






最后回顾一下读取和处理数据的过程,具体方法如下:
1. 读取CSV文件
STEP1 导入csv模块
STEP2 打开文件
STEP3 读取文件
2. 标准化处理
STEP1 先创建一个空列表,用于存储reader对象中的值
STEP2 遍历reader对象
STEP3 将reader对象中的每行数据添加到空列表data中
在最后,我们将data变量输出进行查看。
# 导入csv模块
import csv
# 使用open()函数打开数据集,并将返回的文件对象存储在变量file中
file = open("/Users/yequ/TVComments.csv", "r")
open(“路径”,“打开方式”)
# 使用csv.reader()函数读取数据集,并赋值给变量reader
reader = csv.reader(file)
# 创建一个空列表data
data = []
# 使用for循环遍历reader,将遍历的数据存储到变量info中
for info in reader:
# 使用append()函数,将info逐一添加到data列表中
data.append(info)
# 输出data变量
print(data)
复习结束~
根据上节课的内容,我们知道了对多条评价建立词袋模型的大概步骤:
1. 先对每条评价进行分词
2. 从中提取所有出现过的词语
3. 统计每条评价里每个词语出现的次数
今天,我们会系统地学习这三个步骤来统计词频:

我们先进行第一步,也是文本处理的基础步骤:分词。
中文分词的方法有很多,我们选择了一个准确度还不错的jieba模块,来帮助我们完成分词。
注意:
jieba是一个开源模块,使用前需要在终端中通过代码:pip install jieba 进行安装。
如果在自己电脑上无法安装或安装缓慢,可在命令后添加如下配置来加速:
pip install jieba -i Simple Index
如下即安装成功
在 jieba 模块中,有很多种用于分词的函数。
本案例中,我们选择使用 jieba.lcut() 进行分词,把要进行分词的字符串传入到该函数中即可。
jieba.lcut()函数会将分词后的结果作为一个列表返回。
具体使用方法:
要使用jieba模块进行分词,需要先使用import导入该模块。
然后,我们把要进行分词的字符串对象赋值给变量text,再将text传入 jieba.lcut()函数中,即可进行分词。
最后,把分词结果赋值给变量ret,并输出查看。
# 导入jieba模块
import jieba
# 将"我真的很喜欢编程",赋值给变量text
text = "我真的很喜欢编程"
# 将text传入jieba.lcut()中,并把结果赋值给ret
ret = jieba.lcut(text)
# 输出ret进行查看
print(ret)
output:
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.667 seconds.
Prefix dict has been built successfully.
['我', '真的', '很', '喜欢', '编程']
分析结果:
我们再来看一下刚才输出的结果~
在分词的过程中,会输出jieba模块创建分词模型的过程和花费的时间:
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.667 seconds.
Prefix dict has been built successfully.
模型建立成功后,会以列表的形式返回分词的结果:
['我', '真的', '很', '喜欢', '编程']

注意:
使用 jieba.lcut() 函数分词后,返回的结果是字符串列表。在这里,有多少条电视机评价,就有多少个列表生成。
接下来:
但后续构造词袋模型时,需要传入的数据格式是一个字符串列表,因此我们得对分词结果进行处理:
STEP1. 先将每条评价的分词结果,也就是每个列表中的元素,以空格连接生成一个新的字符串
STEP2. 然后将这些字符串逐一添加到一个新列表中
我们先来完成处理分词结果的第一个小步骤:将分词结果以空格合并为一个完整的字符串。这时,就需要用到join()函数。
Join():
Python中,join()函数可以将列表中的元素以指定的字符连接生成一个新的字符串。只需对指定的字符串使用join()函数,再将要连接的列表作为参数传入即可。

回到项目中,我们来尝试一下使用join()函数,将分词结果ret以空格合并为一个完整的字符串。
# 导入csv模块
import csv
# 使用open()函数打开数据集
file = open("/Users/yequ/TVComments.csv", "r")
# 使用csv.reader()函数读取数据集
reader = csv.reader(file)
# 创建一个空列表data
data = []
# 使用for循环遍历reader,将遍历的数据存储到变量info中
for info in reader:
# 使用append()函数,将info逐一添加到data列表中
data.append(info)
# 导入jieba模块
import jieba
# 使用for循环遍历data列表
for row in data:
# 获取具体的评价内容,并赋值给变量text
text = row[0]
# 使用jieba.lcut()将text进行分词,并把结果赋值给ret
ret = jieba.lcut(text)
# 使用join()函数,将分词结果以空格合并为一个完整的字符串
ret = ' '.join(ret)
# 输出ret进行查看
print(ret)
为了构造词袋模型,我们已经完成了处理分词结果的第一个步骤,将每条评价的分词结果以空格连接生成一个新的字符串。现在可以进行第二步:将这些字符串逐一添加到一个新列表中。具体操作如下:
先新建一个列表word,再使用append()函数,将这些字符串逐一添加到新列表word中。我们在for循环外,将word输出进行查看。
修改后的代码:
# 导入jieba模块
import jieba
# 创建一个空列表word存储结果
word = []
# 使用for循环遍历data列表
for row in data:
# 获取具体的评价内容,并赋值给变量text
text = row[0]
# 使用jieba.lcut()将text进行分词,并把结果赋值给ret
ret = jieba.lcut(text)
# 使用join()函数,将分词结果以空格合并为一个完整的字符串
ret = ' '.join(ret)
# 使用append()函数,添加分词结果到列表word中
word.append(ret)
# 输出word进行查看
print(word)

