







内容整理与黑马程序员阿伟和马哥教育王晓春老师
编译安装Redis
Redis的安装
Redis是基于C语言编写的,因此首先需要安装Redis所需要的gcc依赖:
Linux安装Redis步骤:
1.安装gcc依赖:
yum install -y gcc tcl
2.上传安装包并解压:
tar -xzf redis-6.2.6.tar.gz
3.编译安装,先进入到redis目录再编译安装
3.1 cd redis-6.2.6
3.2 make && make install # 可以指定自定义redis安装目录 make prefix=/apps/redis install
4.默认的安装路径是在 `/usr/local/bin`目录下:
该目录已经默认配置到环境变量,因此可以在任意目录下运行这些命令。
其中:
- redis-cli:是redis提供的命令行客户端
- redis-server:是redis的服务端启动脚本
- redis-sentinel:是redis的哨兵启动脚本
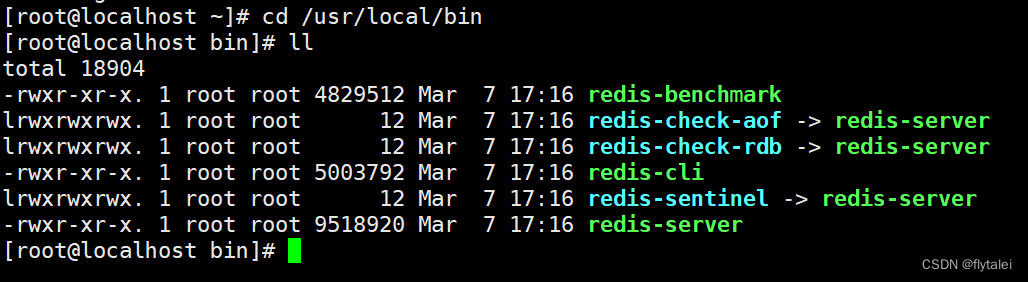
启动Redis
前台启动Redis
前台启动Redis
1.安装完成后,可以任意目录输入redis-server命令即可启动Redis
2.这种启动属于`前台启动`,会阻塞整个会话窗口,窗口关闭或者按下`Ctrk + C`则Redis停止。一般不推荐使用。
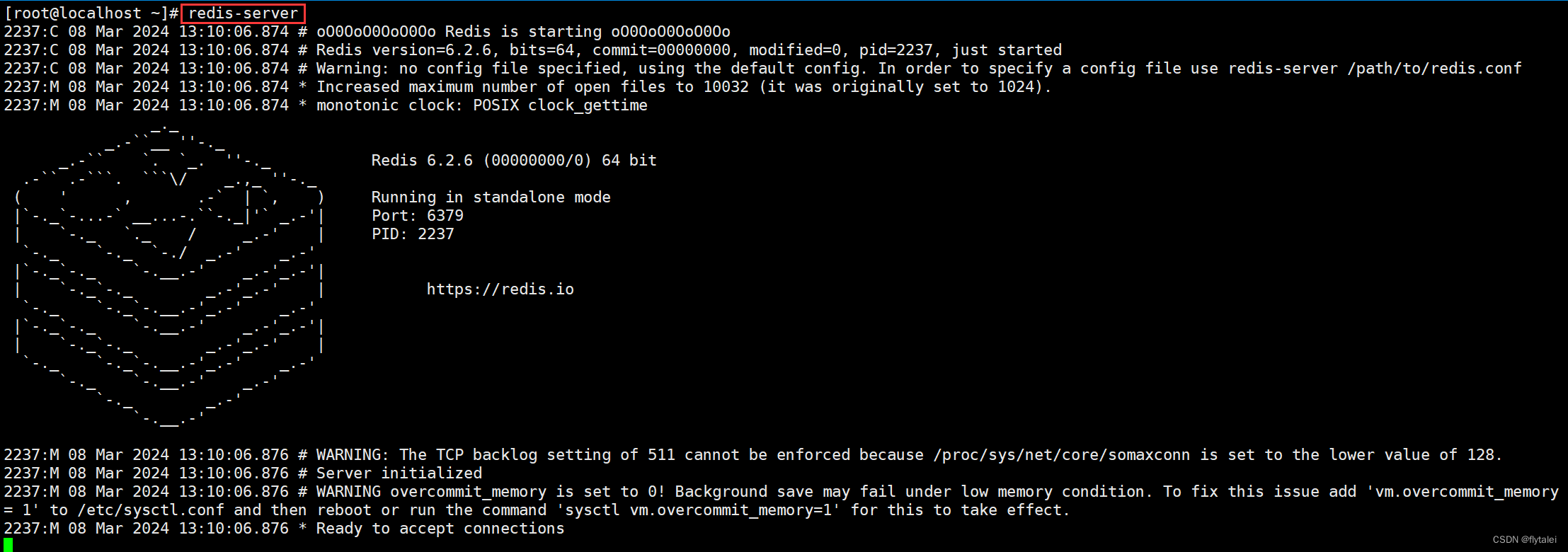
指定配置启动Redis
通过配置文件启动Redis也称`后台`方式启动
1.`后台`方式启动则必须修改Redis配置文件,就在我们之前解压的redis安装包下(`/usr/local/src/redis-6.2.6`),名字叫redis.conf:
2.修改bind
bind 0.0.0.0
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
3.修改守护进程
daemonize yes
# 守护进程,修改为yes后即可后台运行
4.修改密码
requirepass 123321
# 密码,设置后访问Redis必须输入密码
5.指定配置文件启动
# 进入redis安装目录
cd /usr/local/src/redis-6.2.6
# 启动
redis-server redis.conf
6.停止redis
redis-cli -u 123321 shutdown
# 利用redis-cli来执行 shutdown 命令,即可停止 Redis 服务,
# 因为之前配置了密码,因此需要通过 -u 来指定密码

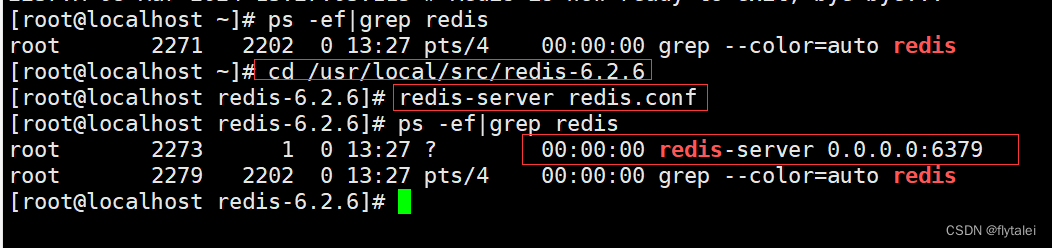
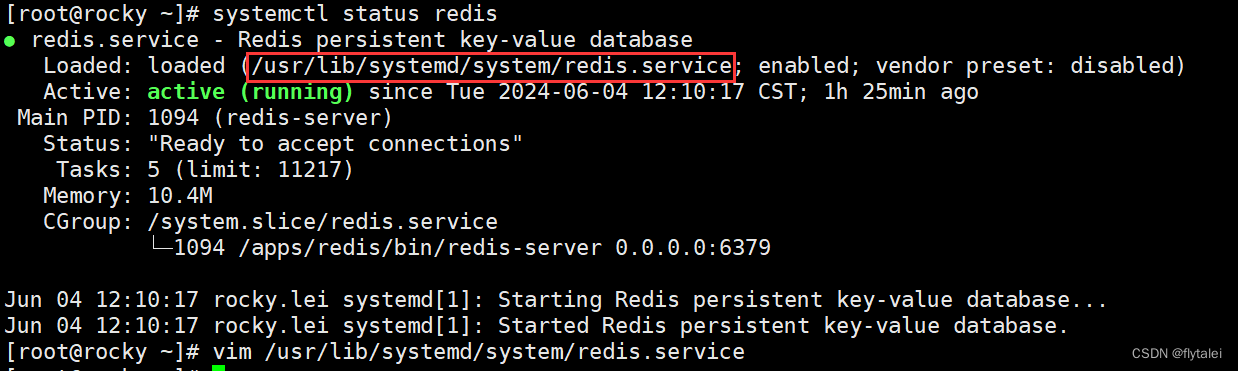
通过systemd开启自启
开机自启脚本
vim /etc/systemd/system/redis.service
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/src/redis-6.2.6/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
systemd启动命令
#以上开启自启脚本配置完后需要重载系统服务:
systemctl daemon-reload
# 启动
systemctl start redis
# 停止
systemctl stop redis
# 重启
systemctl restart redis
# 查看状态
systemctl status redis
#执行下面的命令,可以让redis开机自启:
systemctl enable redis

Redis客户端
安装完成Redis,我们就可以通过Redis客户端来操作Redis实现数据的CRUD了。
Redis客户端包括
- 命令行客户端
- 图形化桌面客户端
- 编程客户端
Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下:
redis-cli -h 10.0.0.212 -p 6379 -a 123321
- `-h 127.0.0.1`:指定要连接的redis节点的IP地址,默认是127.0.0.1
- `-p 6379`:指定要连接的redis节点的端口,默认是6379
- `-a 123321`:指定redis的访问密码
- `ping`:与redis服务端做心跳测试,服务端正常则会返回`pong`

脚本安装redis
脚本来自马哥教育王晓春老师
install_redis.sh
#!/bin/bash
#
#********************************************************************
#Author: wangxiaochun
#Date: 2020-07-22
#FileName: install_redis.sh
#URL: http://www.magedu.com
#Description: The test script
#Copyright (C): 2020 All rights reserved
#********************************************************************
REDIS_VERSION=redis-6.2.6
#REDIS_VERSION=redis-4.0.14
PASSWORD=123456
INSTALL_DIR=/apps/redis
CPUS=`lscpu |awk '/^CPU\(s\)/{print $2}'`
. /etc/os-release
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo -n "$1" && $MOVE_TO_COL
echo -n "["
if [ $2 = "success" -o $2 = "0" ] ;then
${SETCOLOR_SUCCESS}
echo -n $" OK "
elif [ $2 = "failure" -o $2 = "1" ] ;then
${SETCOLOR_FAILURE}
echo -n $"FAILED"
else
${SETCOLOR_WARNING}
echo -n $"WARNING"
fi
${SETCOLOR_NORMAL}
echo -n "]"
echo
}
prepare(){
if [ $ID = "centos" -o $ID = "rocky" ];then
yum -y install gcc make systemd-devel
else
apt update
apt -y install gcc make libjemalloc-dev libsystemd-dev
fi
if [ $? -eq 0 ];then
color "安装软件包成功" 0
else
color "安装软件包失败,请检查网络配置" 1
exit
fi
}
install() {
if [ ! -f ${REDIS_VERSION}.tar.gz ];then
wget http://download.redis.io/releases/${REDIS_VERSION}.tar.gz || { color "Redis 源码下载失败" 1 ; exit; }
fi
tar xf ${REDIS_VERSION}.tar.gz -C /usr/local/src
cd /usr/local/src/${REDIS_VERSION}
make -j $CUPS USE_SYSTEMD=yes PREFIX=${INSTALL_DIR} install && color "Redis 编译安装完成" 0 || { color "Redis 编译安装失败" 1 ;exit ; }
ln -s ${INSTALL_DIR}/bin/redis-* /usr/bin/
mkdir -p ${INSTALL_DIR}/{etc,log,data,run}
cp redis.conf ${INSTALL_DIR}/etc/
sed -i -e 's/bind 127.0.0.1/bind 0.0.0.0/' -e "/# requirepass/a requirepass $PASSWORD" -e "/^dir .*/c dir ${INSTALL_DIR}/data/" -e "/logfile .*/c logfile ${INSTALL_DIR}/log/redis-6379.log" -e "/^pidfile .*/c pidfile ${INSTALL_DIR}/run/redis_6379.pid" ${INSTALL_DIR}/etc/redis.conf
if id redis &> /dev/null ;then
color "Redis 用户已存在" 1
else
useradd -r -s /sbin/nologin redis
color "Redis 用户创建成功" 0
fi
chown -R redis.redis ${INSTALL_DIR}
cat >> /etc/sysctl.conf <<EOF
net.core.somaxconn = 1024
vm.overcommit_memory = 1
EOF
sysctl -p
if [ $ID = "centos" -o $ID = "rocky" ];then
echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.d/rc.local
chmod +x /etc/rc.d/rc.local
/etc/rc.d/rc.local
else
echo -e '#!/bin/bash\necho never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local
chmod +x /etc/rc.local
/etc/rc.local
fi
cat > /lib/systemd/system/redis.service <<EOF
[Unit]
Description=Redis persistent key-value database
After=network.target
[Service]
ExecStart=${INSTALL_DIR}/bin/redis-server ${INSTALL_DIR}/etc/redis.conf --supervised systemd
ExecStop=/bin/kill -s QUIT \$MAINPID
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
LimitNOFILE=1000000
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now redis &> /dev/null
if [ $? -eq 0 ];then
color "Redis 服务启动成功,Redis信息如下:" 0
else
color "Redis 启动失败" 1
exit
fi
sleep 2
redis-cli -a $PASSWORD INFO Server 2> /dev/null
}
prepare
install

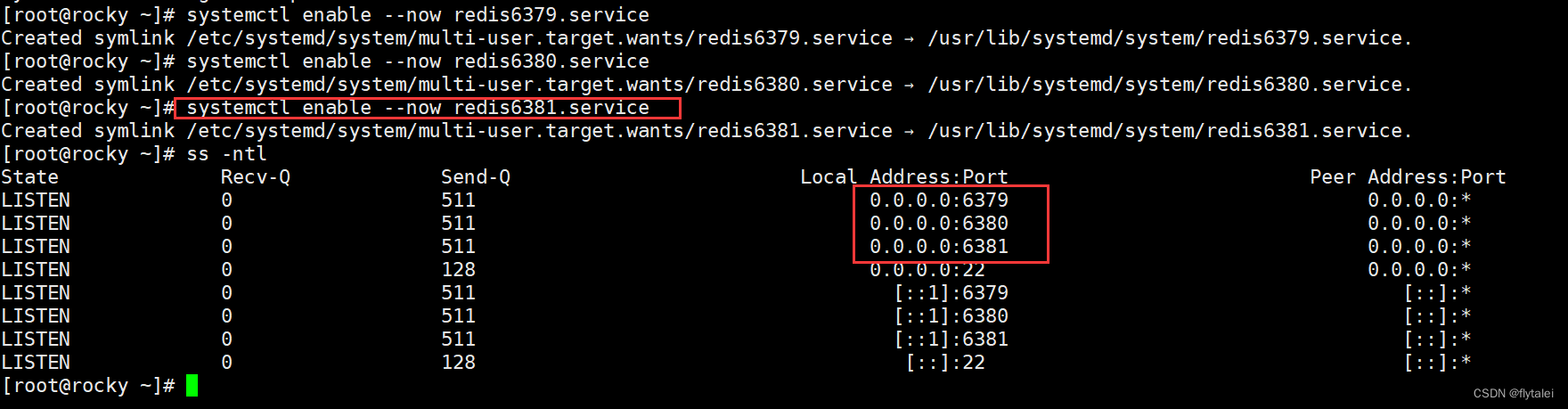
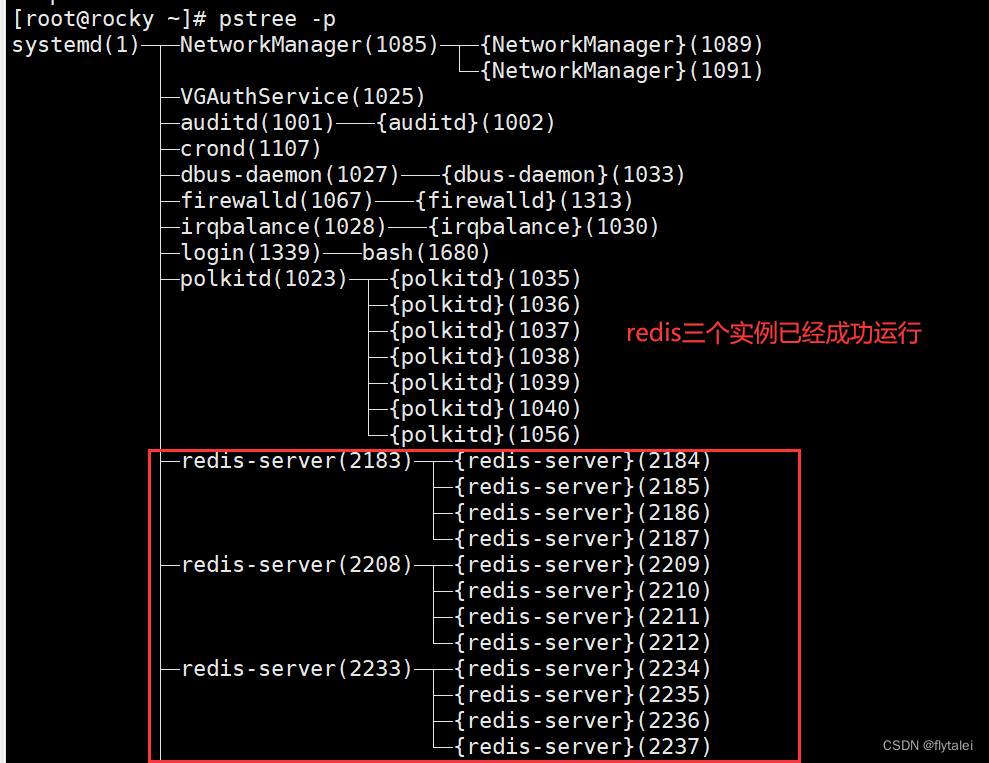
Redis多实例
测试环境中经常使用多实例,需要指定不同实例相对应的端口,配置文件,日志文件等配置。
复制redis.conf
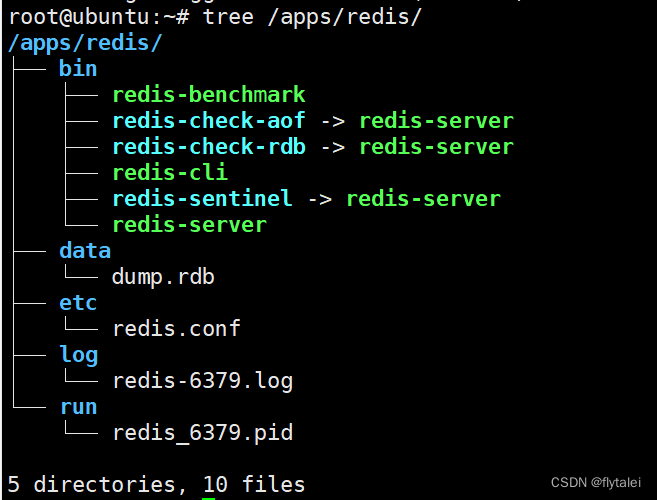
这里我们实现Redis三个实例的案例,将原来的配置文件等信息,一式三份为6379,6380,6381相关配置文件,原来的redis.conf配置文件中有关端口信息的关键字也得改,使用sed命令修改。
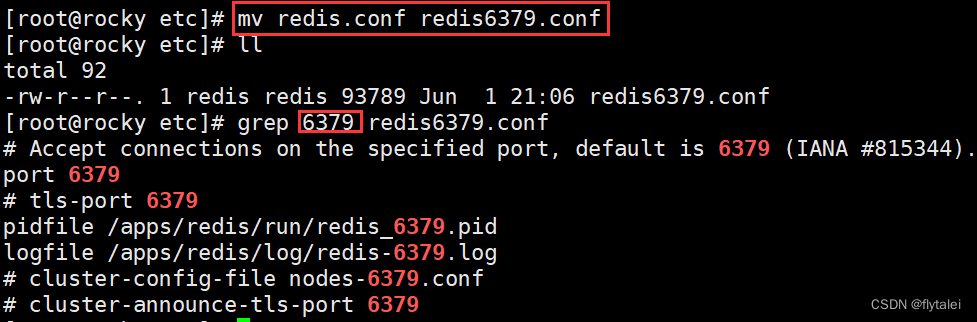
sed 's/6379/6380/' redis6379.conf > redis6380.conf
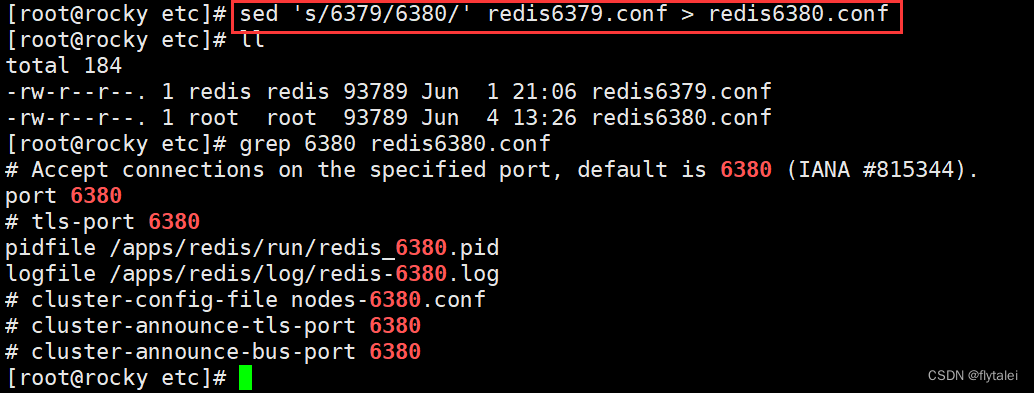
记得修改文件的属性

