






Redis
1.使用
如果通过宝塔面板安装:
-
启动命令:/etc/init.d/redis start
-
停止:/etc/init.d/redis stop
如果是make安装
-
执行redis-server 配置文件名称 启动服务端
-
再执行redis-cli 6379 当然你可以去设置密码登录
测试命令:
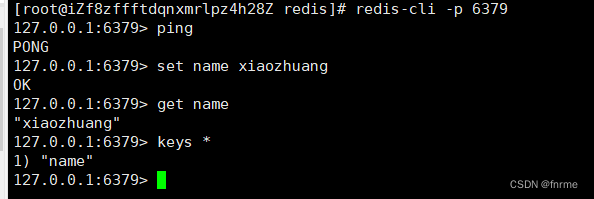
查看redis进程是否开启:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2hkIA1Ix-1670318306116)(redis.assets/image-20221120230155127.png)]](https://i-blog.csdnimg.cn/blog_migrate/595647c97c02268972a2c95df59da35c.png)
关闭redis:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Igbkbxtb-1670318306116)(redis.assets/image-20221120230348745.png)]](https://i-blog.csdnimg.cn/blog_migrate/6df95b2fe52566f9d4a5b99a8d261d03.png)
再次查看进程是否存在
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y0NotMAo-1670318306116)(redis.assets/image-20221120230435004.png)]](https://i-blog.csdnimg.cn/blog_migrate/ab553a8276be959f6645feee7f56ad7a.png)
redis的性能测试:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rpxXDga1-1670318306117)(redis.assets/image-20221120231319433.png)]](https://i-blog.csdnimg.cn/blog_migrate/55c7c58b35d5cc0c09132de52d2fa3db.png)
./redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000
但是记得先进入,否则可能出错
cd www/server/redis/src
2.基础知识
redis默认有16个数据库,默认使用第一个数据库,可以select进行切换数据库
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mZ4KXzto-1670318306117)(redis.assets/image-20221120234834907.png)]](https://i-blog.csdnimg.cn/blog_migrate/427fdd61851604db9b7c63a493033be8.png)
keys * #查看数据库所有的key
flushdb #清除当前数据库
flushall #清空所有数据库
redis 是单线程的
核心:redis 是将所有的数据全部放在内存中的,所以说使用单线程去操作效率就是最高的,多线程(CPU上下文会切换:耗
时的操作!!!),对于内存系统来说,如果没有上下文切换效率就是最高的! 多次读写都在一个CPU上,在内存情况下,这个效率是最高的
3、五大数据类型
Redis-Key
exitts name # 判断当前的key是否存在
move name 1 #移除当前key
expire name 10 #设置key的过期时间,单位秒
ttl name #查看剩余时间
type name #查看当前key的类型
String
append name "hello" #追加字符串,如果当前字符串不存在,会自动set
strlen name #获取字符段长度
incr view #自增1
decr view #自减1
incrby view 10 #设置自增步长10
incrby view 10 #设置自减步长10
getrange name 0 3 #截取字符串前三个字符 0 -1 获取全部字符串
setrange name 0 3 #替换指定位置的字符串
setex key 30 "hello" #创建并设置key的值为hello,30秒后过期
setnx key "redis" #判断key是否存在,不存在创建key;存在,则创建失败,返回0
mset k1 v1 k2 v2 k3 v3 #同时设置多个key值
mget k1 k2 k3 #同时获取多个值
msetnx k4 v4 k1 v1 #是一个原子性的操作即一起成功,一起失败,
mset user:1:name zhangsan user:1:age 2 #设置一个user:1对象,值为json字符来保存对象
getset #先get然后set
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i9z0JlWF-1670318306117)(redis.assets/image-20221122200551959.png)]
List(列表)
lpush list xxx #将一个值或者多个值放到列表的头部
lange list 0 -1 #读取列表的全部内容 方向从左边读取
lpop list #移除列表的左边第一个元素
rpop list #移除列表的右边第一个元素
lindex list 1 # 通过下标获得list种的某一个值
llen list # 返回列表的长度
lrem list 2 three # 移除列表种两个名为three的元素
ltrim list 1 2 # 截取列表中下标为1,2 的两个元素
rpoplpush list otherlist # 移除lsit列表的右边最后一个元素,放到一个新的名为otherlist的列表
lset list 0 item # 将list列表中下表为0的值更新为item的值 !!!如果不存在key,无法更新,会报错。同时不存在下标元素也会报错
linsert list before|after "hello" "my" # 在名为list的列表中,在hello的前后,插入一个名为my的元素
-
他实际上是一个链表,before Node after ,left,right 都可以插入值
-
如果key 不存在,创建新的链表
-
如果key存在,新增内容
-
如果移除了所有值,空链表,也代表不存在!
