







从概率的角度讲,以分类为例,机器学习的目的是从训练数据中学习并估计后验概率
P(c|X)
,其中
X
表示训练数据集,
对于生成模型来说,当假设了数据变量服从某种概率分布时,概率分布模型的学习过程变成了参数估计过程。
广义线性模型
一般线性回归
logistic回归
对 p(Y|X) 和 X 之间的关系建模。
朴素贝叶斯分类
朴素贝叶斯分类的主要思想是:对于待分类数据
后验概率
p(Y=cj|X)
是通过贝叶斯公式计算的,如下
其中, p(X|Y=cj) 中每个数据 X=(x1,x2,...,xm) 包含 m 个特征,如果假设这些特征是在
最大熵分类
最大熵分类的原理是对于待分类数据
X
,求输出类别
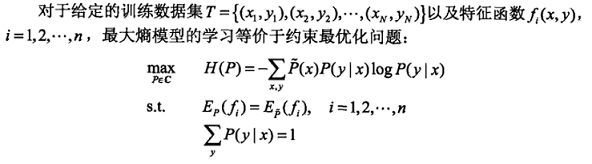
上述可以根据拉格朗日对偶性转化为极大极小问题。
最大熵模型与Logistics模型
两者均属于对数线性模型,一般使用极大似然估计学习模型中的参数。两者也均可形式化为无约束最优化问题,从而使用梯度下降、牛顿法等求解。
最大熵模型是多分类的Logistics模型。详见这里
最大熵分类与朴素贝叶斯分类
都是求给定输入
X
的情况下,求其类别
参考
最大熵模型
1.http://www.cs.cmu.edu/afs/cs/user/aberger/www/html/tutorial/tutorial.html
最大熵模型与Logistics 模型的关系
1. https://www.quora.com/What-is-the-relationship-between-Log-Linear-model-MaxEnt-model-and-Logistic-Regression#
2. Mount J. The equivalence of logistic regression and maximum entropy models[J]. URL: http://www. win-vector. com/dfiles/LogisticRegressionMaxEnt. pdf, 2011.
3. http://www.win-vector.com/blog/2011/09/the-equivalence-of-logistic-regression-and-maximum-entropy-models/















 4913
4913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