复制systemd启动文件
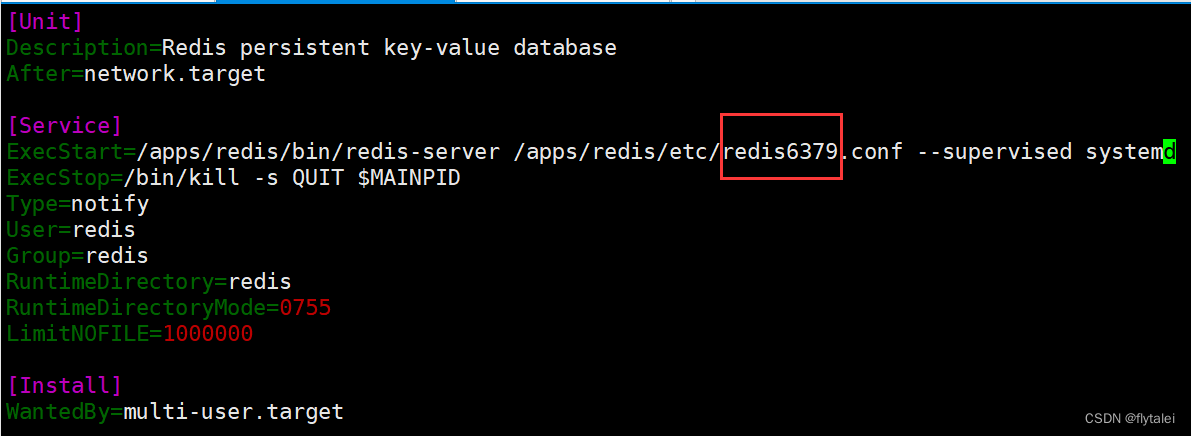
[Unit]
Description=Redis persistent key-value database
After=network.target
[Service]
ExecStart=/apps/redis/bin/redis-server /apps/redis/etc/redis6379.conf --supervised systemd
ExecStop=/bin/kill -s QUIT $MAINPID
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
LimitNOFILE=1000000
[Install]
WantedBy=multi-user.target
指定端口远程连接
redis-cli -h 192.168.10.151 -p 6381 -a 123456
如果报错No route to host则可能是远程主机上的防火墙的原因

关闭防护墙之后就能远程连接了


python客户端连接程序
[root@rocky etc]# python3
Python 3.6.8 (default, Apr 24 2024, 21:55:04)
[GCC 8.5.0 20210514 (Red Hat 8.5.0-22)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import redis
>>> r = redis.Redis(host='localhost', port=6379, db=0)
>>> r.set('student','bar')
True
>>> r.get('student')
b'bar'
>>> r.get('student')
b'lei'
>>>
Redis通用命令
通用指令是部分数据类型的,都可以使用的指令,常见的有:
INFO: 显示redis当前节点运行状态信息
SELECT: 切换数据库,相当于mysql的use tablename
KEYS: 查看当前库下的所有key,此命令慎用,相当于全表扫描,会引发重大生产事故
BGSAVE: 手动在后台执行RDB持久化操作
DBSIZE: 返回当前库下所有key数量
flushdb: 强制清空当前库中的所有key,此命令慎用,你想删库跑路?
flushall: 强制清空当前Redis服务器所有数据库中的所有key,删除所有数据,慎用啊!
可以在redis.conf文件中配置rename-command flushall ""; 使此命令失效。
shutdown: 关闭redis服务,停止所有客户端连接。
DEL: 删除一个指定的key
EXISTS: 判断key是否存在
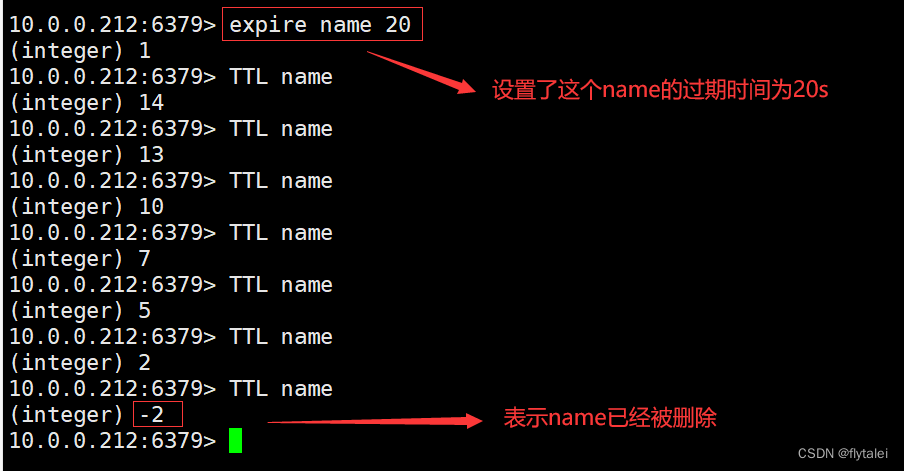
EXPIRE: 给一个key设置有效期,有效期之后该key会被自动删除
TTL: 查看一个KEY的剩余有效期
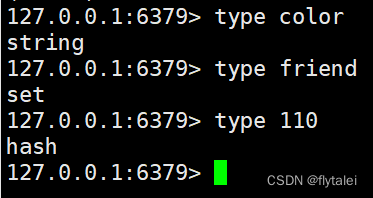
type key: 查看某个key是什么数据类型

通过help [command] 可以查看一个命令的具体用法,例如:

Redis五种数据类型
Redis是一个key-value的数据库,key一般是String类型,value的类型有很多,一般常用的有五种
1.String
2.Hash
3.List
4.Set
5.SortedSet

key的层级格式
Redis的key允许有多个单词形成层级结构,多个单词之间用':'隔开,格式如下:
项目名:业务名:类型:id
这个格式并非固定,也可以根据自己的需求来删除或添加词条。
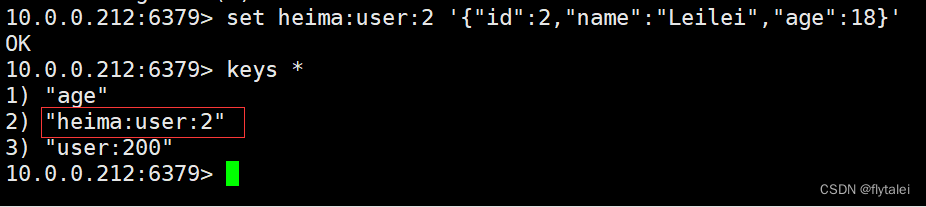
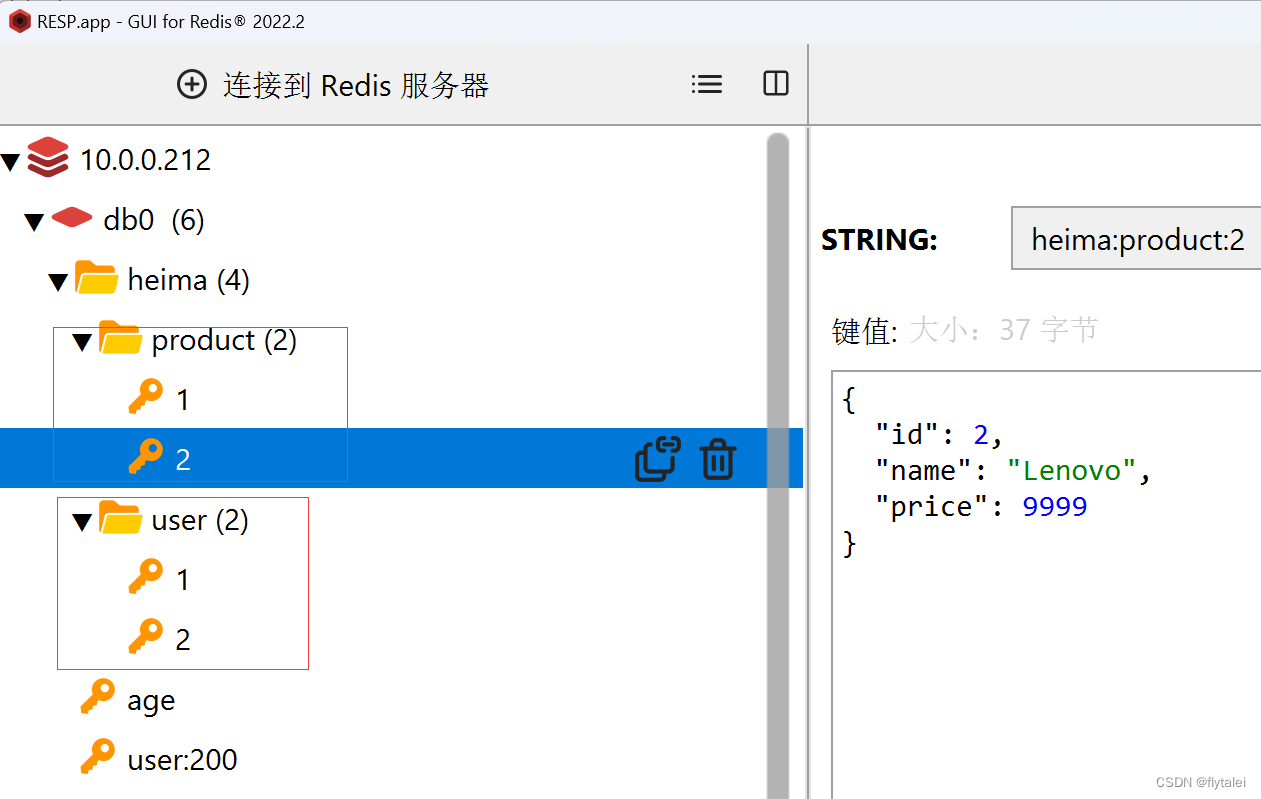
例如我们的项目名称叫 heima,有user和product两种不同类型的数据,我们可以这样定义key:
user相关的key:heima:user:1
product相关的key:heima:product:1
set heima:user:2 '{"id":2,"name":"Leilei","age":18}'
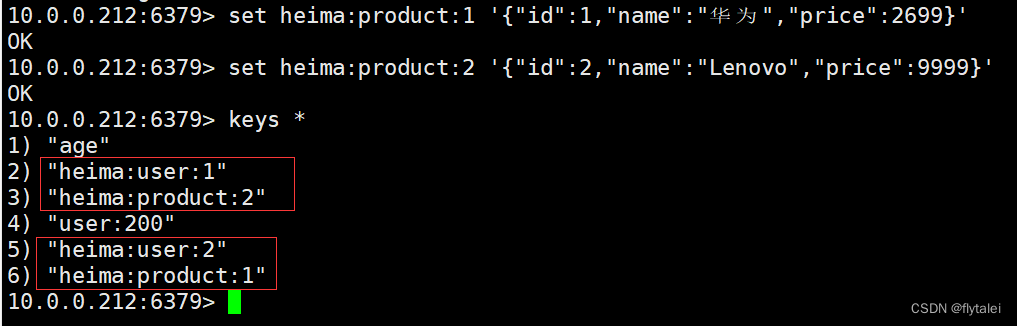
通过RESP图形化界面可以清楚的看见key的层级结构
String
String类型,也就是字符串类型,是Redis中最简单的存储类型。
String类型的value是字符串,不过根据字符串的格式不同,又可以分为3类:
1. string:普通字符串
2. int:整数类型,可以做自增、自减操作
3. float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。
字符串类型的最大空间不能超过512M.
String的常见命令有:
SET: 添加或者修改已经存在的一个String类型的键值对
GET: 根据key获取String类型的value
MSET: 批量添加多个String类型的键值对
MGET: 根据多个key获取多个String类型的value
INCR: 让一个整型的key自增1
INCRBY: 让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
INCRBYFLOAT: 让一个浮点类型的数字自增并指定步长
SETNX: 添加一个String类型的键值对,前提是这个key不存在,否则不执行
SETEX: 添加一个String类型的键值对,并且指定有效期

Hash
Hash类型,也叫散列,其value又是一个键值对,是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象的某个字段时很不方便:

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
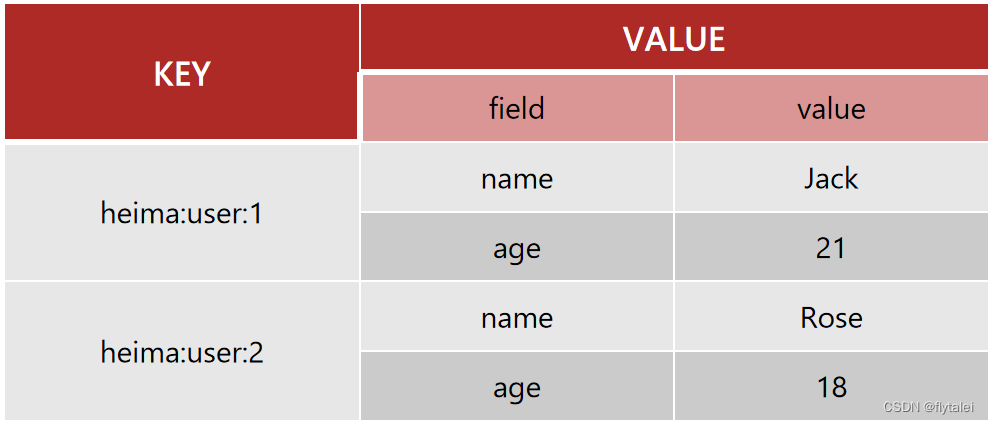
Hash的常见命令有:
HSET key field value: 添加或者修改hash类型key的field的值
HGET key field: 获取一个hash类型key的field的值
HMSET: 批量添加多个hash类型key的field的值
HMGET: 批量获取多个hash类型key的field的值
HGETALL: 获取一个hash类型的key中的所有的field和value
HKEYS: 获取一个hash类型的key中的所有的field
HVALS: 获取一个hash类型的key中的所有的value
HINCRBY: 让一个hash类型key的字段值自增并指定步长
HSETNX: 添加一个hash类型的key的field值,前提是这个field不存在,否则不执行