-
在两边插入或者改动值,效率最高 !中间元素,相对来说效率会低一点~
Set(集合)
set中的值不能重读的!
sadd myset "hello" # 在名为myset的集合中添加名为hello的元素
smembers myset # 查看指定set中的所有元素
sismember myset hello # 判断某一个值是不是在set集合中
scard myset # 获取set集合中的内容元素个数
srem myset other # 移除set中名为other的元素
srandmember myset # 随机抽取myset中的一个元素
srandmember myset 2 # 随机抽取myset中的指定个数2的元素
spop myset # 随机删除一些set集合中的元素
smove myset myset2 hello # 将一个指定的值,从myset集合中移动到myset2集合
sdiff key1 key2 # 差集
sinter key1 key2 # 交集
sunion key1 key2 # 并集
Hash(哈希)
Map集合 ,key-map
hset myhash field1 xz # set 一个具体的key—value
hmset myhash field1 hello field2 world #set 多个具体的key—value,并且将之前field1的覆盖
hget myhash field1 #获取一个字段值
hmget myhash field2 field1 #获取多个字段按值
hgetall myhash # 获取全部字段值
hdel myhash field1 # 删除 hash 指定key字段! 对应的value值删除
hlen myhash # 获取hash表的字段数量
HEXISTS myhash field1 # 判断hash中指定字段是否存在
127.0.0.1:6379> HKEYS myhash # 获取所有的field
1) "field2"
2) "field1"
127.0.0.1:6379> HVALS myhash # 获取所有的value
1) "world"
2) "hello"
HINCRBY myhash field3 1 # 指定自增量 为1
hsetnx myhash field4 news # 如果不存在,则可以设置,存在,则不能设置
hash适用于对象存储,变动数据较大的存储
Zset(有序集合)
在set的基础上,增加了一个值 set k1 v1 zset k1 score1 v1
zadd myset 1 one # 添加一个值
zadd myset 2 two 3 three # 添加多个值
ZRANGEBYSCORE salary -inf +inf # 显示全部的用户,从小到大
ZREVRANGE salary 0 -1 # 从大到小排序
ZRANGEBYSCORE salary -inf +inf withscores # 显示全部的用户且附带成绩
ZRANGEBYSCORE salary -inf 1500 # 显示工资小于1500 的升序排列
zrem salary xiaohong # 移除rem中的元素
zcard salary # 获取有序集合中的个数
4、三种特殊数据类型
Geospatial
所有的数据都应该录入:chinaL:city ,会让结果更加精准
GEOADD chinaL:city 116.40 39.90 beijing
GEOADD chinaL:city 121.47 31.23 shanghai
GEOADD chinaL:city 106.50 29.53 chongqing
GEOADD chinaL:city 114.05 29.53 shenzheng
GEOADD chinaL:city 120.16 30.24 hangzxhou
GEOADD chinaL:city 108.96 34.26 xian
# 添加城市数据 ,两极无法直接添加,通过java程序一次性全部导入
GEOPOS chinaL:city beijing # 获取指定的城市的经度和纬度
GEODIST chinaL:city beijing shanghai km # 查看北京到上海的直接距离 单位km
GEORADIUS chinaL:city 110 30 1000 km #以110,30这个经纬度为中心。寻找方方圆1000km内的城市
