







Riak
基于Amazon的Dynamo论文,用erlang实现,
是一种分布式的key-value数据库,值可以是任何类型的数据(普通文本,JSON,图片,视频),通过普通的http接口访问。
容错是Riak另一个特性是容错。不会有单点故障,所有结点对等,并允许任意增大或缩小集群。
编译Riak,有三个示例服务器,修改配置文件/etc/app.config,创建集群的做法是在各个节点服务器的riak-admin目录下用命令cluster join ,将其指向其他集群节点,从而相连。
REST 是 REpresentational State Transfer,表述性状态转移。REST是将资源映射到URL及使用CRUD方法与这些URL交互的标准。
为了避免冲突,Rial将键分为各个种类,放入桶(bucket)中。
将一个键关联到其他键的元数据称为链接。
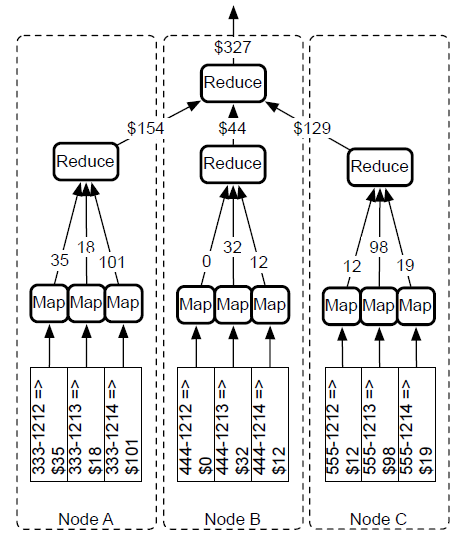
Mapreduce框架
map,映射, reduce, 归约
map函数的结果会输入reduce函数,然后,map函数和reduce函数共同协作的结果也会注入其后连续调用的reduce函数。
键过滤器,
Riak最近新增的特性,键过滤器是一组命令的集合,可以在执行mapreduce之前预处理键。
利用mapreduce作链接遍历
一致性和持久性
Riak服务器架构消除了单点故障
CAP定理:Consistency,Availability,Partition tolerance,一致性,可用性,分区容错性,只能保证三个钟的两个
Riak 环与节点读写
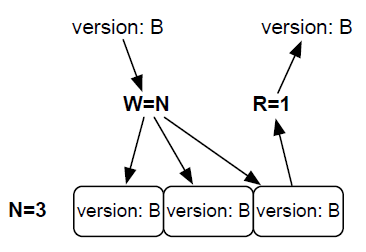
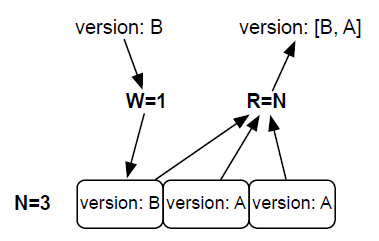
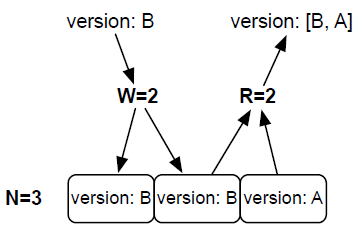
Riak允许通过改变三个值:N,W与R来控制集群的读写。N是一次写入最终复制到的节点数量,换句话说就是集群中的副本数量。WW是一次成功地写入响应之前,必须成功写入的节点数量。如果W小于N, 就认为某次写入是成功的,即使Riak依然在复制数据。最后,R是成功读出一项数据所必需的节点数量。
一种确保我们能够读到最新值的方法是让W=N, R=1,从本质上讲,这是关系数据库的做法;通过确保写操作在返回之前完成,以保证一致性,但是,这确实会降低读写操作的性能。如下:
或者,可以写入单个节点,从全部节点独处,即W=1, R=N,尽管可能读到旧值,但是可以保证检索到最新的值,只要找出哪个是最新的值(通过一个
向量时钟实现)。但是副作用是读操作因此减慢(一读就读所有N副本)
上面的还要插一句,如果尝试从所有节点读取数据,请求失败的概率会很大。一旦某个节点出现故障,Riak可能无法满足读请求。
还有一种选择,让W=2, R=2(N=3),只需要写入多于一半的节点,并从多于一半的节点中读出,就可以保证一致性。这称为法定数(quorum),是确保数据一致性的方法中开销最小的。(but how?笔者囫囵吞枣,浅尝辄止,没看明白怎么保证,多于一半的肯定是有最新值的,难道跟第一个一样也要个向量时钟?先记下来)
若不想等待Riak写入任何节点,可以把W设置成0.意思是“Riak,我相信你会将数据写入,只管返回吧”。
W=0对日志是非常适用的配置,而让W=N且R=1,很适合高速读取数据,极少写入数据的场景。
写入与持久化写入
Riak的写入操作未必是持久化的,也就是说,数据并非立刻写入磁盘。即使一个节点的写入操作成功执行,依然可能因为故障而丢失这个节点中的数据,就算W=N,节点服务器也会发生故障,丢失数据,写入的数据在存到磁盘之前,会于内存中缓存片刻,而这毫秒级的间隙正是危险的所在。
因此,Riak提供了名为DW的单独设置,用于持久化写入,在这种设置下,直到对象写入给定数量的节点上的磁盘,Riak才会成功返回。
级联故障,罕见但依然可能发生。
用向量时钟解决冲突
保持时钟同步是最为困难的,在许多情况下,甚至是不可能的。使用集中式时钟系统是对Riak哲学的诅咒,其意味着单点故障的可能性。

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