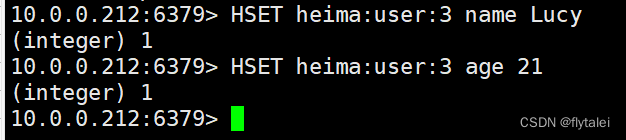
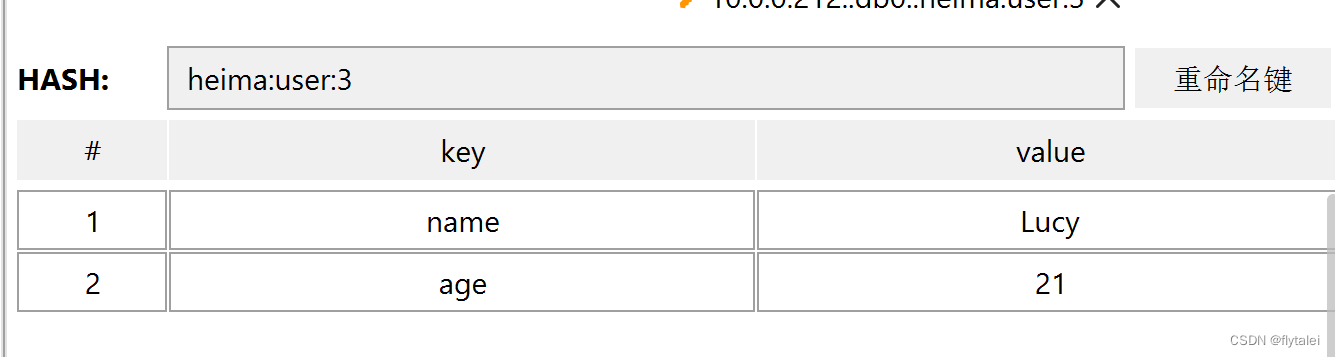
图形化界面表示为
List
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。
既可以支持正向检索和也可以支持反向检索。特征也与LinkedList类似:
1.有序
2.元素可以重复
3.插入和删除快
4.查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
List的常见命令有:
LPUSH key element ... : 向列表左侧插入一个或多个元素
LPOP key: 移除并返回列表左侧的第一个元素,没有则返回nil
RPUSH key element ... : 向列表右侧插入一个或多个元素
RPOP key: 移除并返回列表右侧的第一个元素
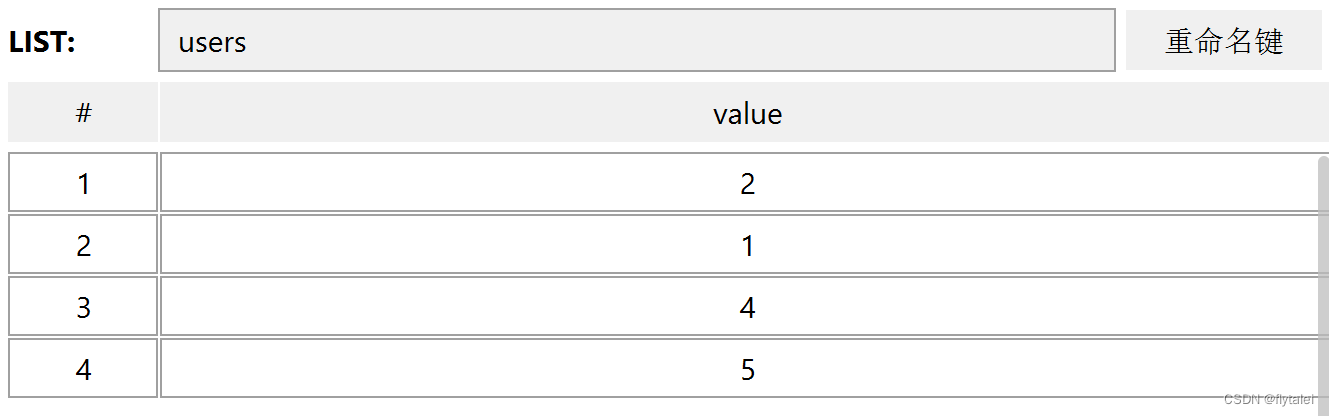
LRANGE key star end: 返回一段角标范围内的所有元素:lrange key 0 -1 取出所有数据
BLPOP和BRPOP: 与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil

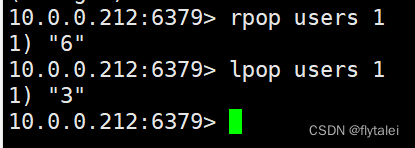
我LPUSH的是123;redis存储的却是321

lpop和rpop
Set
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。
因为也是一个hash表,因此具备与HashSet类似的特征:
1.无序
2.元素不可重复
3.查找快
4.集合间操作:支持交集、并集、差集等功能
Set的常见命令有:
SADD key member ... : 向set中添加一个或多个元素
SREM key member ... : 移除set中的指定元素
SCARD key: 返回set中元素的个数
SISMEMBER key member: 判断一个元素是否存在于set中
SMEMBERS: 获取set中的所有元素
SINTER key1 key2 ... : 求key1与key2的交集
SDIFF key1 key2 ... : 求key1与key2的差集
SUNION key1 key2 ..: 求key1和key2的并集
10.0.0.212:6379> sadd s1 a b c
(integer) 3
10.0.0.212:6379> smembers s1
1) "a"
2) "c"
3) "b"
10.0.0.212:6379> scard s1
(integer) 3
10.0.0.212:6379> srem s1 a
(integer) 1
10.0.0.212:6379> sismember s1 a
(integer) 0
10.0.0.212:6379> sismember s1 b
(integer) 1
10.0.0.212:6379>
Set命令的练习
将下列数据用Redis的Set集合来存储:
张三的好友有:李四、王五、赵六
李四的好友有:王五、麻子、二狗
10.0.0.212:6379> sadd zs lisi wangwu zhaoliu
(integer) 3
10.0.0.212:6379> sadd ls wangwu mazi ergou
(integer) 3
利用Set的命令实现下列功能:
计算张三的好友有几人
10.0.0.212:6379> scard zs
(integer) 3
计算张三和李四有哪些共同好友
10.0.0.212:6379> sinter zs ls
1) "wangwu"
查询哪些人是张三的好友却不是李四的好友
10.0.0.212:6379> sdiff zs ls
1) "lisi"
2) "zhaoliu"
查询张三和李四的好友总共有哪些人
10.0.0.212:6379> sunion zs ls
1) "wangwu"
2) "ergou"
3) "lisi"
4) "zhaoliu"
5) "mazi"
判断李四是否是张三的好友
10.0.0.212:6379> sismember zs lisi
(integer) 1
判断张三是否是李四的好友
10.0.0.212:6379> sismember lisi zs
(integer) 0
将李四从张三的好友列表中移除
10.0.0.212:6379> srem zs lisi
(integer) 1
SortedSet
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。
SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
1.可排序
2.元素不重复
3.查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令有:
ZADD key score member: 添加一个或多个元素到sorted set ,如果已经存在则更新其score值
ZREM key member: 删除sorted set中的一个指定元素
ZSCORE key member: 获取sorted set中的指定元素的score值
ZRANK key member: 获取sorted set 中的指定元素的排名
ZCARD key: 获取sorted set中的元素个数
ZCOUNT key min max: 统计score值在给定范围内的所有元素的个数
ZINCRBY key increment member: 让sorted set中的指定元素自增,步长为指定的increment值
ZRANGE key min max: 按照score排序后,获取指定排名范围内的元素
ZRANGEBYSCORE key min max: 按照score排序后,获取指定score范围内的元素
ZDIFF、ZINTER、ZUNION: 求差集、交集、并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可
SortedSet命令练习
将班级的下列学生得分存入Redis的SortedSet中:
Jack 85, Lucy 89, Rose 82, Tom 95, Jerry 78, Amy 92, Miles 76
10.0.0.212:6379> zadd stus 85 Jack 89 Lucy 82 Rose 95 Tom 78 Jerry 92 Amy 76 Miles
(integer) 7
并实现下列功能:
1.删除Tom同学
10.0.0.212:6379> zrem stus Tom
(integer) 1
2.获取Amy同学的分数
10.0.0.212:6379> zscore stus Amy
"92"
3.获取Rose同学的排名
10.0.0.212:6379> zrank stus Rose
(integer) 2 # zset排序从0开始
4.查询80分以下有几个学生
10.0.0.212:6379> zcount stus 0 80
(integer) 2
5.给Amy同学加2分
10.0.0.212:6379> zincrby stus 2 Amy
"94"
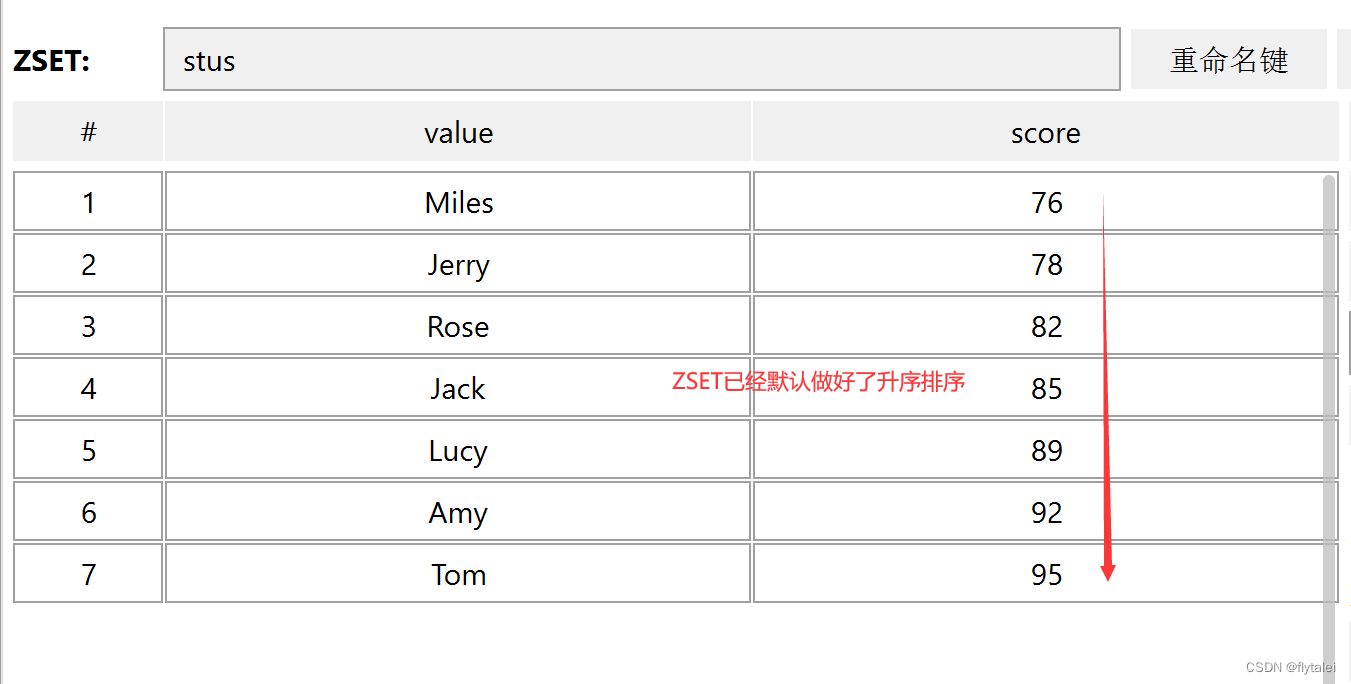
6.查出成绩前3名的同学
10.0.0.212:6379> zrange stus 0 2
1) "Miles"
2) "Jerry"
3) "Rose"
10.0.0.212:6379> zrevrange stus 0 2
1) "Amy"
2) "Lucy"
3) "Jack"
7.查出成绩80分以下的所有同学
10.0.0.212:6379> ZRANGEBYSCORE stus 0 80
1) "Miles"
2) "Jerry"
刷新登录状态
真实案例:登录过期Bug
登录状态过期
某日,官网后管的运营人员反馈说还在正常的操作着,系统忽然提示需要登录,这就是没有刷新登录状态的问题所在。
登录系统使用的memcached做缓存系统,当用户登录后,设置的是30分钟的过期时间,
因为没有刷新过期时间,所以导致了30分钟之后用户需要重新登录,这种体验非常的不好。
解决的思路:
1.已经登录的用户并且在访问该系统时,需要给他刷新过期时间
2.使用拦截器,当用户在正常访问系统时经过这个拦截器,拦截到他的请求后就刷新他的登录过期时间
刷新Token拦截器
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取请求头中的token
String token = request.getHeader("authorization");
if (StrUtil.isBlank(token)) {
return true;
}
// 2.基于TOKEN获取redis中的用户
String key = LOGIN_USER_KEY + token;
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(key);
// 3.判断用户是否存在
if (userMap.isEmpty()) {
return true;
}
// 5.将查询到的hash数据转为UserDTO
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
// 6.存在,保存用户信息到 ThreadLocal
UserHolder.saveUser(userDTO);
// 7.刷新token有效期
stringRedisTemplate.expire(key, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 移除用户
UserHolder.removeUser();
}
}
注册拦截器,且控制拦截器的执行顺序,order的数值越小优先级越高
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 登录拦截器
registry.addInterceptor(new LoginInterceptor())
.excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
).order(1);
// token刷新的拦截器
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate)).addPathPatterns("/**").order(0);
}
}
Redis代替Session需要考虑的问题
Redis代替Session需要考虑的问题
1.选择合适的数据结构
例如:验证码这样的数据比较加单就选择String类型
用户这种复杂对象可以使用Hash类型
2.选择合适的key
保证键的合理唯一性
设置key的过期时间,避免一个key一直存储占用内存空间
3.选择合适的存储粒度
缓存更新策略
什么是缓存
缓存是数据交换的缓冲器(Cache),是存储数据的临时地方,一般读写性能较高。
缓存的作用
1.降低后端负载
2.提高读写效率,降低响应时间
缓存的成本
1.数据一致性成本:如何保证缓存中的数据和数据库中的数据的一致性
2.代码维护成本:代码更复杂了
3.运维成本:需要维护集群
缓存更新策略
内存淘汰
1.不用自己维护,利用Redis的内存淘汰机制,当内存不足时自动淘汰部分数据。下次查询时更新缓存。
2.一致性差
3.没有维护成本
超时剔除
1.给缓存数据添加TTL时间,到期后自动删除缓存,下次查询时更新缓存。
2.一致性一般
3.维护成本低
主动更新
1.编写业务逻辑,在修改数据库的同时,更新缓存。自己手动实现。
2.一致性好
3.维护成本高
根据具体的业务场景选择合适的缓存更新策略
1.低一致性需求:使用内存淘汰机制,例如店铺类型的查询缓存。
2.高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存。
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id不能为空");
}
// 1.更新数据库
updateById(shop);
// 2.删除缓存
stringRedisTemplate.delete(CACHE_SHOP_KEY + id);
return Result.ok();
}
缓存穿透/雪崩/击穿
缓存穿透
缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会命中,这些请求会直接打到数据库上。
恶意请求会使用多线程并发去请求不存在的数据,从而搞垮数据库。
常见的解决方案
1.缓存空对象
优点:实现简单,维护方便。
缺点:额外的内存消耗,可能会造成短期的不一致。
注意:给空对象设置较短的TTL值,当TTL过期后会自动删除这个空对象,这样就不会占用太大的内存。
2.布隆过滤
优点:内存占用较少,没有多余key
缺点:实现复杂,存在误判可能
3.增强id的复杂度,避免被猜测到id规律
4.做好数据的基础格式校验
5.加强用户权限校验
6.做好热点参数的限流
缓存雪崩
缓存雪崩
缓存雪崩是指在同一时间段内大量缓存key同时失效或者Redis服务宕机,导致大量请求直接打到数据库,给数据库带来巨大压力。
解决方案
1.给不同的key的TTL添加随机值。
2.利用Redis集群提高服务的高可用性,Redis的哨兵机制。
3.给缓存业务添加降级限流策略。
4.给业务添加多级缓存。
缓存击穿
缓存击穿
缓存击穿问题也叫热点Key问题,就是一个被高并发访问的Key突然失效了,导致无数的请求会在瞬间给数据库带来巨大的冲击。
解决方案
1.互斥锁
2.逻辑过期

Redis持久化
Redis能有如此高的性能,归根结底还是因为Redis是基于内存的缓存系统,我们知道内存断电之后数据就会丢失,Redis需要使用持久化机制来保证消息不丢失。

使用python添加10万条测试数据
#!/usr/bin/python3
import redis
pool = redis.ConnectionPool(host="127.0.0.1",port=6379,password="123456",decode_responses=True)
r = redis.Redis(connection_pool=pool)
for i in range(100000):
r.set("k%d" % i,"v%d" % i)
data=r.get("k%d" % i)
print(data)

RDB
RDB:是基于某个时间点的数据快照,它只保留当前最新版本的快照。它的持久化功能所生成的是一个经过压缩的二进制RDB文件,通过该文件可以还原生成该RDB文件时的数据库状态。因为RDB文件是保存在磁盘中的,所以即便Redis服务进程挂掉甚至Redis服务器宕机,只要磁盘中的RDB文件还存在,就能将数据恢复。
RDB(Redis Database Backup file):Redis数据备份文件
1.RDB也被叫做Redis数据快照,简单来说就是把内存中的所有数据都保存到磁盘中。
2.当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
3.快照文件称为RDB文件,默认是保存在当前运行目录。
4.Redis默认就有RDB的机制,这个机制只有当你停机的时候才会触发。
5.如果Redis突然宕机,而又没有做持久化策略就会导致数据全部丢失,所以需要定期制作Redis持久化策略而不是依赖Redis默认的RDB机制。