# withdist 显示到中间距离的位置 withcoord 显示他人的定位信息 count 1 筛选出指定的结果
GEORADIUSBYMEMBER chinaL:city beijing 1000 km # 找出位于指定元素周围的其他元素
GEOHASH chinaL:city beijing xian #将二维的经纬度转化为一维的字符串,如果两个字符串越接近,则距离越近
zrange chinaL:city 0 -1 # 查看地图中的全部元素
zrem chinaL:city chongqing # 移除地图中的指定元素
hyperloglog
pfadd mykey a b c d e f g h i j # 创建一组元素mykey
PFCOUNT mykey #统计mykey元素的数量
pfmerge mykey3 mykey mykey2 #合并两组mykey mykey2 =》mykey3并集
网站的uv(一个人访问一个网站多次,但是还是算作一个人!) 统计网站的访问次数
如果允许容错,那么就使用hyperloglog
如果没有容错,就使用set或者自己的数据类型即可
bitmaps
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4aEoj29m-1670318306118)(redis.assets/image-20221130004245834.png)]](https://i-blog.csdnimg.cn/blog_migrate/f20bf40bc78113ac92b865c9b524bf0b.png)
getbit sign 3 # 产看某一天是否有打卡
bitcount sign # # 统计这周的打卡记录,查看是否有全勤
事务
Redis事务本质:一组命令的集合!一个事务中的所有命令都被序列化,在事务的执行过程中,会被照顺序执行!
一次性,顺序性,排他性!执行一些列命令。
Redis事务没有隔离级别的概念
所有命令在事务中,并没有 直接被执行!只有发起执行命令的时候才会执行!Exec
R e d i s 单 条 命 令 保 存 原 子 性 , 但 是 事 务 不 保 证 原 子 性 ! \textcolor{red}{Redis单条命令保存原子性,但是事务不保证原子性!} Redis单条命令保存原子性,但是事务不保证原子性!
redis的事务:
- 开启事务(multi)
- 命令入队()
- 执行事务(exec)
锁:Redis可以
正常执行事务!
127.0.0.1:6379> multi # 开启事务
OK
# 命令队列
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> set k3 v3
QUEUED
127.0.0.1:6379(TX)> exec #执行事务
1) OK
2) OK
3) "v2"
4) OK
127.0.0.1:6379>
discard # 取消事务 ,事务队列中的命令都不会被执行
编译型异常(命令有问题!)事务中所有的命令都不执行
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cWG45SrC-1670318306118)(redis.assets/image-20221130012007243.png)]](https://i-blog.csdnimg.cn/blog_migrate/ae70bb2b75e5afbd1ecf134b131284ba.png)
运行时异常(1/0),如果事务队列中存在语法性,那么执行命令的时候,其他命令都是可以正常执行的,错误命令抛出异常!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8lCKILDf-1670318306119)(redis.assets/image-20221130012535875.png)]](https://i-blog.csdnimg.cn/blog_migrate/cba46740fca9fbae83e2287bf45a5a1d.png)
监控!Watch
悲观锁:
- 一定要加锁
乐观锁:
- 不会上锁!更新数据的时候,判断在此期间是否对数据进行操作,
- version
- 更新的时候比较version
Redis测试检测
正常执行成功!
