







相信大家都知道撸啊撸这个游戏了吧,小时候偷偷跑去网吧和朋友们开黑的日子,那是我们逝去的青春。

学了爬虫课后终于按捺不住了,决定自己手动编写爬虫程序,就把自己用Python编程爬取五黑游戏英雄壁纸和英雄信息的过程整理了出来进行投稿,与大家一起分享,爬取了当前比较火的游戏壁纸,《开黑游戏》,这里展示爬取《hero》的过程,学会了这个,自己再去爬取其他游戏壁纸也就不成问题啦。好了下面进入正题

先看一下最终的效果,每个英雄的壁纸(包括炫彩皮肤)和想要的信息都被爬取下来了:
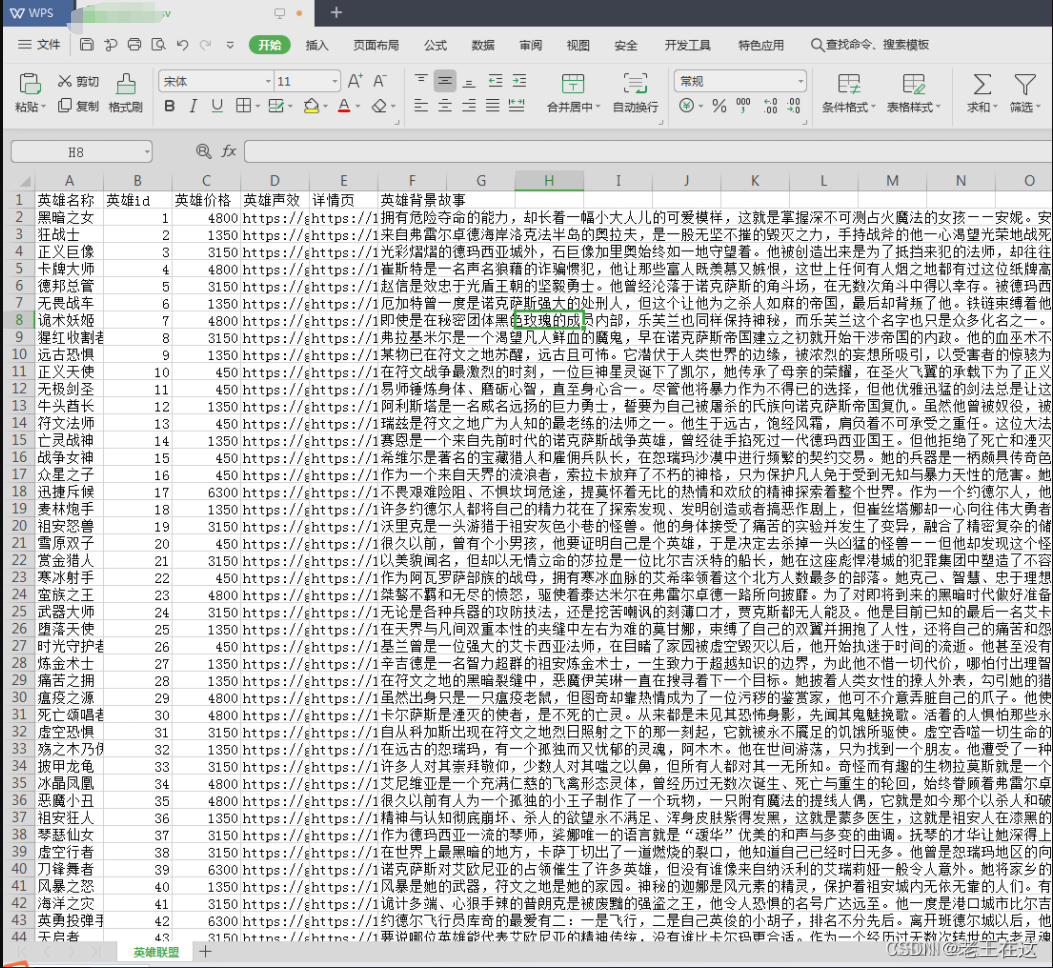
下面开始正式教学!