自动执行bgsave
RDB的触发机制在redis.conf配置文件中
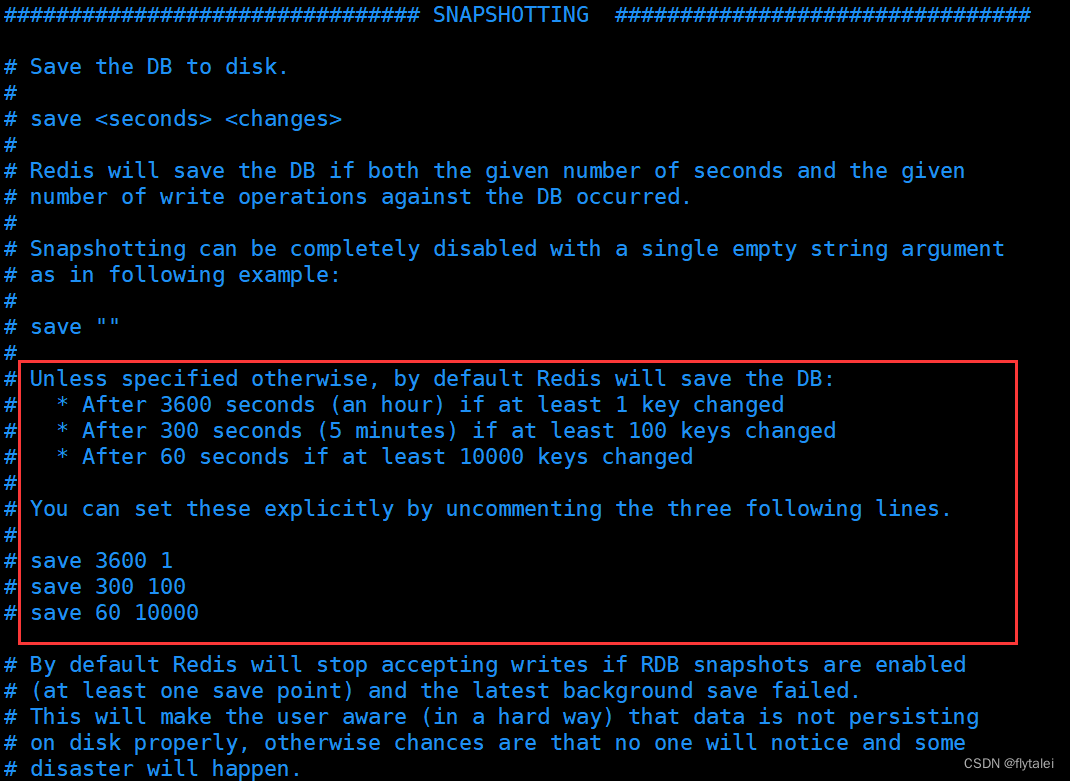
在配置文件中save选项可以设置多个保存条件,只要任意一个条件满足,服务器就会自动执行bgsave , 如果是save " " 则表示禁用RDB
save 900 1 #900秒内修改了10个key即触发保存RDB
save 300 10 #300秒内修改了10个key即触发保存RDB
save 60 10000 #60秒内修改了10000个key即触发RDB
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./

save和bgsave

save
save命令的特点
1.save同步执行命令,使用主进程完成快照;
2.save会阻塞其他命令的执行,如果数据量大,save命令会执行很久,导致其他命令的不能执行;
3.鉴于以上两点,生产中不推荐使用save命令。
redis-cli save&
pstree -p |grep redis ; ll /data/redis
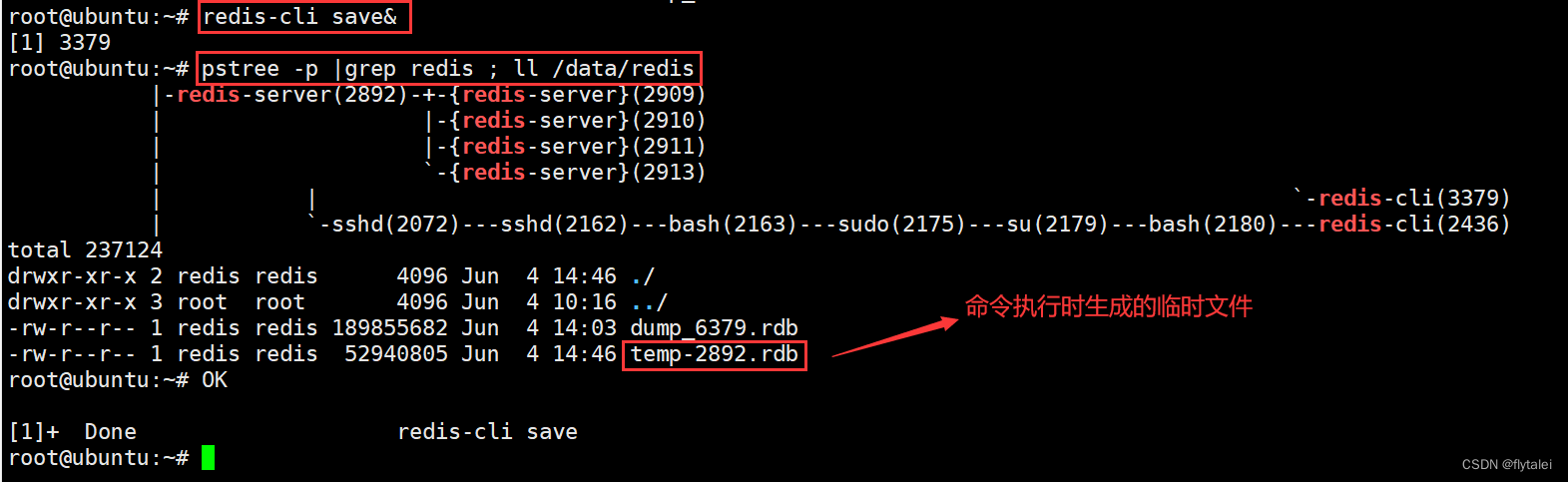
bgsave
bgsave的特点:
1.bgsave异步后台执行,会开启独立的子进程,所以不会阻塞其他命令的执行。
2.使用'rdb_bgsave_in_progress'参数可以判断bgsave是否执行完毕
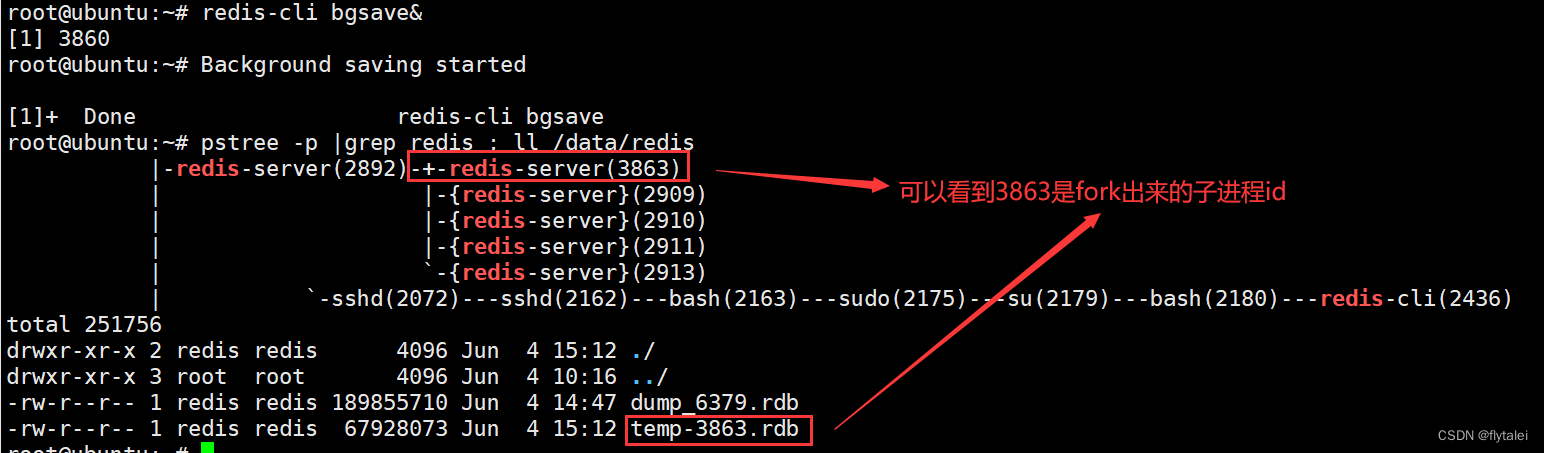
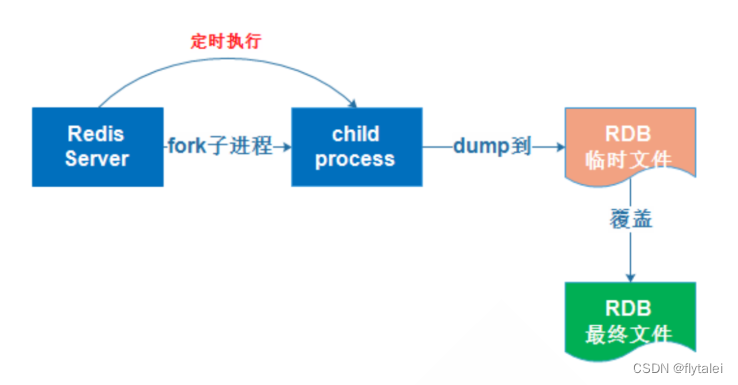
RDB方式bgsave的基本流程?
1.Redis主进程先fork一个新的子进程,子进程与主进程共享内存空间
2.子进程将Redis内存数据创建一个tmp-子进程pid.rdb的临时文件进行数据的保存操作;
3.子进程的临时文件完成数据的保存操作后,会将临时文件改名为最终的RDB文件。
3.用新RDB文件替换旧的RDB文件。
RDB会在什么时候执行?save 60 1000代表什么含义?
1.默认是服务停止时。
2.代表60秒内至少执行1000次修改则触发RDB

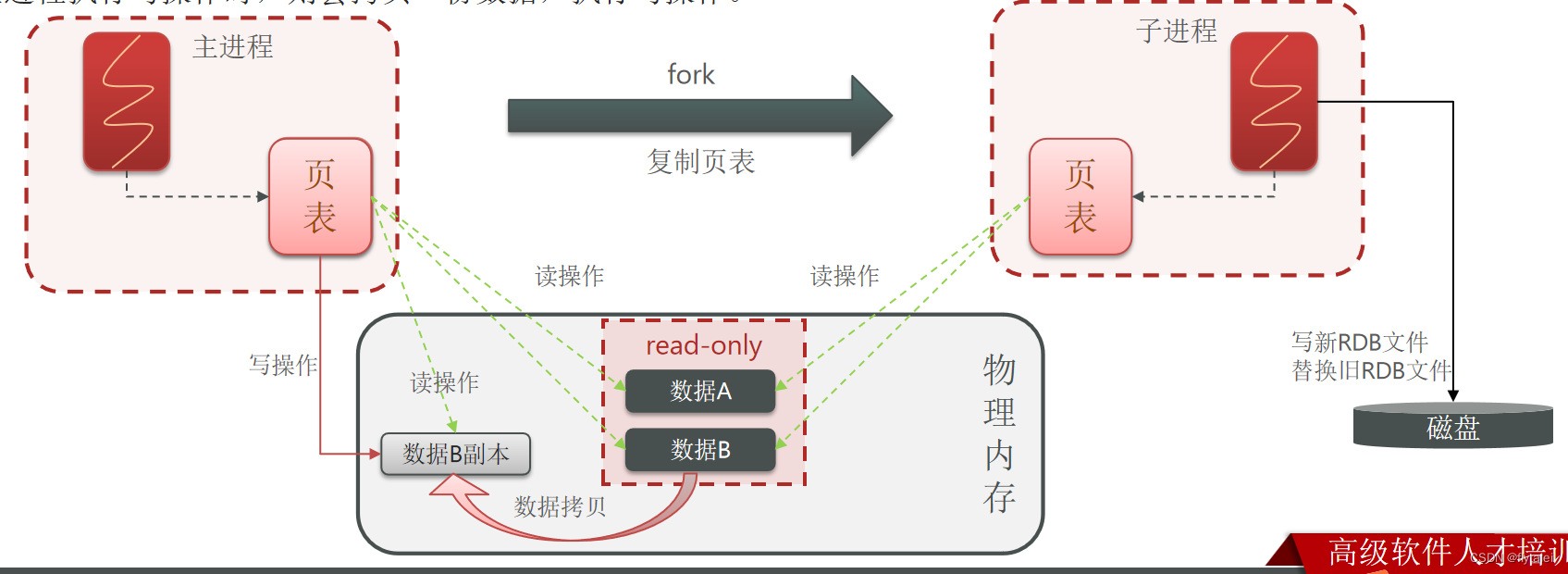
bgsave开始时会fork主进程得到子进程,由子进程来完成异步持久化,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件。
fork:译为派生、分支
1.Fork在计算机中是指创建一个新的进程,这个新的进程与原进程相同,但是它有自己的内存空间,可以独立运行。
2.Fork是Unix/Linux操作系统中的一个系统调用。Fork会复制原进程的所有内容,包括代码,数据和内存空间。这个过程称为"Copy-on-write"
3.Fork采用copy-one-write技术要点:
3.1.当主进程执行读操作时,访问共享内存;
3.2.当主进程执行写操作时,则会拷贝一份数据,执行写操作。
也就是说新进程只有在有写操作时,才会复制原进程的数据。
4.Fork的新进程可以修改自己的内存空间,而不影响原进程内存空间。
RDB的缺点
RDB的缺点?
1.RDB不能实时保存数据,执行间隔时间长,两次RDB之间写入数据有丢失的风险;
2.fork子进程、压缩、写出RDB文件都比较耗时
定期执行远程备份
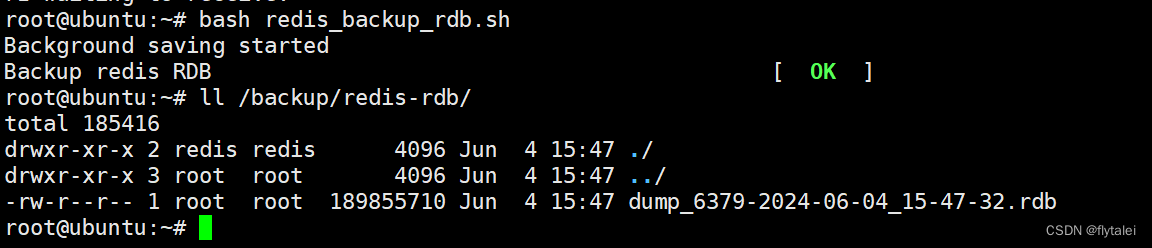
redis_backup_rdb.sh
脚本来自马哥教育王晓春老师
#!/bin/bash
#
#********************************************************************
#Author: wangxiaochun
#Date: 2020-10-21
#FileName: redis_rdb.sh
#URL: http://www.wangxiaochun.com
#Description: The test script
#Copyright (C): 2020 All rights reserved
#********************************************************************
BACKUP=/backup/redis-rdb
DIR=/data/redis
FILE=dump_6379.rdb
PASS=123456
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo -n "$1" && $MOVE_TO_COL
echo -n "["
if [ $2 = "success" -o $2 = "0" ] ;then
${SETCOLOR_SUCCESS}
echo -n $" OK "
elif [ $2 = "failure" -o $2 = "1" ] ;then
${SETCOLOR_FAILURE}
echo -n $"FAILED"
else
${SETCOLOR_WARNING}
echo -n $"WARNING"
fi
${SETCOLOR_NORMAL}
echo -n "]"
echo
}
redis-cli -h 127.0.0.1 -a $PASS --no-auth-warning bgsave
result=`redis-cli -a $PASS --no-auth-warning info Persistence |grep rdb_bgsave_in_progress| sed -rn 's/.*:([0-9]+).*/\1/p'`
until [ $result -eq 0 ] ;do
sleep 1
result=`redis-cli -a $PASS --no-auth-warning info Persistence |grep rdb_bgsave_in_progress| sed -rn 's/.*:([0-9]+).*/\1/p'`
done
DATE=`date +%F_%H-%M-%S`
[ -e $BACKUP ] || { mkdir -p $BACKUP ; chown -R redis.redis $BACKUP; }
cp $DIR/$FILE $BACKUP/dump_6379-${DATE}.rdb
color "Backup redis RDB" 0
AOF
AOF时时刻刻都在备份数据,它相当于完全备份+增量备份
AOF(Append Only File):追加文件
Redis处理的每一个写命令都会记录在AOF文件里,可以看做是命令日志文件
AOF时逐渐的累加追加记录操作命令,而RDB每次都是从头开始备份
AOF的配置

实验:我们修改appendonly为yes,然后重启redis服务
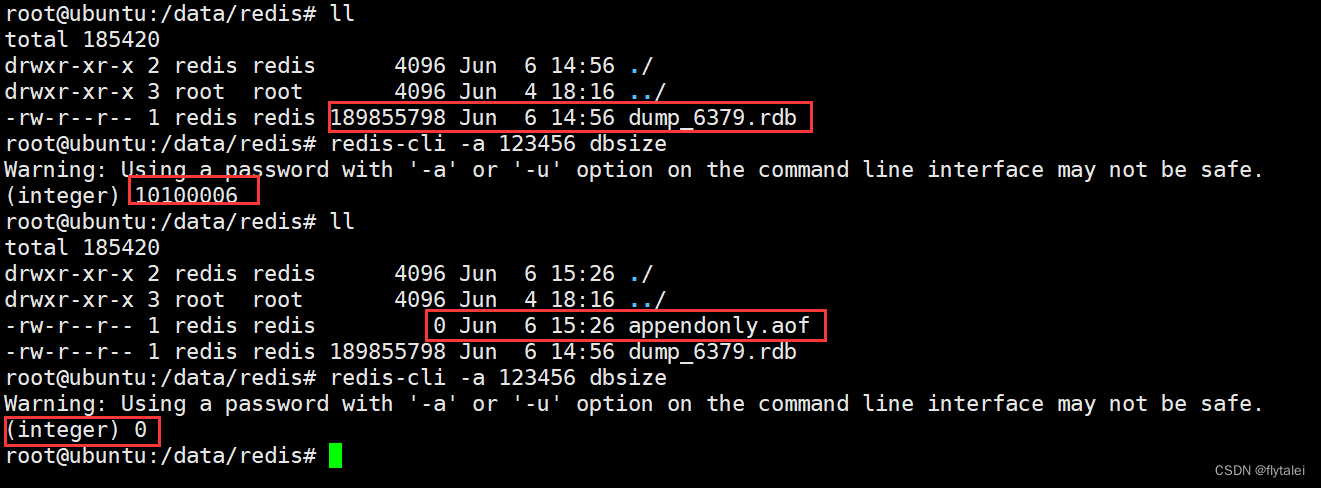
当我们重启了redis之后,appendonly.aof已经生成了,但aof的文件大小为0。此时我们在执行dbseze时,发现redis数据为0了,虽然rdb的文件任然有189M大小的数据,但此时系统并没有读取rdb文件。所以此时我们得出结论当aof和rdb同时存在时,aof的优先级更高,系统会优先读取aof文件。
打开AOF的保险方式
为了防止出现上面的数据为0的情况,我们可以使用config的方式来修改appendonly的状态,不要以修改配置文件后以重启服务的方式让配置生效。而是使用config命令修改等aof备份完了再去文件里修改配置为yes。