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money #监视money对象
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> DECRBY money 20
QUEUED
127.0.0.1:6379(TX)> INCRBY out 20
QUEUED
127.0.0.1:6379(TX)> EXEC
1) (integer) 80
2) (integer) 20
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fAMWwRyJ-1670318306119)(redis.assets/image-20221130014326780.png)]](https://i-blog.csdnimg.cn/blog_migrate/5fe64dce5a59f63a5d77f5bd32802d55.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VQl7sqgr-1670318306119)(redis.assets/image-20221130014355172.png)]](https://i-blog.csdnimg.cn/blog_migrate/7e5b314d0a8225cae9f323c150015784.png)
Jedis
测试
1.导入对应依赖
<!--导入jedis的包-->
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.3.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.11</version>
</dependency>
</dependencies>
2.编码测试
- 连接数据库
- 操作命令
- 断开连接
package com.xz;
import redis.clients.jedis.Jedis;
public class TextPing {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
System.out.println(jedis.ping());
}
}
常用的API
String
List
Set
Hash
Zset
Spring boot整合
2 x 过后,底层使用netty,lettuce
-
导入依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> -
配置连接
spring: redis: host: 127.0.0.1 port: 6379 -
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E8ggrScx-1670318306120)(redis.assets/image-20221201175146755.png)]](https://i-blog.csdnimg.cn/blog_migrate/1a6718b249d3665bdb1d275c46c760a8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RFb1mbVA-1670318306120)(redis.assets/image-20221203165015395.png)]](https://i-blog.csdnimg.cn/blog_migrate/7194a071f3657ffe852bf444c67464a7.png)
自定义的RedisTemplete
package com.xz.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate();
//new 一个jackson的序列化对象
Jackson2JsonRedisSerializer serializer = new Jackson2JsonRedisSerializer(Object.class);
template.setConnectionFactory(redisConnectionFactory);
//json的序列化方式
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance,ObjectMapper.DefaultTyping.NON_FINAL);
serializer.setObjectMapper(om);
//String的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
//hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
//value的序列化采用jackson
template.setValueSerializer(serializer);
//hash的value也采用jackson的序列化
template.setHashValueSerializer(serializer);
//template.afterPropertiesSet();
// template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
Redis.conf详解
- 配置文件unit单位对大小写不敏感
网络
bing 127.0.0.1 # 绑定的ip
protected-mode yes # 保护模式
port 6379 # 端口设置
通用 GENERAL
daemonize yes # 以守护进程的方式运行,默认是no,我们需要自己开启为yes!
pidfile /var/run/redis_6379.pid # 如果以后台的方式运行,我们就需要指定一个pid文件
日志
# Specify the server verbosity Teve1
# This can be one of:
# debug (a lot of information, useful for development/testing)
# verbose (many rarely useful info, but not a mess like the debug level)
# notice (moderately verbose, what you want in production probably) 生产环境
# warning (only very important / critical messages are logged)
logleve1 notice
logfile "" #日志的文件位置名 如果为空则是标准输出
database 16 #数据库的数量 ,默认是16个
always-show-logo yes #是否总是显示logo
快照
持久化,在规定的时间内,执行了多少次操作,则会持久化到文件 .rdb .aof
redis是内存数据库,如果没有持久化,就会断电即失
# 如果900s内,如果至少有一个 key进行了修改,我们及进行持久化操作
save 900 1
# 如果300s内,至少10 key进行了修改,我们及进行持久化操作,
save 300 10
# 如果60s内,如果至少10000 key进行了修改,我们及进行持久化操作
save 60 10000
# 我们之后学习持久化,会自己定义这个测试!
stop-writes-on-bgsave-error yes # 持久化如果出错,是否还需要继续工作!
rdbcompression yes # 是否压缩 rdb 文件,需要消耗一些cpu资源!
rdbchecksum yes # 保存rdb文件的时候,进行错误的检查校验!
dir ./ # rdb 文件保存的目录!
REPLICATION 复制
SECURITY 安全
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> config get requirepass # 获取redis的密码
1)"requirepass"
2) 111
127.0.0.1:6379> config set requirepass "123456" # 设置redis的密码
OK
127.0.0.1:6379> config get requirepass # 发现所有的命令都没有权限了
(error) NOAUTH Authentication required.
127.0.0.1:6379> ping
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 123456 # 使用密码进行登录!
OK
127.0.0.1:6379> config get requirepass
1)"requirepass"
2)"123456"
限制CLIENTS
maxclients 10000 # 设置能连接上redis的最大客户端的数量
maxmemory <bytes> # redis 配置最大的内存容量
maxmemory-policy noeviction # 内存到达上限之后的处理策略
1、volatile-1ru: 只对设置了过期时间的key进行LRU(默认值)
2、a11keys-1ru : 删除1ru算法的key
3、volatile-random: 随机删除即将过期key
4、a11keys-random: 随机删除
5、volatile-tt1 : 删除即将过期的
6、noeviction : 永不过期,返回错误
APPEND ONLY 模式 aof
appendonly no # 默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分所有的情况下,rdb完全够用!
appendfilename "appendonly.aof" # 持久化的文件的名字
# appendfsync always # 每次修改都会 sync。消耗性能
appendfsync everysec # 每秒执行一次 sync,可能会丢失这1s的数据!