版本:Python 3.8
工具:pycharm
了解爬取对象,设计爬取流程
在使用爬虫前,先花一定时间对爬取对象进行了解,是非常有必要的,这样可以帮助我们科学合理地设计爬取流程,以避开爬取难点,节约时间。
1.1英雄基本信息
打开网址,看到游戏的信息:
若要爬取全部英雄,我们先要获取这些英雄的信息,在网页上“右击——检查——XHR”,就能在看到英雄的信息了,如下图所示,包括英雄昵称、英雄名称、英文名等等。由于这些信息是使用JavaScript动态加载的,普通爬取方法无法获取,我们只能用Ajax的方法来获取这些信息。
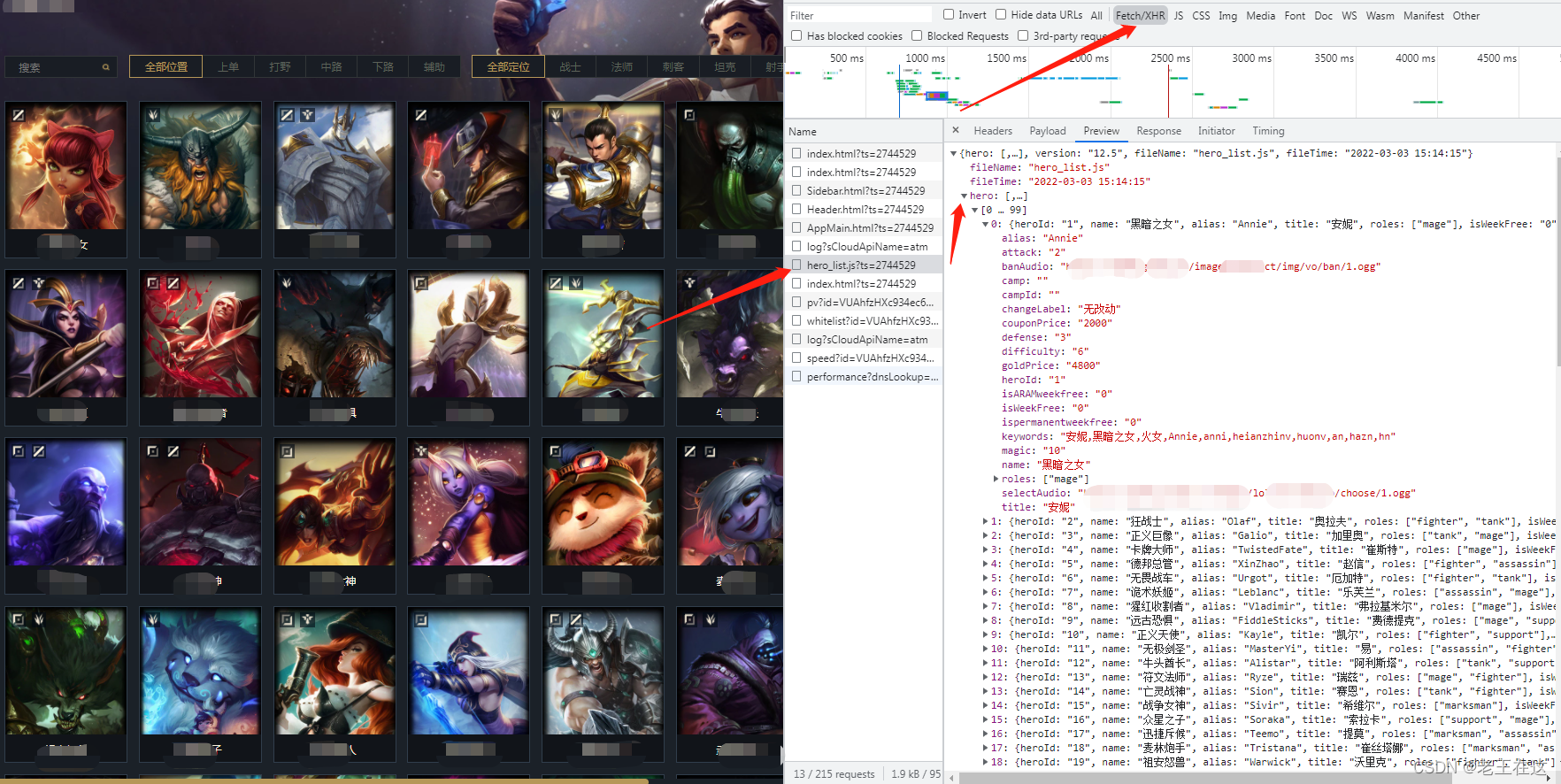
我们进入英雄的详情页来分析看看,我们发现进入英雄详情页后上面网址链接里的heroid会变化你把这个1换成其他数字网址会跳到其他英雄的详情页,这代表着这是英雄的ID,进入详情页会有一个ts?=2743的请求,打开后发现这是请求英雄皮肤或者英雄信息的,那么我们展开skins发现要的东西都在这里。
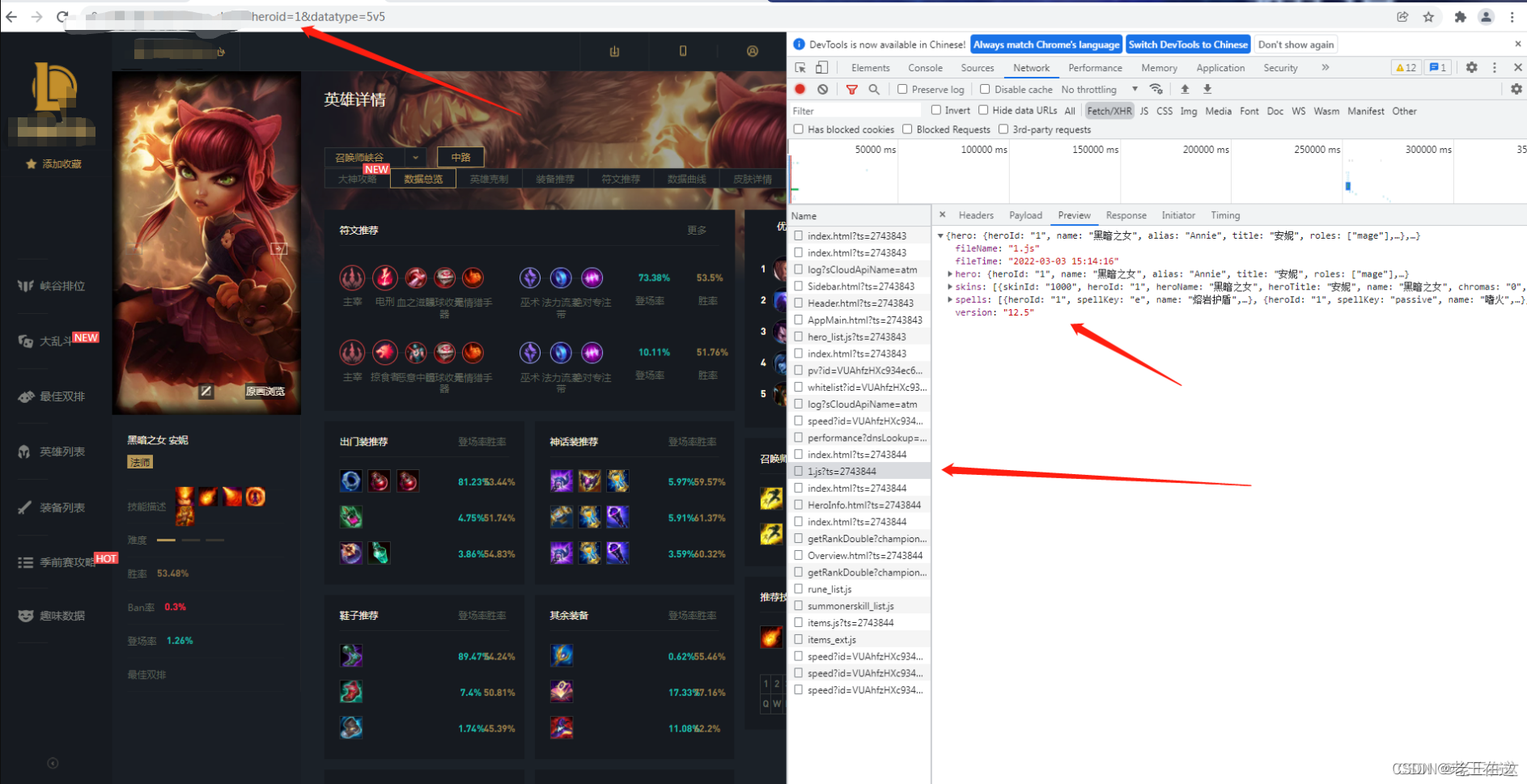
思路分析:
既然我们已经知道了hero的信息在哪里了,那么我们接下来就可以对详情页外面全部英雄header里面的这条URL发起请求获取它的json数据来个循环拿到需要英雄的信息和hero的ID再通过heroid和详情页的URL进行拼接不就可以进入详情页里面再下载皮肤或者取我们还需要的信息莫。

开始工作:
下面我们对网页发送请求,因为网页是动态的所以返回的是json数据
请求成功之后我们就进入到hero,循环列表就能提取我们所需要的信息了,这里我提取了英雄的名称,英雄的id,英雄的价格,英雄的选择声效,这里说一下英雄的ID后面要用到。

有了英雄id之后,接下来我们就可以进入到英雄详情页拿这个请求里面的URL和英雄的id进行拼接 然后发送请求进入详情页提取我们的皮肤链接和英雄的其他信息等…
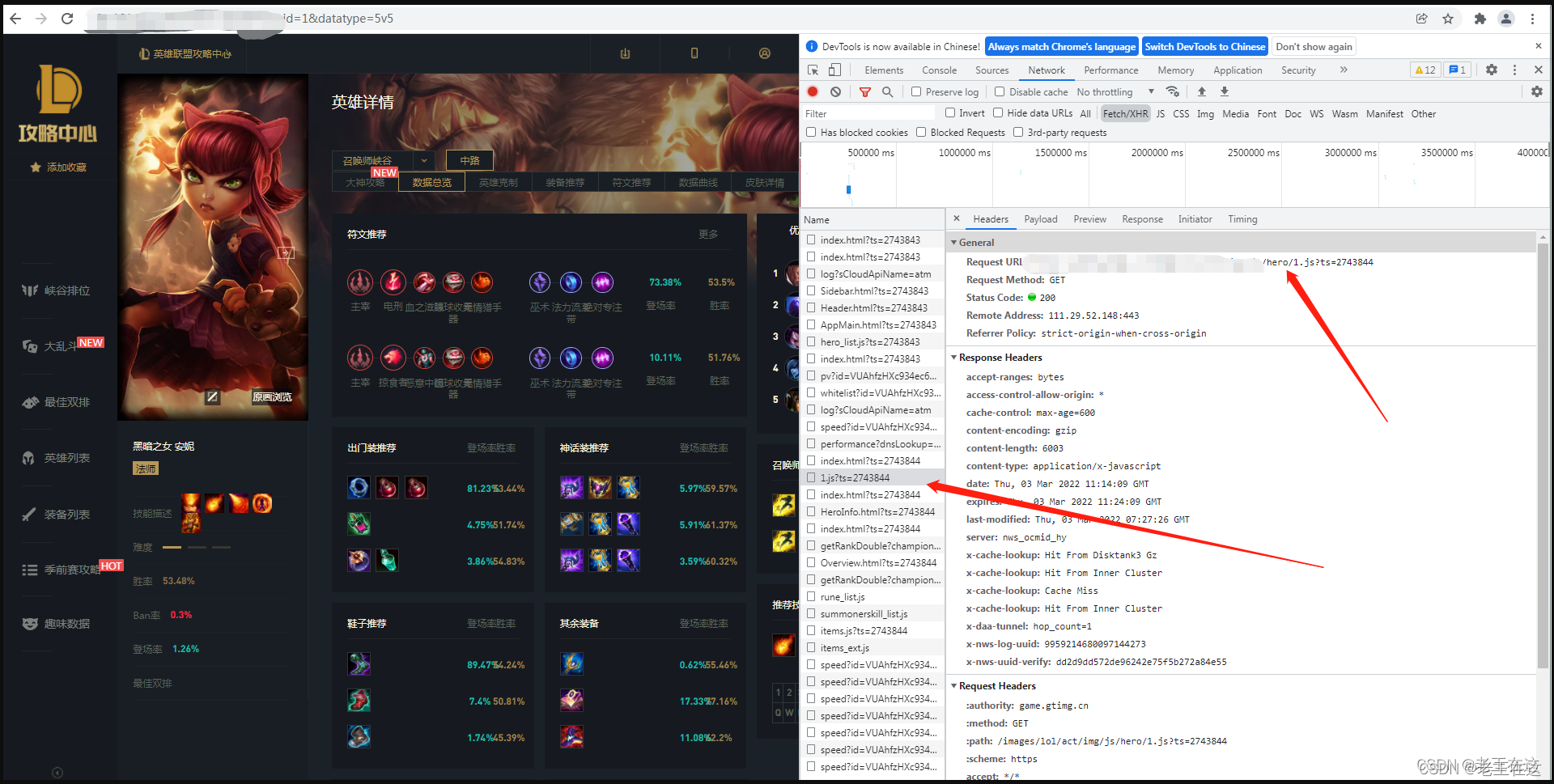
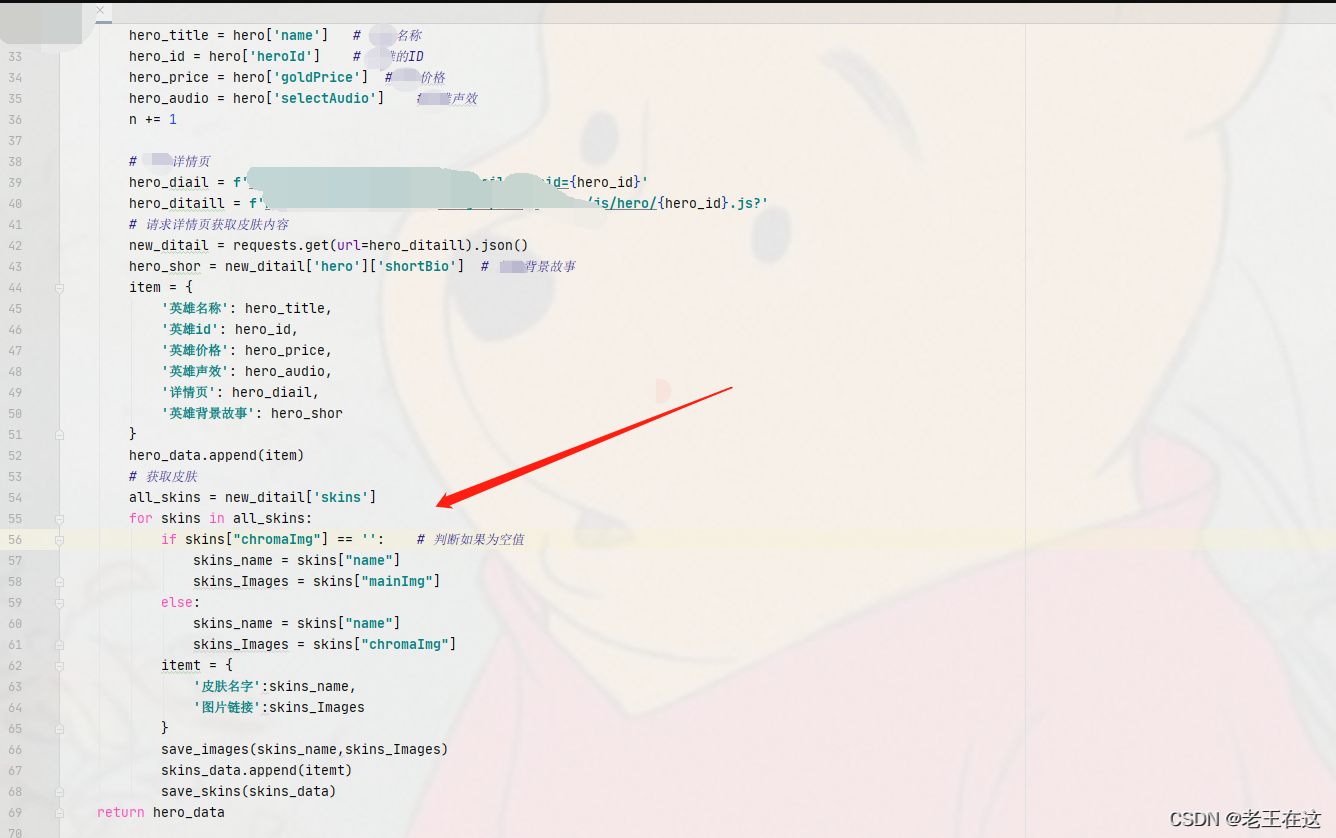
拼接URL后就发起一个请求遍历提取英雄的皮肤,这里创建了一个item字典来储存我们获取下来的hero信息,另一个itemt字典来储存我们获取下来的英雄皮肤信息最后再嵌套到列表里。
这里要注意一下
从网页英雄皮肤的数据知道想要提取炫彩的皮肤就得加个判断,只有进行判读才能把hero全部皮肤包括(炫彩皮肤)一起下载到电脑。
完成到这里我们就离终点差不多了,想想拥有这么多图片就心动。

接下来就是把数据给保存到csv里,这里我写了两个csv,一个是保存hero英雄信息的,另一个是保存hero皮肤信息,
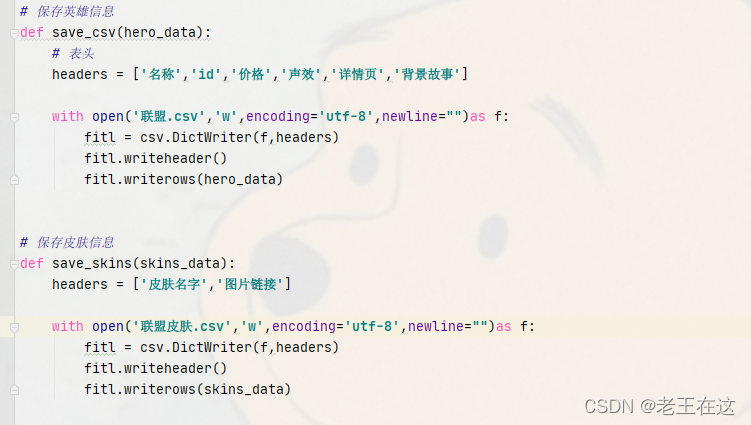
最后就是把hero皮肤图片发送请求创建文件夹给下载下来

实现
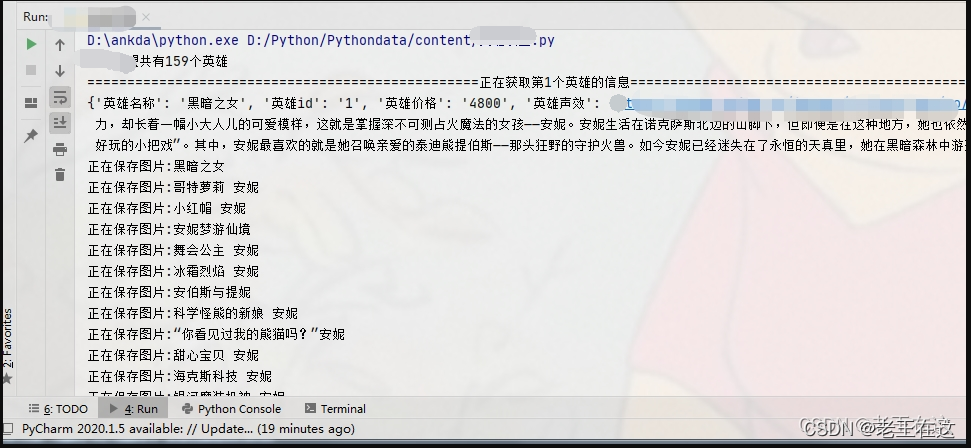