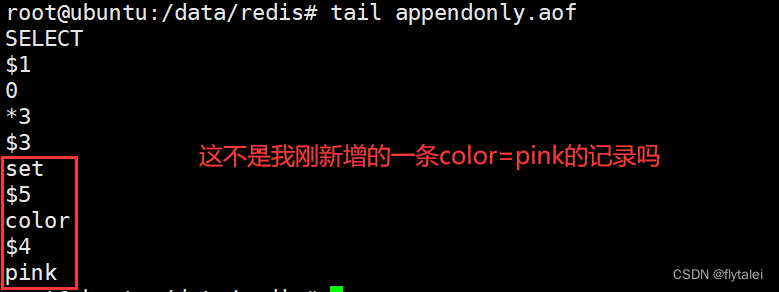
我们验证下,如上操作之后,新增一条key看是不是能保存到aof


AOF的相关配置
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilenane "appendonly.aof"
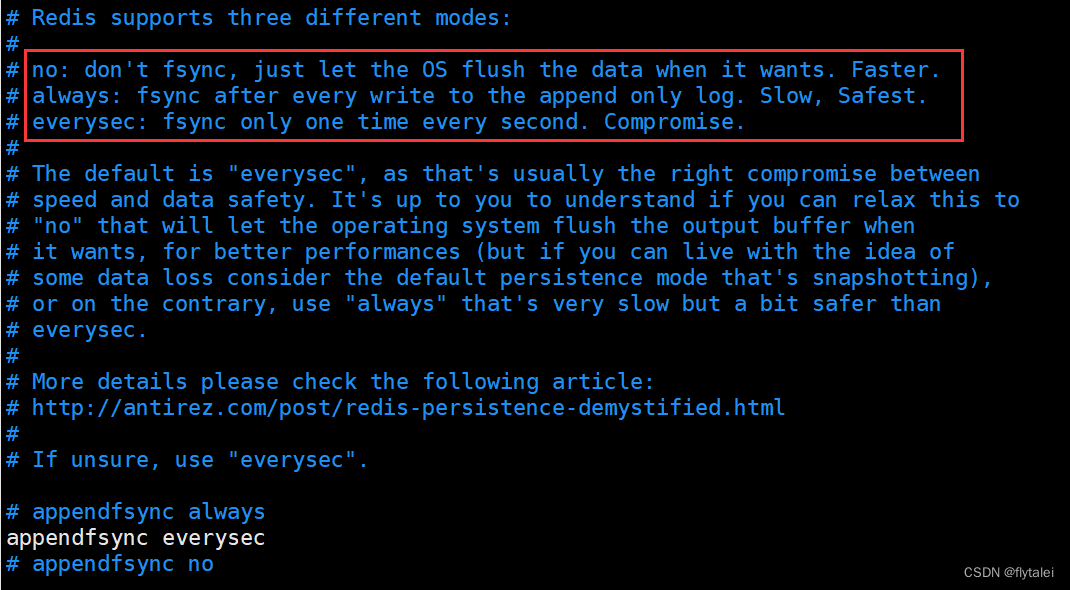
AOF的命令记录的频率也可以通过redis.conf文件俩配置:
appendfsync always # 表示每执行一次命令,立即记录到AOF文件
appendfsync everysec # 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案,也是生成建议值
appendfsync no # 写命令执行完先放入AOF缓存区,由操作系统决定何时将缓冲区内容写会磁盘

AOF并不是一个纯粹的二进制文件

AOF rewrite 重写
将一些重复的,可以合并的,过期的数据重新写入一个新的AOF文件,从而节约AOF备份占用的硬盘空间,也能加速恢复过程。可以手动执行“bgrewriteaof”触发AOF,
AOF rewrite 相关配置
no-appendfsync-on-rewrite no
#默认为no,表示“不暂缓”,新的aof记录仍然会被立即同步到磁盘,是最安全的方式,不会丢失数据,但是要忍受阻塞的问题
#yes,相当于appendfsync设置为no,说明没有执行磁盘操作,只是写入了缓冲区,因此这样并不会造成阻塞,
#但是如果这个时间redis挂掉,就会丢失数据,丢失多少数据呢?
#linux的默认fsync策略是30秒,最多会丢失30s的数据,当由于yes性能就好而且会避免出现阻塞,因此比较推荐。
auto-aof-rewrite-percentage 100
# 当aof log增长超过指定百分比例时,重写aof文件,设置为0表示不自动重写aof日志,
#重写是为了时aof体积保持最小,但是还可以确保保存最完整的数据
auto-aof-rewrite-min-size 64mb
# 触发aof rewarite的最小文件大小
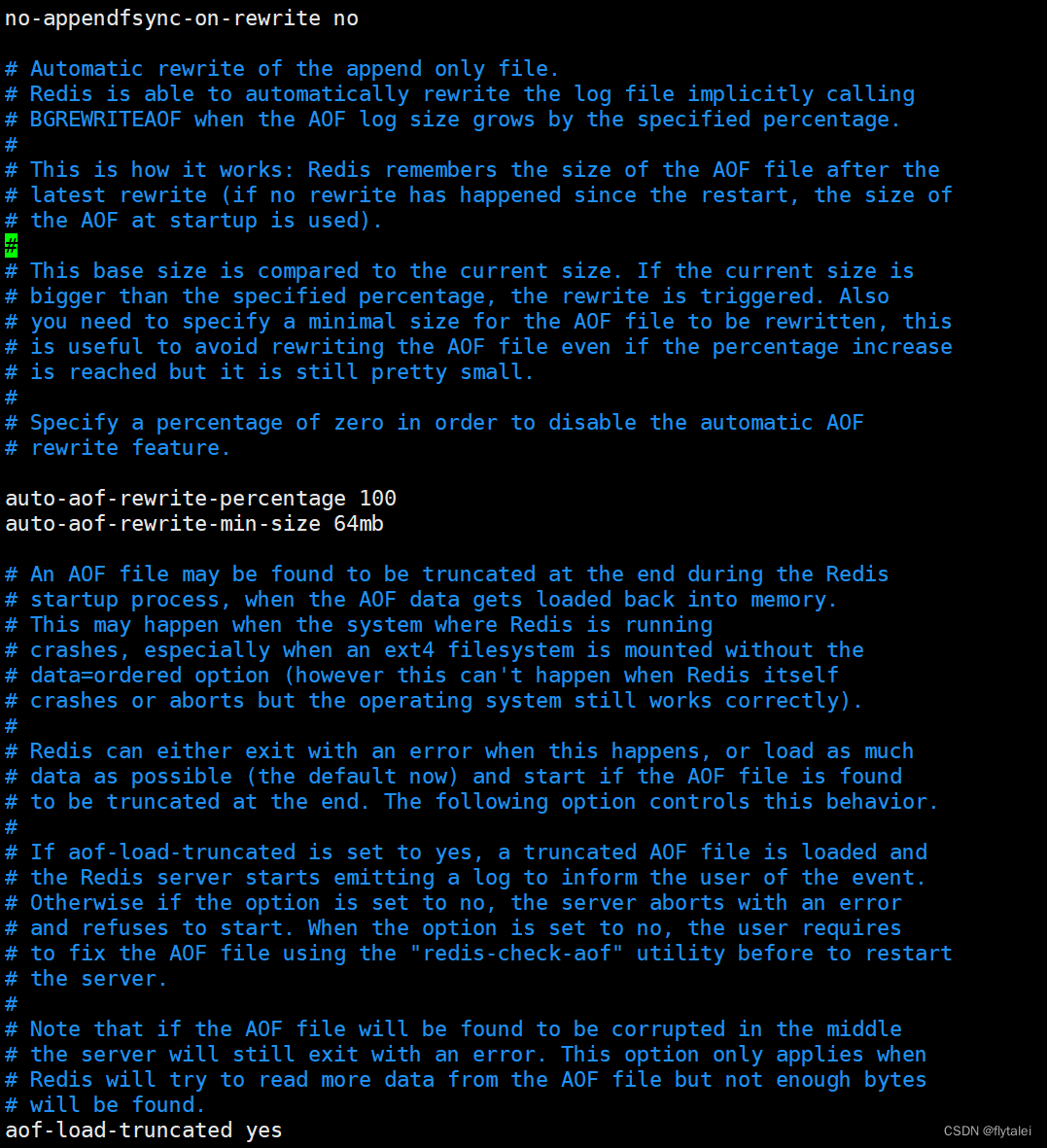
aof-load-truncated yes
#是否加载由于某些原因导致的末尾异常的AOF文件(主进程被kill/断电等),建议yes。
AOF的特点
0.AOF的优先级高于RDB
1.AOF因为是记录命令,所以AOF文件会比RDB文件大的多。
2.而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。
3.通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同的效果。
4.Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
5.AOF在恢复大数据集时的速度比RDB的恢复速度要慢
RDB和AOF的选择
1.如果redis数据主要充当缓存功能,允许有加长时间比如数分钟的数据丢失,可以只需启用RDB即可,RDB也是默认开启的;
2.如果redis数据一点都不能丢失,可以选择同时开启RDB和AOF;
3.一般不建议只开启AOF

Redis主从复制架构
Redis单机服务存在着数据和服务的单点故障问题,而且单机性能也存在上限,可以利用Redis主从复制等集群相关技术来解决问题。
主从复制特点
1.一个master可以有多个slave
2.一个slave只能有一个master
3.数据流向是从master到slave单向的
4.master可读可写
5.slave只读
主从复制的实现
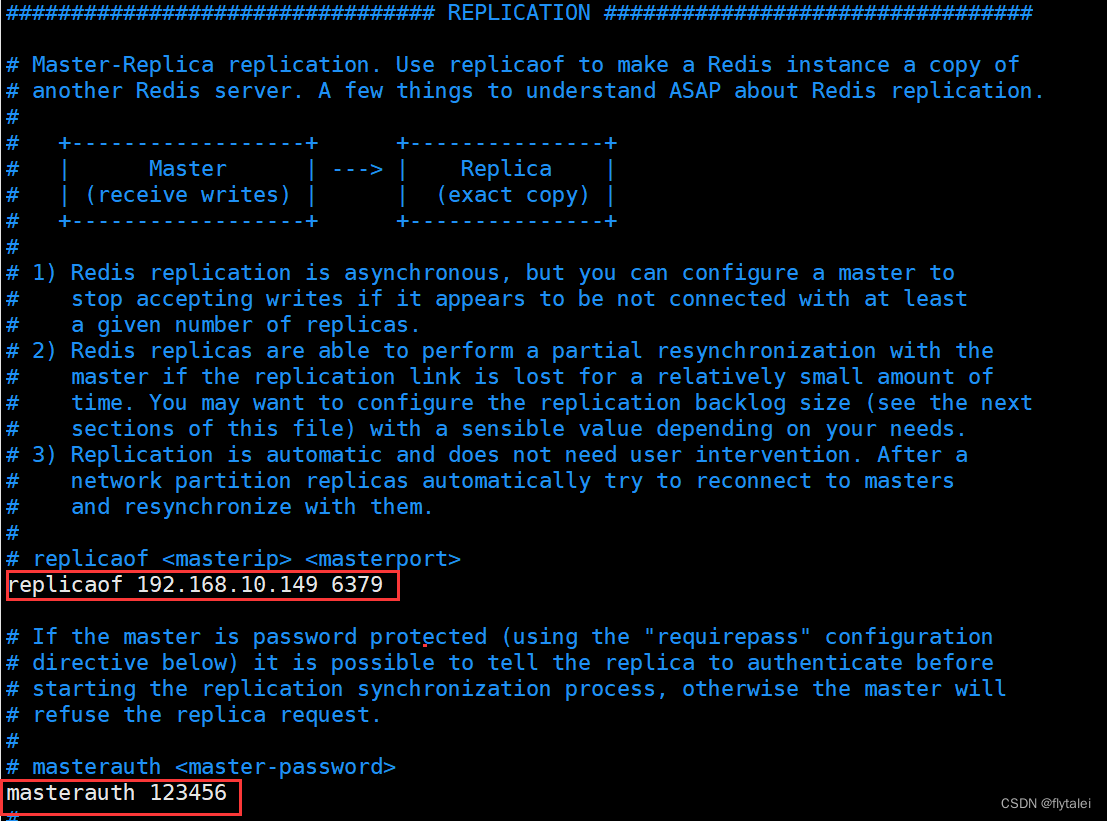
当master出现故障后,可以提升一个slave节点变成新的master,因此Redis Slave需要设置和master相同的连接密码,此外一个Slave提升为新的master通过持久化实现数据的恢复。
Redis默认都是master节点,如果要配置为slave从节点,需要指定master服务的IP,端口及连接密码。
在从节点执行“”
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:93a9dd9d5cc79b46e15cf9fb1bf4a2fe68d7fd67
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
在从节点上配置
replicaof master_ip port
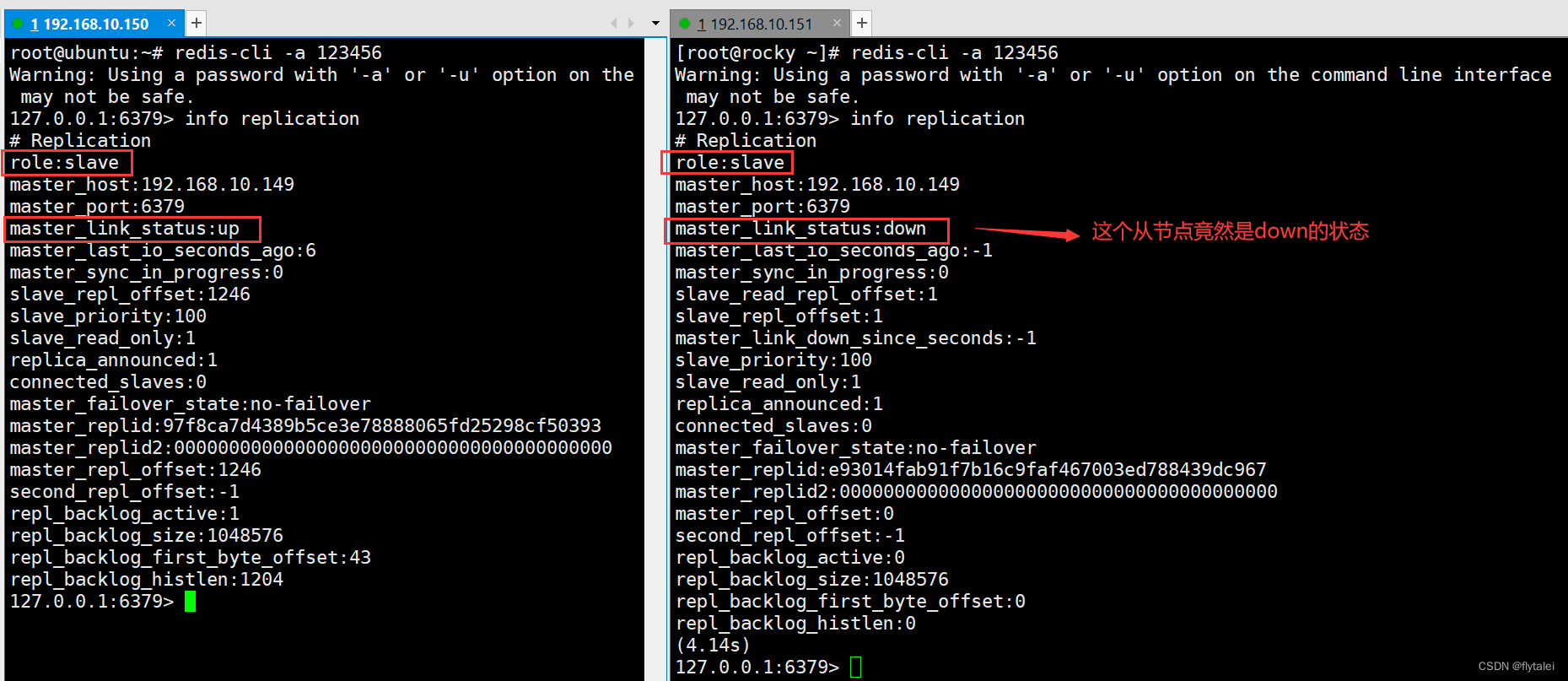
我准备了三台机器,149,150,151来实现一主两从,做完了以上截图的配置后,我们看下149机器上的replication信息
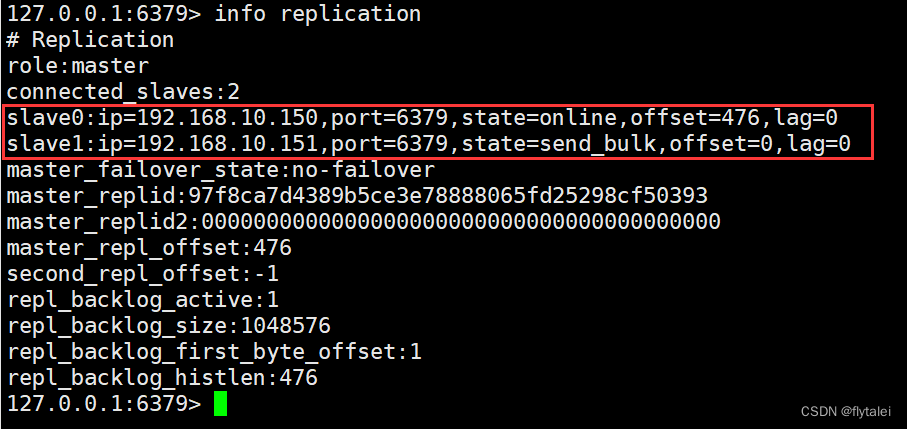
再看下两个从节点的信息,此时有一个从节点的状态是down
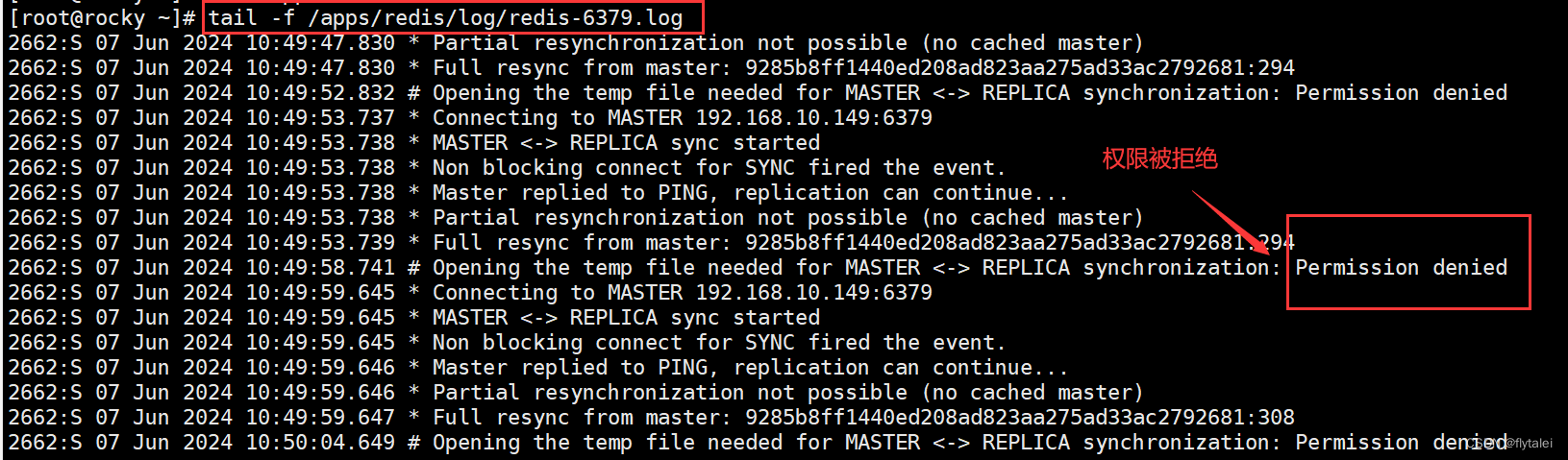
查看下日志,看看是什么原因导致的151从节点的down状态
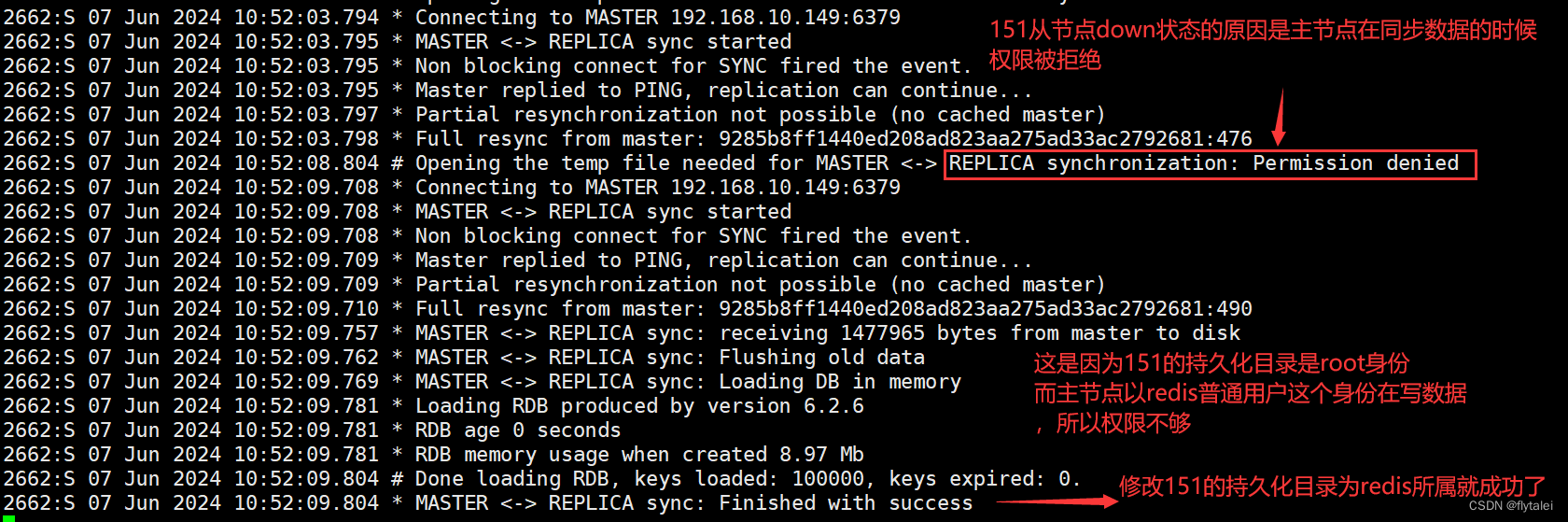