# appendfsvnc no # 不执行 sync,这个时候操作系统自己同步数据,速度最快!
Redis持久化
RDB(Redis DataBase)
RDB,简而言之,就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上
1、RDB方式,是将redis某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法。
2、redis在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。
3、对于RDB方式,redis会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何IO操作的,这样就确保了redis极高的性能。
4、如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
5、虽然RDB有不少优点,但它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K5d8KayC-1670318306120)(redis.assets/image-20221205194403645.png)]](https://i-blog.csdnimg.cn/blog_migrate/7bf13f44604c6a72ef48156b75c0b69a.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3Llw8H4i-1670318306121)(redis.assets/image-20221205200200040.png)]](https://i-blog.csdnimg.cn/blog_migrate/8854e2a2346213e1cf4e829cb1cf74db.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AEvD1Yke-1670318306121)(redis.assets/image-20221205200355764.png)]](https://i-blog.csdnimg.cn/blog_migrate/bf32dfb0eebdcceee4b19fd6ad3547f2.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PJnSJ3Tn-1670318306121)(redis.assets/image-20221205201003168.png)]](https://i-blog.csdnimg.cn/blog_migrate/65b6c711b8360fef62bf82892d884939.png)
AOF(Append Only File)
换了一个角度来实现持久化,那就是将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
如果在追加日志时,恰好遇到磁盘空间满、inode满或断电等情况导致日志写入不完整,也没有关系,redis提供了redis-check-aof工具,可以用来进行日志修复。
1、AOF重写的内部运行原理,我们有必要了解一下。
2、在重写即将开始之际,redis会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
3、与此同时,主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
4、当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中。
5、当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中了。
五、redis持久化----如何选择RDB和AOF
1、对于我们应该选择RDB还是AOF,官方的建议是两个同时使用。这样可以提供更可靠的持久化方案。
2、redis的备份和还原,可以借助第三方的工具redis-dump。
六、Redis的两种持久化方式也有明显的缺点
1、RDB需要定时持久化,风险是可能会丢两次持久之间的数据,量可能很大。
2、AOF每秒fsync一次指令硬盘,如果硬盘IO慢,会阻塞父进程;风险是会丢失1秒多的数据;在Rewrite过程中,主进程把指令存到mem-buffer中,最后写盘时会阻塞主进程。
恢复
1.备份被写坏的AOF文件
2.运行redis-check-aof –fix进行修复
3.用diff -u来看下两个文件的差异,确认问题点
4.重启redis,加载修复后的AOF文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PATA2wSc-1670318306122)(redis.assets/image-20221205203535733.png)]](https://i-blog.csdnimg.cn/blog_migrate/096596fe24652ac2ac1c27bd0a568a72.png)
扩展:
1、RDB 持久化方式能够在指定的时间间隔内对你的数据进行快照存储
2、AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以Redis 协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
3、只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化
4、同时开启两种持久化方式
- 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
- RDB 的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢 ?作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份 ),快速重启,而且不会有AOF可能潜在的Bug,留着作为一个万一的手段。
5、性能建议
- 因为RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留 save 900 1 这条.
规则。 - 如果Enable AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了,代价是带来了持续的0,二是AOF rewrite 的最后将 rewrite 过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite 的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上,默认超过原大100%大小重写可以改到适当的数值。
- 如果不Enable AOF,仅靠 Master-Slave Repllcation 实现高可用性也可以,能省掉一大第10,也减少了rewrite时带来的系统波动。代价是如果Master/Slave 同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个 Master/Slave 中的 RDB文件,载入较新的那个,微博就是这种架构。
Redis发布订阅
命令
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NkqwYx3V-1670318306122)(redis.assets/image-20221206002623467.png)]](https://i-blog.csdnimg.cn/blog_migrate/d694ba372a996607787aa81b66296c71.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FLDD3bcX-1670318306122)(redis.assets/image-20221206002737273.png)]](https://i-blog.csdnimg.cn/blog_migrate/de8a92bef62fed1cb237eec29bf0b725.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ioSNVpGD-1670318306123)(redis.assets/image-20221206002803624.png)]](https://i-blog.csdnimg.cn/blog_migrate/b1af521c58cb4658e2973e5ef33f55d9.png)
Redis主从复制
主从复制的作用主要包括:
1、数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据几余方式
2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复:实际上是一种服务的几余,
3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载,尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
4、高可用(集群)基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uSnxUYO2-1670318306123)(redis.assets/image-20221206141326047.png)]](https://i-blog.csdnimg.cn/blog_migrate/af317181ca517ff65dfae5fafb1ffe24.png)
环境配置
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7nVyoObI-1670318306124)(redis.assets/image-20221206142330359.png)]
info replication 查看信息
至少三个,一主二从,主写从读
复制原理
全量复制: 而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制: Master 继续将新的所有收集到的修改命令依次传给slave,完成同步
层层链路
哨兵模式
我们目前的状态是 一主二从!