接下来,就需要构造词袋模型,从这些评价中提取所有出现过的词语,然后统计每个词出现的频率,即词频。找到商品评论中出现次数最多的词语,比如出现频率最高的前15个词,可能就找出了最能够描述这件商品的关键词。
我们可以使用强大的机器学习模块:sklearn,来完成词袋模型的建立。通过它提供的函数,能够直接提取评论里出现的所有词语,并快速找到出现频率最高的词语~
同样sklearn不是内置模块,所以在使用前需要在终端中输入代码:pip install scikit-learn==1.1.3,进行安装。如果在自己电脑上无法安装或安装缓慢,可在命令后添加如下配置来加速:
pip install scikit-learn==1.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/

安装成功后,我们就可以使用sklearn模块建立词袋模型,并找出关键词啦。具体步骤如下:
STEP1. 导入模块
STEP2. 创建CountVectorizer对象
STEP3. 使用fit_transform()函数构造词袋模型
STEP4. 使用get_feature_names()提取关键词
具体步骤:
1. 导入模块
sklearn模块提供了多种机器学习所需的算法包。
构造词袋模型其实就是在提取文本的特征,也就是词频,需要用到的是sklearn.feature_extraction.text模块,它包含了关于提取文本特征的算法。
该模块有一个 CountVectorizer 类,为我们提供了一些可以快速统计词频的方法。
(1) 导入模块
我们需使用
from...import...,从 sklearn.feature_extraction.text 模块中导入 CountVectorizer 类。
代码:from sklearn.feature_extraction.text import CountVectorizer
2. 创建CountVectorizer对象
导入模块后,需要创建一个CountVectorizer对象,这样才能调用CountVectorizer类里面的某个方法或属性。
代码:vect = CountVectorizer()
在创建对象时,可以传入可选参数max_features,用于控制提取的文本特征数量。
由于我们只想从评价中筛选出前15个出现频率最高的词语,所以传入了max_features=15。我们将创建好的对象存储在变量vect中。
修改后的代码:vect = CountVectorizer(max_features=15)
CountVectorizer类里,有个 fit_transform() 函数,用于构造词袋模型,计算各个词语出现的次数。传入该函数中的数据格式必须是一个字符串列表,这就解释了为什么刚刚我们需要对数据进行处理。fit_transform() 会筛选出所有评价里前15个出现频率最高的词语,并对这些词语进行编号,然后依次统计每条评价里这些词语出现的次数。
3. 调用fit_transform()函数构造词袋模型
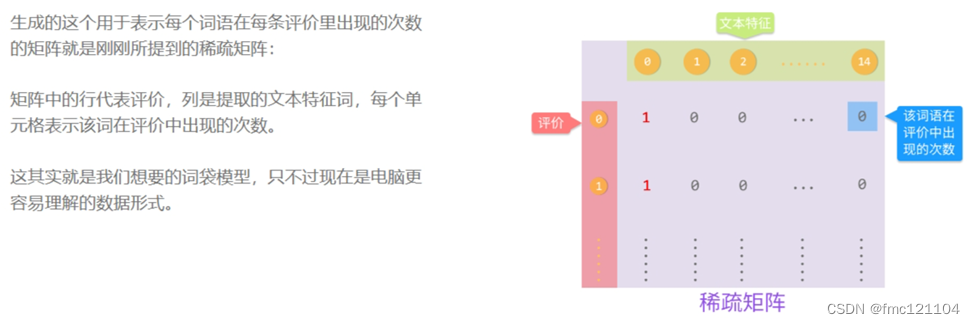
只需对vect对象使用fit_transform()函数,然后将存储了分词结果的列表word传入其中即可。fit_transform()函数会返回一个稀疏矩阵(sparse matrix)来记录每一条评价里,每个词语出现的次数。我们把该结果赋值给了X,并输出进行查看
代码:
# 通过vect.fit_transform()和word,构造词袋模型
X = vect.fit_transform(word)
# 输出X
print(X)

原理:
现在,我们自己来尝试一下构造词袋模型吧~具体方法如下:
1. 使用
from...import...,从 sklearn.feature_extraction.text 模块中导入 CountVectorizer 类
2. 创建CountVectorizer对象,并将max_features=15作为可选参数传入,把结果存储在vect变量中
3. 对vect对象使用fit_transform()函数,将存储了分词结果的列表word传入其中,并把结果赋值给变量X
最后输出X变量,我们就得到了这份评论数据的词袋模型。
# 使用append()函数,添加分词结果到列表word中
word.append(ret)
# 从sklearn.feature_extraction.text中导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
# 创建CountVectorizer对象,并存储在vect中
vect = CountVectorizer(max_features=15)
# 通过vect.fit_transform()和word,构造词袋模型
X = vect.fit_transform(word)
# 输出X
print(X)
4. 提取关键词
构建完词袋模型后,我们可以对vect对象使用get_feature_names()。
该函数会将评价里前15个出现频率最高的词语作为一个字符串列表返回。
提示:由于sklearn版本更新,在本地运行时,请将 get_feature_names()替换为 get_feature_names_out() 。
修改后的代码# 对vect对象使用get_feature_names(),并将结果赋值给keywords
keywords = vect.get_feature_names()
# 输出keywords
print(keywords)














 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