此时再看master上的两个节点信息就都正常了
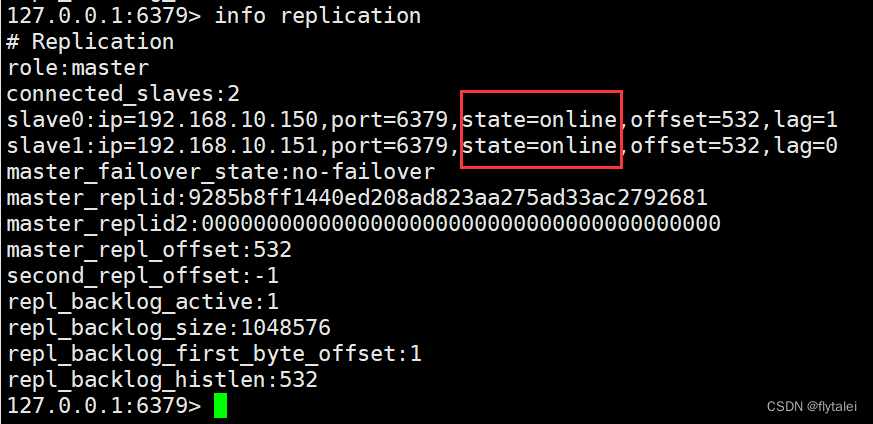
我们在149的master节点上新增一个key,此时150和151两个从节点已经同步过来了

可以看看此时151从节点上的日志信息
root@ubuntu:~# tail -n 23 /apps/redis/log/redis-6379.log
4107:S 07 Jun 2024 10:46:16.586 * Connecting to MASTER 192.168.10.149:6379
4107:S 07 Jun 2024 10:46:16.586 * MASTER <-> REPLICA sync started
4107:S 07 Jun 2024 10:46:16.586 * Non blocking connect for SYNC fired the event.
4107:S 07 Jun 2024 10:46:16.587 * Master replied to PING, replication can continue...
4107:S 07 Jun 2024 10:46:16.587 * Trying a partial resynchronization (request 97f8ca7d4389b5ce3e78888065fd25298cf50393:1485).
4107:S 07 Jun 2024 10:46:16.588 * Full resync from master: 9285b8ff1440ed208ad823aa275ad33ac2792681:0
4107:S 07 Jun 2024 10:46:16.588 * Discarding previously cached master state.
4107:S 07 Jun 2024 10:46:16.626 * MASTER <-> REPLICA sync: receiving 1477964 bytes from master to disk
4107:S 07 Jun 2024 10:46:16.632 * MASTER <-> REPLICA sync: Flushing old data
4107:S 07 Jun 2024 10:46:16.647 * MASTER <-> REPLICA sync: Loading DB in memory
4107:S 07 Jun 2024 10:46:16.649 * Loading RDB produced by version 6.2.6
4107:S 07 Jun 2024 10:46:16.649 * RDB age 0 seconds
4107:S 07 Jun 2024 10:46:16.649 * RDB memory usage when created 8.93 Mb
4107:S 07 Jun 2024 10:46:16.672 * MASTER <-> REPLICA sync: Finished with success
4107:S 07 Jun 2024 10:46:16.673 * Background append only file rewriting started by pid 4574
4107:S 07 Jun 2024 10:46:16.719 * AOF rewrite child asks to stop sending diffs.
4574:C 07 Jun 2024 10:46:16.719 * Parent agreed to stop sending diffs. Finalizing AOF...
4574:C 07 Jun 2024 10:46:16.719 * Concatenating 0.00 MB of AOF diff received from parent.
4574:C 07 Jun 2024 10:46:16.719 * SYNC append only file rewrite performed
4574:C 07 Jun 2024 10:46:16.720 * AOF rewrite: 0 MB of memory used by copy-on-write
4107:S 07 Jun 2024 10:46:16.788 * Background AOF rewrite terminated with success
4107:S 07 Jun 2024 10:46:16.788 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
4107:S 07 Jun 2024 10:46:16.788 * Background AOF rewrite finished successfully
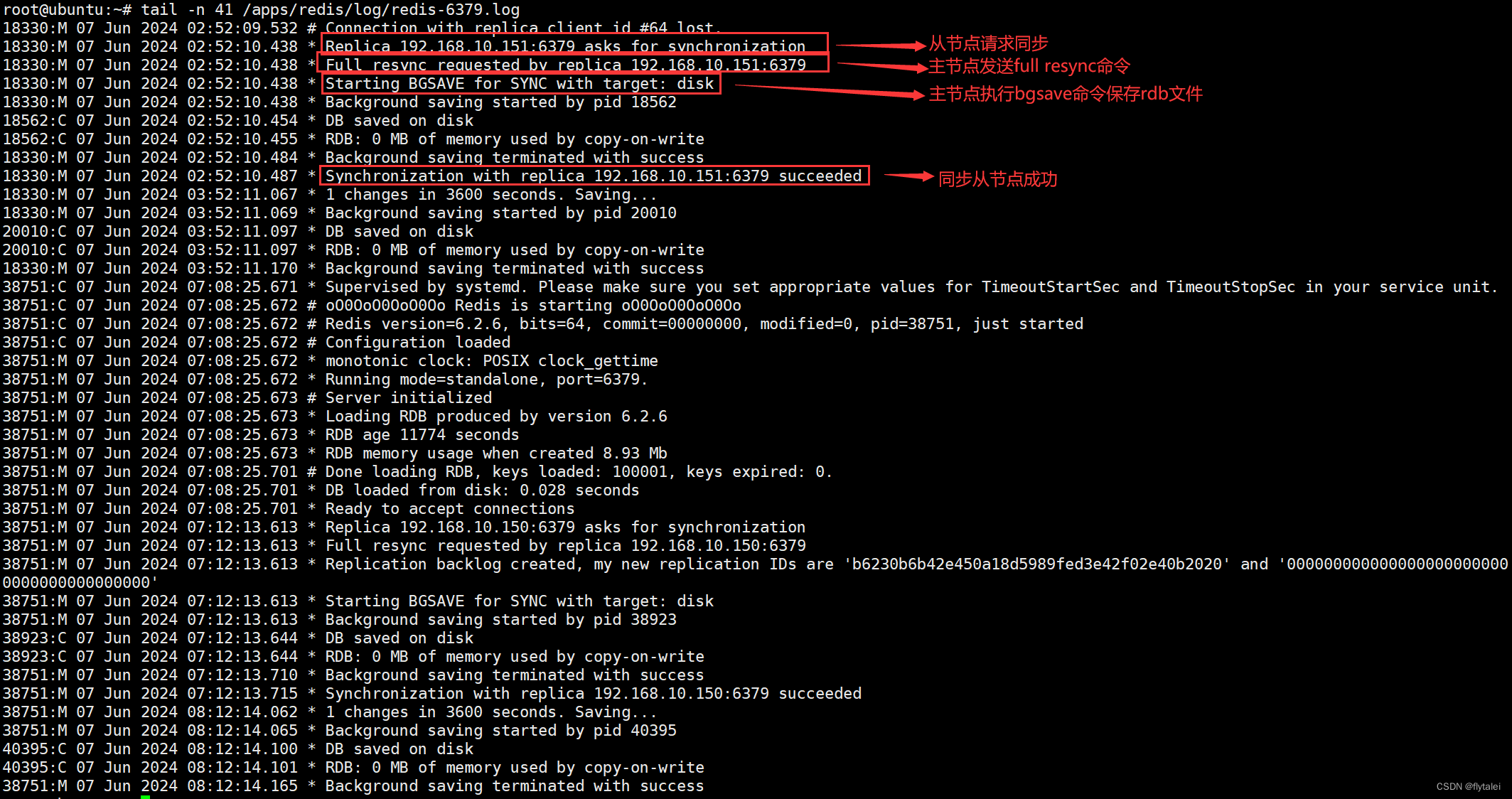
master节点149的日志信息
root@ubuntu:~# tail -n 14 /apps/redis/log/redis-6379.log
18330:M 07 Jun 2024 02:52:09.532 # Connection with replica client id #64 lost.
18330:M 07 Jun 2024 02:52:10.438 * Replica 192.168.10.151:6379 asks for synchronization
18330:M 07 Jun 2024 02:52:10.438 * Full resync requested by replica 192.168.10.151:6379
18330:M 07 Jun 2024 02:52:10.438 * Starting BGSAVE for SYNC with target: disk
18330:M 07 Jun 2024 02:52:10.438 * Background saving started by pid 18562
18562:C 07 Jun 2024 02:52:10.454 * DB saved on disk
18562:C 07 Jun 2024 02:52:10.455 * RDB: 0 MB of memory used by copy-on-write
18330:M 07 Jun 2024 02:52:10.484 * Background saving terminated with success
18330:M 07 Jun 2024 02:52:10.487 * Synchronization with replica 192.168.10.151:6379 succeeded
18330:M 07 Jun 2024 03:52:11.067 * 1 changes in 3600 seconds. Saving...
18330:M 07 Jun 2024 03:52:11.069 * Background saving started by pid 20010
20010:C 07 Jun 2024 03:52:11.097 * DB saved on disk
20010:C 07 Jun 2024 03:52:11.097 * RDB: 0 MB of memory used by copy-on-write
18330:M 07 Jun 2024 03:52:11.170 * Background saving terminated with success
删除主从同步
在从节点上执行“replicaof no one”指令可以取消主从复制
取消复制,在slave上执行"replicaof no one" 会断开和master的连接不在主从复制,但不会清除slave上已有的数据
主从复制故障恢复
关掉149,提升150为master
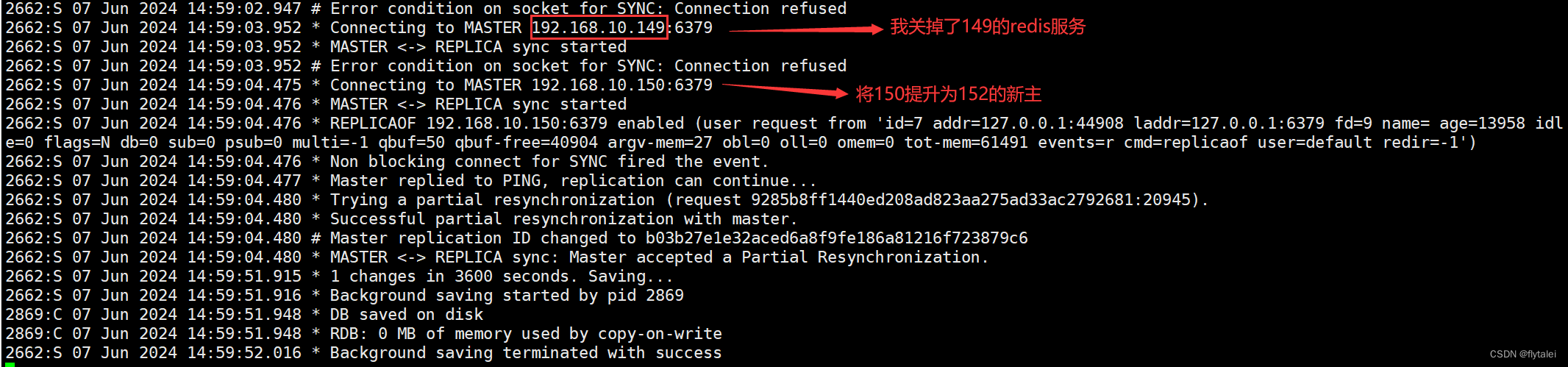