1、配置哨兵配置文件 sentinel.conf
#sentine1 monitor 被监控的名称 host port 1
sentinel monitor myredis 127.0.0.1 6379 1
后面的这个数字1,代表主机挂了,slave投票看让谁接替成为主机,票数最多的,就会成为主机!
优点 :
1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有
2、主从可以切换,故障可以转移,系统的可用性就会更好
3、哨兵模式就是主从模式的升级,手动到自动,更加健壮!
缺点:
1、Redis 不好啊在线扩容的,集群容量一旦到达上限,在线扩容就十分麻烦!
2、实现哨兵模式的配置其实是很麻烦的,里面有很多选择!
哨兵模式的全部配置
# Example sentinel.conf
# 哨兵sentinel实例运行的端口 默认26379
port 26379
# 哨兵sentinel的工作目录
dir /tmp
# 哨兵sentinel监控的redis主节点的 ip port
# master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。
# quorum 配置多少个sentinel哨兵统一认为master主节点失联 那么这时客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
# 当在Redis实例中开启了requirepass foobared 授权密码 这样所有连接Redis实例的客户端都要提供密码
# 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间 failover-timeout 可以用在以下这些方面:
#1. 同一个sentinel对同一个master两次failover之间的间隔时间。
#2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
#3.当想要取消一个正在进行的failover所需要的时间。
#4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了
# 默认三分钟
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。
#对于脚本的运行结果有以下规则:
#若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
#若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
#如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
#一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
#通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
#通知脚本
# shell编程
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 客户端重新配置主节点参数脚本
# 当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。
# 以下参数将会在调用脚本时传给脚本:
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
# 目前<state>总是“failover”,
# <role>是“leader”或者“observer”中的一个。
# 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # 一般都是由运维来配置!
Redis缓存穿透和雪崩
Redis缓存的使用,极大的提升了应用程序的性能和效率,特别是数据查询方面。但同时,它也带来了一些问题。其中,最要害的问题,就是数据的一致性问题,从严格意义上讲,这个问题无解。如果对数据的一致性要求很高,那么就不能使用缓存。另外的一些典型问题就是,缓存穿透、缓存雪崩和缓存击穿。目前,业界也都有比较流行的解决方案
概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中(秒杀!),于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
解决方案
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2sYlqCz1-1670318306124)(redis.assets/image-20221206164814143.png)]](https://i-blog.csdnimg.cn/blog_migrate/22f84093949a52d02760f5e0306ad28e.png)
缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护
了后端数据源;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-crGIdtYb-1670318306125)(redis.assets/image-20221206164847712.png)]](https://i-blog.csdnimg.cn/blog_migrate/2f7eb2a724f502ffe9bb1a4d8ac2d6b8.png)
但是这种方法会存在两个问题
1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键,
2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会
有影响。
缓存击穿
概述
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个kev在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
当某个kev在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且回写缓存,会导使数据库瞬间压力过大
解决方案
设置热点数据永不过期I
从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题
加互斥锁
分布式锁: 使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
缓存雪崩
概念
缓存雪崩,是指在某一个时间段,缓存集中过期失效
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
解决方案
redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。

















 1675
1675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









