







SVM原理
当训练数据线性可分时,通过硬间隔最大化,学习线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机;
当训练数据近似线性可分时,通过软间隔最大化,学习线性分类器,即线性支持向量机,又称为软间隔支持向量机;
当训练数据线性不可分时,通过核技巧及软间隔最大化,学习非线性支持向量机。
函数间隔
定义训练数据集
T
,超平面
超平面 (w,b) 关于训练数据 T 的函数间隔为超平面
几何间隔
对于给定的训练数据集 T 和超平面
线性可分支持向量机
线性可分支持向量机学习算法-最大间隔法
输入:线性可分训练数据集
T={(x1,y1),(x2,y2),...,(xN,yN)}
,其中,
xi∈X=RN,yi∈Y={−1,+1},i=1,2,...,N;
输出:最大间隔分离超平面和分类决策函数
- 构建约束最优化问题
minw,b 12∥w∥2s.t. yi(w⋅xi+b)−1≥0,i=1,2,...,N(1)
- 求得最优解 w∗,b∗ .
- 由此得到分离超平面
w∗⋅x+b∗=0
- 分类决策函数为
f(x)=sign(w∗⋅x+b∗)
线性可分支持向量机的对偶算法
对于上式
(1)
中的不等式约束,引入拉格朗日乘子
αi≥0
,定义拉格朗日函数:
求
minw,bL(w,b,α)
对
α
的极大,可转化为如下的极小问题
解上述极小值问题可以得到 α 的解为 α∗=(α∗1,α∗2,...,α∗N)T ,从而求得
线性支持向量机
线性支持向量机学习算法-最大软间隔法
假设训练数据线性不可分,对于除去训练数据集中存在特异点后剩余的样本集合线性可分的情况,即某些样本点不能满足函数间隔大于等于1的约束条件,可以对每个样本点
(xi,yi)
引进一个松弛变量
ξ≥0
,使得函数间隔加上松弛变量大于等于1,同时,对每个松弛变量
ξi
支付一个代价
ξi
,此时的优化问题变为
线性支持向量机的对偶算法
式
(3)
中的最优化问题的拉格朗日函数是
对偶问题是拉格朗日函数的极大极小问题,先求 L(w,b,ξ,α,μ) 对 w,b,ξ 的极小,由
从而可以求得分类超平面和决策函数。
非线性支持向量机
非线性支持向量机学习算法
输入:训练数据集
T={(x1,y1),(x2,y2),...,(xN,yN)}
,其中
xi∈X=RN,yi∈Y=−1,+1,i=1,2,...,N;
输出:分类决策函数。
- 选择适当的核函数
K(x,z)
和适当的参数
C
,构造并求解最优化问题求得最优解 α∗=(α∗1,α∗2,...,α∗N)T .
minα 12∑i=1N∑j=1NαiαjyiyjK(xi,xj)−∑i=1Nαis.t. ∑i=1Nαiyi=00≤αi≤C,i=1,2,...,N - 选择
α∗
的一个正分量
0<α∗j<C
,计算
b∗=yj−∑i=1Nyiα∗i(xi⋅xj)
- 构造决策函数:
f(x)=sign(∑i=1Nα∗iyiK(x⋅xi)+b∗)
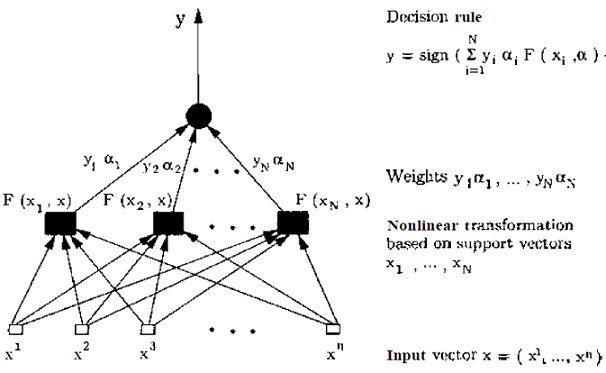
两层的SVM结构图















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