级联复制
149同步给150,再由150同步给151,一级一级的同步
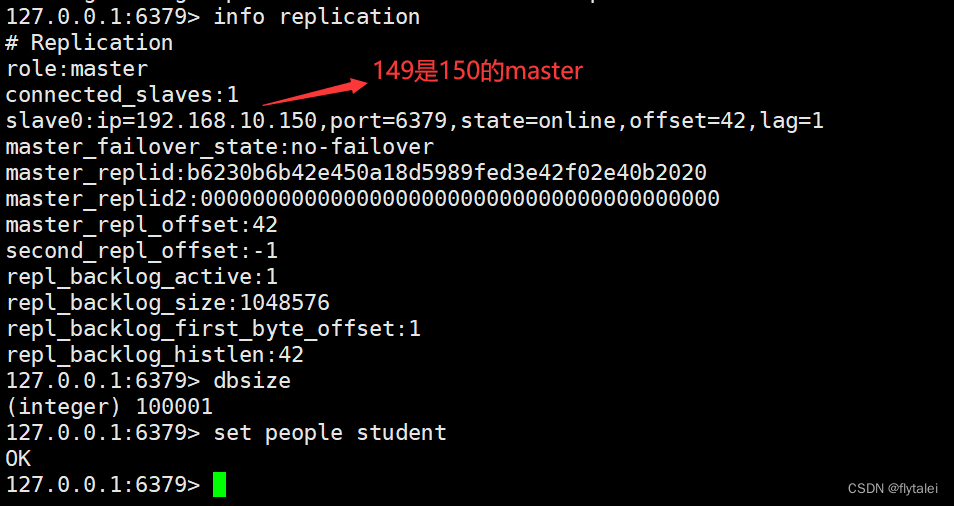

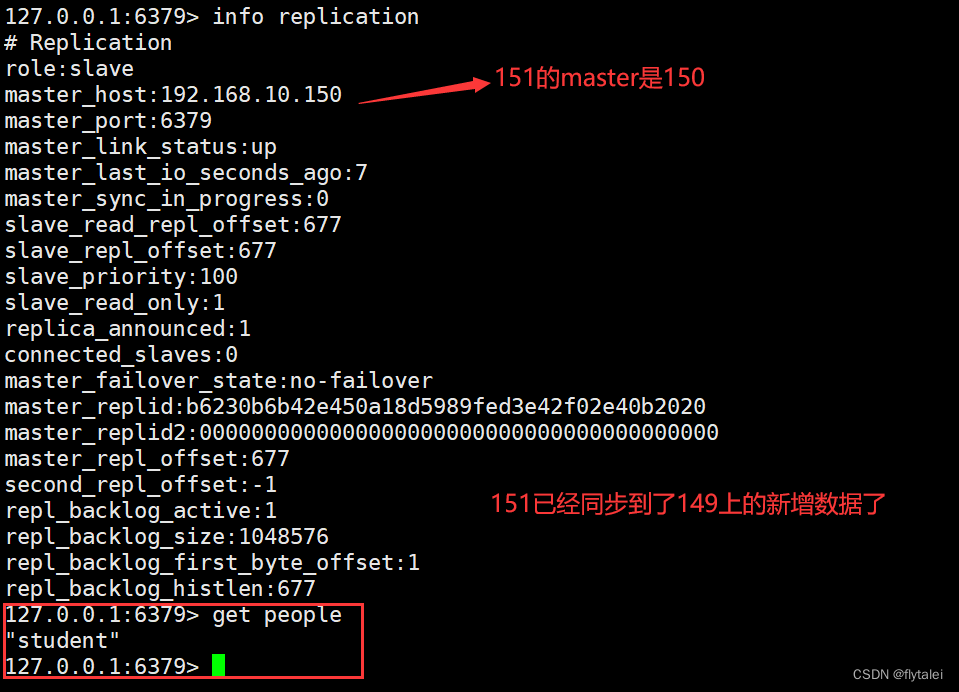
主从复制过程
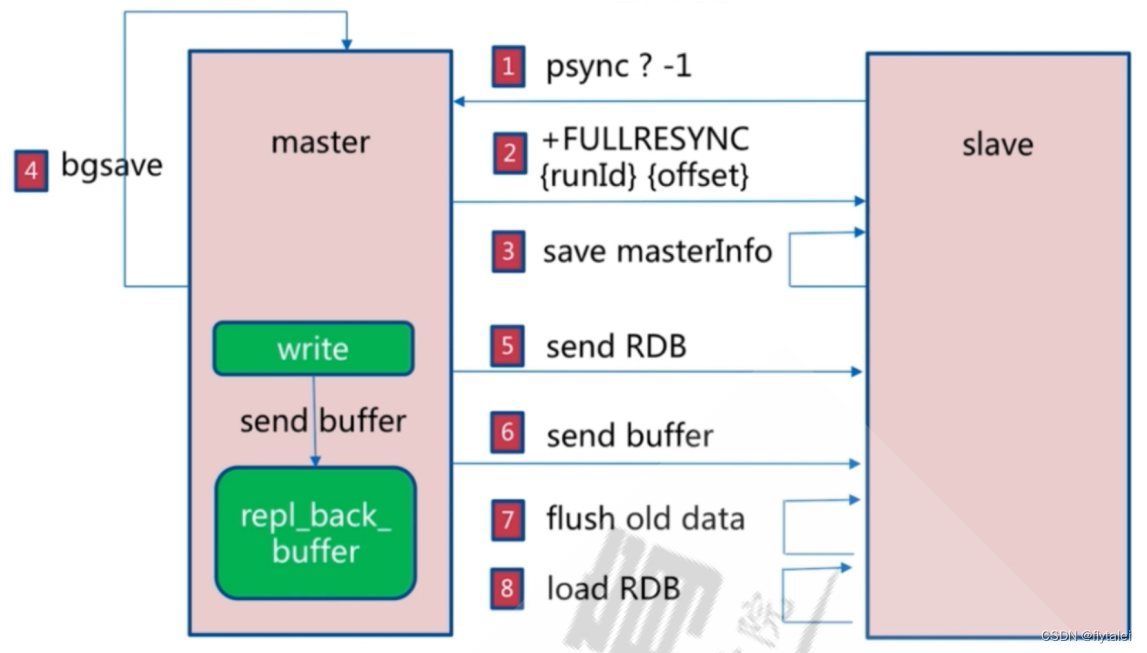
Redis主从复制分为全量同步和增量同步
主从同步是非阻塞的,即同步过程不会影响主服务器的正常访问。
全量复制
全量复制过程:
1.主从节点建立连接,验证身份后,从节点向主节点发送PSYNC命令
2.主节点向从节点发送FULLRESYNC命令,包括runid和offset
3.从节点保存主节点信息
4.主节点执行bgsave保存rdb文件,同时记录新的记录到buffer中
5.主节点发送rdb文件给从节点
6.主节点将新收到buffer中的记录发送至从节点
7.从节点删除本机的旧数据
8.从节点加载RDB
9.从节点同步主节点的buffer信息
主节点主从复制的log信息
从节点主从复制的log信息

Redis哨兵(Sentinel)
我们上面搭建的Redis主从复制架构无法实现master和slave角色的自动切换。即当master出现故障后,不能自动的将一个slave节点提升为新的master继续提供Redis服务。如果通过手动切换,势必很繁琐也不够高效,从而导致Redis服务性能达到瓶颈。那么我们此时就可以引入Redis的哨兵机制Sentinel来实现master和slave节点的自动切换。
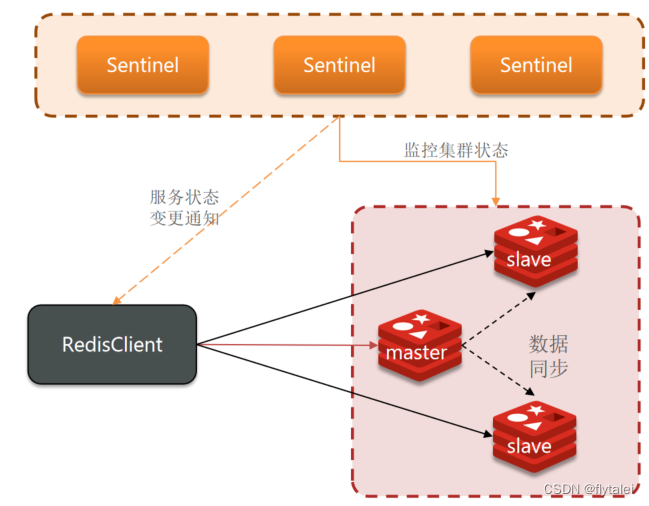
哨兵的作用
Redis的哨兵机制实现主从架构的故障恢复。哨兵也需要一个集群的架构,不然哨兵自己都挂了还提供什么故障恢复,它的作用有3点
1.监控:Sentinel会不断检查master和slave是否安预期工作
2.自动故障恢复:master故障后,Sentinel会将一个slave提升为master,当故障实例恢复后也以新的master为主
3.通知:Sentinel充当Redid客户端的服务发现来源,但集群发生故障转移时,会将最新信息推送给Redis客户端
为了避免脑裂,Sentinel服务实例最好是奇数个 3、5、7…等,一般控制成本3个Sentinel就够了。
哨兵的相关配置
哨兵的配置文件sentinel.conf编译安装时默认解压在了源码目录“/usr/local/src/redis-6.2.6”目录下
grep -vE "^#|^$" /apps/redis/etc/sentinel.conf
在我配置的出从架构的三台机器149,150,151中分别做一下sentinel.conf的配置。
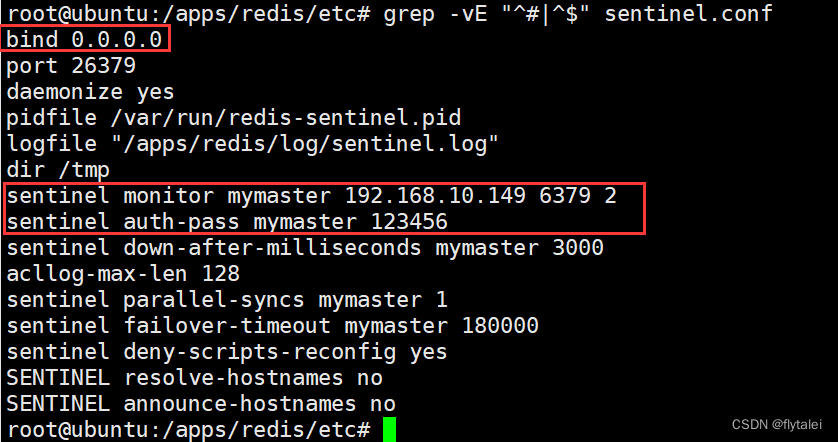
vim sentinel.conf
# port <sentinel-port>
port 26379
# By default Redis Sentinel does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis-sentinel.pid when
# daemonized.
daemonize no
# When running daemonized, Redis Sentinel writes a pid file in
# /var/run/redis-sentinel.pid by default. You can specify a custom pid file
# location here.
pidfile /var/run/redis-sentinel.pid
# Specify the log file name. Also the empty string can be used to force
# Sentinel to log on the standard output. Note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
logfile ""
# dir <working-directory>
# Every long running process should have a well-defined working directory.
# For Redis Sentinel to chdir to /tmp at startup is the simplest thing
# for the process to don't interfere with administrative tasks such as
# unmounting filesystems.
dir /tmp
sentinel monitor mymaster 127.0.0.1 6379 2
mymaster是集群的名称,此行指定当前mymaster集群中master服务器的地址和端口;
2为法定人数限制(quorum),即有几个sentinel认为master down了就进行故障转移,一般此值是所有sentinel节点(一般总数是>=3的奇数,3,5,7等)的一半以上的整数值,比如,总数是3,即3/2=1.5,取整为2,是master的down客观下线的依据。
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
#
# Tells Sentinel to monitor this master, and to consider it in O_DOWN
# (Objectively Down) state only if at least <quorum> sentinels agree.
#
# Note that whatever is the ODOWN quorum, a Sentinel will require to
# be elected by the majority of the known Sentinels in order to
# start a failover, so no failover can be performed in minority.
#
# Replicas are auto-discovered, so you don't need to specify replicas in
# any way. Sentinel itself will rewrite this configuration file adding
# the replicas using additional configuration options.
# Also note that the configuration file is rewritten when a
# replica is promoted to master.
#
# Note: master name should not include special characters or spaces.
# The valid charset is A-z 0-9 and the three characters ".-_".
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# sentinel auth-pass <master-name> <password>
#
# Set the password to use to authenticate with the master and replicas.
# Useful if there is a password set in the Redis instances to monitor.
#
# Note that the master password is also used for replicas, so it is not
# possible to set a different password in masters and replicas instances
# if you want to be able to monitor these instances with Sentinel.
#
# However you can have Redis instances without the authentication enabled
# mixed with Redis instances requiring the authentication (as long as the
# password set is the same for all the instances requiring the password) as
# the AUTH command will have no effect in Redis instances with authentication
# switched off.
#
# Example:
#
# sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
myster集群中master的密码,注意此行要在上面行的下面
sentinel down-after-milliseconds mymaster 30000
# sentinel down-after-milliseconds <master-name> <milliseconds>
#
# Number of milliseconds the master (or any attached replica or sentinel) should
# be unreachable (as in, not acceptable reply to PING, continuously, for the
# specified period) in order to consider it in S_DOWN state (Subjectively
# Down).
#
# Default is 30 seconds
判断mymaster集群中所有节点的主观下线(SDOWN)的时间,单位:毫秒,建议3000
sentinel parallel-syncs mymaster 1
# The password for Sentinel to authenticate with other Sentinels. If sentinel-user
# is not configured, Sentinel will use 'default' user with sentinel-pass to authenticate.
# sentinel parallel-syncs <master-name> <numreplicas>
#
# How many replicas we can reconfigure to point to the new replica simultaneously
# during the failover. Use a low number if you use the replicas to serve query
# to avoid that all the replicas will be unreachable at about the same
# time while performing the synchronization with the master.
发生故障转移后,可以同时向新master同步数据的slave的数量,数字越小总同步时间越长,但可以减轻新master的负载压力。
sentinel failover-timeout mymaster 180000
# sentinel failover-timeout <master-name> <milliseconds>
#
# Specifies the failover timeout in milliseconds. It is used in many ways:
#
# - The time needed to re-start a failover after a previous failover was
# already tried against the same master by a given Sentinel, is two
# times the failover timeout.
#
# - The time needed for a replica replicating to a wrong master according
# to a Sentinel current configuration, to be forced to replicate
# with the right master, is exactly the failover timeout (counting since
# the moment a Sentinel detected the misconfiguration).
#
# - The time needed to cancel a failover that is already in progress but
# did not produced any configuration change (SLAVEOF NO ONE yet not
# acknowledged by the promoted replica).
#
# - The maximum time a failover in progress waits for all the replicas to be
# reconfigured as replicas of the new master. However even after this time
# the replicas will be reconfigured by the Sentinels anyway, but not with
# the exact parallel-syncs progression as specified.
#
# Default is 3 minutes.
所有slaves指向新的master所需的超时时间,单位:毫秒
启动Sentinel
指定配置文件前台启动sentinel
/apps/redis/bin/redis-sentinel /apps/redis/etc/sentinel.conf
配置service文件systemd启动sentinel
[Unit]
Description=Redis Sentinel
After=network.target
[Service]
ExecStart=/apps/redis/bin/redis-sentinel /apps/redis/etc/sentinel.conf --supervised systemd
ExecStop=/bin/kill -s QUIT $MAINPID
Type=notify
User=redis
Group=redis
RuntimeDirectory=redis
RuntimeDirectoryMode=0755
LimitNOFILE=1000000
[Install]
WantedBy=multi-user.target
注意所有节点的目录权限,否则无法启动服务
chown -R redis.redis /apps/redis
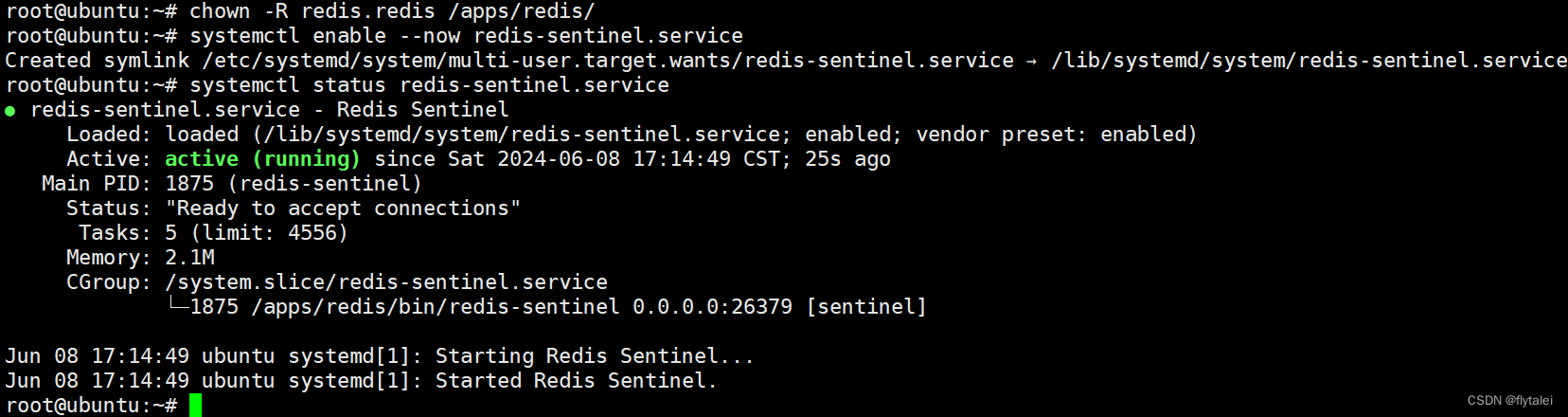
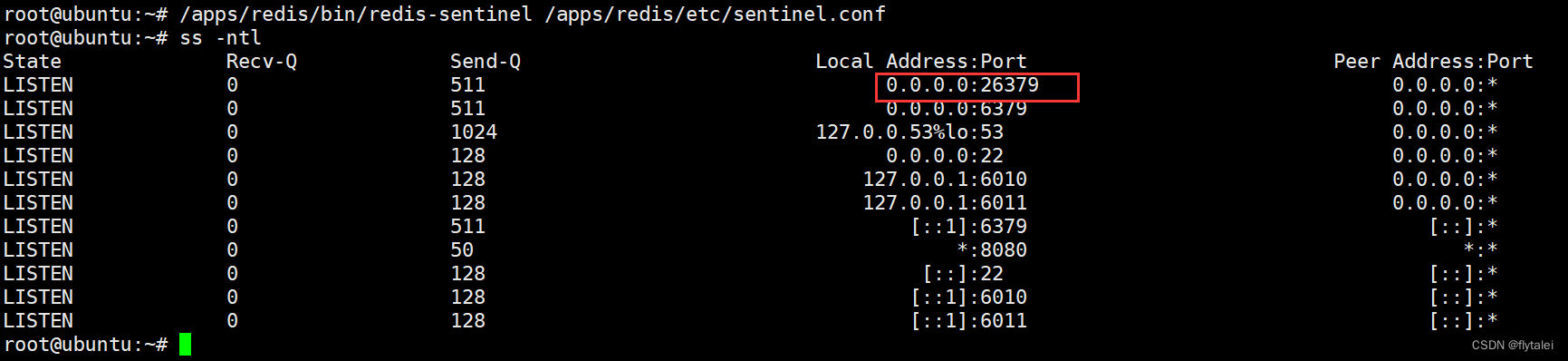
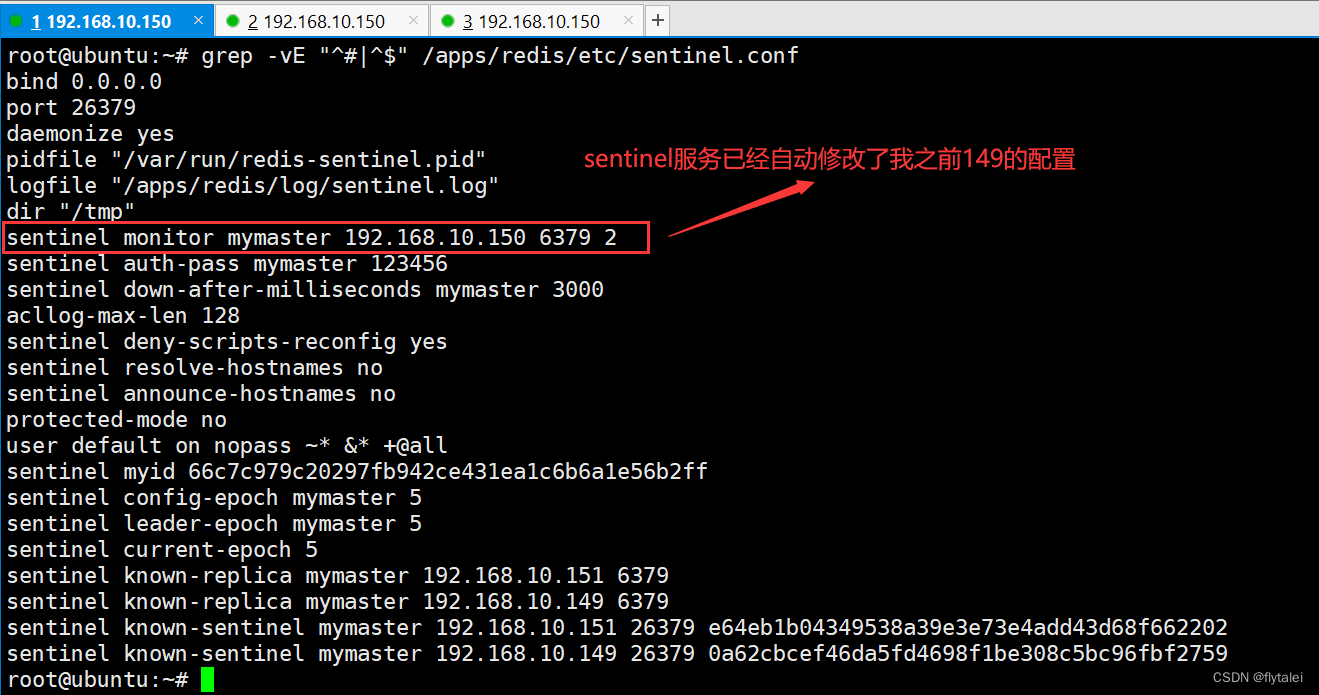
sentinel启动成功后,sentinel服务自动地在各自的服务的sentinel.conf文件的末尾出添加了如下信息:
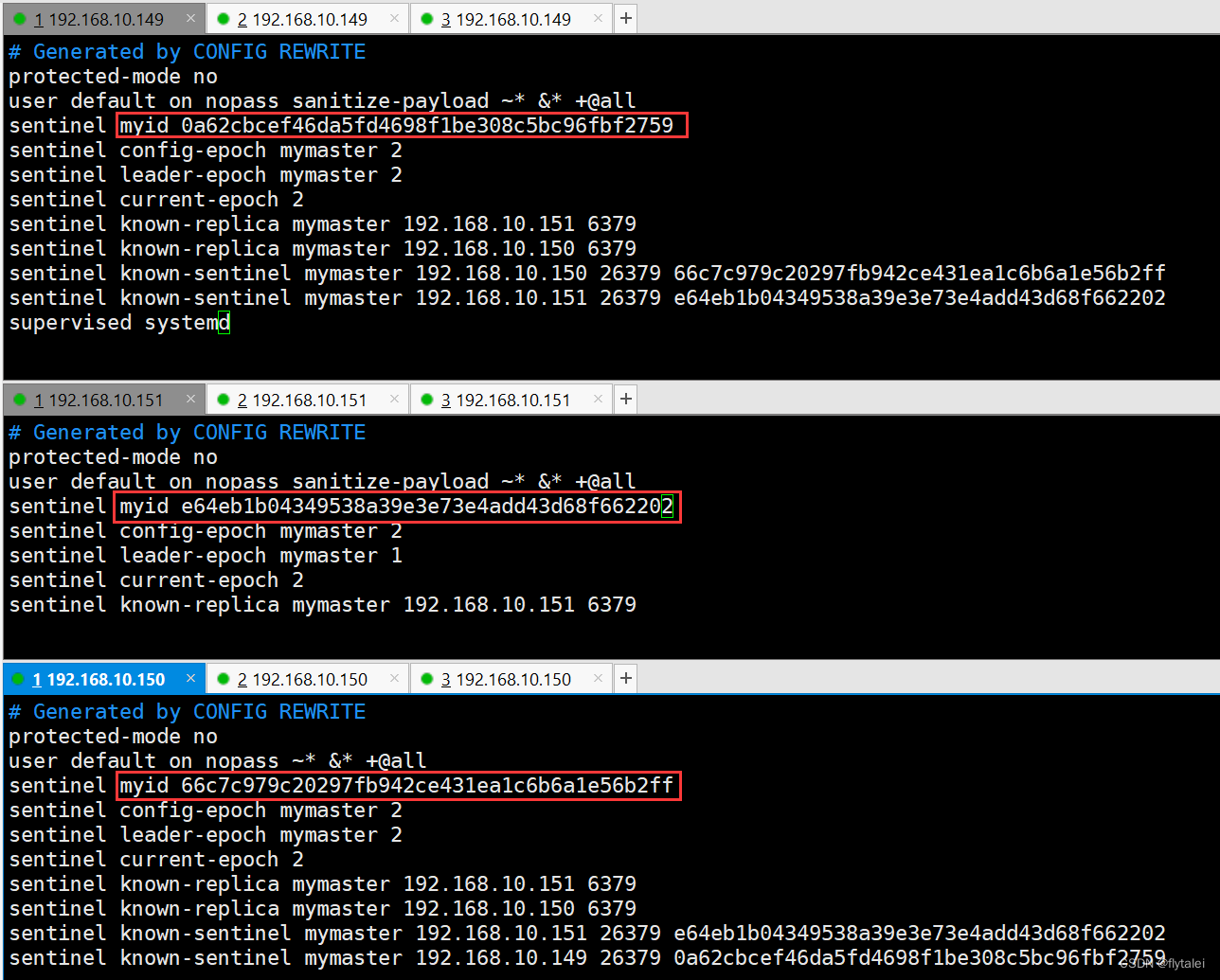
Sentinel配置成功地info和log
可以登录到Sentinel服务上去看info信息,能看到以下信息才是正常的,slaves=2,sentinels=3

