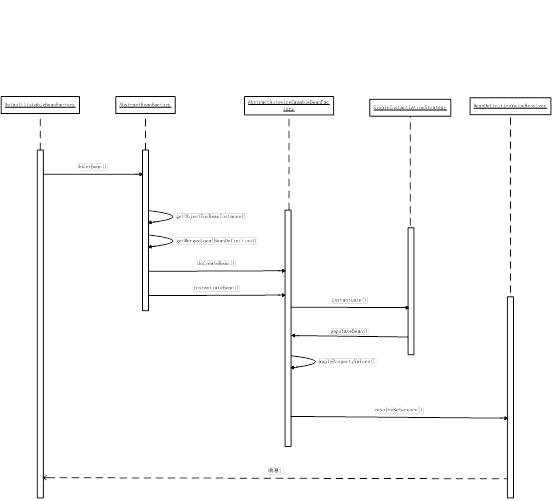
图10、spring ioc容器bean注入时序图
在时序图中可以看到依赖注入主要有两个阶段:instantiate即bean的实例化;populateBean即对bean所依赖的引用以及属性进行初始化。
2、instantiate
<pre name="code" class="java">public Object instantiate(RootBeanDefinition beanDefinition, String beanName, BeanFactory owner) {
// Don't override the class with CGLIB if no overrides.
if (beanDefinition.getMethodOverrides().isEmpty()) {
Constructor<?> constructorToUse;
synchronized (beanDefinition.constructorArgumentLock) {
constructorToUse = (Constructor<?>) beanDefinition.resolvedConstructorOrFactoryMethod;
if (constructorToUse == null) {
final Class clazz = beanDefinition.getBeanClass();
if (clazz.isInterface()) {
throw new BeanInstantiationException(clazz, "Specified class is an interface");
}
try {
if (System.getSecurityManager() != null) {
constructorToUse = AccessController.doPrivileged(new PrivilegedExceptionAction<Constructor>() {
public Constructor run() throws Exception {
return clazz.getDeclaredConstructor((Class[]) null);
}
});
}
else {
constructorToUse = clazz.getDeclaredConstructor((Class[]) null);
}
beanDefinition.resolvedConstructorOrFactoryMethod = constructorToUse;
}
catch (Exception ex) {
throw new BeanInstantiationException(clazz, "No default constructor found", ex);
}
}
}
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// Must generate CGLIB subclass.
return instantiateWithMethodInjection(beanDefinition, beanName, owner);
}
}代码层次比较清晰,beanDefinition是从之前载入的BeanDefinition中获取的根节点数据,一种是使用BeanUtils进行实例化,其实就是反射机制进行实例化,找出类的构造函数,再使用构造函数ctor.newInstance(args)实例化一个对象。另外一种就是使用CGLIB进行实例化,CGLIB构造一个实例的基本实现流程如下:
public Object instantiate(Constructor ctor, Object[] args) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(this.beanDefinition.getBeanClass());
enhancer.setCallbackFilter(new CallbackFilterImpl());
enhancer.setCallbacks(new Callback[] {
NoOp.INSTANCE,
new LookupOverrideMethodInterceptor(),
new ReplaceOverrideMethodInterceptor()
});
return (ctor == null) ?
enhancer.create() :
enhancer.create(ctor.getParameterTypes(), args);
}
首先生成一个Enhancer对象,在使用enhancer对基类、回调方法进行设置,最后使用cglib的create生成一个bean对象。这里简单阐述一下反射进行实例化的一个流程。
ClassInstance ci05 = null;
//额外的思考 在第二种类实例化的方式中有没有一种方法实现有参数的构造方式
//获得类的构造信息
Constructor[] ctor = Class.forName("ClassInstance").getDeclaredConstructors();
//找到我们需要的构造方法
for(int i=0;i<ctor.length;i++ ){
Class[] cl = ctor[i].getParameterTypes();
if(cl.length == 1){
//实例化对象
ci05 = (ClassInstance) Class.forName("ClassInstance").getConstructor(cl).newInstance(new Object[]{"05"});
}
}
ci05.fun();基本流程就是上述。类实例化都是在jvm里面进行的,所以实例化的步骤是如下的:
1、 类加载到jvm;
2、 Jvm对类进行链接;
3、 Jvm实例化对象。
上述代码流程里面Class.forName("ClassInstance")这个的作用就是前两步功能;第三步就是ctor. newInstance(args),这样就是完成了一个类实例化的过程,一般我们在系统里面new关键字就已经将上述三个步骤全部涵盖了。
在Spring IOC实例化的过程中还有一个地方需要注意的:
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
final String beanName = transformedBeanName(name);
Object bean;
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
if (logger.isDebugEnabled()) {
if (isSingletonCurrentlyInCreation(beanName)) {
logger.debug("Returning eagerly cached instance of singleton bean '" + beanName +
"' that is not fully initialized yet - a consequence of a circular reference");
}
else {
logger.debug("Returning cached instance of singleton bean '" + beanName + "'");
}
}
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
else {
....
