







文章目录
一 logstash
1.1 flume和logstash的区别
| logstash | flume | |
|---|---|---|
| 输入源 | input | source |
| 中间处理 | filter | channel |
| 输出源 | output | sink |
logstash优点: 轻量级, 配置以及安装简单, 可以和es无缝结合, 有断电续传的功能, filter可以直接对数据进行清洗, 将不需要的数据过滤掉减少网络之间的传输, 主要用于日志采集.
flume优点: 用于多类型数据的采集, 在高可用方面由于logstash, 在数据传输中是通过事务控制的
1.2 logstash的安装
-
下载logstash, 上传到Linux [https://www.elastic.co/products/logstash]
-
解压logstash
tar -zxvf logstash-2.3.1.tar.gz
1.3 logstash的基本操作
1.3.1 命令行形式
-
输入是标准输入源, 输出是标准输出源
bin/logstash -e 'input { stdin {} } output { stdout{} }'
-
输入是标准输入源, 输出是ruby语言形式
bin/logstash -e 'input { stdin {} } output { stdout{codec => rubydebug} }'
-
输入是标准输入, 输出是es
bin/logstash -e 'input { stdin {} } output { elasticsearch {hosts => ["node3:9200"]} stdout{} }'

-
输入是标准输入, 输出源有两个, 一个是es, 另一个是标准输出源
bin/logstash -e 'input { stdin {} } output { elasticsearch {hosts => ["node1:9200", "node2:9200"]} stdout{} }'

-
输入是标准输入, 输出是kafka以及标准输出源
bin/logstash -e 'input { stdin {} } output { kafka { topic_id => "test1" bootstrap_servers => "192.168.88.81:9092,192.168.88.82:9092,192.168.88.83:9092"} stdout{codec => rubydebug} }'
1.3.2 配置文件形式
-
给定一个路径, 每5秒刷新一次, 将数据拉取到kafka
vi logstash-kafka.conf input { file { path => "/root/data/test.log" discover_interval => 5 start_position => "beginning" } } output { kafka { topic_id => "test1" codec => plain { format => "%{message}" charset => "UTF-8" } bootstrap_servers => "node01:9092,node02:9092,node03:9092" } } #启动logstash bin/logstash -f logstash-kafka.conf -
监控一个日志文件, 每10秒刷新一次,指定一个类型名称并拉取到es,
vi logstash-es.conf input { file { type => "gamelog" path => "/log//.log" discover_interval => 10 start_position => "beginning" } } output { elasticsearch { index => "gamelog-%{+YYYY.MM.dd}" hosts => ["node01:9200", "node02:9200", "node03:9200"] } } #启动logstash bin/logstash -f logstash.conf
1.3.3 使用filter
-
使用匹配模式, 将数据输出到ruby
bin/logstash -e ' input { stdin {} } filter { grok { match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" } } } output { stdout{codec => rubydebug} }'
1.4 数据获取流程
-
通过前端js埋点用户的点击来获取数据
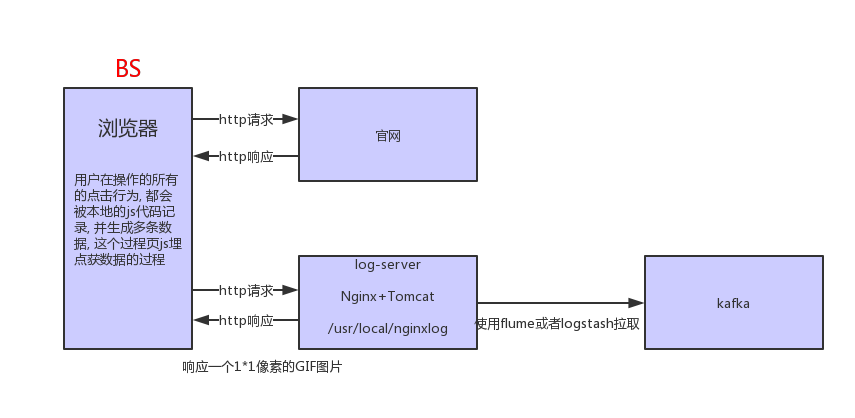
-
通过后端的javaSDK收集数据
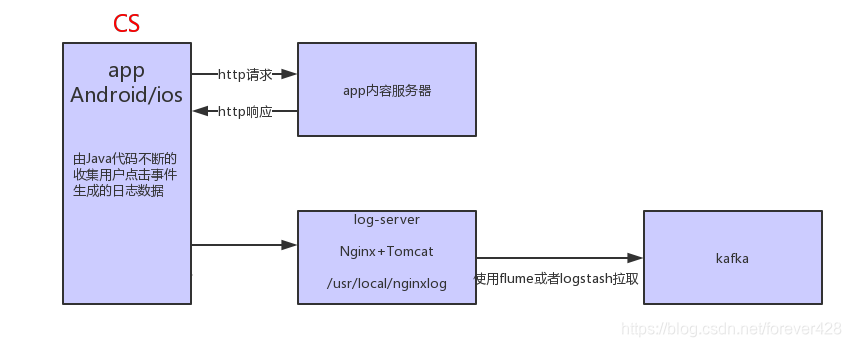
二 项目的业务流程:
- 提出需求:分情况,如果是公司自己的项目,由公司的产品经理或公司领导人提出需求。如果是第三方公司的项目,由第三方公司的需求负责人提出需求。此时的需求作为项目的可行性研究。
- 需求分析:进行需求调研–调研竞品,如果是给甲方做的项目,需要和甲方在调研的过程中继续确定需求。
- 技术选型:确定项目中各阶段需要的框架和技术。需要和多个开发部门一起研究协商。数据获取-etl-分析-存储-展示
- 可行性分析:确切的说就是预研工作–开始搭建一个基本的环境,模拟一些数据进行前期的可行性测试。
- 指标分析:根据需求来确定需要实现的指标,就是需求到指标的转换过程
- 数据对接:数据的生成、数据的采集、数据清洗、数据存储(数仓的建立)(在项目前期,这个工作相当重要)
- 数据分析:把每个指标转换为代码的过程,实现过程中的测试工作。
- 结果数据的存储
- 数据展示:由运营部门负责该工作














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