149的sentinel.log

150的sentinel.log

151的sentinel.log

宕掉master实现故障转移
21:00点我停掉了redis服务
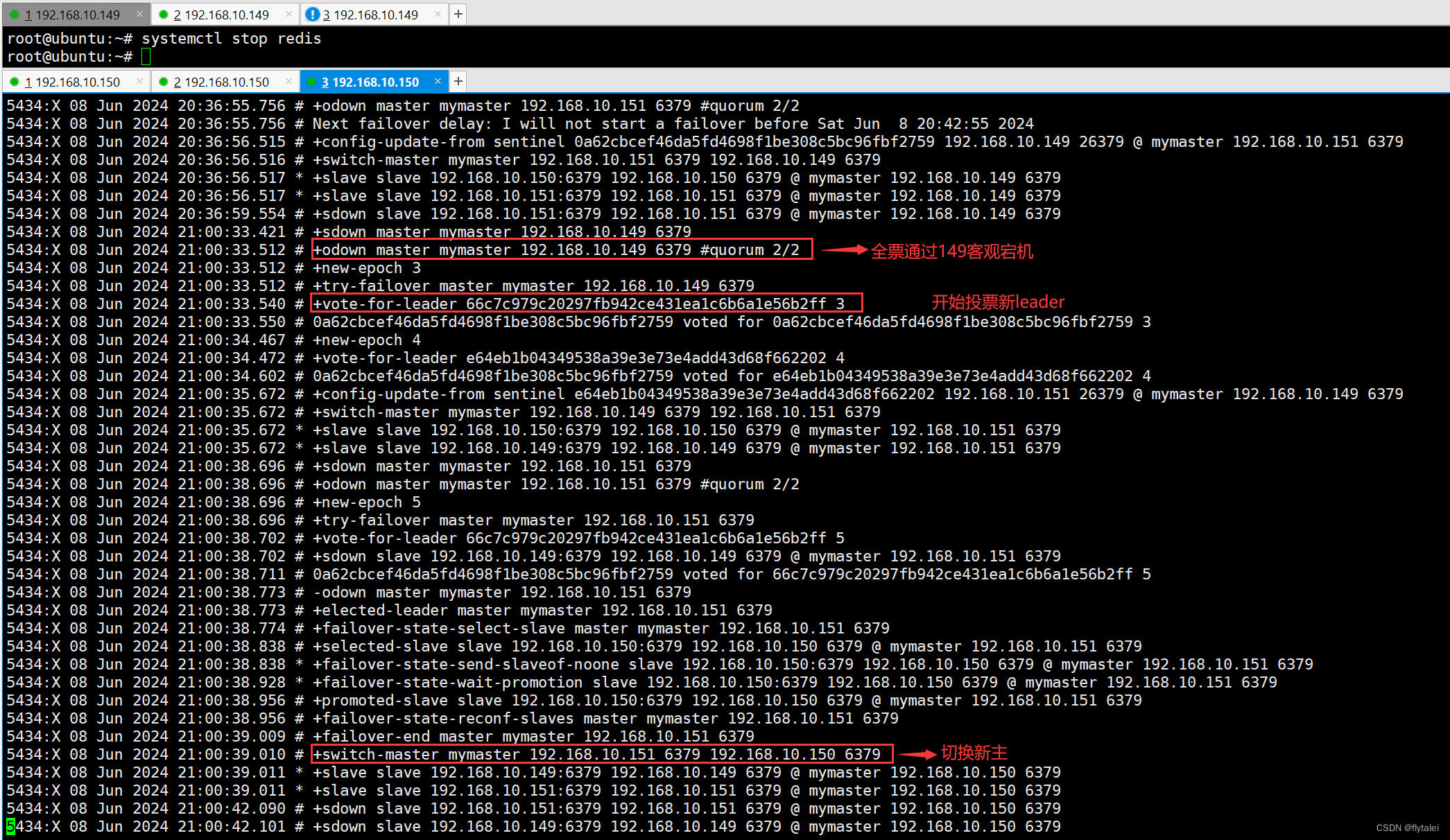
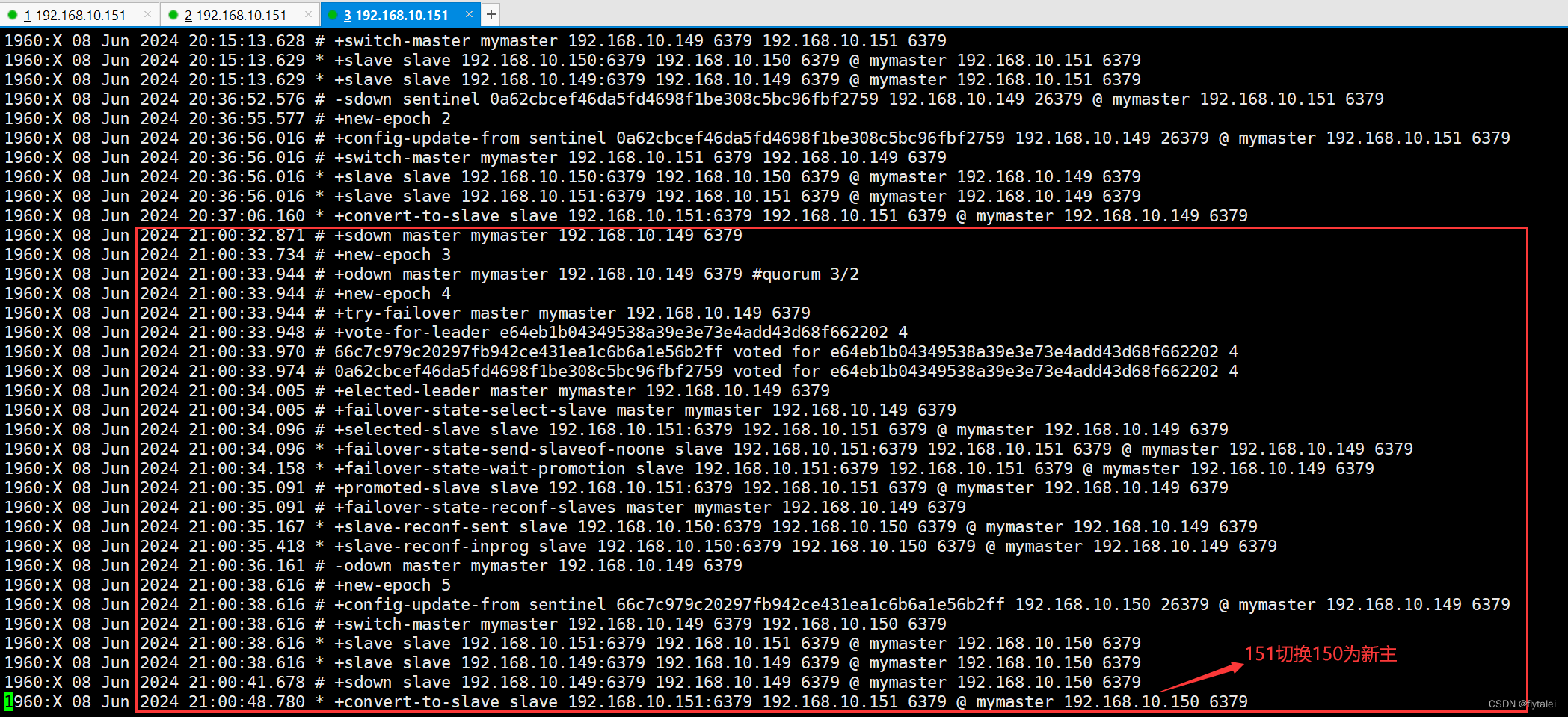
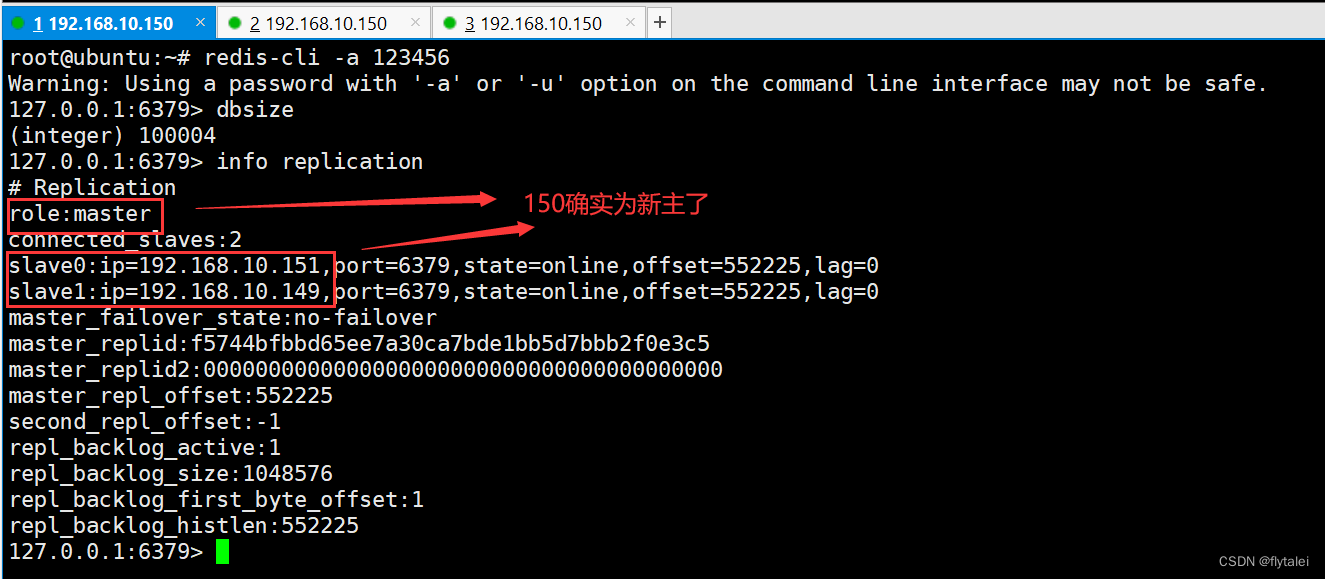
故障转移后sentinel服务修改了sentinel.conf中的配置
手动让主节点下线
sentinel failover <masterName>
# sentinel failover mymaster
# 指定优先级,值越小sentinel会优先将之选为新的master,默认值为100
congfig set replica-priority 99















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