}
值得注意的地方就是if (sharedInstance != null && args == null) 这段代码的判断是看这个bean是从beanFactory里面获取(false)还是从factoryBean来生产(true)FactoryBean.getObject(),FactoryBean是一个工厂模式。Beanfactory是所有bean的出处,即使FactoryBean也是从Beanfactory来的,那么FactoryBean是做什么的呢?我们看下它类的继承关系就比较容易理解:
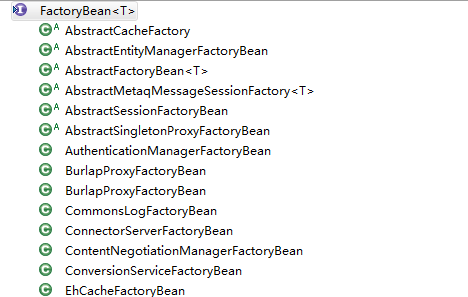
图11、FacotryBean的类关系图
也就是说FactoryBean其实是各类特定类型beanfactory的工厂,说起来有些拗口,其实就是里面出来的都是一个factory,例如RMI,JNDI,PROXY等等类型的factory。就可以由其生产。它的设计模式是一个工厂方法。
3、populateBean
populateBean就是bean相关属性以及依赖类的加载,这里会触发相关bean的依赖注入。
在这个过程中也有两个阶段,如下代码所示:List<PropertyValue> deepCopy = new ArrayList<PropertyValue>(original.size());
boolean resolveNecessary = false;
for (PropertyValue pv : original) {
if (pv.isConverted()) {
deepCopy.add(pv);
}
else {
String propertyName = pv.getName();
Object originalValue = pv.getValue();
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
Object convertedValue = resolvedValue;
boolean convertible = bw.isWritableProperty(propertyName) &&
!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
if (convertible) {
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}
// Possibly store converted value in merged bean definition,
// in order to avoid re-conversion for every created bean instance.
if (resolvedValue == originalValue) {
if (convertible) {
pv.setConvertedValue(convertedValue);
}
deepCopy.add(pv);
}
else if (convertible && originalValue instanceof TypedStringValue &&
!((TypedStringValue) originalValue).isDynamic() &&
!(convertedValue instanceof Collection || ObjectUtils.isArray(convertedValue))) {
pv.setConvertedValue(convertedValue);
deepCopy.add(pv);
}
else {
resolveNecessary = true;
deepCopy.add(new PropertyValue(pv, convertedValue));
}
}
}
if (mpvs != null && !resolveNecessary) {
mpvs.setConverted();
}
// Set our (possibly massaged) deep copy.
try {
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
第一个阶段就是resolveValueIfNecessary,这个就是将改类相关的依赖类找出来,这个有很多类型,list,set,map以及object等等,最终模式都是回归到resolveReference上来,这个功能就是最终使用beanFacotry.getBean()来完成bean的依赖实例化。
第二个阶段就是setPropertyValues,这个过程就是将bean的set和get方法读出来,将这些类set进去或是read出来。对于在xml中手动配置的bean ref这个比较容易理解,而对于系统自动依赖注入的方式这里简单介绍下:
Spring不但支持自己定义的@Autowired注解,还支持几个由JSR-250规范定义的注解,它们分别是@Resource、@PostConstruct以及@PreDestroy。
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按 byName自动注入罢了。@Resource有两个属性是比较重要的,分是name和type,Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不指定name也不指定type属性,这时将通过反射机制使用byName自动注入策略。
@Resource装配顺序
1. 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
2. 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
3. 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
4. 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配;
@Autowired 与@Resource的区别:
1、 @Autowired与@Resource都可以用来装配bean. 都可以写在字段上,或写在setter方法上。
2、 @Autowired默认按类型装配(这个注解是属业spring的),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用,如下:
@Autowired()
@Qualifier("baseDao")
private BaseDaobaseDao;
3、@Resource(这个注解属于J2EE的),默认安装名称进行装配,名称可以通过name属性进行指定,如果没有指定name属性,当注解写在字段上时,默认取字段名进行安装名称查找,如果注解写在setter方法上默认取属性名进行装配。当找不到与名称匹配的bean时才按照类型进行装配。但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
@Resource(name="baseDao")
private BaseDao baseDao;
4、IOC依赖注入设计模式
在上面讲到FactoryBean采用的是工厂方法,我们在这里讲述下改设计模式:
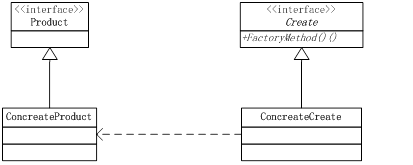
在FactoryBean的设计中Create就是FactoryBean,而ConcreateCreate就相当于HttpInvokerProxyFactoryBean,FactoryMethod就是getObject(),获取到的object其实就是一个产品,例如ProxyFactory,而这个proxyFacory就可以生产中各类的Proxy出来,这个ProxyFactory就相当于ConcreateProduct了。
工厂方法的优点:
首先,良好的封装性,代码结构清晰。一个对象创建是有条件约束的,如一个调用者需要一个具体的产品对象,只要知道这个产品的类名(或约束字符串)就可以了,不用知道创建对象的艰辛过程,减少模块间的耦合。
其次,工厂方法模式的扩展性非常优秀。在增加产品类的情况下,只要适当地修改具体的工厂类或扩展一个工厂类,就可以完成“拥抱变化”。
再次,屏蔽产品类。这一特点非常重要,产品类的实现如何变化,调用者都不需要关心,它只需要关心产品的接口,只要接口保持不表,系统中的上层模块就不要发生变化,因为产品类的实例化工作是由工厂类负责,一个产品对象具体由哪一个产品生成是由工厂类决定的。在数据库开发中,大家应该能够深刻体会到工厂方法模式的好处:如果使用JDBC连接数据库,数据库从MySql切换到Oracle,需要改动地方就是切换一下驱动名称(前提条件是SQL语句是标准语句),其他的都不需要修改,这是工厂方法模式灵活性的一个直接案例。
最后,工厂方法模式是典型的解耦框架。高层模块值需要知道产品的抽象类,其他的实现类都不用关心,符合迪米特原则,我不需要的就不要去交流;也符合依赖倒转原则,只依赖产品类的抽象;当然也符合里氏替换原则,使用产品子类替换产品父类。















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