**到这里就大功告成啦!只要运行一下这个程序,所有hero的皮肤壁纸就都收入囊中了,运行代码时注意保持网络畅通,如果网速太慢可能会爬取失败。
以下是全部代码:
# @Author : 王同学
import requests
import json
import csv
import os.path
import re
import threading
from fake_useragent import UserAgent
ua = UserAgent() # 伪造头
def get_content(url):
headers = {'user-agent': ua.random,
'referer': 'https://101.qq.com/'}
try:
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
return response.json()
except:
print('NOD DATA')
def get_data(response):
hero_data = []
skins_data = []
n = 1
all_hero = response["hero"]
print(f'共有{len(all_hero)}个英雄') # 打印一下列表长度
for hero in all_hero: # 遍历这个列表里面的内容
print(f'=================================================正在获取第{n}个英雄的信息===========================================')
hero_title = hero['name'] # 名称
hero_id = hero['heroId'] # ID
hero_price = hero['goldPrice'] #价格
hero_audio = hero['selectAudio'] #声效
n += 1
# 详情页
hero_diail = f'https://101.qq.com/#/hero-detail?heroid={hero_id}'
hero_ditaill = f'https://game.gtimg.cn/images/lol/act/img/js/hero/{hero_id}.js?'
# 请求详情页获取皮肤内容
new_ditail = requests.get(url=hero_ditaill).json()
hero_shor = new_ditail['hero']['shortBio'] # 背景故事
item = {
'名称': hero_title,
'id': hero_id,
'价格': hero_price,
'声效': hero_audio,
'详情页': hero_diail,
'背景故事': hero_shor
}
print(item)
hero_data.append(item)
# 获取皮肤
all_skins = new_ditail['skins']
for skins in all_skins:
if skins["chromaImg"] == '': # 判断如果为空值,则跳过空值
skins_name = skins["name"]
skins_Images = skins["mainImg"]
itemt = {
'皮肤名字': skins_name,
'图片链接': skins_Images
}
save_images(skins_name, skins_Images)
skins_data.append(itemt)
continue # 继续往下
save_skins(skins_data)
return hero_data
# 保存hero信息
def save_csv(hero_data):
# 表头
headers = ['名称','id','价格','声效','详情页','背景故事']
with open('联盟.csv','w',encoding='utf-8',newline="")as f:
fitl = csv.DictWriter(f,headers)
fitl.writeheader()
fitl.writerows(hero_data)
# 保存皮肤信息
def save_skins(skins_data):
headers = ['皮肤名字','图片链接']
with open('皮肤.csv','w',encoding='utf-8',newline="")as f:
fitl = csv.DictWriter(f,headers)
fitl.writeheader()
fitl.writerows(skins_data)
# 保存皮肤
def save_images(skins_name,skins_Images):
if not os.path.exists("皮肤"):
os.mkdir("皮肤")
bug = '[/\<>|":?]' # 剔除特殊字符
new_title = re.sub(bug,"",skins_name)
images = requests.get(url=skins_Images).content
with open("皮肤\\" + new_title + ".jpg",mode="wb")as f:
f.write(images)
print("正在保存图片:" + skins_name)
def main():
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?'
response = get_content(url)
hero_data = get_data(response)
save_csv(hero_data)
if __name__ == '__main__':
thred = threading.Thread(target=main)
thred.start()


















 3022
3022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











